이번 논문은 YOLO v2라고도 불리우는 YOLO9000입니다. 논문 구성이 기존에 읽어왔던 논문들과는 다르게 Introduction 이후에, 제목 그대로 Better/Faster/Stronger에 대한 내용을 다루고 있습니다. 우선 이번 글에서는 Better만 다뤄보고자 합니다.
아직 학생이기도하고 영어가 미숙하다보니 본 리뷰에 오류가 있을 수도 있습니다. 이 점 감안해주시고 혹시나 찾으신다면 피드백 감사히 받겠습니다.
YOLO v1의 경우는 타 object detection 기술에 비해서 굉장히 빠른 속도를 갖고 있지만, sota 기술이 되지는 못했습니다. Fast R-CNN과 비교했을 때도 상당한 localization error를 만들었고 region proposal-based 방법들과 비교했을 때 낮은 recall을 보유하고 있었습니다. 그래서 YOLO v2는 localization과 recall을 향상시키는 방향쪽으로 연구를 진행하게 되었습니다.
단순히 모델을 deep하고 large하게 만들어 성능을 향상시키는 방법도 있지만, 이러한 방법들은 기존의 YOLO의 빠른 속도라는 장점을 오히려 퇴색시킬 수도 있습니다. 그렇기에 연구진은 모델은 단순화하되, 학습이 쉽고 빠르게 될 수 있는 다양한 기술을 접목시키기로 했습니다.
1. Batch Normalization
굉장히 많은 Convolutional Network에 접목되어 있는 기술인 Batch Normalization을 YOLO의 접목시켰습니다. Batch Normalization은 학습되는 minibatch 안에서 Normalization을 진행해 학습 과정을 안정되게 해 학습 속도를 가속시키는 기술입니다. 알고리즘은 다음과 같습니다.

연구진은 Batch Normalization을 접목시킴으로써 모델의 mAP를 대략 2% 끌어올렸다고 합니다. 그리고 동시에 Batch Normalization을 적용시키면서 dropout을 모델 내부에서 제거할 수 있었다고 합니다.
2. High Resolution Classifier
YOLO v1의 경우는 224 X 224 size 의 이미지를 활용해서 모델을 학습시켰지만 detection 시에는 448 X 448 size의 확장된 이미지를 사용했습니다. 이러한 과정은 model이 새로운 input image size에 적응을 해야한다는 문제가 있습니다. 그래서 YOLO v2는 448x448 size의 image로 10 epoch동안 먼저 학습을 하고 그 후에 finetuning을 하는 식으로 진행되었습니다. 이러한 학습 방식은 mAP를 4%정도 향상시켰다고 합니다.
3. Convolutional with Anchor Boxes
YOLO v1의 경우에는 bounding box의 값이 초기값이 random으로 설정된 후 최적값을 찾는 방식으로 학습이 진행되었습니다. 또한 이 과정에서 YOLO v1은 FC Layer을 활용하기 때문에 연산량의 문제도 어느정도 존재했습니다.
그렇기에 YOLO v2에서는 Anchor Box의 개념을 도입합니다. Anchor Box란 Faster R-CNN에서 사용하는 기술로 Faster R-CNN은 9개의 anchor box를 정의한 후 ground truth와의 좌표 차이를 조정해가는 방식으로 학습을 진행합니다. 우선 Fully Connected Layer을 제거하고 최종 feature map을 13X13으로 설계합니다. 하지만 우리가 사용하는 training data의 size인 448 X 448은 13X13으로 만들 수가 없어 416 X 416으로 사용합니다.(feature map의 크기가 중심 cell이 존재) 그 후 feature map에서 7X7X2로 총 98개의 bounding box만 추출했던 v1과 달리 천개가 넘는 anchor box를 추출해 bounding box를 예측합니다.
이와 같은 기술을 사용했을 때, mAP는 대략 0.3% 감소했지만, recall의 경우 7%가량 증가했습니다. mAP가 비록 조금 감소했지만, recall의 큰 증가는 해당 모델이 발전의 여지가 있다는 것을 의미한다고 본 논문은 해석했습니다.
4. Dimension Clusters
연구진은 Anchor Box 기술을 도입하기로 했을 때 두가지 문제점을 직면했습니다. 첫 번째는 Box를 고르는 기준이 hand picked였다는 것입니다. 그래서 연구진은 Box를 고르는 기준을 설정하고, 그 기준으로 K-means clustering을 사용합니다. 다만 일반적인 K-means clustering의 기준은 Euclidean distance를 사용하지만 해당 모델에서는 IOU를 기준으로 거리를 잡습니다. 식은 다음과 같습니다
Euclidean distance를 사용하지 않는 이유는 큰 box가 작은 box에 비해 큰 error를 발생시킬 수 있어서라고 합니다. 그렇기에 위와 같은 식으로 계산을 하기로 했습니다.
연구진은 k 값을 변경해가며 최적의 k값을 찾아보았고, 그 결과 k=5일때 recall과 모델의 complexity간의 가장 적절한 trade-off를 보여주었다고 합니다.
5. Direct location prediction
Anchor Box 기술 도입 시 마주한 두번째 문제점은 model의 instability였습니다.
위와 같은 식으로 모델은 최적의 를 찾아나가는 방식이지만 이 t value에 제한이 없어서 모델이 안정적이지 못하다는 단점이 있습니다. 그렇기에 연구진은 sigmoid function을 도입해 상대적인 위치 좌표를 예측하는 방법을 택했습니다. 자세한 방식은 다음 그림 형식으로 진행이 됩니다.
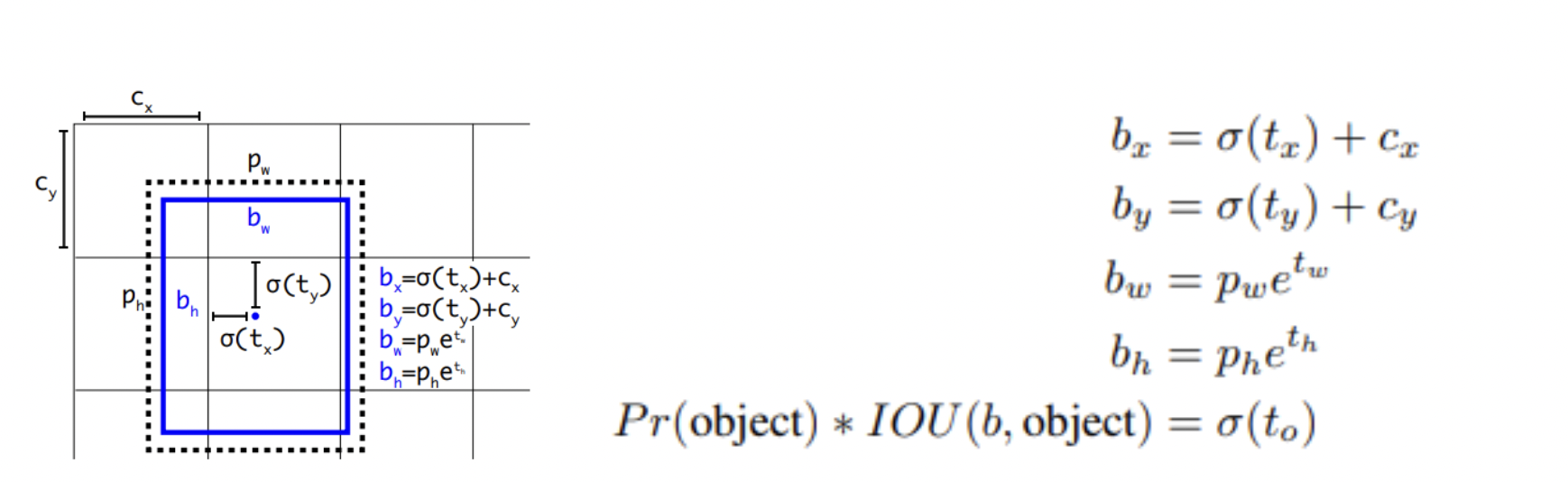
6. Fine-Grained Features
YOLO v2의 최종 feature map의 size는 13x13x1024입니다. 이 정도의 사이즈는 큰 object를 detect하기에는 적절할지 몰라도 작은 object를 detect하는데는 어느정도 문제가 있다고 합니다.
그렇기에 연구진은 최종 feature map이 추출되기 전 26x26x512의 size의 feature map을 추출해 13x13x2048 형태로 쪼갠 후 최종 feature map의 concatenate해 진짜 최종 feature map(13x13x3072)을 추출하는 방식을 택했다고 합니다. 그리고 이러한 방식은 1% 정도의 성능 향상을 일궈냈다고 합니다.
7. Multi-Scale Training
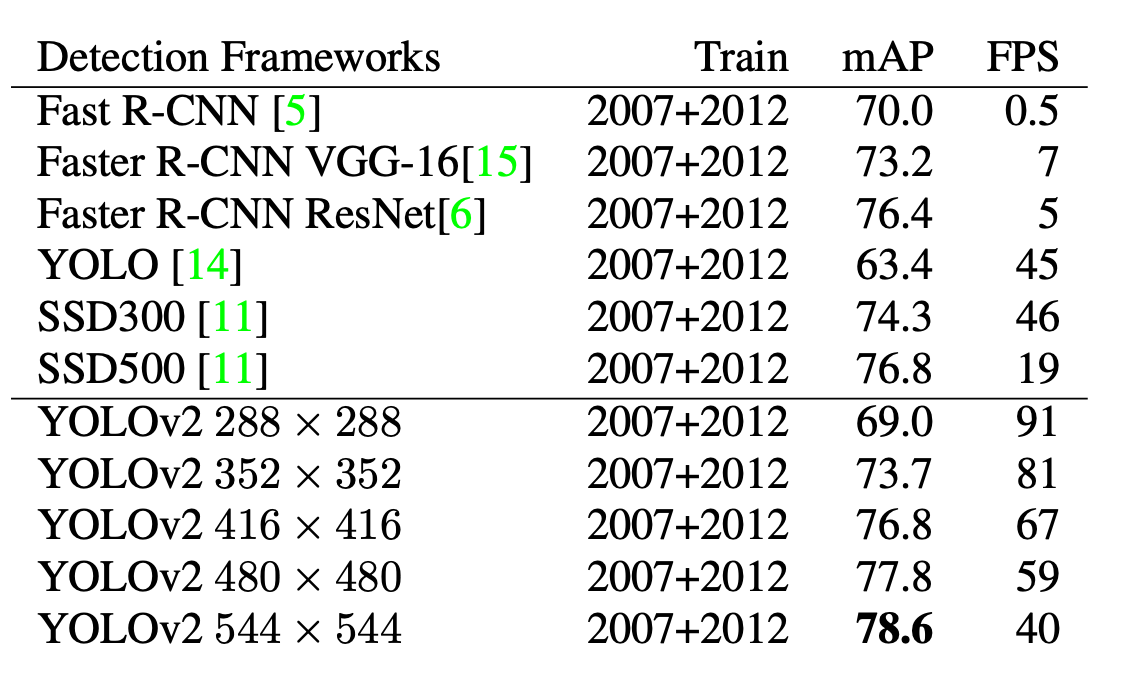
연구진은 YOLOv2를 robust한 모델로 만들기 위해 다양한 size의 image로 모델을 학습시켰다고 합니다. 320x320 부터 608x608까지 32단위로 사이즈를 조절하며 학습을 진행시켰다고 합니다. 그 결과 저해상도로 학습시킨 YOLO는 90FPS까지 속도가 나왔지만 mAP는 살짝 떨어지는 것으로 나왔고, 고해상도로 학습시킨 YOLO는 78.6이라는 높은 mAP값을 가져 state-of-the-art를 기록했습니다. 아래는 기존 모델들과 학습 데이터 해상도에 따른 YOLOv2의 성능 기록표입니다.
뒷부분은 Faster와 Stronger 부분인데 시간이되는대로 보충해보겠습니다... 현생이 너무 바쁘네요
Reference
YOLO9000: Better, Faster, Stronger -Joseph Redmon, Ali Farhadi
