NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections Review
paper-review
기말고사 시즌과 새로운 방학을 맞이해 여차저차 바쁘게 사느라 되게 오랜만에 논문 리뷰를 올립니다. 방학에는 아마 NeRF 시리즈와 평소 관심있게 본 BNN 그리고 ViT, MLP Mixer 등 새로운 Vision 분야에 대해서 글을 올릴 것 같습니다. 우선 그 시작은 NeRF-W로 시작하려고 합니다.
아직 학생이기도하고 영어가 미숙하다보니 본 리뷰에 오류가 있을 수도 있습니다. 이 점 감안해주시고 혹시나 찾으신다면 피드백 감사히 받겠습니다.
Introduction
해당 논문은 Novel View Synthesis에 있어서 NeRF라는 새로운 기술이 보여준 혁신적인 결과와 NeRF의 한계점에 대해 시사하며 시작합니다. 우선 연구진이 말하는 NeRF의 문제점은 실험에서 사용한 dataset과 real world의 차이입니다. NeRF는 object가 static하다고 가정을 하고, 그렇기에 모든 사진은 동일한 조명 하에 동일한 시간에 찍혀야만 합니다.
하지만 현실의 dataset들은 그렇지 않습니다. 연구진은 다양한 각도에서의 사진을 보유하고 있는 유명 landmark 데이터를 예시로 들었는, 해당 데이터셋에서 현실세계에서의 사진들은 동시에 찍는다는 개념이 현실적으로 불가능하고 사진마다 사람, 시간, 조명 등 다양한 요소들이 다르게 나타남을 확인할 수 있습니다. 그리고 이렇게 object는 동일하지만 다양한 차이가 있는 dataset들을 기존에 NeRF의 데이터셋으로 활용할 경우 좋지 않은 성능을 보여줍니다. 그렇기에 연구진은 이러한 변화에 robust하게 대처할 수 있는 NeRF-W를 고안하게 됩니다.
NeRF-W는 크게 2가지 새로운 요소를 NeRF에 추가하였습니다. 우선, per-image appearance variation(ex: weather, lighting)들을 담은 latent space를 구현하였습니다. 그리고 이러한 latent vector를 기존에 MLP의 input으로 삼아 이러한 요소들을 고려할 수 있게 해주었습니다. 두번째로는, scene을 static component와 transient component로 구분해 학습을 시켰습니다. 그렇기에 차후 rendering 과정에서 transient한 부분을 제거하고 static한 부분만으로 좀 더 사실적인 view를 생성할 수 있었다고 합니다.
논문에서 NeRF에 대해 설명하는 부분이 꽤 깁니다. 이 부분에 대해서는 제가 올린 포스트 중 하나인 https://velog.io/@mer9ury/NeRF-Representing-Scenes-as-Neural-Radiance-Fields-for-View-Synthesis-Review
요기를 확인하시면 꽤 도움이 될겁니다!
NeRF in the Wild
여기서는 NeRF-W에 대한 세부적인 내용을 소개해보려 합니다.
Latent Appearance Modeling
연구진은 NeRF를 다양한 환경과 광원으로부터 촬영된 사진에 잘 적응시키기 위해 임베딩 기법을 사용했습니다. 그 중 연구진은 GLO(Global Latent Optimization) 기법을 사용했다고 합니다. 해당 방식에 대해서는 GLO를 소개한 논문에서 이 기법을 “discriminator-less” GAN이라고 소개하기도 하였고, 실제 논문을 보면 latent vector와 image를 매칭한 후 latent vector와 embedding network를 학습하는 구조로 일단은 단순 learnable한 embedding 정도로 이해했습니다.
렌더링 과정은 이 임베딩을 인풋으로 사용하여 다음과 같은 식을 통해서 진행됩니다.
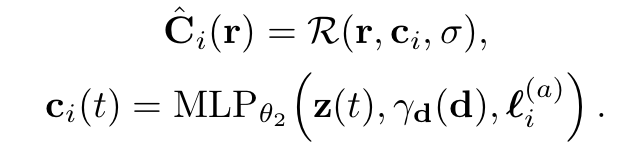
기존의 NeRF와는 다르게 input image에 dependent한 output을 결과가 나온다는 것과, 또 그 과정에서 해당 이미지의 embedding vector가 MLP의 input으로 들어감을 확인할 수 있습니다. 그리고 여기서 주목할만한 점은 서로 다른 두 이미지의embbeding vector를 interpolation함으로써 각 이미지의 style들이 섞인 image도 생성할 수 있다는 점입니다.

위 사진은 좌, 우 이미지에 대한 embedding vector를 가중치를 달리하며 interpolation한 결과입니다.
Transient Object
Real world에서 찍은 사진들은 환경과 광원등의 Style적인 요소만 다를 뿐만이 아니라 때로는 사람, 새 등 다양한 물체들이 찍히기도 합니다. 연구진은 이에 robust하게 대처하기 위해 static한 object를 다루는 network에 추가로 transient한 object를 다루는 network도 생성합니다. 이러한 최종 network structure는 아래와 같습니다.
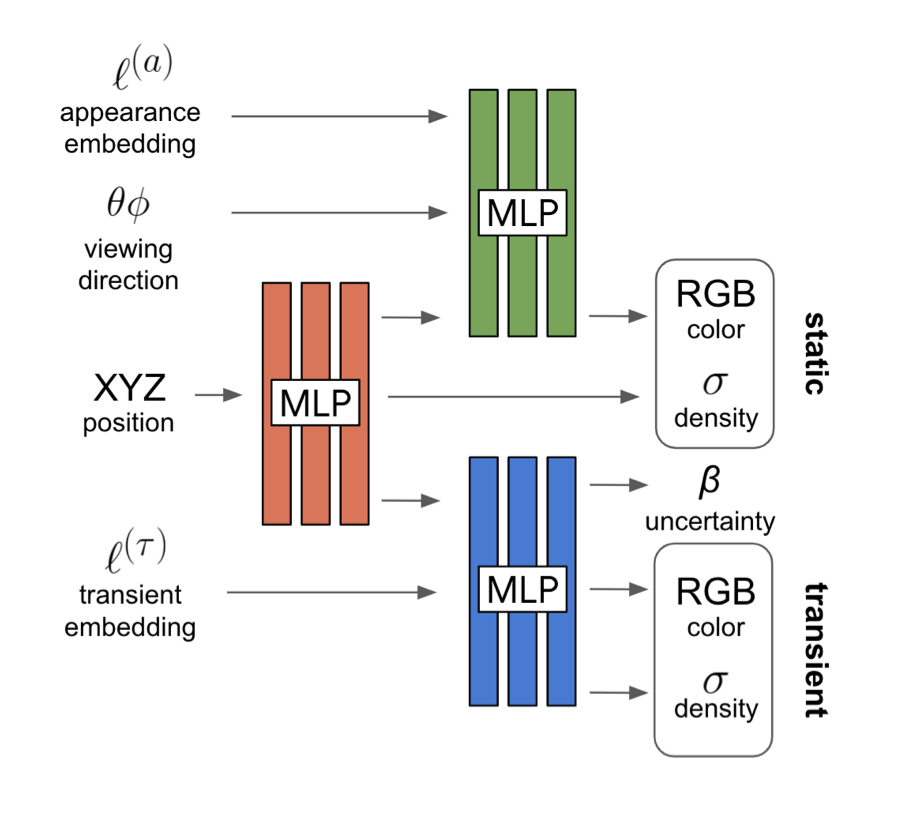
이러한 transient object로 인해 NeRF-W는 occlude와 관련된 요소들도 더 사실적으로 reconstruct할 수 있게 되었습니다. 추가로 transient object들은 static object와 달리 항상 존재하는 것이 아니기때문에 연구진은 해당 network의 output에 uncertainty라는 개념을 추가합니다. 이러한 uncertainty를 최종 output에 포함해 occluder 등을 포함한 해당 object의 pixel 관련 부분을 확률적으로 무시할 수 있게 되어 좀 더 사실적인 결과를 생성합니다.
그리고 이러한 two model 구조를 형성함으로써 NeRF-W는 static phenomena와 transient phenomena를 어떠한 supervision 없이 분리할 수 까지 있다고 연구진은 말합니다. 해당 부분과 관련된 실험결과는 아래와 같습니다. 순서대로 Static phenomena, transient phenomena, 합친 부분, GT, uncertatiny visualization 입니다.

연구진은 이 2가지의 network를 학습시키기 위해 최종 Pixel value 값에 대한 식을 아래와 같이 변경했습니다.
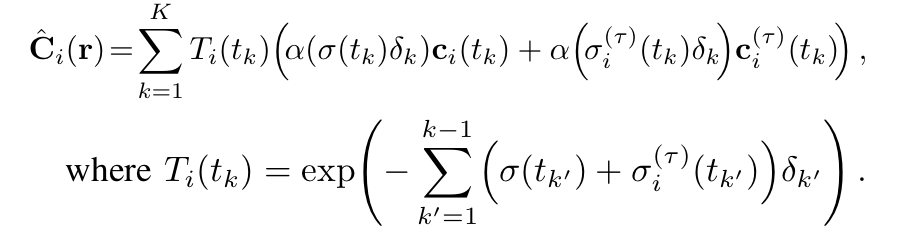
단순히 두 네트워크의 기존 결과들을 더하는 형태로 이해하기는 어렵지 않으나 이 과정에서 Uncertainty와 관련한 요소가 나타나지 않음을 확인할 수 있습니다. uncertainty는 말 그대로 확률적인 요소이기 때문에 연구진은 uncertainty를 bayesian learning framework에 접목시켜 사용하였습니다.
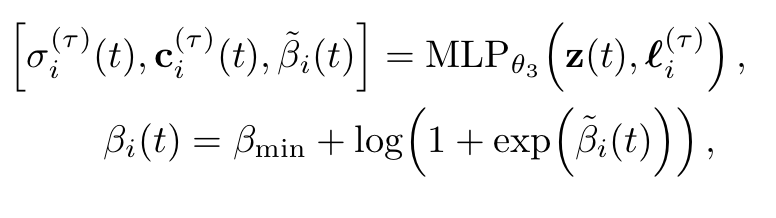
transient network의 경우 위의 식과 같은 결과를 내게 되고, uncertainty의 경우에는 softplus라는 activation function을 거쳐 최종 식을 얻게 됩니다. 이 과정에서 은 실험할 때 설정할 수 있는 parameter입니다. 그 후 최종 Color Pixel 값은 아래와 같은 확률분포에서 Sampling한다고 합니다.
이렇게 를 사용한다고 하며 최종 결과에 대해서 Loss function은 아래와 같이 설계 됩니다.
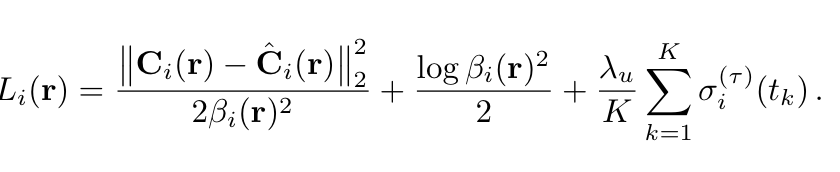
위 식의 경우에는 MLE 기반으로 최종 픽셀 값인 가우시안 분포 값을 넣고 Maximum 문제를 Minimum 문제로 변경할 시 앞의 두 항이 나오게 되고, 마지막 항은 regularization 관련 항이라고 합니다.
Optimization
NeRF-W는 기존 NeRF에서 사용했던 Positional Encoding과 Hierarchical Sampling 기법을 모두 사용하였습니다. 그 중, Hierarchical Sampling 관련해서 Coarse Network에 대해서는 latent appearance embedding vector만 사용하고 transient한 object에 대해서는 실험하지 않았다고 합니다. 그렇기에 최종적인 Loss는 아래의 식으로 계산됩니다.
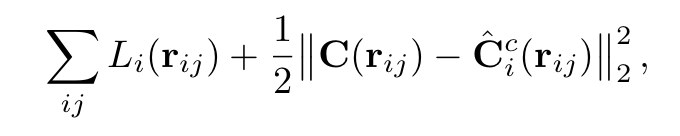
Experiments
Basic한 NeRF와 기존에 존재하는 타 NeRF와 비교했을 때 아래와 같은 실험 결과가 나왔다고 합니다.

Reference
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections - Ricardo Martin-Brualla, Noha Radwan, Mehdi S. M. Sajjadi
