연구실 인턴하면서 필요할 것 같기도하고 굉장히 유명한 GAN 논문 중 하나인 Style GAN을 Review 해보았습니다.
아직 학생이기도하고 영어가 미숙하다보니 본 리뷰에 오류가 있을 수도 있습니다. 이 점 감안해주시고 혹시나 찾으신다면 피드백 감사히 받겠습니다.
Introduction
지금까지 고화질의 좋은 사진을 생성할 수 있는 생성모델인 GAN에 대한 연구는 2014년 GAN이 탄생한 이후로 빠르게 진행되어 왔다. 하지만 많은 노력에도 불구하고 Generator의 생성 영역은 black box처럼 여겨지고 latent space 역시도 아직 그 이해가 턱없이 부족합니다. 본 논문은 style transfer를 기반으로 image 합성 과정을 조절할 수 있는 generator architecture을 새로 디자인하였습니다. 연구진의 generator는 평균을 종합한 상수로 구성된 input이 각 Convolutional layer을 통과할 때마다 style을 덧씌우는 형식으로 진행되고 따라서 각각의 다양한 scale에다가 style을 다르게 조절하는 형식으로 Style을 갖고 있는 이미지를 생성합니다. 또한 각 레이어마다 확률 기반의 noise가 추가되어 이미지의 세세한 부분을 보정해줘 좀 더 고품질의 이미지를 생성합니다. 해당 논문에서는 generator를 제외한 GAN의 구성요소는 크게 건들지 않아 세세하게 다루지는 않을 것입니다.
저자가 새롭게 생성한 generator는 input latent code를 input latent space로 embedding해준 후, 해당 space를 AdaIN Layer을 통해서 image에 덧씌워줍니다. 기존에 사용하던 Input latent space의 경우에는 training data의 확률 분포를 따를 수 밖에 없는 구조라 entanglement 현상을 피할 수 없다는 단점이 있습니다. entanglement와 해당 부분은 뒤에서 더 세세하게 다룰 거지만, 해당 부분에 대해서는 mapping network를 거쳐 input latent space를 형성해서 style 형태로 덧씌운다는 정도로 기억하면 좋을 것 같습니다. 또한 entanglement에 대해 평가하는 지표인 perceptual path length와 linear separability의 개념도 도입하였습니다.
추가로 연구진은 사람 얼굴에 대한 고퀄리티의 데이터셋 FFHQ를 새로 생성하여 배포하였다고 합니다.
Style-based generator
전통적인 GAN에서는 latent code Z가 FFN의 첫 Layer에 직접적으로 들어가는 형태였습니다. 하지만 연구진이 제시한 Generator에서는 8개의 FC layer로 되어있는 Mapping Network를 거쳐 W의 형태로 변환된 후, 모델에 Style 형태로 입혀집니다. Style 형태로 입혀진다는 말은 AdaIN이라는 다음 연산을 거쳐서 이루어집니다. 우선, 우리는 각 w를 layer를 거쳐 형태로 표현을 하고 AdaIN 연산은 아래와 같은 식으로 이루어집니다.
각 Layer에서 x에 대해 y라는 style은 위 AdaIN 연산을 통해 입혀지고 이 과정은 아래 그림을 통해 설명할 수 있습니다.
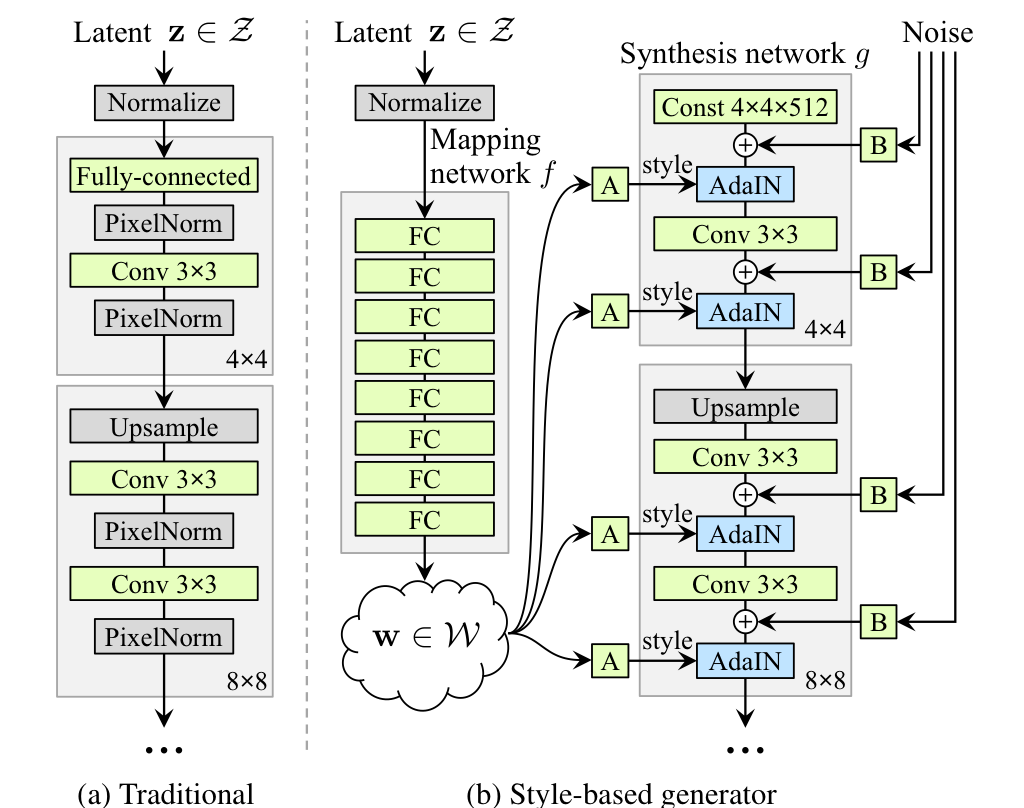
위 그림에서 A부분이 style을 설명하고 B 부분은 noise를 설명합니다. 여기서 noise란 Gaussian noise를 기반으로 확률적으로 이미지의 세세한 부분을 조절하는 것을 말하는데 이러한 확률 기반의 조절로 인해 이미지는 좀 더 사실적으로 보이는 효과를 받습니다. 자세한 설명 역시 뒤에 존재합니다.
Properties of the style-based generator
연구진의 모델은 이미지 합성을 스타일 개념으로 일궈냈습니다. mapping network와 affine transfomation을 통해 각 style의 분포를 학습시키고 이러한 분포를 통해 만들어낸 latent space를 Synthesis network를 통해서 Style을 조절가능한 Image로 합성시켰습니다.
Style Mixing
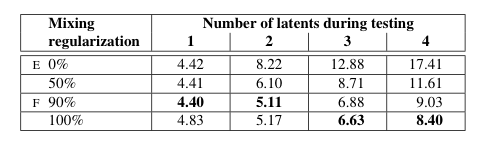
연구진은 latent vector로 특정한 이미지를 만들 때, mixing regularization이라는 효과를 노렸습니다. 하나의 w를 사용하는 것이 아니라 2개의 w를 사용해 다양한 style을 network에 첨부해 네트워크 정규화를 실시하였습니다. 다음 사진들은 이러한 방식들을 사용해서 두 상이한 이미지를 합성한 이미지입니다. 그리고 이러한 w를 각 style로서 삽입할 때 저 해상도의 layer에 삽입된 style은 좀 더 coarse한 style 위주로 image에 관여하고 점차 고해상도의 layer로 갈수로 fine한 부분을 다룬다는 것입니다. 아래 그림에서도 위의 표를 보면 Source B를 어느 layer에 넣는지에 따라서 합성한 두 이미지의 Style이 어느 위주로 반영되어있는지를 확인할 수 있습니다.

또한 아래 표를 확인하면 multiple latent vector를 사용하였을 때 대체로 더 좋은 결과를 나타내는 것 역시도 확인할 수 있습니다.
Stochastic Variation
사람의 얼굴에는 주근깨, 머리카락, 잡티 등등 확률적으로 미세하게 존재하는 많은 요소가 있습니다. 연구진은 이러한 요소들은 무작위로 확률분포를 사용해서 모델에 노이즈를 첨가함으로써 구현했습니다. 이러한 점은 논문에서 첨부한 사진들을 보면 좀 더 명확하게 이해할 수 있습니다. 머리카락들을 보면 미세하게 다름을 확인할 수 있고, 이러한 다양성은 사진을 좀 더 사실적으로 표현할 수 있도록 도와줍니다.

또한 이러한 Noise 첨가 역시도 Synthesis network에 어느 Layer에 첨가되느냐에 따라서 coarse한 부분을 조작할 지, fine한 부분을 조작할지 나뉘어집니다.

위 사진에서 (a)는 모든 부분에 noise가 첨가된 사진, (b)는 noise가 없는 사진 (c)는 fine layer(고해상도 layer)에만 noise가 첨가된 사진, (d)는 coarse layer(저해상도 layer)에 noise가 첨가된 사진입니다. (c)의 경우에는 coarse한 부분, 얼굴에 전반적인 기본틀을 건드려서 (b)보다는 (a)에 가깝고 (d)의 경우는 얼굴의 전반적인 기본틀보다는 세부적인 부분을 건드려 머리카락같은 부분은 (a)와 유사하지만 전반적인 얼굴 형태는 (b)와 더 유사함을 확인할 수 있습니다.

오 너무 깔끔한 정리에요