비전 쪽에 관심이 생기기도 했고, 학회 스터디의 일환으로 드디어 논문 첫 리뷰를 시작하게 되었습니다.
아직 학생이기도하고 영어가 미숙하다보니 본 리뷰에 오류가 있을 수도 있습니다. 이 점 감안해주시고 혹시나 찾으신다면 피드백 감사히 받겠습니다.
Introduction
Scene text detection은 굉장히 많은 쓰임새로 인해서 CV 분야에서 굉장히 큰 관심을 받아왔습니다. 특히 text detection 분야의 2014년 AlexNet의 등장 이후로 이 deep learning 기술을 접목하자 그때부터 좋은 성능을 보여주기 시작했습니다. 하지만 구부려진 모양이거나 변형된 형태의 box로 구성된 text들에 대한 detection 성능은 아직까지 기대에 미치지 못했는데요.
이러한 문제를 해결하기 위해 본 논문은 box를 찾는 detection보다는 각 character를 찾은 후 link를 찾아 box를 형성하는 bottom-up 형식의 detection을 제안습니다. 그리고 이 framework를 CRAFT(Character Region Awareness for Text Detection)라고 부르게 됩니다.
이 Framework는 Character를 찾는 region score와 character를 grouping하는 affinity score로 구성이 되어 해당 score를 최적화하는 방식으로 학습합니다.
하지만 이 모델은 dataset이 부족하기도하고 생성하는데 너무 큰 cost가 든다는 문제가 있습니다. 그래서 이를 해결하기 위해 weakly-supervised learning을 진행합니다.
- Character - link - box 순서의 bottom-up 형식 detection
- high cost for making dataset -> weakly-supervised learning
Methodology
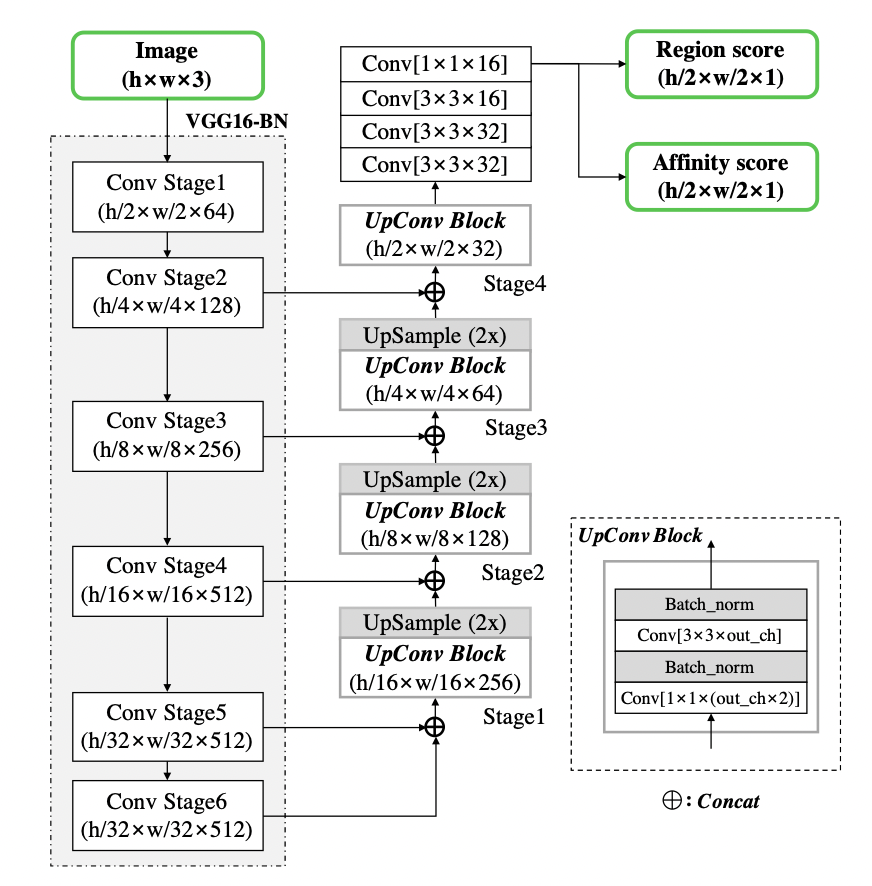
Architecture
- VGG-16 Net을 BN을 접목해서 사용
- skip-connection을 추가해 U-net과 비슷한 형태
- Final output: region score, affinity score
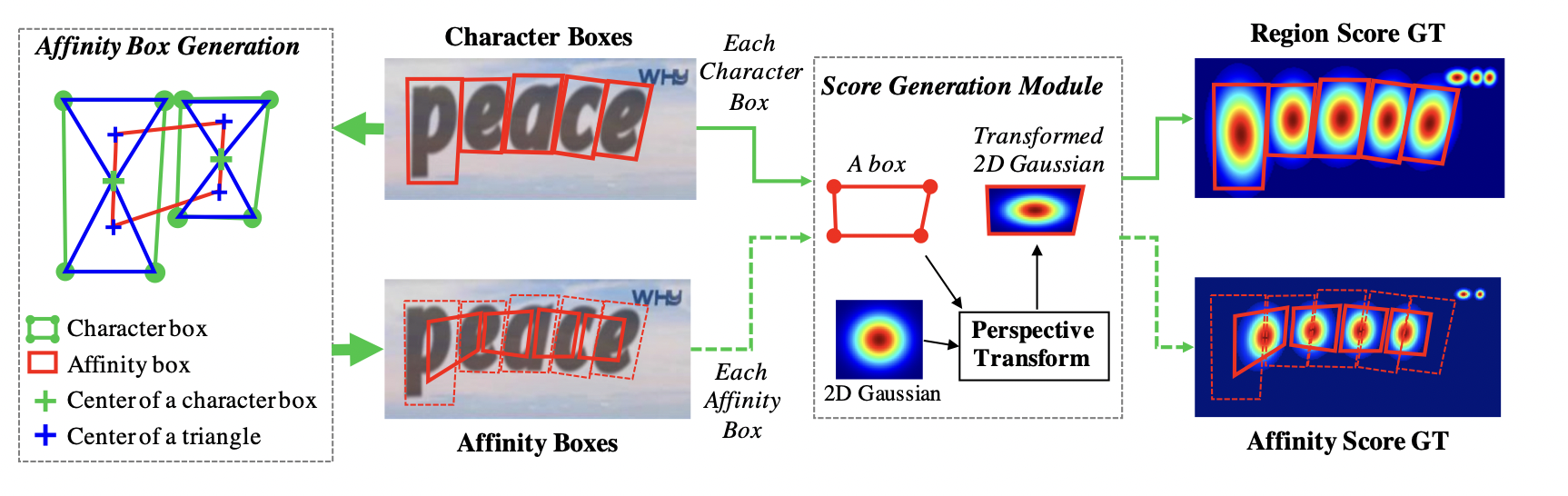
Synthetic GT Generation
우선 Ground Truth Label을 생성하는데 있어 Region score을 먼저 생성합니다. 이때, binary labeling이 아닌 Character box의 중앙점을 기점으로 2D Gaussian distribution 형태로 score를 측정한 후, Box 형태에 맞게 transform해줘 Image data에 삽입합니다.
Affinity Score 역시도, Affinity Box를 생성 후 2D Gaussian distribution 형태로 Score를 Labeling해줍니다. 이 때, Affinity Box는 인접한 Character Box의 대각선들로 삼각형을 생성해준 후, 생성된 삼각형들 중 위 아래 삼각형의 중심들을 이어서 생성해줍니다. Affinity Box Generation 부분은 그림이 좀 더 직관적으로 와닿기 때문에 아래 그림을 보시면 좀 더 이해하기 편할겁니다.
Pseudo GT Generation
하지만 이런 형식으로 Dataset을 만들기에는 character box를 일일이 다 찾는 방식에서 소모하는 cost가 너무 큽니다. 그래서 본 논문은 다음과 같은 Weakly-Supervised Learning을 사용합니다.
현실에 존재하는 Dataset들 중, Text Box가 Labeling되어있는 Dataset은 많기에 해당 Dataset을 이용해 문자가 있는 부분만 Crop합니다. 그 후, Crop된 부분만 Interim model에 넣어 Character들을 분리해주고 위 단락에서 언급한 Score Labeling을 진행해줍니다. 그리고 Wathershed algorithm을 활용해 Character Box를 찾아주고 원래 Image에 복구해줍니다.
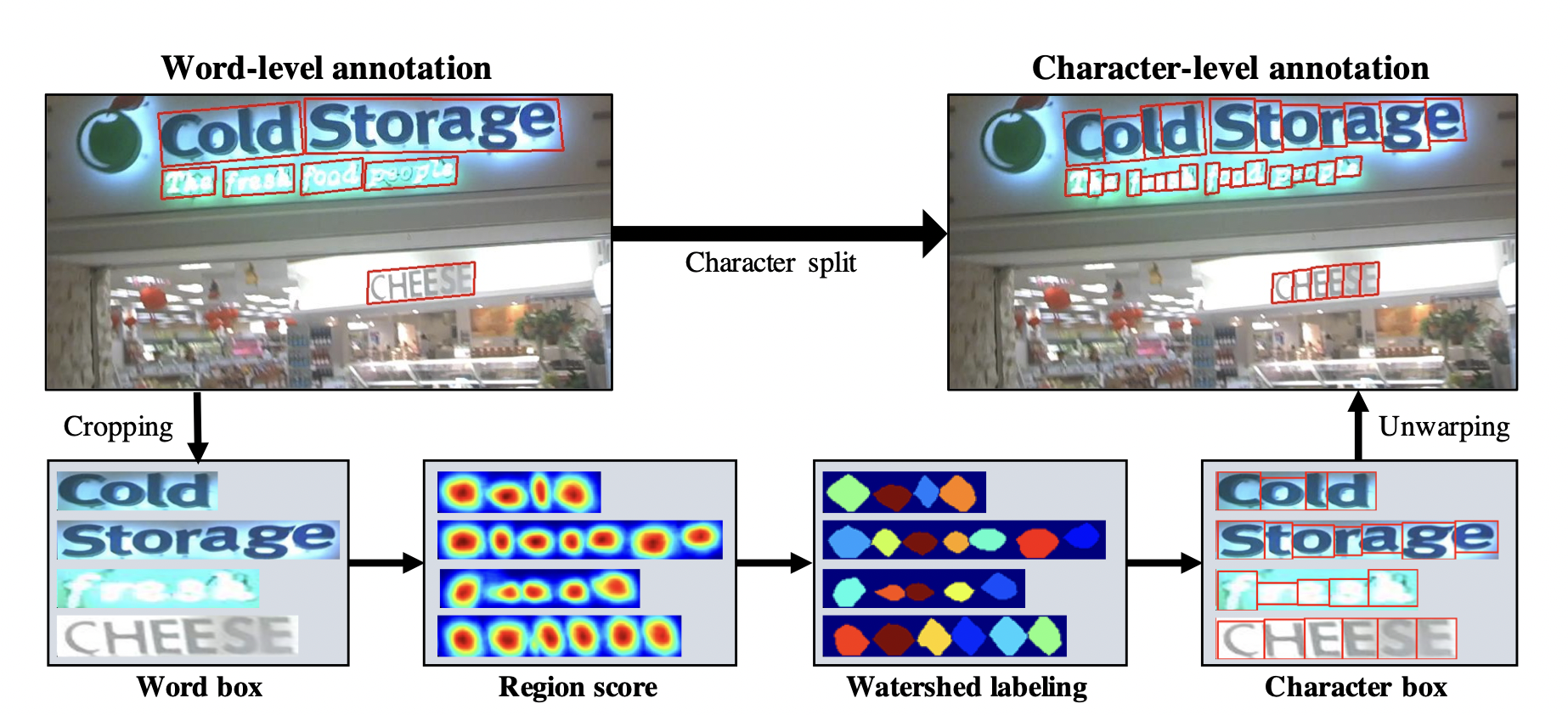
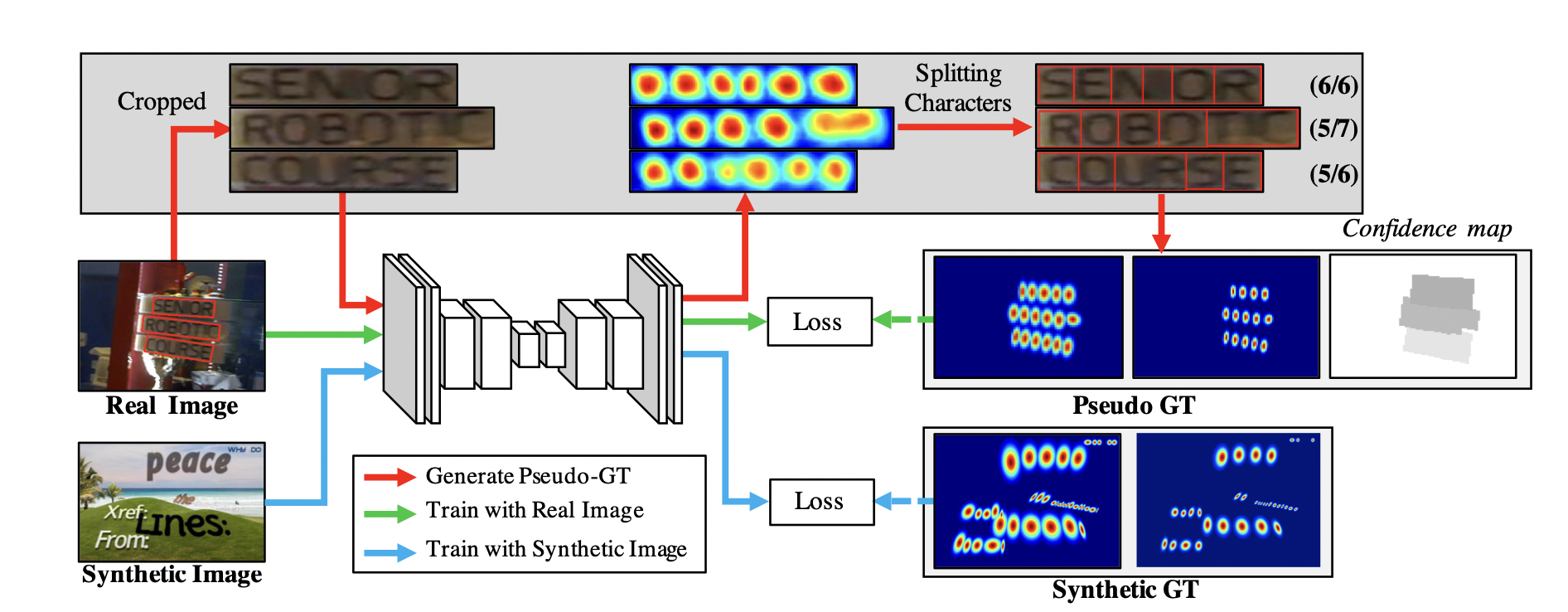
하지만 이렇게 형성된 Ground Truth를 우리는 믿을 수 있을까요? 혹시라도 잘못된 Ground Truth가 생성이 된다면 해당 Data는 Model이 제 성능을 하지 못하게 만들 수도 있습니다. 그렇기에 연구진은 이러한 형태의 Ground Truth를 pseudo-GT라고 명칭하고 pseudo-GT에 한해서는 일종의 신뢰도 개념을 도입하게 됩니다. 신뢰도 점수는 다음과 같습니다.
위 사진 속 예제에서 Storage의 경우 만약 Interim model이 8개의 글자를 추출했다면 결과는 로 인해 6/7이 됐겠네요.
만약 이 신뢰도가 너무 낮다면 어떻게 될까요?
이런 경우를 대비해서 신뢰도가 0.5이하일 경우, 값 만큼 박스를 균일하게 잘라서 Character box를 생성한 후 신뢰도는 0.5로 setting하게 됩니다.
Training
이렇게 Ground Truth를 형성하게 된 후, Objective Function을 알아보면 다음과 같습니다.
명료한 형태의 GT의 신뢰도를 반영한 목적함수의 형태를 띄고 있습니다.
그림으로 해당 모델을 요약하면 다음과 같습니다.
Inference
이렇게 모델을 거쳐서 생성된 이미지는 다음의 과정을 거쳐 Text Box를 생성하게 됩니다.
1. 이미지의 모든 pixel을 binary map으로 변환한다.
2. Affinty score or Region score과 threshold value를 넘어가면 해당 pixel의 binary map의 값을 1로 setting한다.(이때, Region threshold != Affinity threshold)
3. 해당 binarymap과 OpenCV function을 활용해 QuadBOX or Text Polygon을 생성한다.
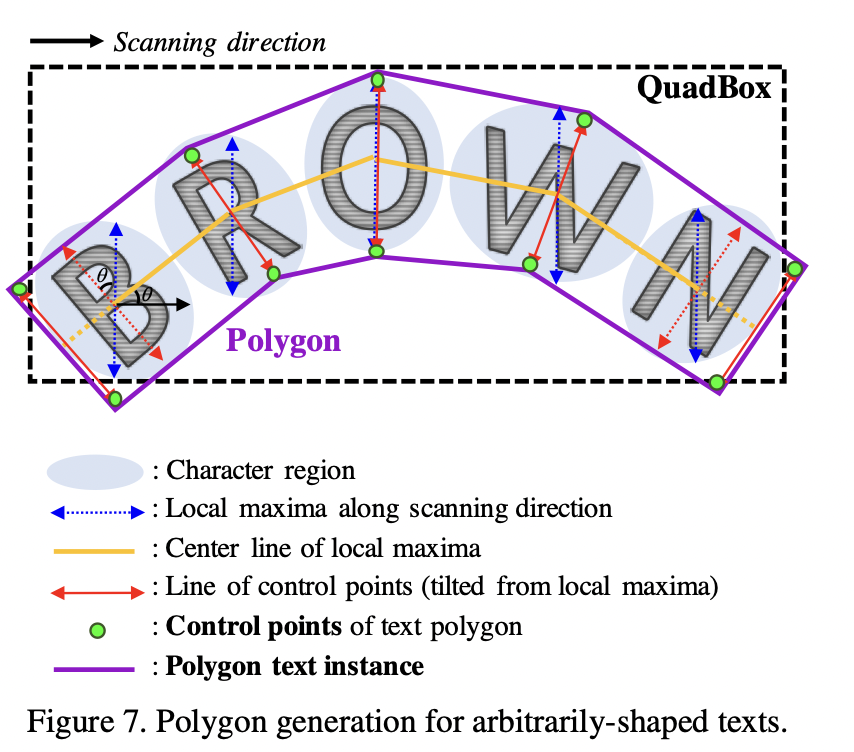
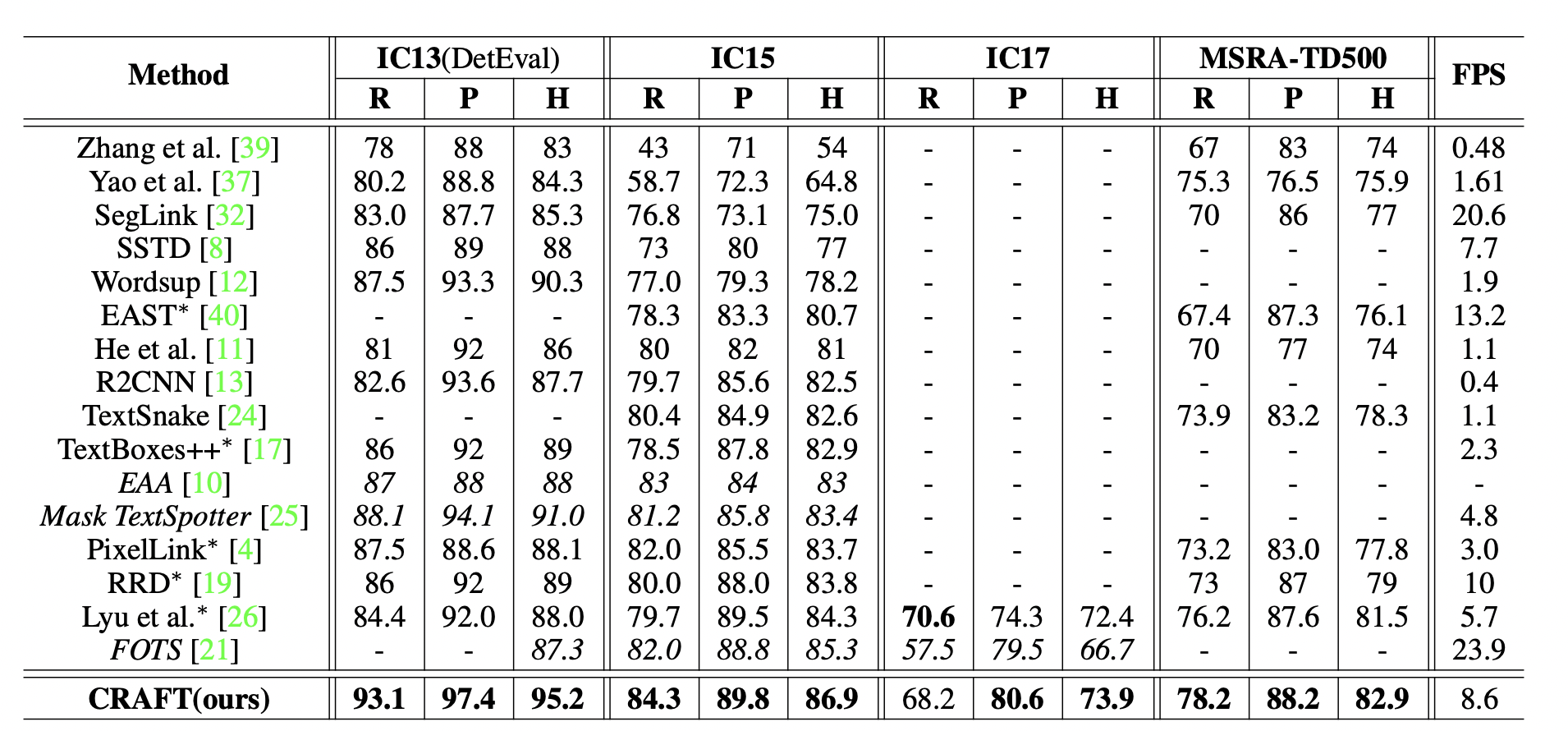
Result
타 모델들에 비해 압도적인 성능을 가지고 있음을 확인할 수 있습니다.
Reference
Character Region Awareness for Text Detection -
Youngmin Baek, Bado Lee, Dongyoon Han, Sangdoo Yun, and Hwalsuk Lee∗ Clova AI Research, NAVER Corp.
https://arxiv.org/pdf/1904.01941v1.pdf
스터디의 목표가 Pytorch code를 뜯어보는 거라, 일단 논문 리뷰는 code를 이해하는데 도움이 되는 위주로 진행했습니다. 기존에 읽어 본 object detection 논문은 fast, faster r-cnn과 yolo v1 정도가 있는데 bottom-up 방식을 통해서 detection을 했다는 발상과 그 발상을 코드로 옮기는 능력이 참 대단하다고 느껴지는 논문이었습니다. 그 다음 리뷰는 easyOCR code 리뷰가 되지 않을까 싶네요...
