
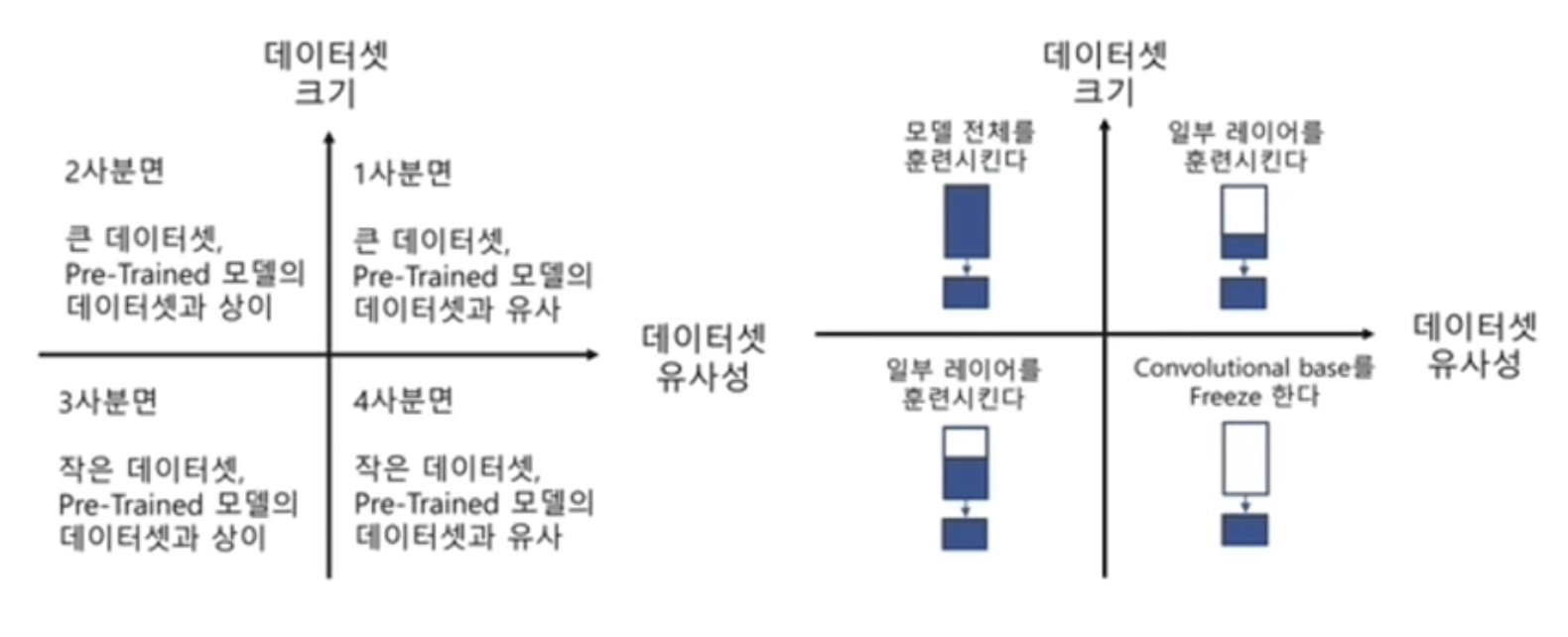
전이학습
- fine-tunning, 미세조정
- resNet, MobileNetV2


pytorch
식물잎 사진으로 질병 분류
import os
import shutil
import math
import time
import copy
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as transforms
from google.colab import drive
from torchvision import models
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torch.optim import lr_scheduler데이터 정리를 위한 목록 및 폴더 생성
drive.mount('/content/drive')
!unzip -qq '/content/drive/MyDrive/plants_dataset.zip' -d './dataset'
original_dataset_dir = './dataset'
classes_list = os.listdir(original_dataset_dir)
base_dif = './splitted'
os.mkdir(base_dif)
train_dir = os.path.join(base_dif, 'train')
os.mkdir(train_dir)
val_dir = os.path.join(base_dif, 'val')
os.mkdir(val_dir)
test_dir = os.path.join(base_dif, 'test')
os.mkdir(test_dir)
# 폴더 생성
for cls in classes_list:
os.mkdir(os.path.join(train_dir, cls))
os.mkdir(os.path.join(val_dir, cls))
os.mkdir(os.path.join(test_dir, cls))
# 폴더에 이미지파일 분배
for cls in classes_list:
path = os.path.join(original_dataset_dir, cls)
fnames = os.listdir(path)
train_size = math.floor(len(fnames) * 0.6)
val_size = math.floor(len(fnames) * 0.2)
test_size = math.floor(len(fnames) * 0.2)
# train
train_fnames = fnames[:train_size]
print('Train size(', cls, '): ', len(train_fnames))
for fname in train_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(train_dir, cls), fname)
shutil.copyfile(src, dst)
# validation
val_fnames = fnames[train_size:(val_size+train_size)]
print('Val size(', cls, '): ', len(val_fnames))
for fname in val_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(val_dir, cls), fname)
shutil.copyfile(src, dst)
# test
test_fnames = fnames[(val_size+train_size):(val_size+train_size+test_size)]
print('Test size(', cls, '): ', len(test_fnames))
for fname in train_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(test_dir, cls), fname)
shutil.copyfile(src, dst)학습 준비
is_cuda = torch.cuda.is_available()
device = torch.device('cuda' if is_cuda else 'cpu')
batch_size = 256
epoch_num = 30
# ImageFolder : 폴더 이름을 라벨로 봄
transform_base = transforms.Compose([transforms.Resize((64,64)), transforms.ToTensor()])
train_dataset = ImageFolder(root='./splitted/train', transform=transform_base)
val_dataset = ImageFolder(root='./splitted/val', transform=transform_base)
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True,
num_workers=4)
val_loader = torch.utils.data.DataLoader(dataset = val_dataset,
batch_size = batch_size,
shuffle = True,
num_workers=4)클래스 & 함수
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.pool = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.conv3 = nn.Conv2d(64, 64, 3, padding=1)
self.fc1 = nn.Linear(4096, 512)
self.fc2 = nn.Linear(512, 33)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p=0.25, training=self.training)
x = self.conv2(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p=0.25, training=self.training)
x = self.conv3(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p=0.25, training=self.training)
x = x.view(-1, 4096)
x = self.fc1(x)
x = F.relu(x)
x = F.dropout(x, p=0.5, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)def train(model, train_loader, optimizer):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
def evaluate(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuracy = 100. * correct / len(test_loader.dataset)
return test_loss, test_accuracy
def train_baseline(model, train_loader, val_loader, optimizer, num_epochs=30):
best_acc = 0.0
best_model_wts = copy.deepcopy(model.state_dict())
for epoch in range(1, num_epochs+1):
since = time.time()
train(model, train_loader, optimizer)
train_loss, train_acc = evaluate(model, train_loader)
val_loss, val_acc = evaluate(model, val_loader)
if val_acc > best_acc:
best_acc = val_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('------------- epoch {} --------------'.format(epoch))
print('train Loss: {:.4f}, Accuracy: {:.2f}%'.format(train_loss, train_acc))
print('val Loss: {:.4f}, Accuracy: {:.2f}%'.format(val_loss, val_acc))
print('Completed in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
model.load_state_dict(best_model_wts)
return model
def train_resnet(model, criterion, optimizer, scheduler, num_epochs=25):
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('------------- epoch {} --------------'.format(epoch+1))
since = time.time()
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('Completed in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:.4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
return model학습
model_base = Net().to(device)
optimizer = optim.Adam(model_base.parameters(), lr=0.001)
base = train_baseline(model_base, train_loader, val_loader, optimizer, 30)
# ------------- epoch 30 --------------
# train Loss: 0.0513, Accuracy: 98.74%
# val Loss: 0.2114, Accuracy: 93.25%
torch.save(base, 'baseline.pt')전이학습
data_transforms = {
'train' : transforms.Compose([transforms.Resize([64,64]), # 전처리
transforms.RandomHorizontalFlip(), # 상하좌우로 이미지 반전(랜덤하게)
transforms.RandomVerticalFlip(),
transforms.RandomCrop(52),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), # rgb 색상값을 Normalize
'val' : transforms.Compose([transforms.Resize([64,64]),
transforms.RandomCrop(52),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ])
}
data_dif = './splitted'
image_datasets = {x: ImageFolder(root=os.path.join(data_dif, x),
transform=data_transforms[x]) for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=batch_size,
shuffle=True,
num_workers=4) for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
# 전이학습
# pretrained=True : 학습이 완료된 weight를 가져옴
# pretrained=False : 구조만 가져옴
resnet = models.resnet50(pretrained=True)
num_ftrs = resnet.fc.in_features
resnet.fc = nn.Linear(num_ftrs, 33)
resnet = resnet.to(device)
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.Adam(filter(lambda p : p.requires_grad, resnet.parameters()), lr=0.001)
# filter(lambda p : p.requires_grad, resnet.parameters()
# : 마지막 33개 레이어는 학습 안 되어 있기 때문에 주는 옵션
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
# 7 epoch마다 0.1씩 learning_rate을 감소시킴
ct = 0
for child in resnet.children():
ct += 1
if ct < 6: # 6번레이어부터 학습
for param in child.parameters():
param.requires_grad = False
model_resnet50 = train_resnet(resnet, criterion, optimizer_ft, exp_lr_scheduler, 25)
# 모델 저장
torch.save(model_resnet50, 'resnet50.pt')테스트
transform_resNet = transforms.Compose([
transforms.Resize([64,64]),
transforms.RandomCrop(52),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ])
test_resNet = ImageFolder(root='./splitted/test', transform=transform_resNet)
test_loader_resNet = torch.utils.data.DataLoader(test_resNet,
batch_size=batch_size,
shuffle=True,
num_workers=4)
resnet50 = torch.load('resnet50.pt')
resnet50.eval()
test_loss, test_accuracy = evaluate(resnet50, test_loader_resNet)
print('ResNet test acc: ', test_accuracy)
# ResNet test acc: 99.75822251865438텐서플로우
cats vs dogs
import os
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import matplotlib.pyplot as plt
from __future__ import absolute_import, division, print_function, unicode_literals
tfds.disable_progress_bar()
keras = tf.keras(raw_train, raw_validation, raw_test), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True # 데이터가 라벨과 함께 튜플 형태로 저장
)
# 메타정보에서 라벨 이름 가져오기
get_label_name = metadata.features['label'].int2str
# 사진 하나만 확인
for image, label in raw_train.take(1):
plt.imshow(image)
# plt.title(label.numpy()) # 1
plt.title(get_label_name(label))
함수
IMG_SIZE = 160 # 모든 이미지는 160x160
def format_example(image, label):
image = tf.cast(image, tf.float32)
image = (image/127.5) - 1 # -1 ~ 1 사이로.
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
return image, label모델 준비
train = raw_train.map(format_example)
validation = raw_validation.map(format_example)
test = raw_test.map(format_example)
BATCH_SIZE = 32
SHUFFLE_BUFFER_SIZE = 1000
train_batches = train.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
validation_batches = validation.batch(BATCH_SIZE)
test_batches = test.batch(BATCH_SIZE)
# 확인
for image_batch, label_batch in train_batches.take(1):
pass
image_batch.shape # TensorShape([32, 160, 160, 3])
IMG_SHAPE = (IMG_SIZE, IMG_SIZE, 3)
# 1. base_model
# ImageNet 데이터셋을 사용해 사전 훈련된 모델 사용
# include_top=False : 내가 학습할 모델의 클래스 숫자는 다르니깐 False
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
feature_batch = base_model(image_batch)
print(feature_batch.shape) # (32, 5, 5, 1280)
# 이 특징 추출기는 각 160x160x3 이미지를 5x5x1280개의 특징 블록으로 변환
base_model.trainable = False
# base_model.summary()
# 2. global_average_layer
# GlobalAveragePooling2D : 채널마다의 평균값 뽑아냄 -> 차원 축소
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape) # (32, 5, 5, 1280) -> (32, 1280)
# 특징을 이미지 한개 당 1280개의 요소 벡터로 변환
# 3. prediction_layer
prediction_layer = keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape) # (32, 1)전체 모델 구성
model = tf.keras.Sequential([
base_model,
global_average_layer,
prediction_layer
])
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])아무 학습을 하지 않은 현재의 성능
initial_epochs = 10
validation_steps = 20
loss0, accuracy0 = model.evaluate(validation_batches, steps = validation_steps)
# loss: 0.7056 - accuracy: 0.5391학습
history = model.fit(train_batches,
epochs=initial_epochs,
validation_data = validation_batches)
# loss: 0.0272 - accuracy: 0.9908
# val_loss: 0.0454 - val_accuracy: 0.9858acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8,8))
plt.subplot(2,1,1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
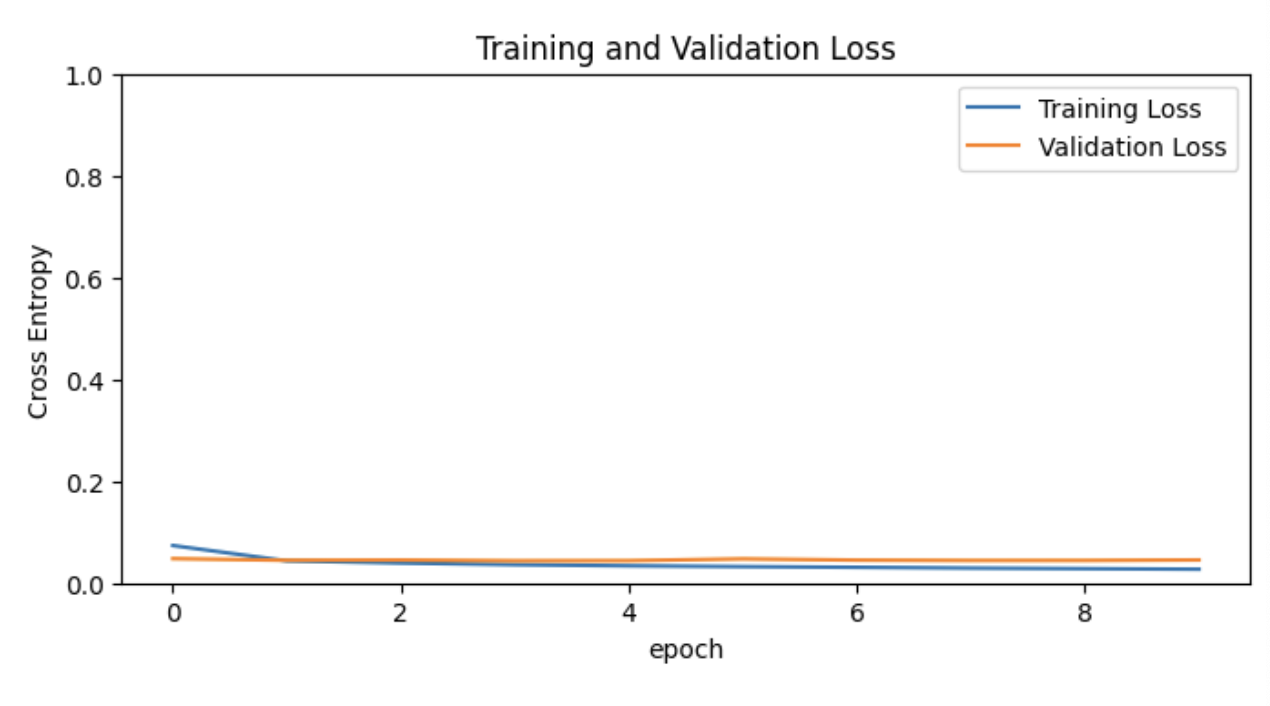
plt.figure(figsize=(8,8))
plt.subplot(2,1,2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0, 1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()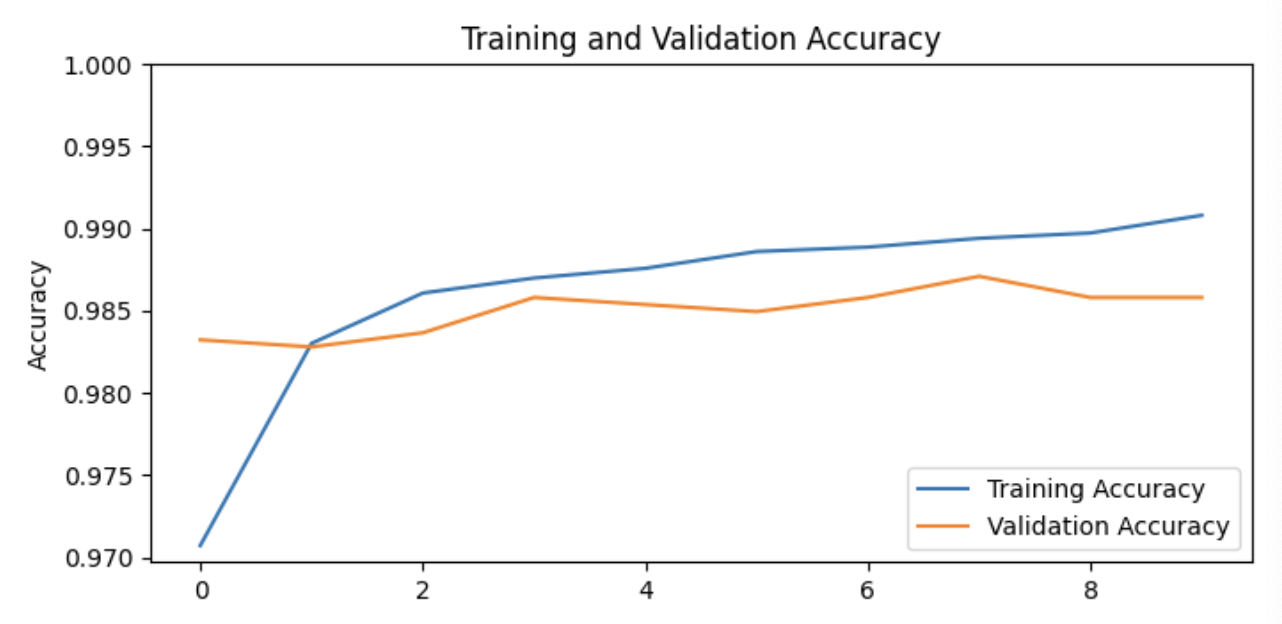
전이학습
base_model.trainable = True
print('Number of layers in the base model: ', len(base_model.layers))
# Number of layers in the base model: 154
# 100번째 층부터 튜닝가능하게 설정
find_tune_at = 100
# find_tune_at 층 이전의 모든 층을 고정
for layer in base_model.layers[:find_tune_at]:
layer.trainable = False
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(lr=base_learning_rate/10),
metrics=['accuracy'])
find_tune_epochs = 10
total_epochs = initial_epochs + find_tune_epochs # 20
# 10 부터 시작
history_find = model.fit(train_batches,
epochs=total_epochs,
initial_epoch = history.epoch[-1],
validation_data=validation_batches)
acc += history_find.history['accuracy']
val_acc += history_find.history['val_accuracy']
loss += history_find.history['loss']
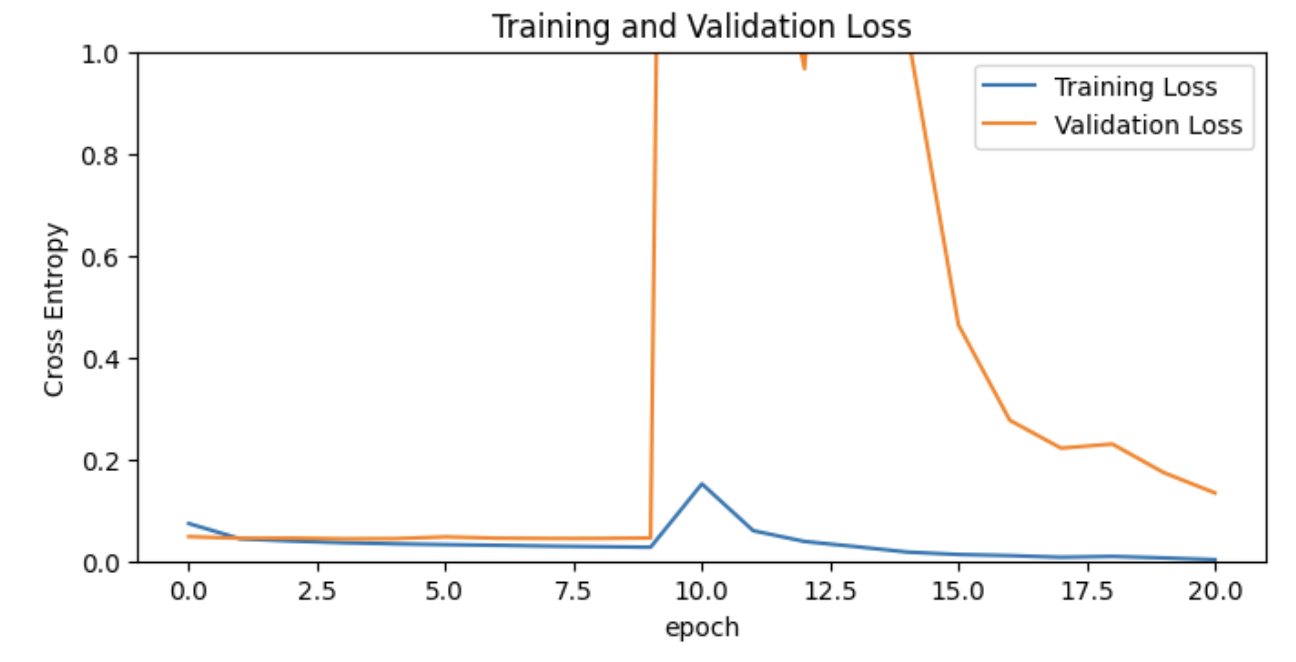
val_loss += history_find.history['val_loss']plt.figure(figsize=(8,8))
plt.subplot(2,1,1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1, initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2,1,2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1, initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()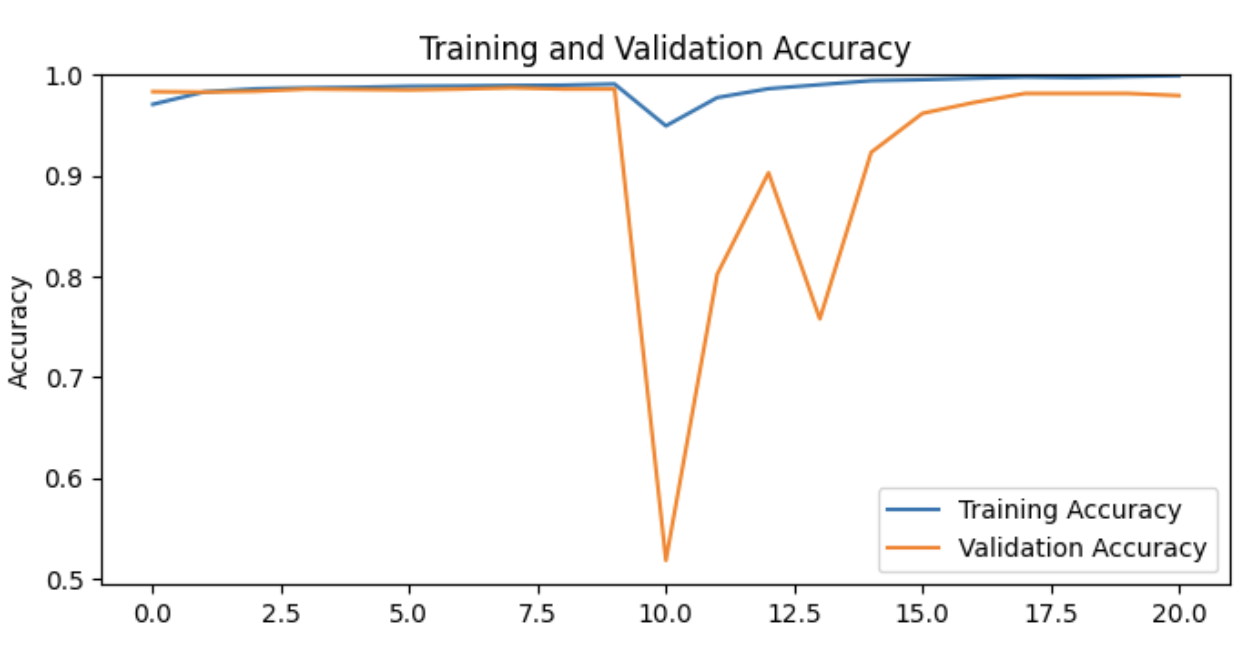
의상 맞추기
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_hub as hub
import numpy as np
import PIL.Image as Image
from tensorflow.keras import layersurl = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/2"
IMAGE_SHAPE = (224,224)
classifier = tf.keras.Sequential([
hub.KerasLayer(url, input_shape=IMAGE_SHAPE+(3,))
])이미지 하나 가져오기
url = 'https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg'
grace_hopper = tf.keras.utils.get_file('image.jpg', url)
grace_hopper = Image.open(grace_hopper).resize(IMAGE_SHAPE)
grace_hopper
정규화
grace_hopper = np.array(grace_hopper)/255.0
grace_hopper.shape (224, 224, 3)예측
result = classifier.predict(grace_hopper[np.newaxis, ...])
result.shape # (1, 1001)
predicted_class = np.argmax(result[0], axis=-1)
predicted_class # 653
# label
url = 'https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt'
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt', url)
imagenet_labels = np.array(open(labels_path).read().splitlines())
plt.imshow(grace_hopper)
plt.axis('off')
predicted_class_name = imagenet_labels[predicted_class]
_ = plt.title("Prediction: " + predicted_class_name.title())
꽃 이름 맞추기
url = 'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz'
data_root = tf.keras.utils.get_file('flower_photos', url, untar=True)
image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255)
image_data = image_generator.flow_from_directory(str(data_root), target_size=IMAGE_SHAPE)
# Found 3670 images belonging to 5 classes
for image_batch, label_batch in image_data:
print("Image batch shape: ", image_batch.shape)
print("Label batch shape: ", label_batch.shape)
break
# Image batch shape: (32, 224, 224, 3)
# Label batch shape: (32, 5)
result_batch = classifier.predict(image_batch)
result_batch.shape # (32, 1001)
predicted_class_names = imagenet_labels[np.argmax(result_batch, axis=-1)]plt.figure(figsize=(10,9))
plt.subplots_adjust(hspace=0.5)
for n in range(30):
plt.subplot(6,5,n+1)
plt.imshow(image_batch[n])
plt.title(predicted_class_names[n])
plt.axis('off)
_ = plt.suptitle("ImageNet predictions") 특징 추출
feature_extractor_url = 'https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/2'
feature_extractor_layer = hub.KerasLayer(feature_extractor_url, input_shape=(224,224,3))
feature_batch = feature_extractor_layer(image_batch)
print(feature_batch.shape) # (32, 1280)
feature_extractor_layer.trainable = False
model = tf.keras.Sequential([
feature_extractor_layer,
layers.Dense(image_data.num_classes, activation='softmax')
])
model.summary()
predictions = model(image_batch)
predictions.shape # TensorShape([32, 5])
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss='categorical_crossentropy',
metrics=['acc']
)클래스
class CollectBatchStats(tf.keras.callbacks.Callback):
def __init__(self):
self.batch_losses = []
self.batch_acc = []
def on_train_batch_end(self, batch, logs=None):
self.batch_losses.append(logs['loss'])
self.batch_acc.append(logs['acc'])
self.model.reset_metrics()모델 적용
steps_per_epoch = np.ceil(image_data.samples/image_data.batch_size)
batch_stats_callback = CollectBatchStats()
history = model.fit_generator(image_data,
epochs=2,
steps_per_epoch=steps_per_epoch,
callbacks= [batch_stats_callback])plt.figure()
plt.ylabel('Loss')
plt.xlabel('Traing steps')
plt.ylim([0,2])
plt.plot(batch_stats_callback.batch_losses);
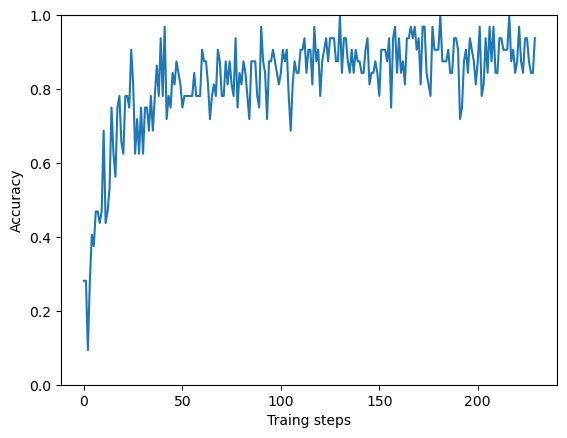
plt.figure()
plt.ylabel('Accuracy')
plt.xlabel('Traing steps')
plt.ylim([0,1])
plt.plot(batch_stats_callback.batch_acc);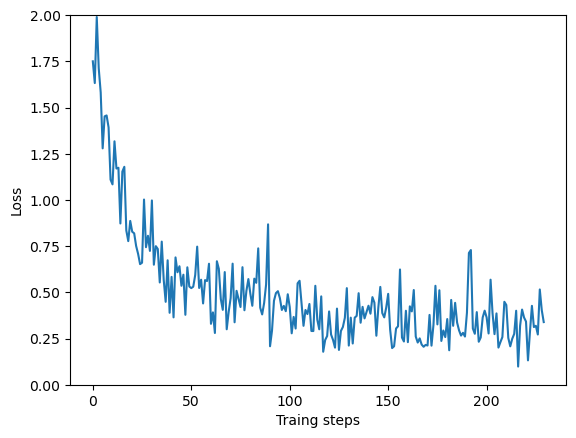
### class name 할당
class_names = sorted(image_data.class_indices.items(), key=lambda pair:pair[1])
class_names = np.array([key.title() for key, value in class_names])
predicted_batch = model.predict(image_batch)
predicted_id = np.argmax(predicted_batch, axis=-1)
predicted_label_batch = class_names[predicted_id]
label_id = np.argmax(label_batch, axis=-1)
plt.figure(figsize=(10,9))
plt.subplots_adjust(hspace=0.5)
for n in range(30):
plt.subplot(6,5,n+1)
plt.imshow(image_batch[n])
color = 'green' if predicted_id[n] == label_id[n] else 'red'
plt.title(predicted_label_batch[n].title(), color=color)
plt.axis('off')
_=plt.suptitle('Model predictions (green: correct, red: incorrect)')
모델 저장
model.save('./depplearning_flower', save_format='tf')
# 모델 불러오기
reloaded = tf.keras.models.load_model('./depplearning_flower')
result_batch = model.predict(image_batch)
reloaded_result_batch = reloaded.predict(image_batch)
# 같은 모델인지 확인
abs(reloaded_result_batch - result_batch).max()오토인코더
이미지 증강
YOLO
- darkNet
RNN
- SimpleRNN, LSTM
감성 분석

21세기 주인공