
딥러닝
- 분류, 회귀, 물체 검출
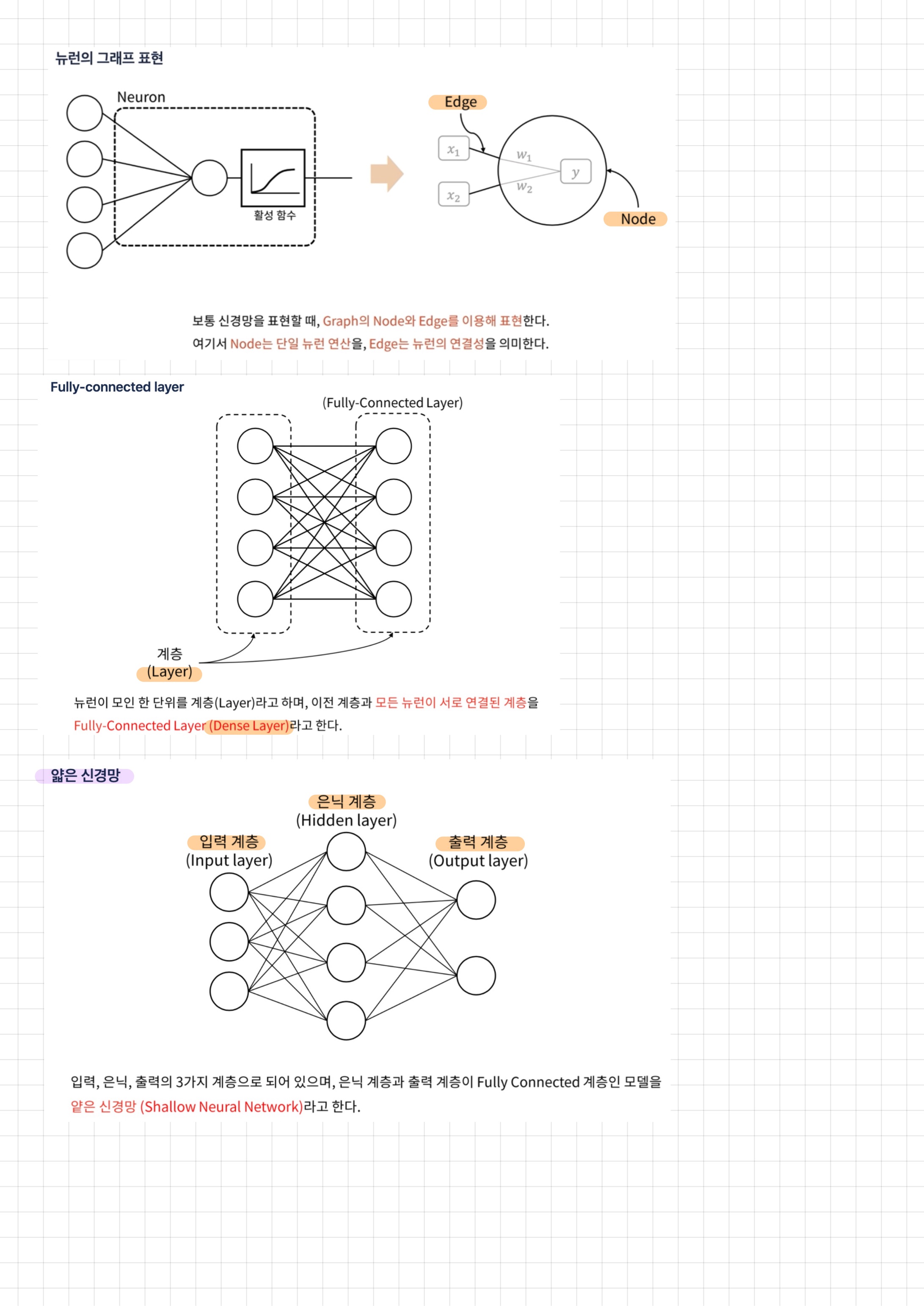
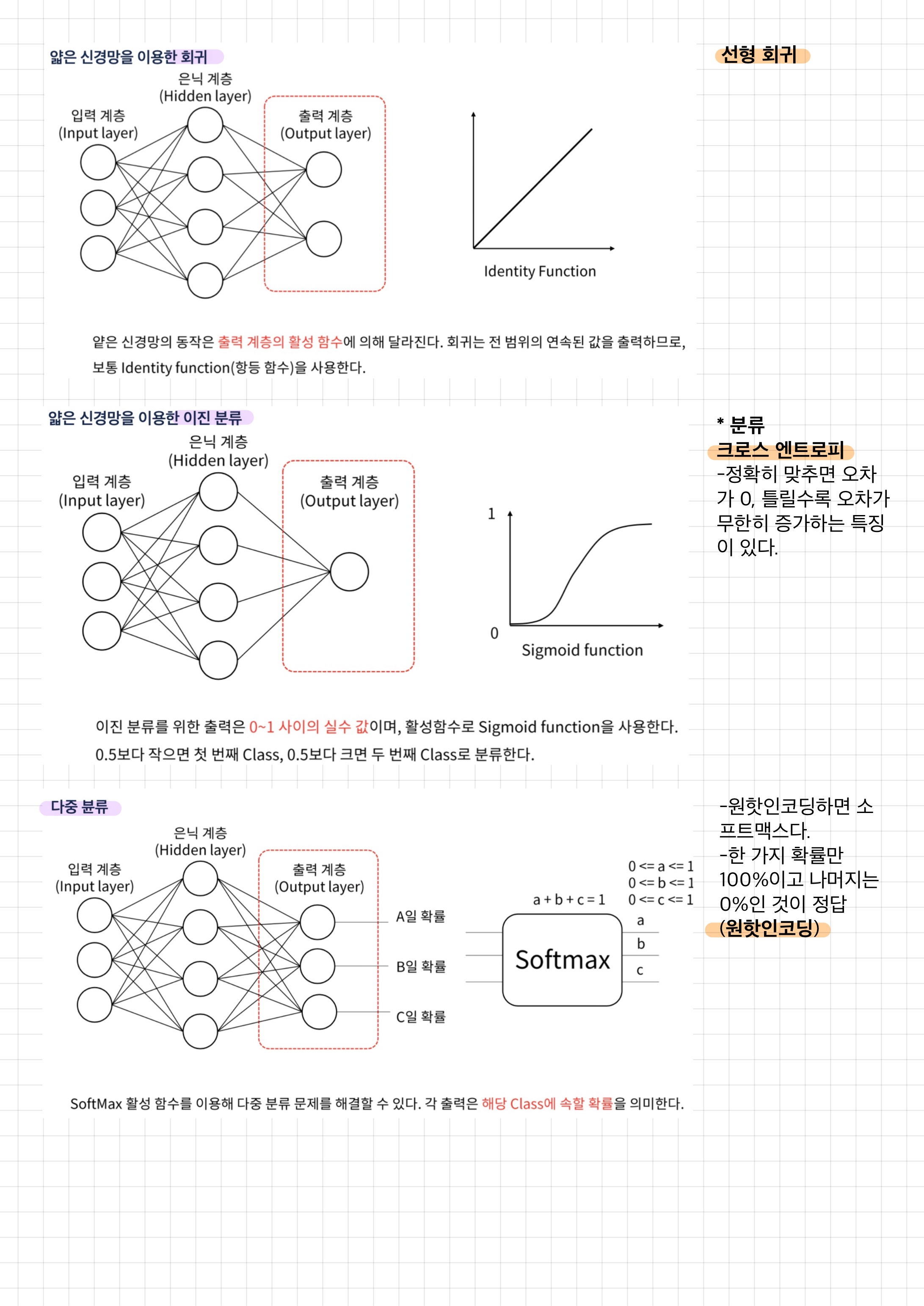

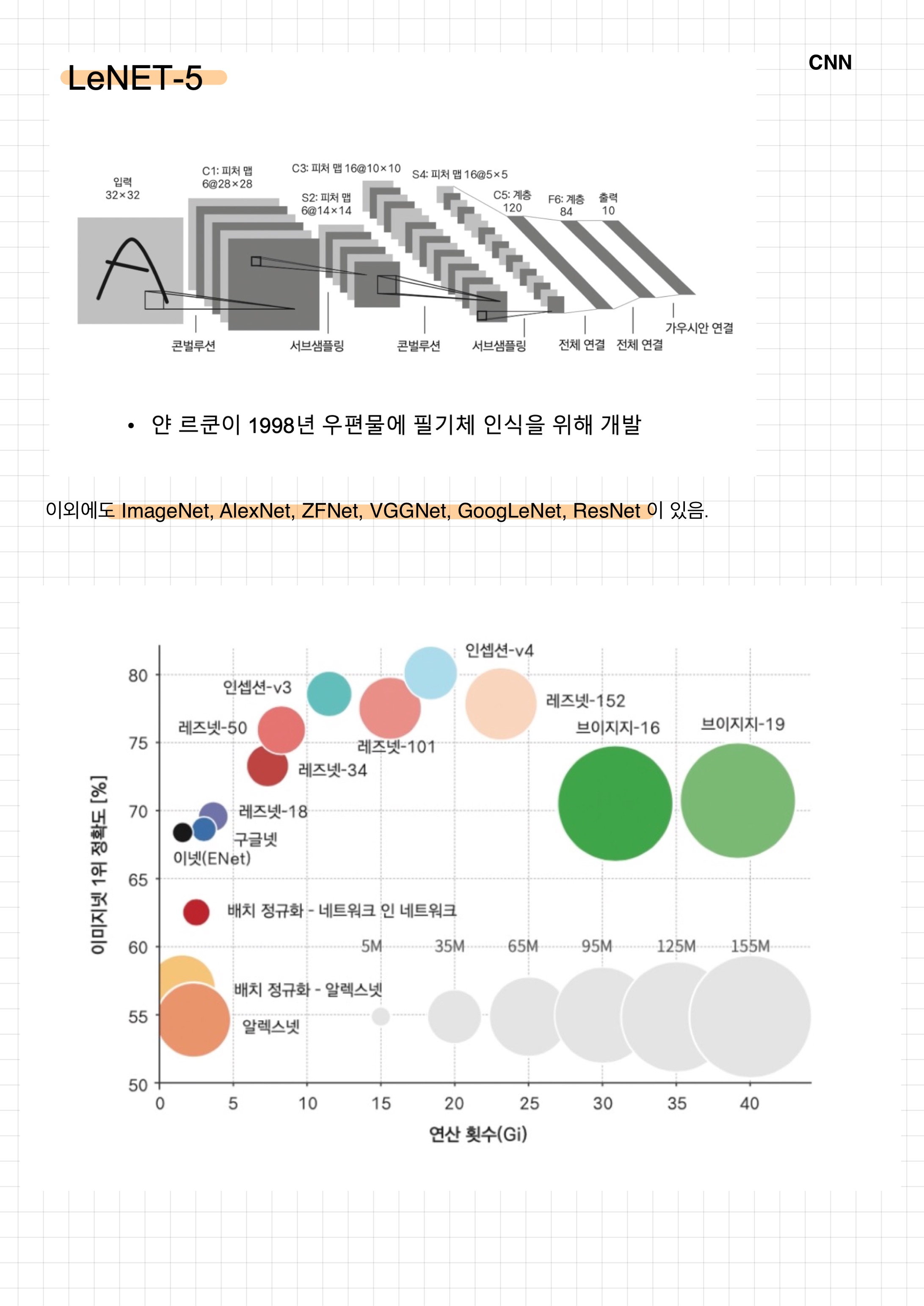
tensorflow
MNIST(CNN)
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
minst = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = minst.load_data()
X_train, X_test = X_train/255, X_test/255
X_train = X_train.reshape((60000,28,28,1))
X_test = X_test.reshape((10000,28,28,1))
model = models.Sequential([
layers.Conv2D(3, kernel_size=(3,3), strides=(1,1),
padding='same', activation='relu', input_shape=(28,28,1)),
layers.MaxPooling2D(pool_size=(2,2), strides=(2,2)),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(1000, activation='relu'),
layers.Dense(10, activation='softmax')
])
conv = model.layers[0]
conv_weights = conv.weights[0].numpy()
plt.hist(conv_weights.reshape(-1,1))
plt.xlabel('weights')
plt.ylabel('count')
plt.show()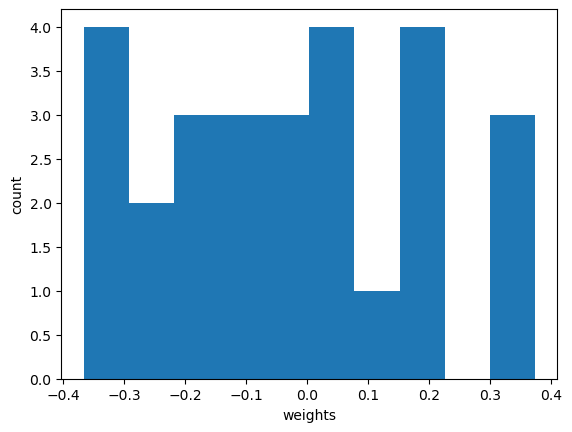
fig, ax = plt.subplots(1,3,figsize=(15,5))
for i in range(3):
ax[i].imshow(conv_weights[:,:,0,i], vmin=-0.5, vmax=0.5)
ax[i].axis('off')
plt.show()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
hist = model.fit(X_train, y_train, epochs=5, verbose=1, validation_data=(X_test, y_test))
inputs = X_train[0].reshape(-1,28,28,1)
conv_layer_output = tf.keras.Model(model.input, model.layers[0].output)
feature_maps = conv_layer_output.predict(inputs)def draw_feature_maps(n):
inputs = X_train[n].reshape(-1,28,28,1)
feature_maps = conv_layer_output.predict(inputs)
# 적용
draw_feature_maps(50)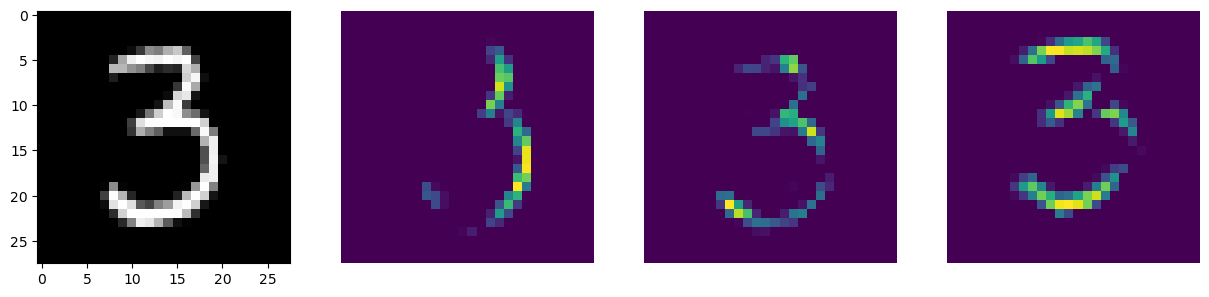
Mask man
import zipfile
import cv2
import random
import pandas as pd
import numpy as np
import os
import glob
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import Sequential, models
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
content_zip = zipfile.ZipFile('../data/maskman_archive.zip')
content_zip.extractall('../data/')
content_zip.close()path = '../data/Face Mask Dataset/'
dataset = {
'image_path' : [],
'mask_status' : [],
'where' : []
}
for where in os.listdir(path):
if where != '.DS_Store':
for status in os.listdir(path + where):
for image in glob.glob(path + where + '/' + status + '/' + '*.png'):
dataset['image_path'].append(image)
dataset['mask_status'].append(status)
dataset['where'].append(where)
dataset = pd.DataFrame(dataset)
sns.countplot(x=dataset['mask_status']);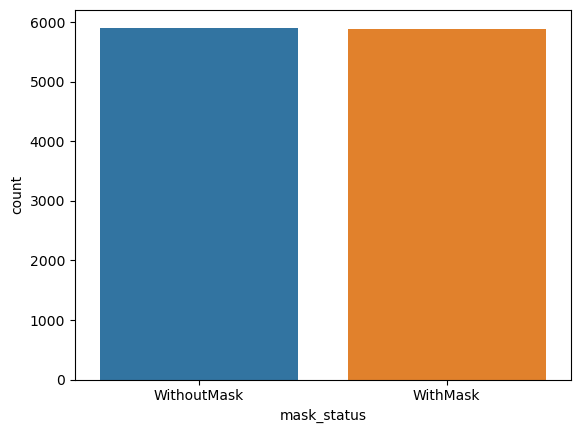
plt.figure(figsize=(15,10))
for i in range(9):
random = np.random.randint(1, len(dataset))
plt.subplot(3,3, i+1)
plt.imshow(cv2.imread(dataset.loc[random, 'image_path']))
plt.title(dataset.loc[random, 'mask_status'], size=15)
plt.xticks([])
plt.yticks([])
plt.show()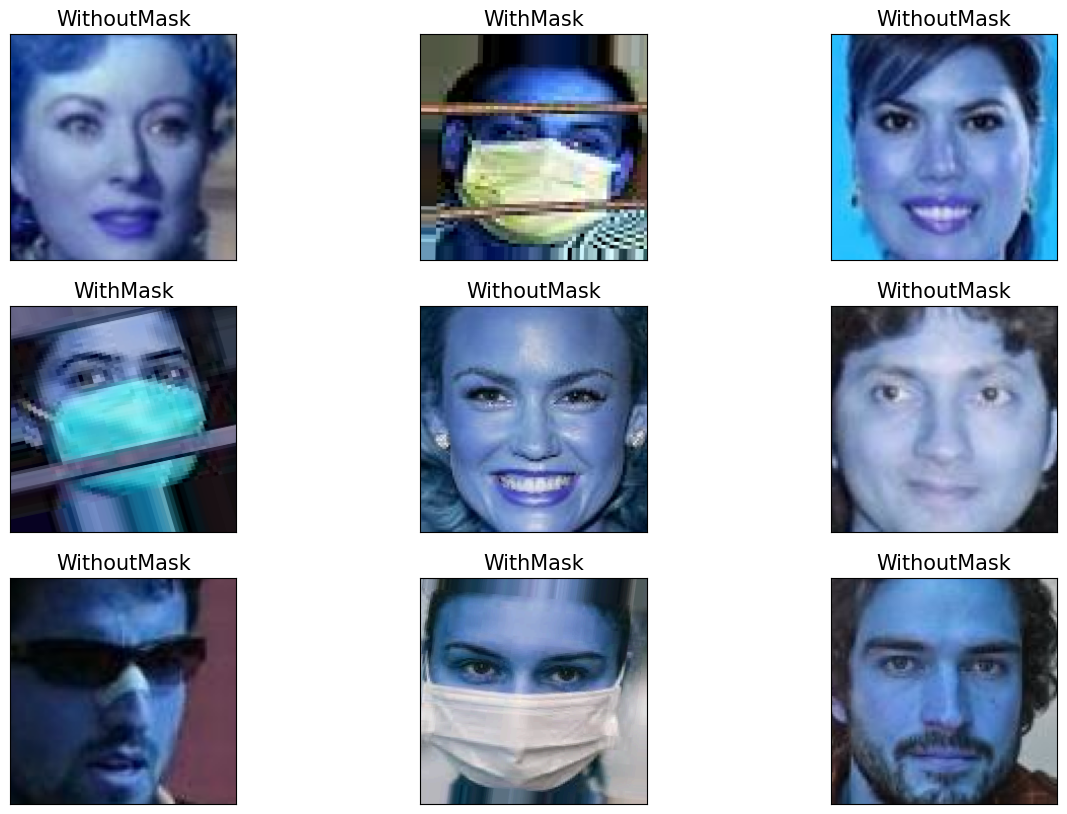
train_df = dataset[dataset['where']=='Train']
test_df = dataset[dataset['where']=='Test']
validation_df = dataset[dataset['where']=='Validation']
plt.figure(figsize=(15,5))
plt.subplot(1,3,1)
sns.countplot(x=train_df['mask_status'])
plt.title('Training Dataset', size=10)
plt.subplot(1,3,2)
sns.countplot(x=test_df['mask_status'])
plt.title('Test Dataset', size=10)
plt.subplot(1,3,3)
sns.countplot(x=validation_df['mask_status'])
plt.title('Vlidation Dataset', size=10)
plt.show()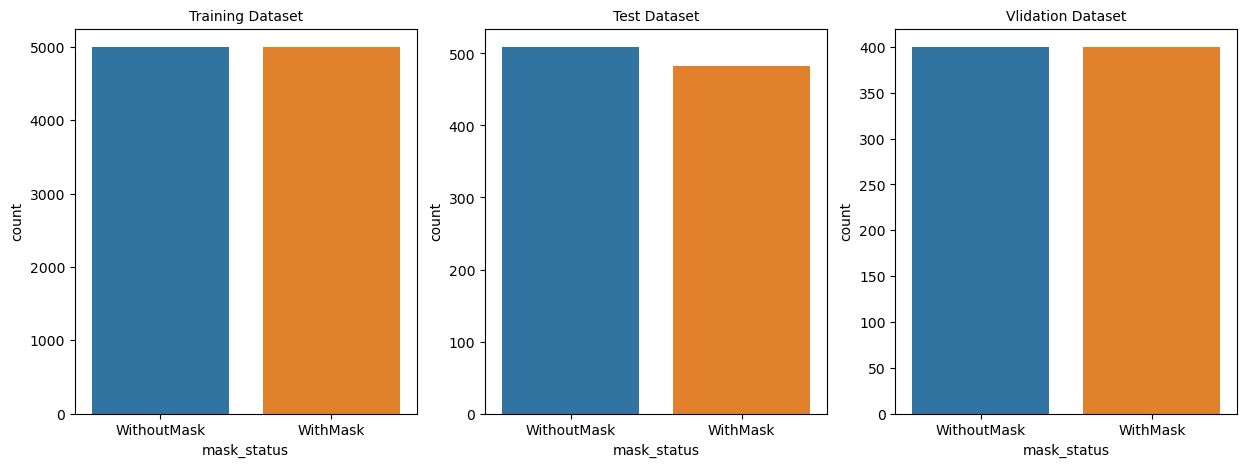
train_df = train_df.reset_index(drop=True)
data = []
image_size = 150
for i in range(len(train_df)):
img_array = cv2.imread(train_df['image_path'][i], cv2.IMREAD_GRAYSCALE)
new_image_array = cv2.resize(img_array, (image_size,image_size))
# 라벨
if train_df['mask_status'][i] == 'WithMask':
data.append([new_image_array, 1])
else:
data.append([new_image_array, 0])
np.random.shuffle(data)
fig, ax = plt.subplots(2,3, figsize=(10,6))
for row in range(2):
for col in range(3):
image_index = row * 100 + col
ax[row, col].axis('off')
ax[row, col].imshow(data[image_index][0], cmap='gray')
if data[image_index][1] == 0:
ax[row, col].set_title('Without Mask')
else:
ax[row, col].set_title('With Mask')
딥러닝
X = []
y = []
for image in data:
X.append(image[0])
y.append(image[1])
X = np.array(X)
y = np.array(y)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=13)
model = models.Sequential([
layers.Conv2D(32, kernel_size=(5,5), strides=(1,1),
padding='same', activation='relu', input_shape=(150,150,1)),
layers.MaxPooling2D(pool_size=(2,2), strides=(2,2)),
layers.Conv2D(64, (2,2), activation='relu', padding='same'),
layers.MaxPooling2D(pool_size=(2,2), strides=(2,2)),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(1000, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=['accuracy']
)
X_train = X_train.reshape(-1, 150, 150, 1)
X_val = X_val.reshape(-1, 150, 150, 1)
history = model.fit(X_train, y_train, epochs=4, batch_size=32)
model.evaluate(X_val, y_val) # [0.09353695064783096, 0.9745000004768372]
prediction = (model.predict(X_val) > 0.5).astype('int32')
print(classification_report(y_val, prediction))
print(confusion_matrix(y_val, prediction))오답 확인
wrong_result = []
for n in range(0, len(y_val)):
if prediction[n] != y_val[n]:
wrong_result.append(n)
len(wrong_result) # 51
samples = random.choices(population=wrong_result, k=6)
plt.figure(figsize=(14,10))
for idx, n in enumerate(samples):
plt.subplot(3,2, idx+1)
plt.imshow(X_val[n].reshape(150,150), interpolation='nearest')
plt.title(prediction[n])
plt.axis('off')
plt.show();
OX분류
import numpy as np
import matplotlib.pyplot as plt
import keras
from glob import glob
from skimage import color
from skimage.io import imread, imsave
from skimage.transform import rescale, resize
from keras.models import Sequential
from keras.layers import Dense, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.preprocessing.image import ImageDataGeneratornp.random.seed(13)
train_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_directory(
'/content/drive/MyDrive/ds_study/data/OX_clf/train',
target_size=(28,28),
batch_size=3,
class_mode='categorical'
)
test_datagen = ImageDataGenerator(rescale = 1./255)
test_generator = test_datagen.flow_from_directory(
'/content/drive/MyDrive/ds_study/data/OX_clf/test',
target_size=(28,28),
batch_size=3,
class_mode='categorical'
)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3,3), activation='relu', input_shape=(28,28,3)))
model.add(Conv2D(64, kernel_size=(3,3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(2, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
hist = model.fit_generator( # ImageDataGenerator 쓸 때는 model.fit_generator
train_generator,
steps_per_epoch=15,
epochs=50,
validation_data=test_generator,
validation_steps=5
)
plt.figure(figsize=(12,6))
plt.plot(hist.history['loss'], label='loss')
plt.plot(hist.history['val_loss'], label='val_loss')
plt.plot(hist.history['accuracy'], label='accuracy')
plt.plot(hist.history['val_accuracy'], label='val_accuracy')
plt.legend()
plt.show()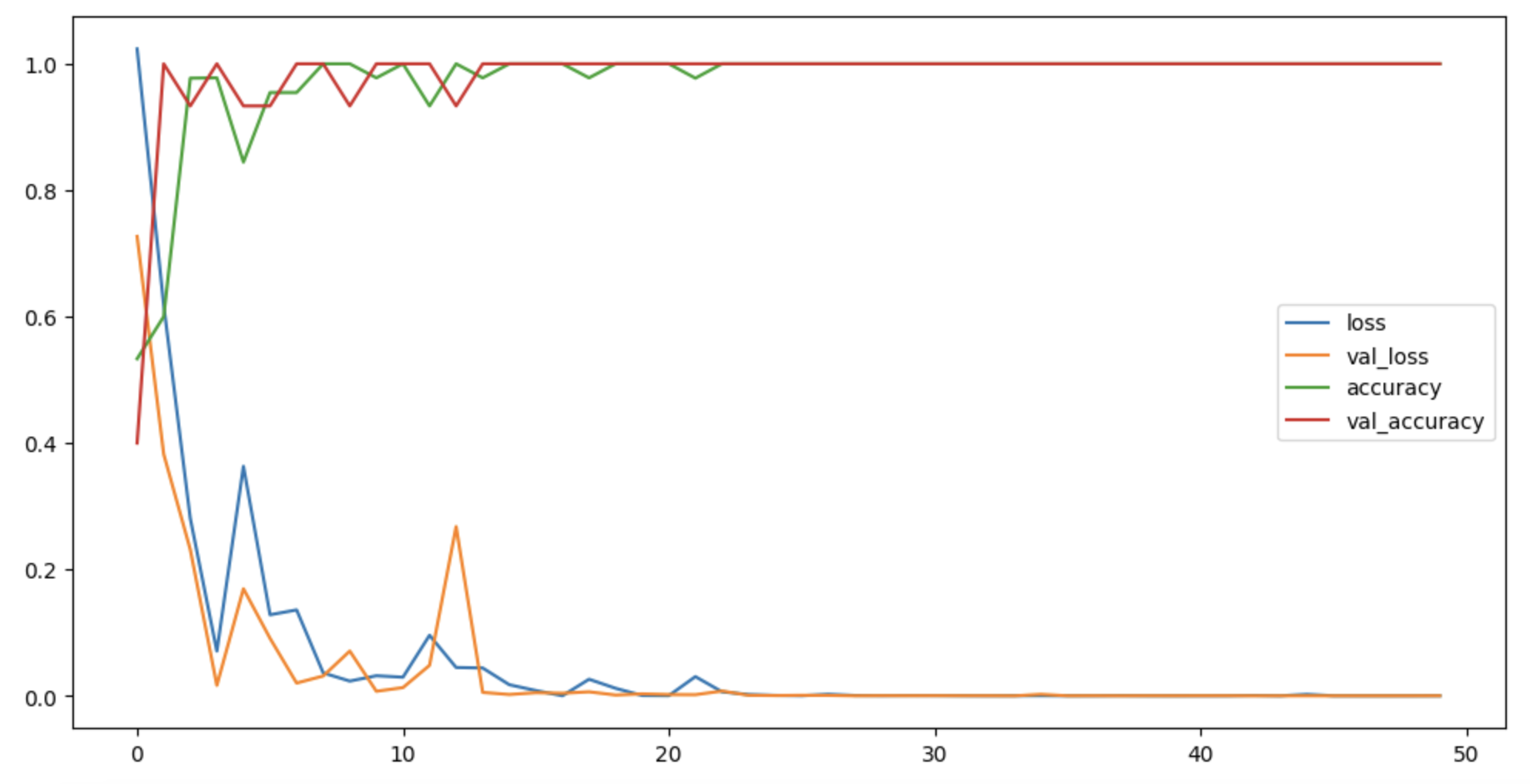
scores = model.evaluate(test_generator, steps=5)
print('%s: %.2f%%' %(model.metrics_names[1], scores[1]*100))
# accuracy: 100.00%
model.predict(test_generator)
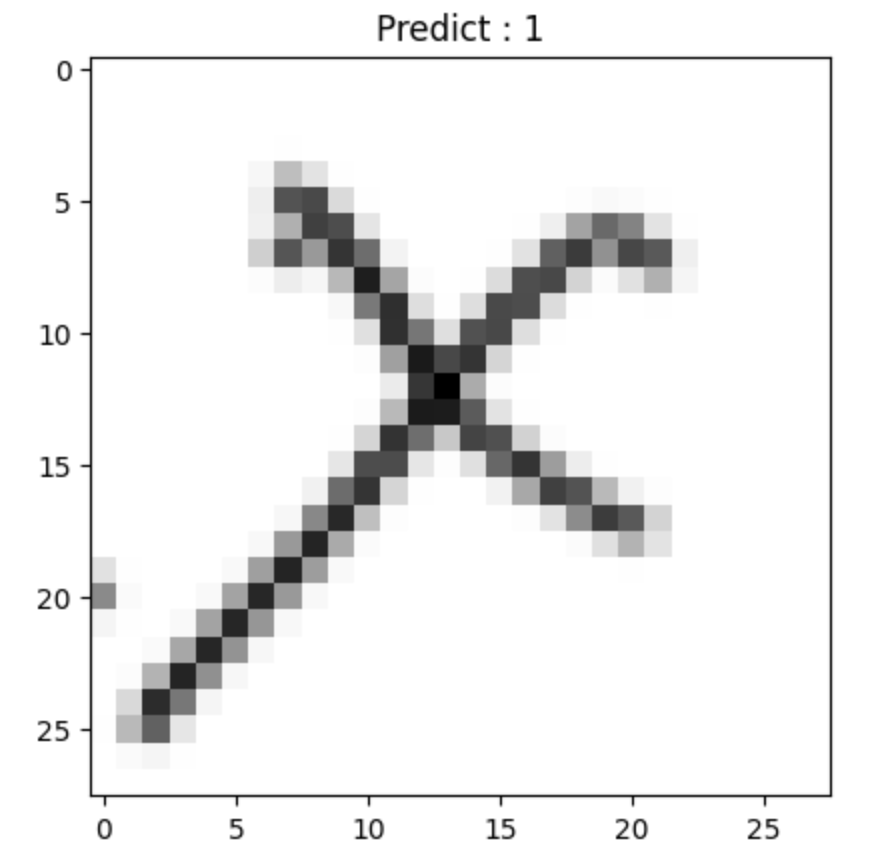
def show_prediction_result(n):
img = imread(test_generator.filepaths[n])
pred = model.predict(np.expand_dims(color.gray2rgb(img), axis=0))
title = 'Predict : ' + str(np.argmax(pred))
plt.imshow(img/255., cmap='gray')
plt.title(title)
plt.show()
show_prediction_result(1)
show_prediction_result(40)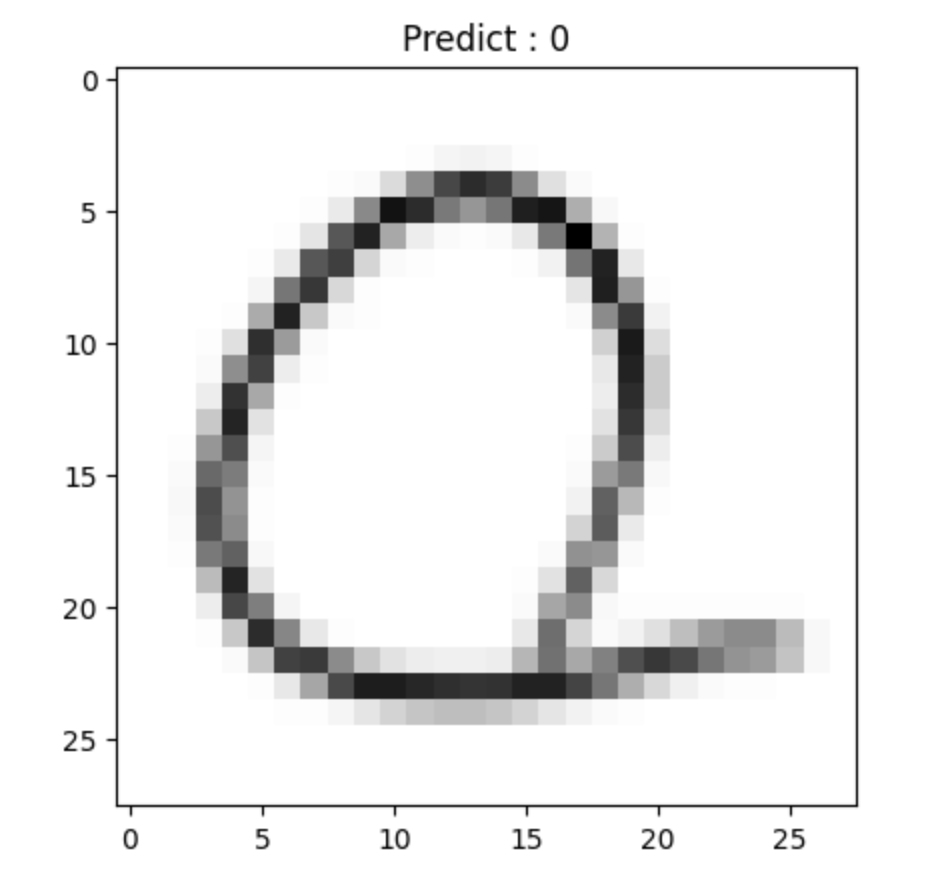
pytorch
유방암
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optimfrom sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
df['class'] = cancer.target
cols = ['mean radius', 'mean texture', 'mean smoothness', 'mean compactness', 'mean concave points',
'worst radius', 'worst texture', 'worst smoothness', 'worst compactness', 'worst concave points',
'class']
# data
data = torch.from_numpy(df[cols].values).float()
data.shape # torch.Size([569, 11])
x = data[:, :-1]
y = data[:, -1:]
print(x.shape, y.shape)
# torch.Size([569, 10]) torch.Size([569, 1])class MyModule(nn.Module):
def __init__(self, input_dim, output_dim):
self.input_dim = input_dim
self.output_dim = output_dim
# nn.Module 속성 상속
super().__init__()
self.linear = nn.Linear(input_dim, output_dim)
self.act = nn.Sigmoid()
def forward(self, x):
y = self.act(self.linear(x))
return yn_epochs = 20000
learning_rate = 1e-2
print_interval = 10000
model = MyModule(input_dim=x.size(-1), output_dim=y.size(-1))
crit = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
for i in range(n_epochs):
y_hat = model(x)
loss = crit(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % print_interval == 0:
print('Epoch %d: loss=%.4e' % (i+1, loss))correct_cnt = (y == (y_hat > .5)).sum()
total_cnt = float(y.size(0))
print('Accuracy: %.4f' %(correct_cnt / total_cnt))
# Accuracy: 0.9192df = pd.DataFrame(torch.cat([y, y_hat], dim=1).detach().numpy(),
columns=["y", "y_hat"])
sns.histplot(df, x='y_hat', hue='y', bins=50, stat='probability')
plt.show()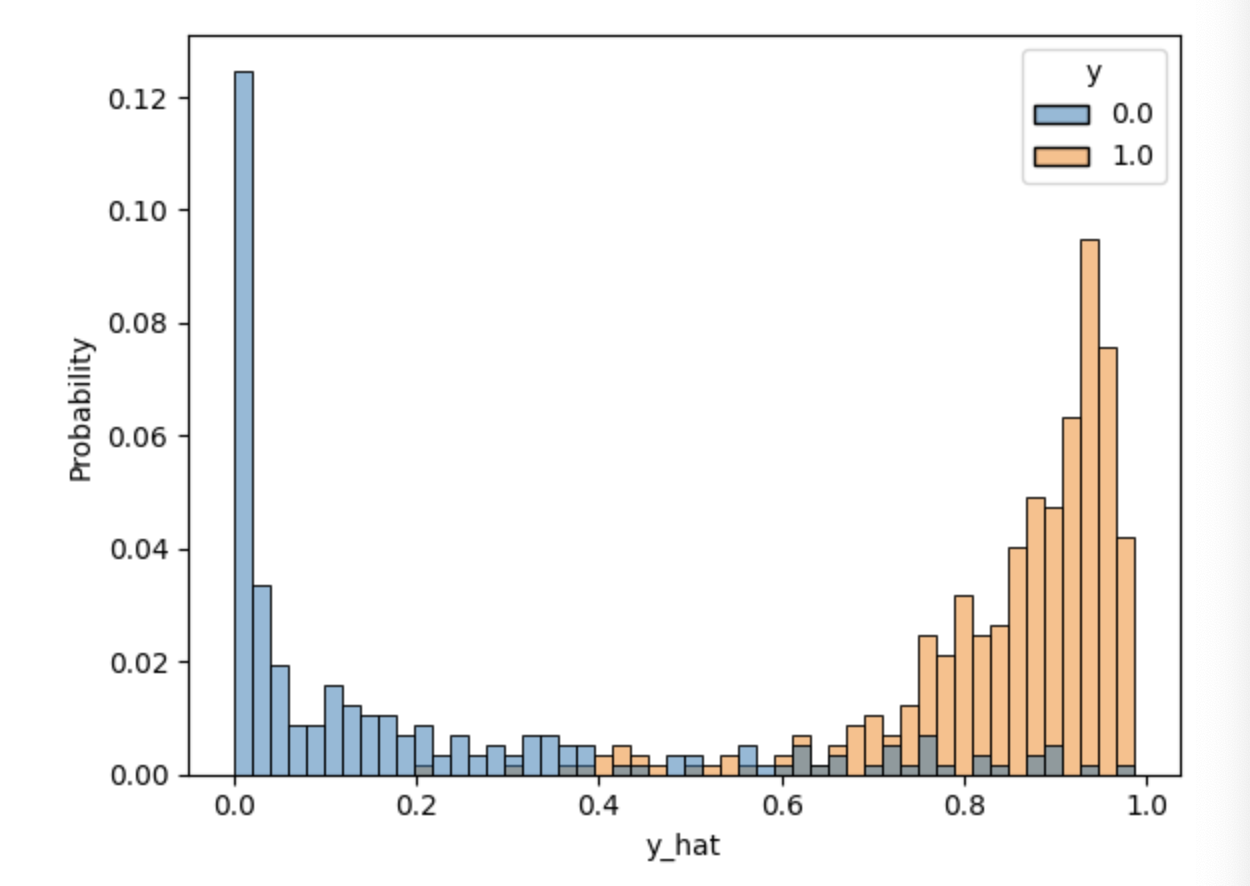
MNIST
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
is_cuda = torch.cuda.is_available()
device = torch.device('cuda' if is_cuda else 'cpu')
batch_size = 50
learning_rate = 0.0001
epoch_num = 15
train_data = datasets.MNIST(root = './data',
train = True,
download = True,
transform = transforms.ToTensor())
test_data = datasets.MNIST(root = './data',
train = False,
download = True,
transform = transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset = train_data,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_data,
batch_size = batch_size,
shuffle = True)
image, label = train_data[0]
print(image.shape, label) # (torch.Size([1, 28, 28]), 5)
plt.imshow(image.squeeze().numpy(), cmap='gray') # squeeze(): 크기가 1인 차원 제거
plt.title('label : %s' %label)
plt.show()
클래스
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1, padding='same')
self.conv2 = nn.Conv2d(32, 64, 3, 1, padding='same')
self.dropout = nn.Dropout2d(0.25)
self.fc1 = nn.Linear(3136, 1000)
self.fc2 = nn.Linear(1000, 10)
# nn.Conv2d(입력의 채널수, 32개채널 출력, kernelSize, strides, padding)
# 28 14 -> '64 7'
# nn.Linear(3136, 1000) # 7 * 7 * 64 = 3136
#입력 #출력
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output학습
model = CNN().to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
model.train()
i = 1
for epoch in range(epoch_num):
# 배치
for data, target in train_loader:
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if i%1000 == 0:
print(i, loss.item())
i += 1평가
model.eval()
correct = 0
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
output = model(data)
prediction = output.data.max(1)[1]
correct += prediction.eq(target.data).sum()
print(correct / 10000)
# tensor(0.9915, device='cuda:0')
21세기 주인공