


와인 데이터 분석
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
wine_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/wine.csv'
wine = pd.read_csv(wine_url, index_col=0)
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]전처리
from sklearn.preprocessing import StandardScaler
X = wine.drop(['taste','quality'], axis=1)
y = wine['taste']
ss = StandardScaler()
X_ss = ss.fit_transform(X)EDA
# 데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_ss, y, test_size=0.2, random_state=13)# 모든 컬럼의 히스토그램 조사
wine.hist(bins=10, figsize=(15,10))
plt.show()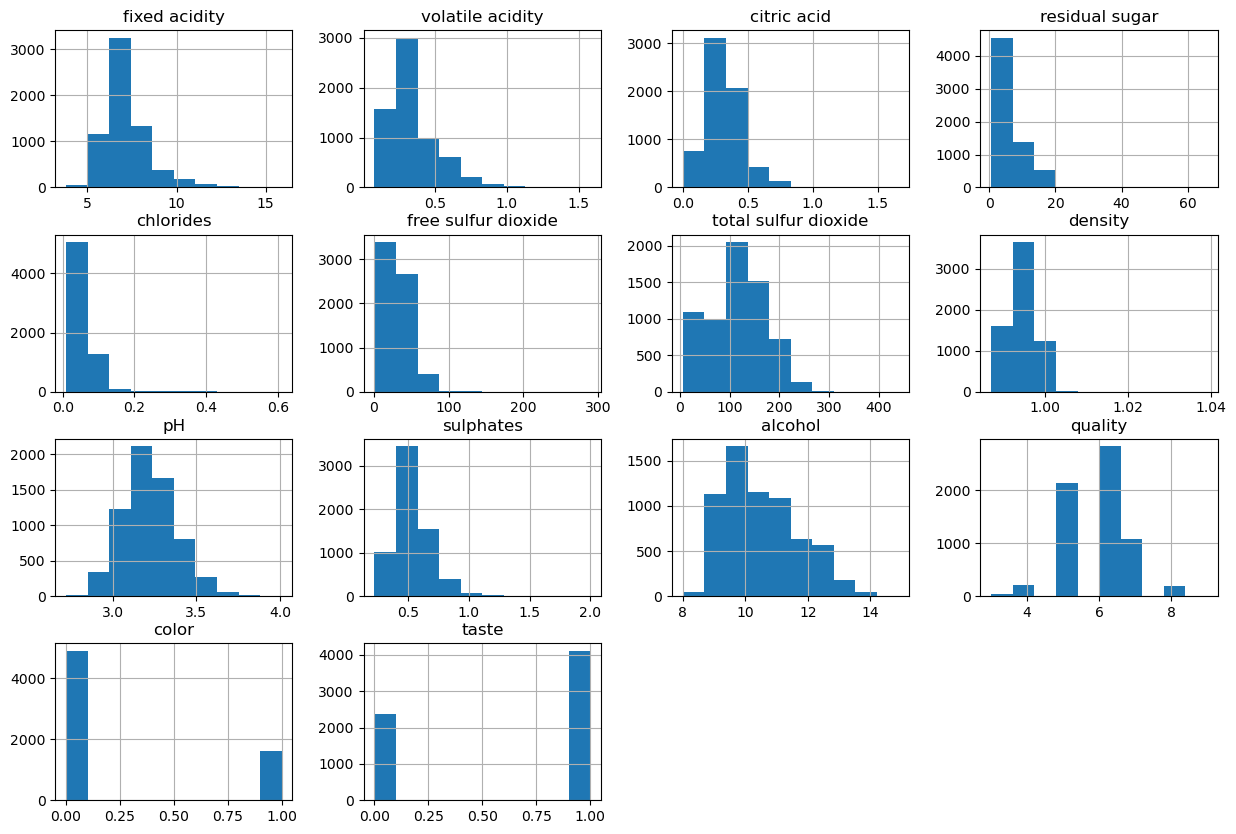
# quality별 특성 확인
column_names = ['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar',
'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density',
'pH', 'sulphates', 'alcohol']
df_pivot_table = wine.pivot_table(column_names, ['quality'], aggfunc='median')
print(df_pivot_table)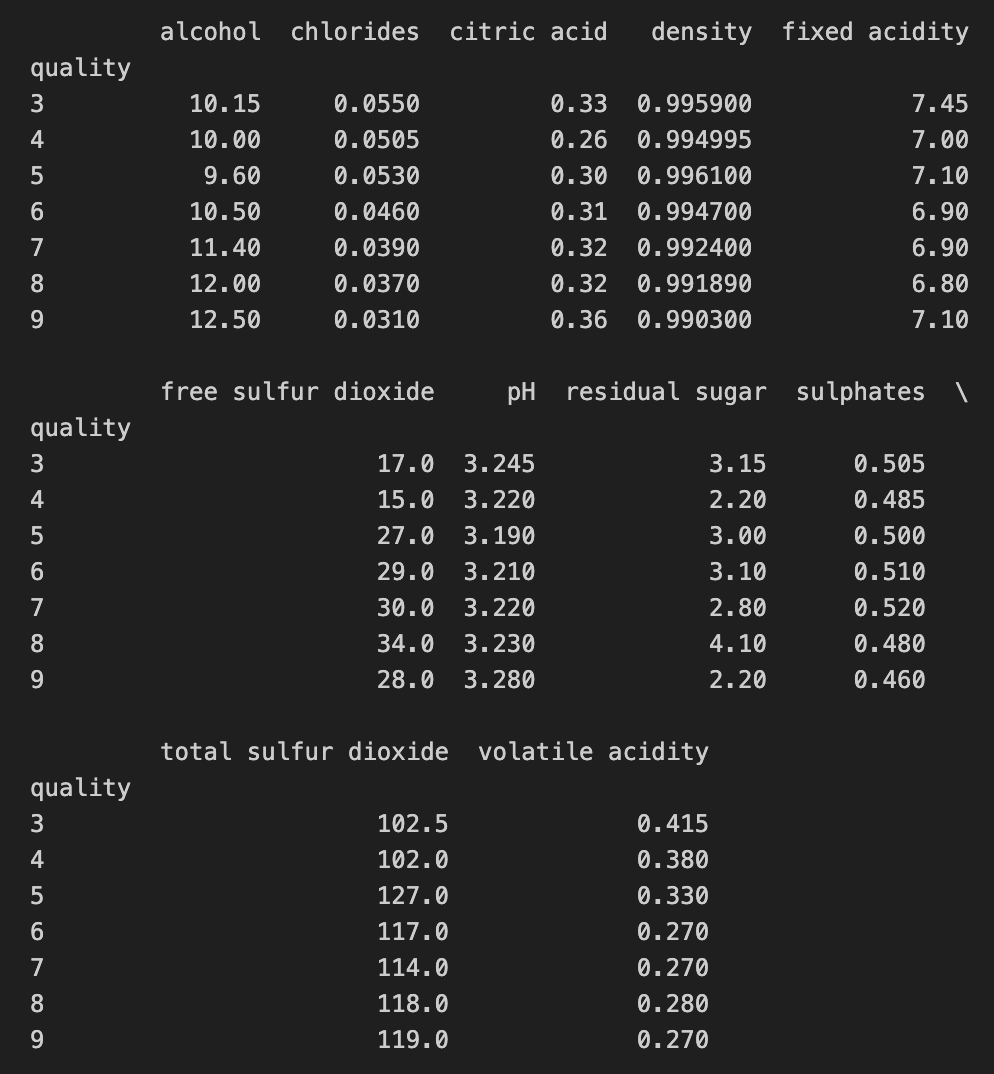
# quality와 다른 특성들 상관관계
corr_matrix = wine.corr()
corr_matrix["quality"].sort_values(ascending=False)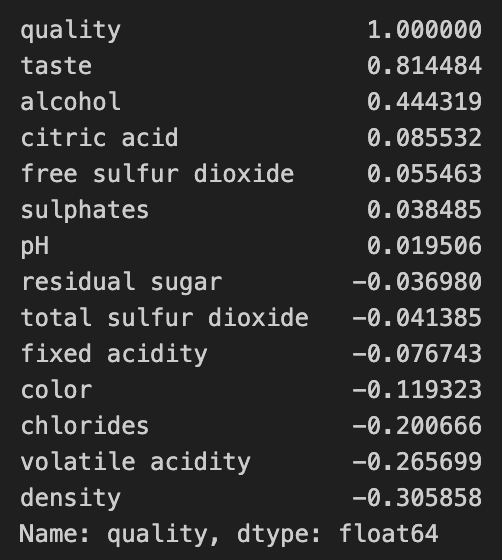
# taste 수 확인
sns.countplot(x='taste', data=wine);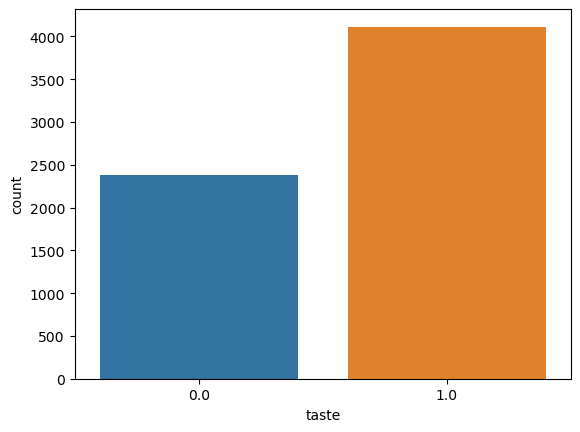
모델 분석
# 다양한 모델 한 번에 테스트
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
models = []
models.append(('RandomForestClassifier', RandomForestClassifier()))
models.append(('AdaBoostClassifier', AdaBoostClassifier()))
models.append(('GradientBoostingClassifier', GradientBoostingClassifier()))
models.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
models.append(('LogisticRegression', LogisticRegression()))# 결과 저장
from sklearn.model_selection import KFold, cross_val_score
results = []
names = []
for name, model in models:
kfold = KFold(n_splits=5, random_state=13, shuffle=True)
cv_results = cross_val_score(model, X_train, y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print(name, cv_results.mean(), cv_results.std())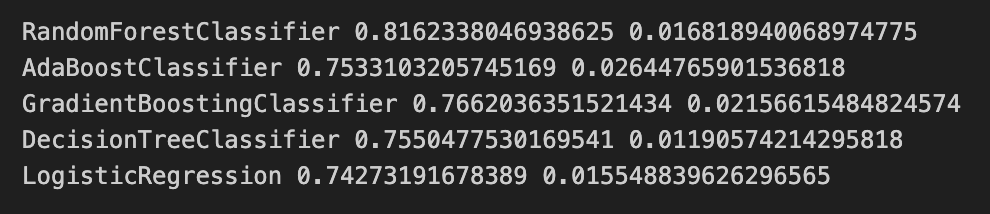
results
# 알고리즘별 성능 확인
fig = plt.figure(figsize=(14,8))
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
sns.boxplot(results)
ax.set_xticklabels(names)
plt.show()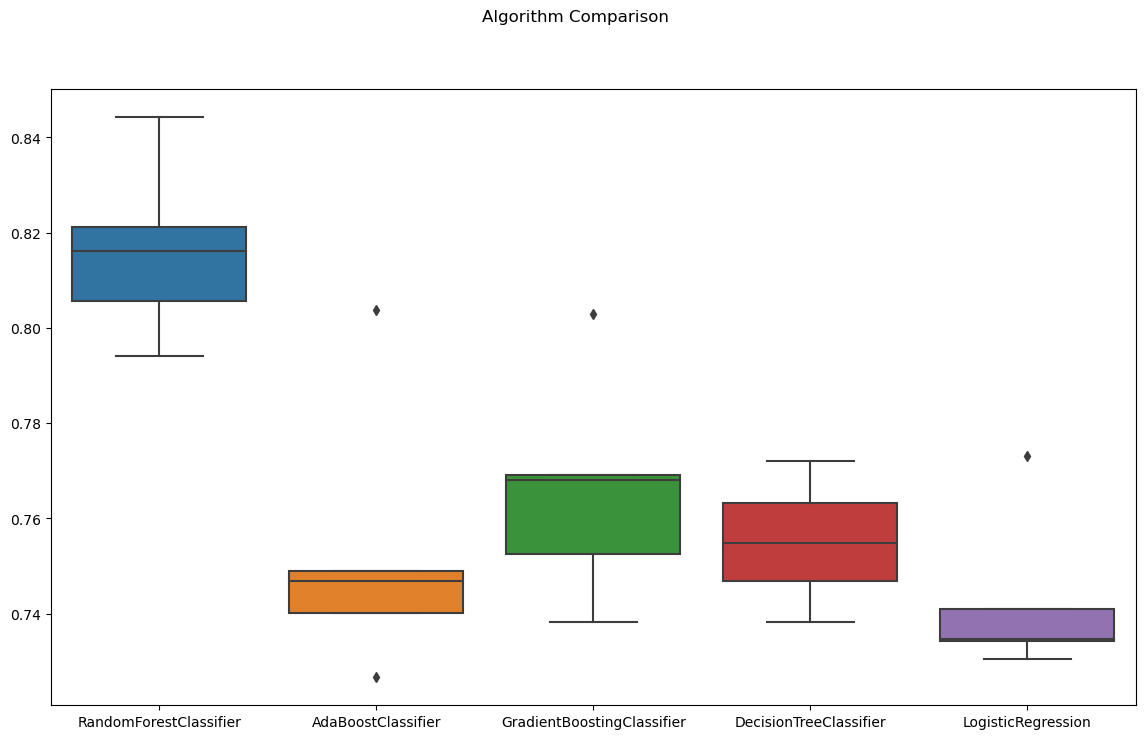
# 테스트 데이터에 대한 평가 결과
from sklearn.metrics import accuracy_score
for name, model in models:
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(name, accuracy_score(y_test, pred))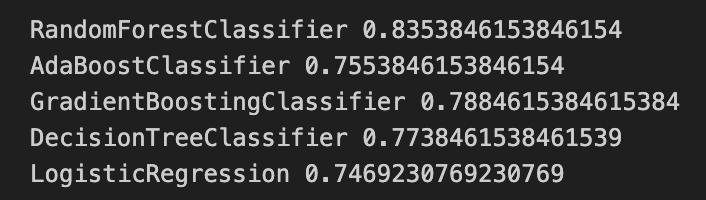
iris 데이터 분석
KNN
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 데이터
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=13, stratify=iris.target)
# 분석
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
pred = knn.predict(X_test)
print(accuracy_score(y_test, pred)) # 0.9666666666666667# 성과
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))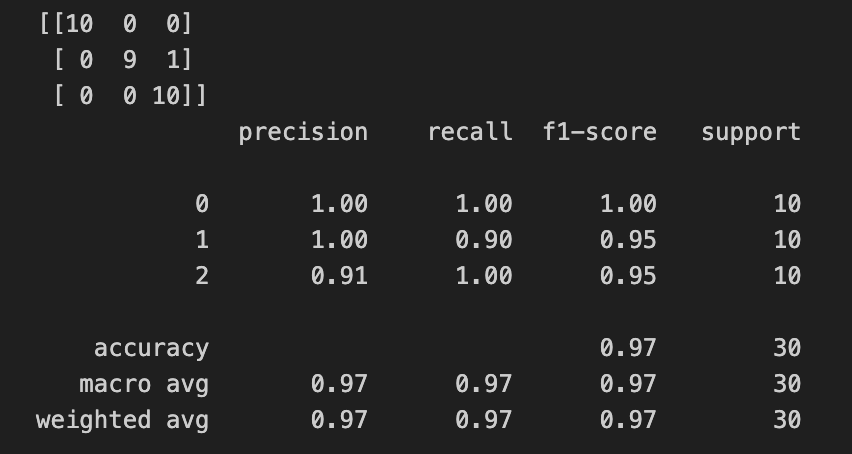
Boosting Algorithm(HAR 데이터)
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/features.txt'
feature_name_df = pd.read_csv(url, sep='\s+', header=None, names=['column_index','column_name'])
feature_name = feature_name_df.iloc[:,1].values.tolist()
X_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/X_train.txt'
X_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/X_test.txt'
X_train = pd.read_csv(X_train_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)
X_train.columns = feature_name
X_test.columns = feature_name
y_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/y_train.txt'
y_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/y_test.txt'
y_train = pd.read_csv(y_train_url, sep='\s+', header=None, names=['action'])
y_test = pd.read_csv(y_test_url, sep='\s+', header=None, names=['action'])from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
import time
import warnings
warnings.filterwarnings('ignore')GBM
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=13)
gb_clf.fit(X_train, y_train)
gb_pred = gb_clf.predict(X_test)
print('ACC : ', accuracy_score(y_test, gb_pred)) # 0.9385816084153377
print('Fit time : ', time.time() - start_time) # 520.3400387763977# GridSearchCV
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators' : [100,500],
'learning_rate' : [0.05, 0.1]
}
start_time = time.time()
grid_cv = GridSearchCV(gb_clf, param_grid=params, cv=2, verbose=1, n_jobs=-1)
grid_cv.fit(X_train, y_train)
print('Fit time : ', time.time() - start_time) # 2760.5976428985596
print(accuracy_score(y_test, grid.best_estimator_.predict(X_test))) # 0.9392602646759416XGBoost
from xgboost import XGBClassifier
start_time = time.time()
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb.fit(X_train.values, y_train-1)
print('Fit time : ', time.time() - start_time) # 70.90948677062988
xgb_pred = xgb.predict(X_test)
accuracy_score(y_test-1, xgb_pred) # 0.9494401085850017# 조기 종료 조건, 검증 데이터 지정
evals = [(X_test.values, y_test-1)]
start_time = time.time()
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb.fit(X_train.values, y_train-1, early_stopping_rounds=10, eval_set=evals)
print('Fit time : ', time.time() - start_time) # 38.06765580177307
xgb_pred = xgb.predict(X_test)
accuracy_score(y_test-1, xgb_pred) # 0.9419748897183576LightGBM
from lightgbm import LGBMClassifier
start_time = time.time()
lgb = LGBMClassifier(n_estimators=400)
lgb.fit(X_train.values, y_train-1, early_stopping_rounds=100, eval_set=evals)
print('Fit time : ', time.time() - start_time) # 9.756305932998657
lgb_pred = lgb.predict(X_test)
accuracy_score(y_test-1, lgb_pred) # 0.9260264675941635credit card fraud detection
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
raw_data = pd.read_csv('../data/creditcard.csv')EDA
raw_data['Class'].value_counts()
# 0 284315
# 1 492
frauds_rate = round(raw_data['Class'].value_counts()[1] / len(raw_data) * 100, 2)
print(frauds_rate, '%') # 0.17 %
# 시각화
sns.countplot(x='Class', data=raw_data)
plt.title('Class Distributions \n (0:No Fraud || 1:Fraud)')
plt.show()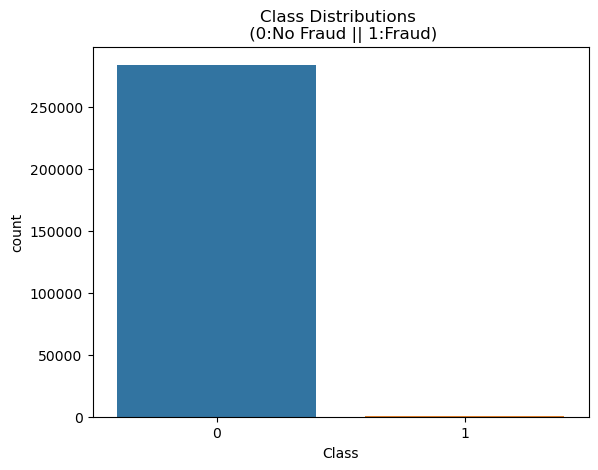
데이터 분리
from sklearn.model_selection import train_test_split
X = raw_data.iloc[:, 1:-1]
y = raw_data.iloc[:, -1]
X.shape, y.shape # ((284807, 29), (284807,))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13, stratify=y)
# 나눈 데이터의 불균형 정도 확인
tmp = np.unique(y_train, return_counts=True)[1]
tmp[1] / len(y_train) * 100 # 0.17292457591783889함수 만들기
# 1. get_clf_eval
from sklearn.metrics import (accuracy_score, precision_score, recall_score, f1_score, roc_auc_score)
def get_clf_eval(y_test, pred):
acc = accuracy_score(y_test, pred)
pre = precision_score(y_test, pred)
re = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
auc = roc_auc_score(y_test, pred)
return acc, pre, re, f1, auc
# 2. print_clf_eval
from sklearn.metrics import confusion_matrix
def print_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
acc, pre, re, f1, auc = get_clf_eval(y_test, pred)
print("=> confusion_matrix")
print(confusion)
print("==========")
print('accuracy : {0:.4f}, precision : {1:.4f}'.format(acc, pre))
print('recall : {0:.4f}, f1 : {1:.4f}, auc : {2:.4f}'.format(re, f1, auc))
# 3. get_result
def get_result(model, X_train, y_train, X_test, y_test):
model.fit(X_train, y_train)
pred = model.predict(X_test)
return get_clf_eval(y_test, pred)
# 4. get_result_pd
def get_result_pd(models, model_names, X_train, y_train, X_test, y_test):
col_names = ['accuracy','precision','recall','f1','auc']
tmp = []
for model in models:
tmp.append(get_result(model, X_train, y_train, X_test, y_test))
return pd.DataFrame(tmp, columns=col_names, index=model_names)
# 5. draw_roc_curve
from sklearn.metrics import roc_curve
def draw_roc_curve(models, model_names, X_test, y_test):
plt.figure(figsize=(7,7))
for model in range(len(models)):
pred = models[model].predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, pred)
plt.plot(fpr, tpr, label=model_names[model])
plt.plot([0,1],[0,1], 'k--', label='random guess')
plt.title('ROC')
plt.legend()
plt.grid()
plt.show()
# 6. get_outlier
def get_outlier(df=None, column=None, weight=1.5):
fraud = df[df['Class']==1][column]
quantile25 = np.percentile(fraud.values, 25)
quantile75 = np.percentile(fraud.values, 75)
iqr = iqr = quantile75 - quantile25
iqr_weight = iqr * weight
lowest_val = quantile25 - iqr_weight
highest_val = quantile75 + iqr_weight
outlier_index = fraud[(fraud<lowest_val) | (fraud>highest_val)].index
return outlier_index분석
# 1. LogisticRegression
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(random_state=13, solver='liblinear')
lr_clf.fit(X_train, y_train)
lr_pred = lr_clf.predict(X_test)
print_clf_eval(y_test, lr_pred)
# => confusion_matrix
# [[56856 8]
# [ 40 58]]
# ==========
# accuracy : 0.9992, precision : 0.8788
# recall : 0.5918, f1 : 0.7073, auc : 0.7958# 2. DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(random_state=13, max_depth=4)
dt_clf.fit(X_train, y_train)
dt_pred = dt_clf.predict(X_test)
print_clf_eval(y_test, dt_pred)
# => confusion_matrix
# [[56856 8]
# [ 33 65]]
# ==========
# accuracy : 0.9993, precision : 0.8904
# recall : 0.6633, f1 : 0.7602, auc : 0.8316# 3. RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1, n_estimators=100)
rf_clf.fit(X_train, y_train)
rf_pred = rf_clf.predict(X_test)
print_clf_eval(y_test, rf_pred)
# => confusion_matrix
# [[56857 7]
# [ 25 73]]
# ==========
# accuracy : 0.9994, precision : 0.9125
# recall : 0.7449, f1 : 0.8202, auc : 0.8724# 4. LGBMClassifier
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(random_state=13, n_jobs=-1, n_estimators=1000, num_leaves=64, boost_from_average=False)
lgbm_clf.fit(X_train, y_train)
lgbm__pred = lgbm_clf.predict(X_test)
print_clf_eval(y_test, lgbm__pred)
# => confusion_matrix
# [[56858 6]
# [ 24 74]]
# ==========
# accuracy : 0.9995, precision : 0.9250
# recall : 0.7551, f1 : 0.8315, auc : 0.8775# 5. 4개 분류모델 한 번에
import time
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg.','DecisionTree','RandomForest','LightGBM']
start_time = time.time()
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
print('Fit time : ', time.time() - start_time)
results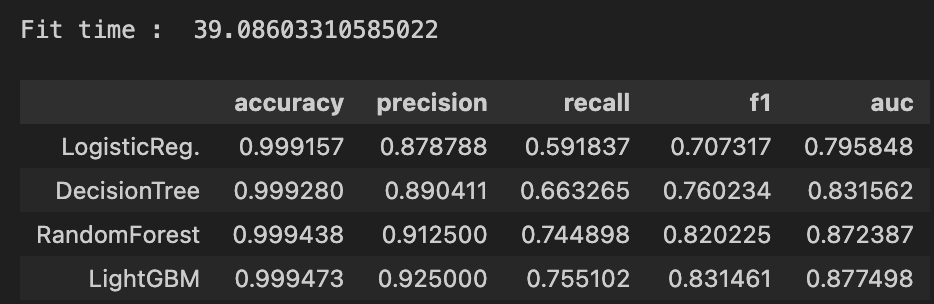
정규화(StandardScaler)
# (Amount 컬럼) 정규화 전
plt.figure(figsize=(6,5))
sns.distplot(raw_data['Amount'], color='r');
plt.show()
# (Amount 컬럼) 정규화
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
amount_n = scaler.fit_transform(raw_data['Amount'].values.reshape(-1, 1))
raw_data_copy = raw_data.iloc[:, 1:-2]
raw_data_copy['Amount_Scaled'] = amount_nplt.figure(figsize=(6,5))
sns.distplot(raw_data_copy['Amount_Scaled'], color='r');
plt.show()
# 정규화된 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(raw_data_copy, y, test_size=0.2, random_state=13, stratify=y)
# 분석
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg.','DecisionTree','RandomForest','LightGBM']
start_time = time.time()
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
print('Fit time : ', time.time() - start_time)
results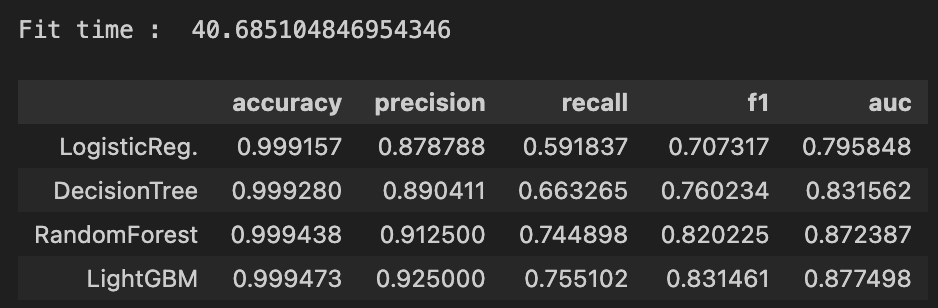
# roc커브 그리기
draw_roc_curve(models, model_names, X_test, y_test)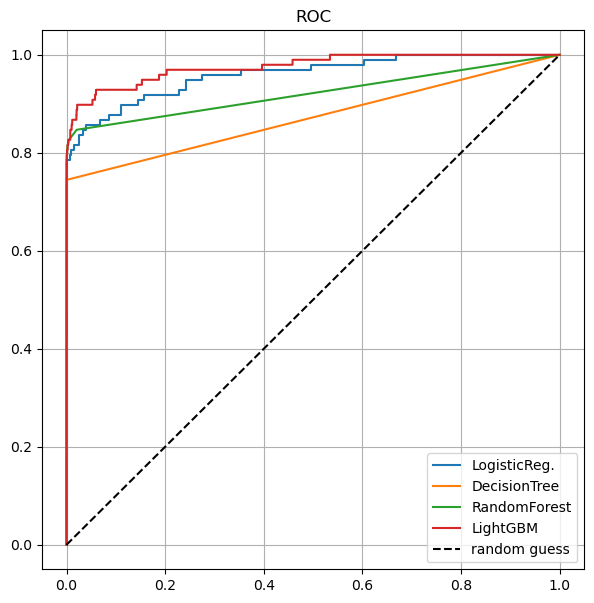
정규화(log scale)
amount_log = np.log1p(raw_data['Amount'])
raw_data_copy['Amount_Scaled'] = amount_log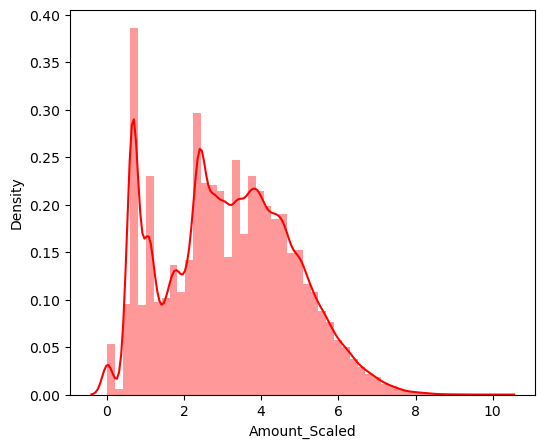
# 정규화된 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(raw_data_copy, y, test_size=0.2, random_state=13, stratify=y)
# 분석
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg.','DecisionTree','RandomForest','LightGBM']
start_time = time.time()
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
results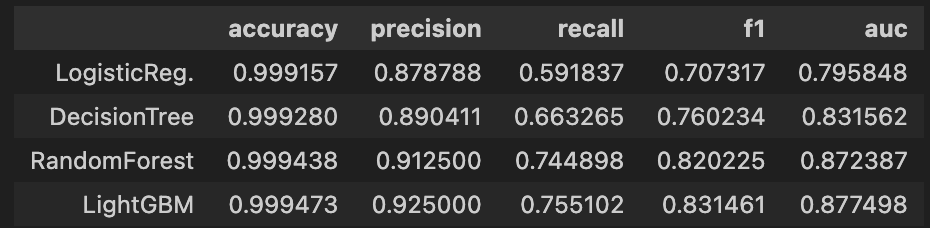
# roc커브 그리기
draw_roc_curve(models, model_names, X_test, y_test)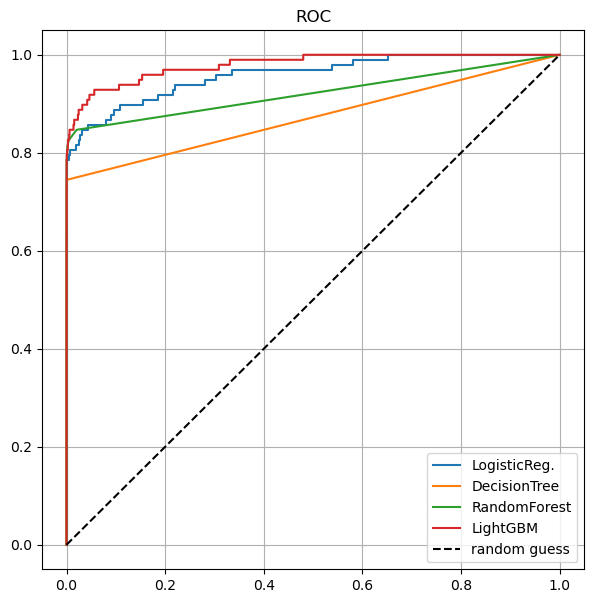
이상값 처리
plt.figure(figsize=(7,6))
sns.boxplot(data=raw_data[['V13','V14','V15']]);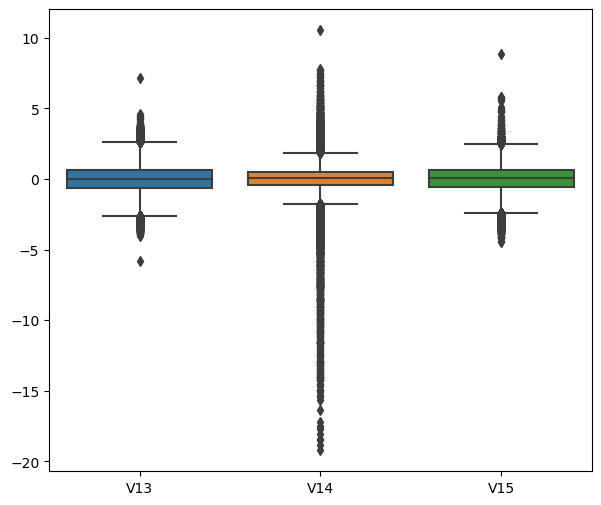
# 현재 행 수
raw_data_copy.shape # (284807, 29)
# 이상값 처리
outlier_index = get_outlier(df=raw_data, column='V14', weight=1.5)
# Int64Index([8296, 8615, 9035, 9252], dtype='int64')
raw_data_copy.drop(outlier_index, axis=0, inplace=True)
raw_data_copy.shape # (284803, 29)
X = raw_data_copy
raw_data.drop(outlier_index, axis=0, inplace=True)
y = raw_data.iloc[:, -1]
# 이상값 처리 된 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13, stratify=y)
# 분석
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg.','DecisionTree','RandomForest','LightGBM']
start_time = time.time()
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
results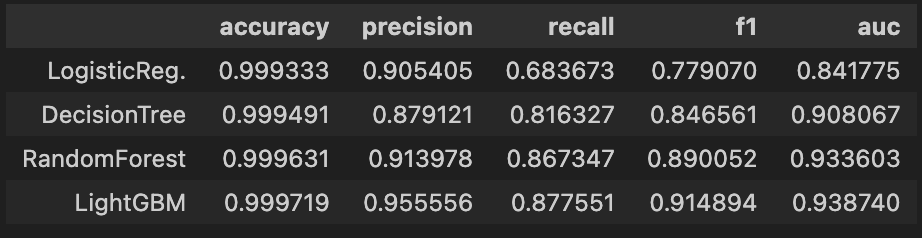
# roc커브 그리기
draw_roc_curve(models, model_names, X_test, y_test)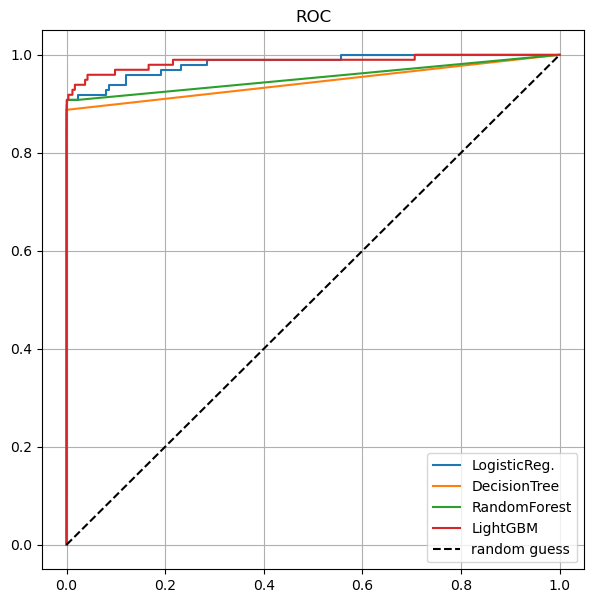
오버샘플링(SMOTE)
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=13)
X_train_over, y_train_over = smote.fit_resample(X_train, y_train)
print(np.unique(y_train, return_counts=True))
print(np.unique(y_train_over, return_counts=True))
# (array([0, 1]), array([227452, 390]))
# (array([0, 1]), array([227452, 227452]))
# 분석
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg.','DecisionTree','RandomForest','LightGBM']
start_time = time.time()
results = get_result_pd(models, model_names, X_train_over, y_train_over, X_test, y_test)
results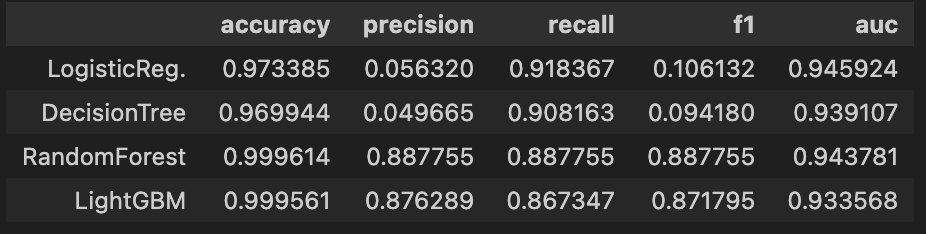
# roc커브 그리기
draw_roc_curve(models, model_names, X_test, y_test)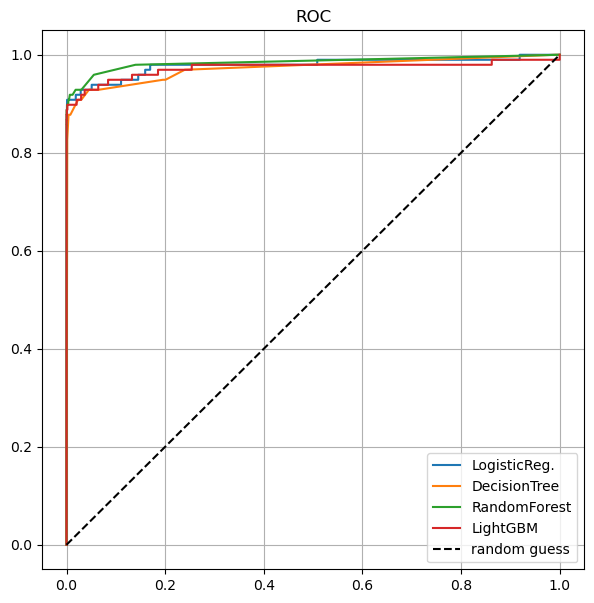
자연어 처리
형태소 분석
# Kkma
from konlpy.tag import Kkma
kkma = Kkma()
message = '한국어 분석을 시작합니다 재미있어요~~'
kkma.sentences(message)
kkma.nouns(message)
kkma.pos(message)
# Hannanum
from konlpy.tag import Hannanum
hannanum = Hannanum()
hannanum.nouns(message)
hannanum.pos(message)
# Okt
from konlpy.tag import Okt
t = Okt()
t.nouns(message)
t.morphs(message)
t.pos(message)워드클라우드
앨리스
# 폰트 설정
import platform
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
%matplotlib inline
path = "C:/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
rc("font", family="Arial Unicode MS")
elif platform.system() == "Windows":
font_name = font_manager.FontProperties(fname=path).get_name()
rc("font", family=font_name)
else :
print("Unknown system. sorry")from wordcloud import WordCloud, STOPWORDS
from PIL import Image
import numpy as np
text = open('../data/alice.rtf').read()
alice_mask = np.array(Image.open('../data/06_alice_mask.png'))
stopwords = set(STOPWORDS)
stopwords.add('said')
wc = WordCloud(
background_color="white", max_words=2000, mask=alice_mask, stopwords=stopwords
)
wc = wc.generate(text)
# wc.words_ # 단어와 빈도 확인
plt.figure(figsize=(8,8))
plt.imshow(alice_mask, cmap=plt.cm.gray, interpolation='bilinear')
plt.axis("off")
plt.show()
plt.figure(figsize=(8,8))
plt.imshow(wc)
plt.axis("off")
plt.show()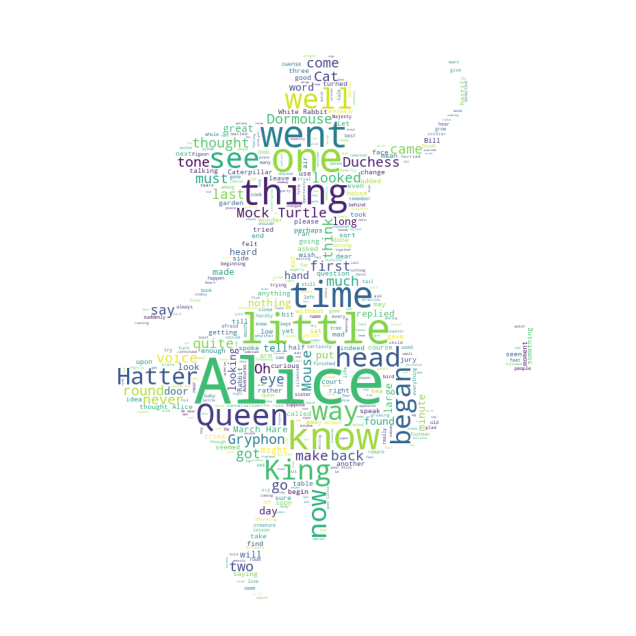
스타워즈
text = open("../data/a_new_hope.rtf").read()
text = text.replace("HAN", "Han")
text = text.replace("LUKE'S", "Luke")
mask = np.array(Image.open('../data/06_stormtrooper_mask.png'))
stopwords = set(STOPWORDS)
stopwords.add('int')
stopwords.add('ext')
wc = WordCloud(
max_words=1000, mask=mask, stopwords=stopwords, margin=10, random_state=1
).generate(text)
# default_colors = wc.to_array
# 흑백으로 그리기 위한 함수
import random
def grey_color_func(
word, font_size, position, orientation, random_state=None, **kwargs
):
return "hsl(0, 0%%, %d%%)" % random.randint(60, 100)
plt.figure(figsize=(8,8))
plt.imshow(wc.recolor(color_func=grey_color_func, random_state=13))
plt.axis("off")
plt.show()
육아휴직 관련 법안
import nltk
from konlpy.corpus import kobill
# files_ko = kobill.fileids()
doc_ko = kobill.open("1809890.txt").read()
tokens_ko = t.nouns(doc_ko)
ko = nltk.Text(tokens_ko, name='대한민국 국회 의안 제 1809890호')
print(len(ko.tokens)) # 735
print(len(set(ko.tokens))) # 250
ko.vocab() # 단어별 빈도 수 확인
# 제외힐 단어 처리
stop_words = [".","(",")",",","'","%","-","X",").","x","의","자", "에","안","번","호","을","이","다","만","로","가","를"]
ko = [word for word in ko if word not in stop_words]
ko = nltk.Text(ko, name='대한민국 국회 의안 제 1809890호')
# ko.count("초등학교") # 6
# ko.concordance("초등학교") # 해당 단어 좌우 글자
# ko.collocations() # 조합을 이루는 단어 (초등학교 저학년; 근로자 육아휴직; 육아휴직 대상자; 공무원 육아휴직)
plt.figure(figsize=(12,6))
ko.plot(50)
plt.show()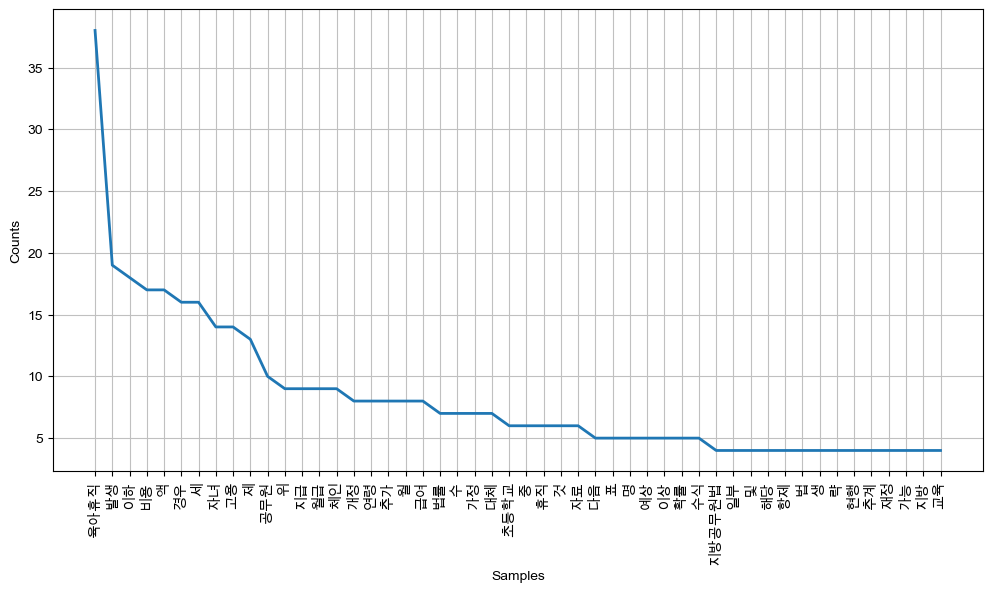
plt.figure(figsize=(15,5))
ko.dispersion_plot(["육아휴직", "초등학교", "공무원"])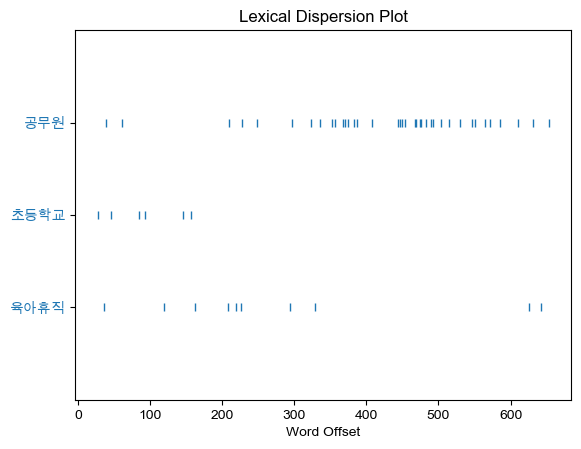
data = ko.vocab().most_common(150)
wordcloud = WordCloud(
font_path="/Library/Fonts/Arial Unicode.ttf",
relative_scaling=0.2,
background_color="white"
).generate_from_frequencies(dict(data))
plt.figure(figsize=(12,8))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
감성분석
영어
from nltk.tokenize import word_tokenize
train = [
("i like you", "pos"),
("i hate you", "neg"),
("you like me", "neg"),
("i like her", "pos")
]
# 말 뭉치 만들기
all_words = set(
word.lower() for sentence in train for word in word_tokenize(sentence[0])
)
# {'hate', 'her', 'i', 'like', 'me', 'you'}
# 말뭉치에 있는 단어들이 해당 문장에 있는지 없는지
t = [({word:(word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]
# 훈련
classifier = nltk.NaiveBayesClassifier.train(t)
classifier.show_most_informative_features()
# hate가 없을 때(False) pos일 확률이 1.7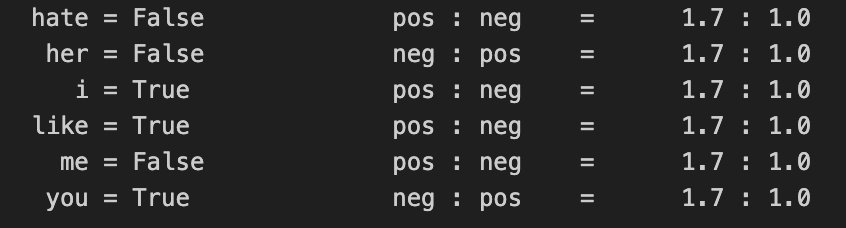
# 테스트
test_sentence = "i like MeRui"
test_sentence_features = {
word.lower() : (word in word_tokenize(test_sentence.lower())) for word in all_words
}
classifier.classify(test_sentence_features) # pos한글
-형태소 분석 필수다.
pos_tagger = Okt()
train = [
("메리가 좋아", "pos"),
("고양이도 좋아", "pos"),
("난 수업이 지루해", "neg"),
("메리는 이쁜 고양이야", "pos"),
("난 마치고 메리랑 놀거야", "pos")
]
# 함수 만들기(단어/조사 출력)
def tokenize(doc):
return ["/".join(t) for t in pos_tagger.pos(doc, norm=True, stem=True)]
# 적용
train_docs = [(tokenize(row[0]), row[1]) for row in train]
tokens = [t for d in train_docs for t in d[0]]
# 함수 만들기(단어/조사/TF 출력)
def term_exists(doc):
return {word: (word in set(doc)) for word in tokens}
# 적용
train_xy = [(term_exists(d), c) for d, c in train_docs] # 훈련
classifier = nltk.NaiveBayesClassifier.train(train_xy)
classifier.show_most_informative_features()
# 테스트
test_sentence = [("난 수업이 마치면 메리랑 놀거야")]
test_docs = pos_tagger.pos(test_sentence[0])
test_sentence_features = {word: (word in tokens) for word in test_docs}
classifier.classify(test_sentence_features) # pos유사도
CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=1)
t = Okt()
contents = [
'상처받은 아이들은 너무 일찍 커버려',
'내가 상처받은 거 아는 사람 불편해',
'잘 사는 사람들은 좋은 사람 되기 쉬워',
'아무 일도 아니야 괜찮아'
]
# 형태소 분석
contents_tokens = [t.morphs(row) for row in contents]
# 다시 문장으로 합치기
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence += ' ' + word
contents_for_vectorize.append(sentence)
X = vectorizer.fit_transform(contents_for_vectorize)
num_sampels, num_features = X.shape # (4, 17)
vectorizer.get_feature_names_out()
# array(['괜찮아', '너무', '되기', '받은', '불편해', '사는', '사람', '상처', '쉬워', '아는',
'아니야', '아무', '아이', '일도', '일찍', '좋은', '커버'], dtype=object) # 17개
# X.toarray().transpose()# 테스트
new_post = ['상처받기 싫어 괜찮아']
new_post_tokens = [t.morphs(row) for row in new_post]
# 다시 문장으로 합치기
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence += ' ' + word
new_post_for_vectorize.append(sentence)
# 벡터로 표현
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()
# 함수만들기(거리 구하기)
import scipy as sp
def dis_raw(v1, v2):
delta = v1 - v2
return sp.linalg.norm(delta.toarray())
# 적용
dist = [dis_raw(each, new_post_vec) for each in X]
print('Best post is ', dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is -->', new_post )
print('Best dist post is -->', contents[dist.index(min(dist))])
# Best post is 3 , dist = 2.0
# Test post is --> ['상처받기 싫어 괜찮아']
# Best dist post is --> 아무 일도 아니야 괜찮아TfidfVectorizer(가중치)
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=1, decode_error='ignore')
X = vectorizer.fit_transform(contents_for_vectorize)
# X.toarray().transpose()
new_post_vec = vectorizer.transform(new_post_for_vectorize)
# new_post_vec.toarray()
# 함수만들기(두 벡터의 크기를 1로 변경 후 거리 측정)
def dist_norm(v1, v2):
v1_normalized = v1 / sp.linalg.norm(v1.toarray())
v2_normalized = v2 / sp.linalg.norm(v2.toarray())
delta = v1_normalized - v2_normalized
return sp.linalg.norm(delta.toarray())
# 적용
dist = [dist_norm(each, new_post_vec) for each in X]
print('Best post is ', dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is -->', new_post )
print('Best dist post is -->', contents[dist.index(min(dist))])
# Best post is 3 , dist = 1.102139611977359
# Test post is --> ['상처받기 싫어 괜찮아']
# Best dist post is --> 아무 일도 아니야 괜찮아유사질문 찾기(네이버API)
import urllib.request
import json
import datetime
# 함수
# url 생성 (gen_search_url)
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_disp
# 검색 결과
def get_result_openpage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print("[%s] Url Request Success" % datetime.datetime.now())
return json.loads(response.read().decode("utf-8"))
# 태그 삭제
def delete_tag(input_str):
input_str = input_str.replace("<b>", "")
input_str = input_str.replace("</b>", "")
return input_str
# 내용 추출
def get_description(pages):
contents = []
for sentences in pages['items']:
contents.append(delete_tag(sentences['description']))
return contentsclient_id = "클라이언트ID"
client_secret = "비밀번호"
# 내용 가져오기
url = gen_search_url('kin', '파이썬', 10, 10)
one_result = get_result_openpage(url)
contents = get_description(one_result)
# 형태소 분석
contents_tokens = [t.morphs(row) for row in contents]
# 다시 합치기
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence += ' ' + word
contents_for_vectorize.append(sentence)
X = vectorizer.fit_transform(contents_for_vectorize) # 테스트
new_post = ['파이썬을 배우는데 좋은 방법이 어떤 것인지 추천해주세요']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence += ' ' + word
new_post_for_vectorize.append(sentence)
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()
dist = [dis_raw(each, new_post_vec) for each in X]
print('Best post is ', dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is -->', new_post )
print('Best dist post is -->', contents[dist.index(min(dist))])
# Best post is 3 , dist = 5.744562646538029
# Test post is --> ['파이썬을 배우는데 좋은 방법이 어떤 것인지 추천해주세요']
# Best dist post is --> 점프 투 파이썬을 공부 했는데 그 다음에 무엇을 해야하나요? 파이썬 공부 로드맵 부탁드립니다...
21세기 주인공