Pose Detection
우선 지난번에 생각했던 구조대로 코드를 합치는 데 성공했고 대략 800개의 방향성을 띈 강아지 얼굴들을 샘플링할 수 있었다. 25만 개 data 중 800개라서 타율이 좋지는 않지만 그래도 일단 이 데이터들로 실험을 해보려고 했다.
우선 실험 가능한 변수는 다음과 같다.
- Scoring Function (1,-1) vs slope
- z vs w vs wp
가장 먼저 Scoring Function은 간편하게 (1,-1)로 했는데 사실 이것도 자의가 아니라 샘플링된 이미지들을 저장할 때 landmark 정보를 따로 저장을 안해놔서 다시 landmark detector 돌려서 계산해야 하는데 이 코드를 짜는 것보다는 1,-1 마킹하는 게 더 빨라서 (1,-1)부터 진행을 해봤다.
가장 먼저는 Z space에서 실험을 진행해봤는데 결과가 괜찮다.

Identity가 조금은 변하는 걸 확인할 수 있지만 pose는 되게 명확하게 잘 변한다. 하지만 문제가 있다면 dataset에 큰 오류는 없었는데 애가 오른쪽에서 중앙으로는 이동하지만 거기가 끝이다. 왼쪽을 보지 않는다.
원래 느낌상, 안 좋은 것부터 시작해서 좋은 걸로 실험을 하면 좀 더 나은 결과를 얻는다는 것 같은 기분이 든다. 그래서 이번에도 Z space에서 실험을 진행하고 W space로 옮겼는데... 엥?

Z space보다 왼쪽은 조금 더 보는 것 같기는 한데 전반적인 Image quality가 그렇게 좋지 않다. 다른 걸 조절해봐도 그렇다.
wp는... 실험을 해봐야하는데 이것도 실험결과들 정리할 때 wp 혼자 w, z랑 차원이 달라서 안 만들어서 실험을 안했다 ㅎ 코드를 한번에 잘 짜자...
실험 결과를 본 사수님은 일단 결과에 대해서 t-SNE로 과연 seperate가 어떻게 됐는지 한번 확인해보고 과연 landmark based pose detection이 유의미한지 human-face dataset으로 확인해보자고 하셨다. 이건 차후 해야지 우선 실험결과에 대한 t-SNE 결과는 아래와 같이 나왔다.
Z
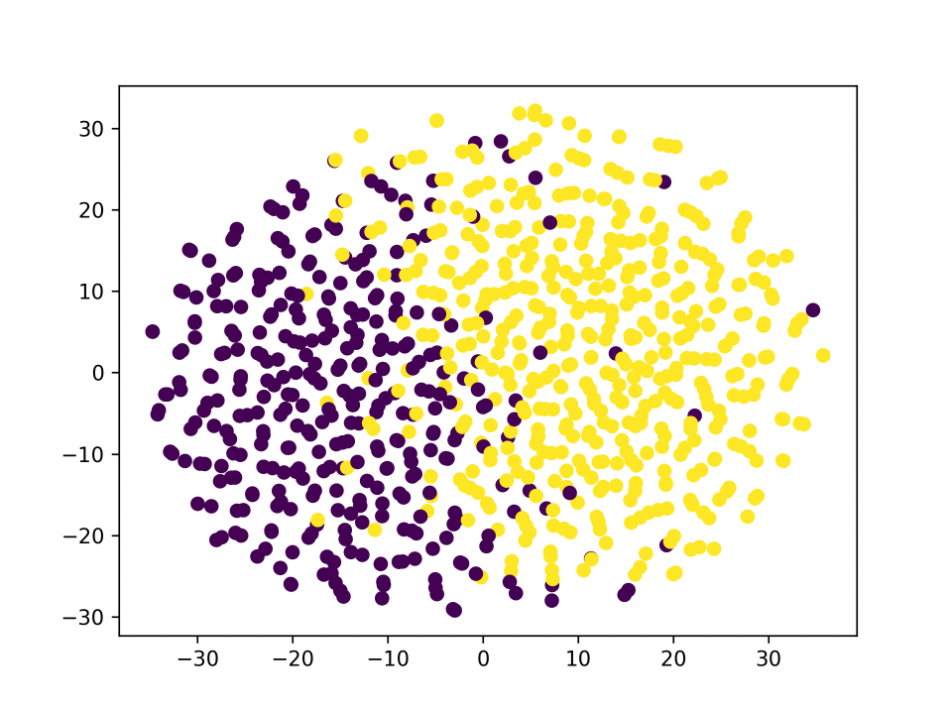
W
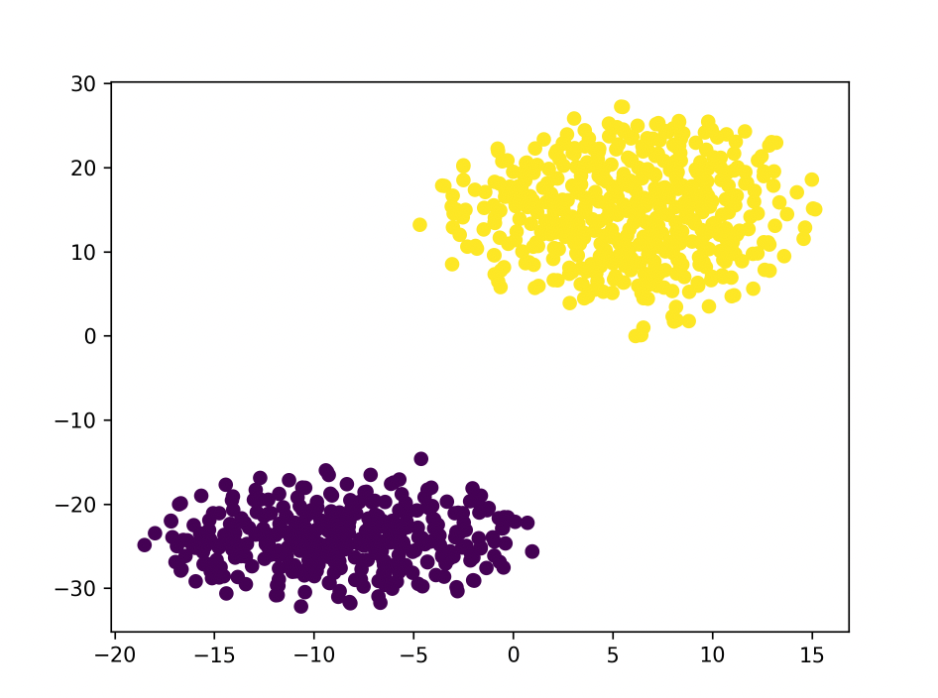
W가 seperation은 더 잘 된 걸 확인할 수 있는데... 이미지 퀄리티는 뭐가 문젤까 오히려 너무 잘 쪼개놔서 이게 문제가 되나...
하지만 통계를 공부한 사람으로서 큰 수의 법칙을 믿는 나는 더 많은 데이터셋을 만들면 이 문제가 해결될 것이라고 믿고 있다. 애초에 논문도 양 사이드에 10000개씩 해서 20000개로 sampling했는데 800개로 유의미한 결과를 본다는 마인드가 살짝 오만방자한게 아닐까
Smile Detection
Smile Detection은 우선 Landmark 기반으로 Tongue이 위치할만할 위치를 추정해서 거기서 색상데이터들의 조합으로 뭔가 찾아보자라는 시도였는데 아직은 잘 모르겠다. Tongue Detection으로 해결해보려는 시도도 해보았지만 마땅한 코드가 존재하지 않아서 이건 좀 차치하고 아예 새로운 방법론으로 가고 있다. SEFA도 좋은 unsupervised latent space discovering method지만 다른 unsupervised 방법들도 있어서 이것들로 한 번 실험을 해보려고 한다. 아니 사실 StyleGAN2 base라서 큰 어려움없이 포팅해서 지금 학습 돌리고 있다. 읽어본 논문은 Unsupervised Discovery of Interpretable Directions in the GAN Latent Space인데 이름부터 좋아보인다. 여유가 있으면 리뷰 올려야지
아무튼 순간의 귀찮음으로 인해 코드를 좀 대충 짜서 여러번 딜레이가 생겼던 주였다. 한 번에 잘 짜고 그림을 크게 크게 봐야겠다.
To-do list
- Human Face Dataset으로 landmark base - pose detection이 유의미한지 검증!
- GanLatentDiscovery 논문 모델 돌려본 거 결과 비교
- 2에서 결과 괜찮으면 이거로 Smile Axis 찾자.
