
COLAB
- command + m 누르면, 주피터노트북에서 하던 단축키 거의 다 됨
텐서플로




ImageDataGenerator
-flow_from_directory
-flow_from_DataFrame
Linear regression(가상데이터)
import tensorflow as tf
import matplotlib.pyplot as plt
tf.random.set_seed(777)W_true = 3.0
B_true = 2.0
X = tf.random.normal((500,1))
noise = tf.random.normal((500,1))
y = X * W_true + B_true + noise
plt.scatter(X, y)
plt.show()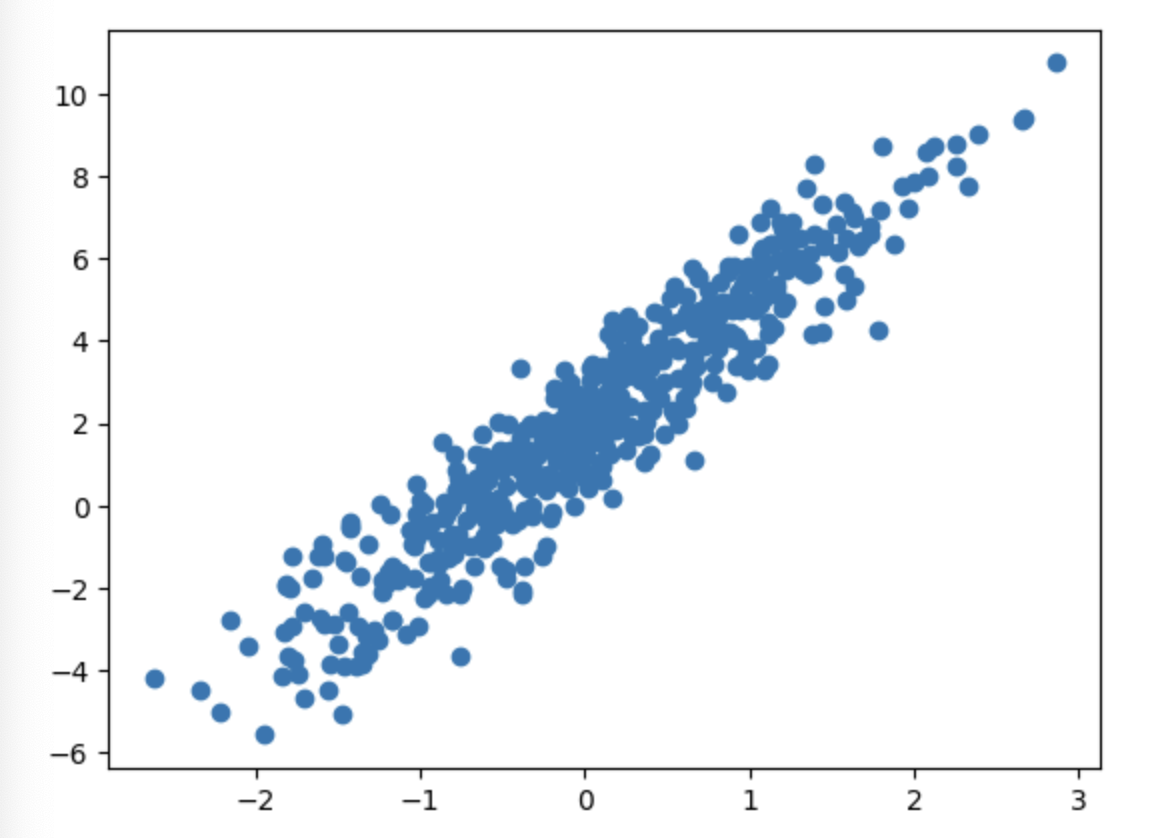
w = tf.Variable(5.)
b = tf.Variable(0.)
lr = 0.03
w_records = []
b_records = []
loss_records = []
for epoch in range(100):
with tf.GradientTape() as tape:
y_hat = X * w + b
loss = tf.reduce_mean(tf.square(y - y_hat))
w_records.append(w.numpy())
b_records.append(b.numpy())
loss_records.append(loss.numpy())
dw, db = tape.gradient(loss, [w, b])
w.assign_sub(lr * dw)
b.assign_sub(lr * db)
plt.figure(figsize=(15,6))
plt.subplot(131)
plt.plot(loss_records)
plt.title('Loss')
plt.subplot(132)
plt.plot(w_records)
plt.title('w_records')
plt.subplot(133)
plt.plot(b_records)
plt.title('b_records')
plt.show() 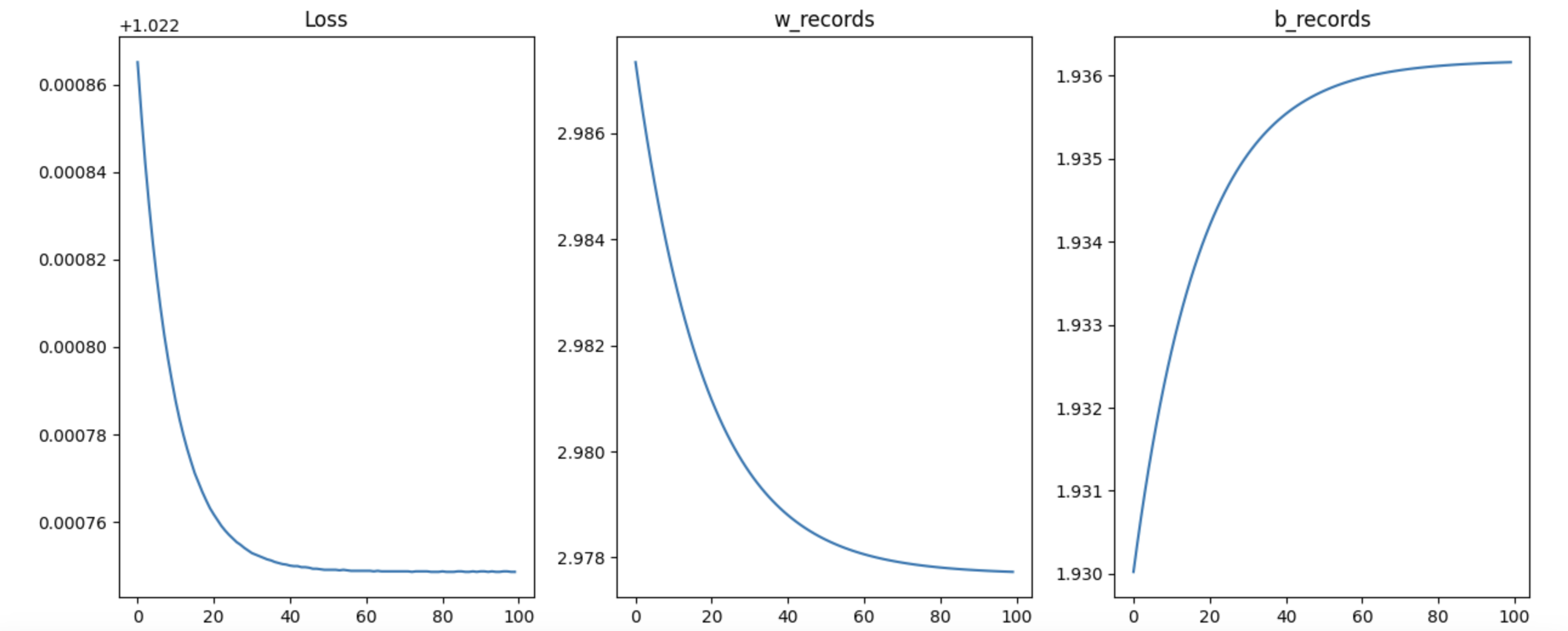
Linear regression(당뇨병 데이터)
import pandas as pd
import numpy as np
import tensorflow as tf
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names, dtype=np.float32)
df['const'] = np.ones(df.shape[0])
X = df
y = np.expand_dims(diabetes.target, axis=1)
XT = tf.transpose(X)
w = tf.matmul(tf.matmul(tf.linalg.inv(tf.matmul(XT, X)), XT), y)
y_pred = tf.matmul(X, w)
diabetes.target.shape # (442,)
X.shape, y.shape # ((442, 11), (442, 1))
XT.shape # TensorShape([11, 442])
w.shape # TensorShape([11, 1])print('예측한 진행도 : ', y_pred[0].numpy(), '실제 진행도 : ', y[0])
print('예측한 진행도 : ', y_pred[1].numpy(), '실제 진행도 : ', y[1])
print('예측한 진행도 : ', y_pred[2].numpy(), '실제 진행도 : ', y[2])
print('예측한 진행도 : ', y_pred[3].numpy(), '실제 진행도 : ', y[3])
print('예측한 진행도 : ', y_pred[4].numpy(), '실제 진행도 : ', y[4])
# 예측한 진행도 : [206.11667747] 실제 진행도 : [151.]
# 예측한 진행도 : [68.07103311] 실제 진행도 : [75.]
# 예측한 진행도 : [176.8827902] 실제 진행도 : [141.]
# 예측한 진행도 : [166.91445692] 실제 진행도 : [206.]
# 예측한 진행도 : [128.4622584] 실제 진행도 : [135.]SGD
# X.dtypes
lr = 0.03
num_itar = 100
w_init = tf.random.normal((X.shape[-1],1), dtype=tf.float64)
w = tf.Variable(w_init)
for epoch in range(num_itar):
with tf.GradientTape() as tape:
y_hat = tf.matmul(X, w)
loss = tf.reduce_mean((y - y_hat)**2)
dw = tape.gradient(loss, w)
w.assign_sub(lr * dw)print('예측한 진행도 : ', y_hat[0].numpy(), '실제 진행도 : ', y[0])
print('예측한 진행도 : ', y_hat[1].numpy(), '실제 진행도 : ', y[1])
print('예측한 진행도 : ', y_hat[2].numpy(), '실제 진행도 : ', y[2])
print('예측한 진행도 : ', y_hat[3].numpy(), '실제 진행도 : ', y[3])
print('예측한 진행도 : ', y_hat[4].numpy(), '실제 진행도 : ', y[4])
# 예측한 진행도 : [153.22489312] 실제 진행도 : [151.]
# 예측한 진행도 : [148.00045362] 실제 진행도 : [75.]
# 예측한 진행도 : [152.5368862] 실제 진행도 : [141.]
# 예측한 진행도 : [151.89688155] 실제 진행도 : [206.]
# 예측한 진행도 : [150.6241322] 실제 진행도 : [135.]iris(tanh)
from sklearn.datasets import load_iris
iris = load_iris()
idx = np.in1d(iris.target, [0,2])
X_data = iris.data[idx, 0:2]
y_data = (iris.target[idx] - 1.0)[:, np.newaxis]
X_data.shape, y_data.shape # ((100, 2), (100, 1))
X_data[0].shape # (2,)num_iter = 500
lr = 0.0003
w = tf.Variable(tf.random.normal([2,1], dtype=tf.float64))
b = tf.Variable(tf.random.normal([1,1], dtype=tf.float64))
zero = tf.constant(0, dtype=tf.float64)
for epoch in range(num_iter):
for i in range(X_data.shape[0]):
# 차원 유지
x = X_data[i:i+1]
y = y_data[i:i+1]
with tf.GradientTape() as tape:
logit = tf.matmul(x, w) + b
y_hat = tf.tanh(logit)
loss = tf.maximum(zero, tf.multiply(-y, y_hat))
grad = tape.gradient(loss, [w,b])
w.assign_sub(lr * grad[0])
b.assign_sub(lr * grad[1])
y_pred = tf.tanh(tf.matmul(X_data, w) + b)print('예측치 : ', -1 if y_pred[0] <0 else 1, '정답 : ', y_data[0])
print('예측치 : ', -1 if y_pred[1] <0 else 1, '정답 : ', y_data[1])
print('예측치 : ', -1 if y_pred[2] <0 else 1, '정답 : ', y_data[2])
print('예측치 : ', -1 if y_pred[80] <0 else 1, '정답 : ', y_data[80])
print('예측치 : ', -1 if y_pred[99] <0 else 1, '정답 : ', y_data[99])
예측치 : -1 정답 : [-1.]
예측치 : -1 정답 : [-1.]
예측치 : -1 정답 : [-1.]
예측치 : 1 정답 : [1.]
예측치 : 1 정답 : [1.]MNIST
- 데이터 탐색 > preprocessing > Modeling > Evaluation
데이터 탐색
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
print(X_train.shape, X_train.dtype)
print(y_train.shape, y_train.dtype)
print(X_test.shape, X_test.dtype)
print(y_test.shape, y_test.dtype)
# (60000, 28, 28) uint8
# (60000,) uint8
# (10000, 28, 28) uint8
# (10000,) uint8
image = X_train[50]
image.shape # (28, 28)
plt.imshow(image, 'gray')
plt.show()
y_unique, y_counts = np.unique(y_train, return_counts=True)
df_view = pd.DataFrame(data={'count': y_counts}, index=y_unique)
plt.bar(x=y_unique, height=y_counts, color='black')
plt.title('Label Distribution')
plt.show()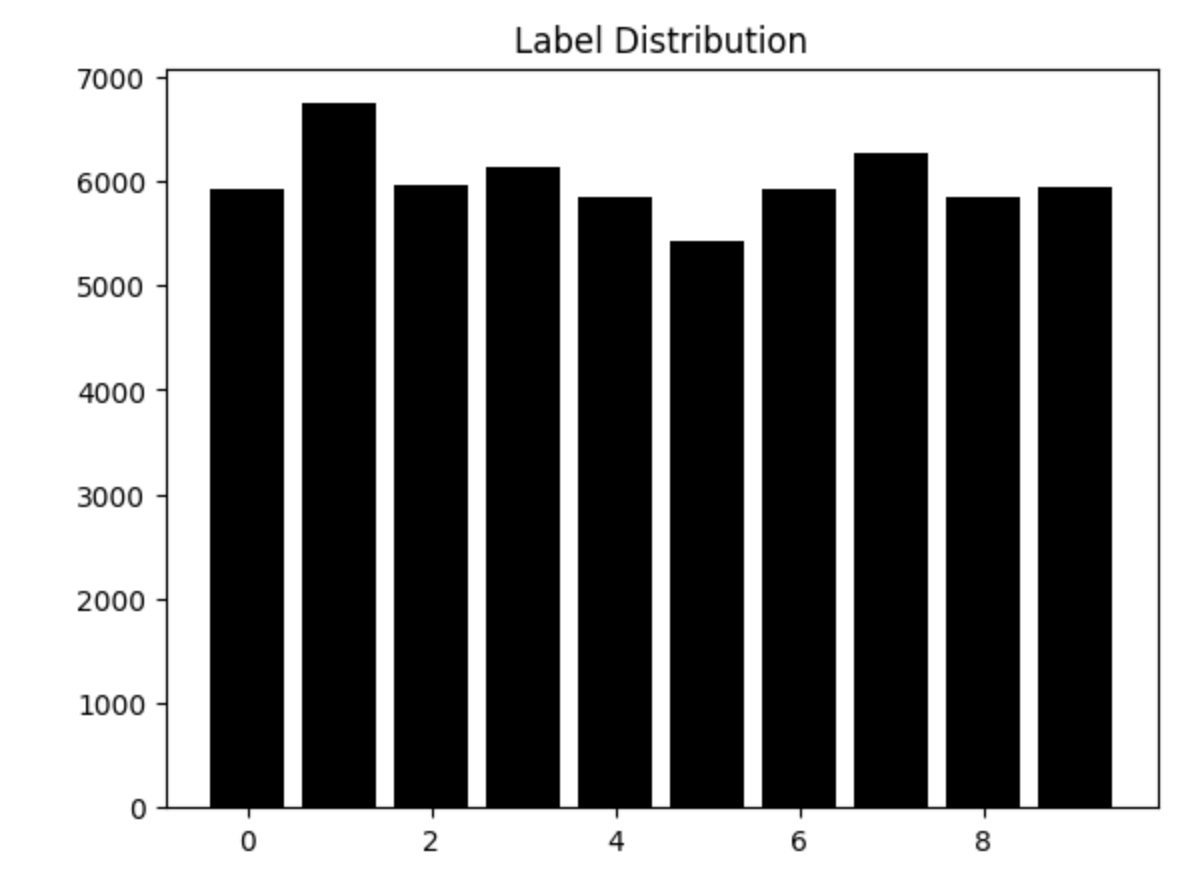
image = tf.constant(image)
plt.imshow(image, 'gray')
plt.show()
plt.imshow(tf.transpose(image), 'gray')
plt.show()
preprocessing
# 함수
# validate
def validate_poxel_scale(x):
return 255 >= x.max() and 0 <= x.min()
# scaling
def scale(x):
return (x / 255.0).astype(np.float32)
# validated
validated_train_x = np.array([x for x in X_train if validate_poxel_scale(x)])
validated_train_y = np.array([y for x, y in zip(X_train, y_train) if validate_poxel_scale(x)])
print(validated_train_x.shape)
print(validated_train_y.shape)
# (60000, 28, 28)
# (60000,)
# scaled
scaled_train_x = np.array([scale(x) for x in validated_train_x])
# flattening : 1차원 자료로 바꿔줌
flattened_train_x = scaled_train_x.reshape((60000, -1))
flattened_train_x.shape # (60000, 784) # 28 * 28
# label encoding
ohe_train_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_train_y])
ohe_train_y.shape # (60000, 10)# scale 잘 되는지 확인
sample = scale(validated_train_x[777])
sns.displot(sample);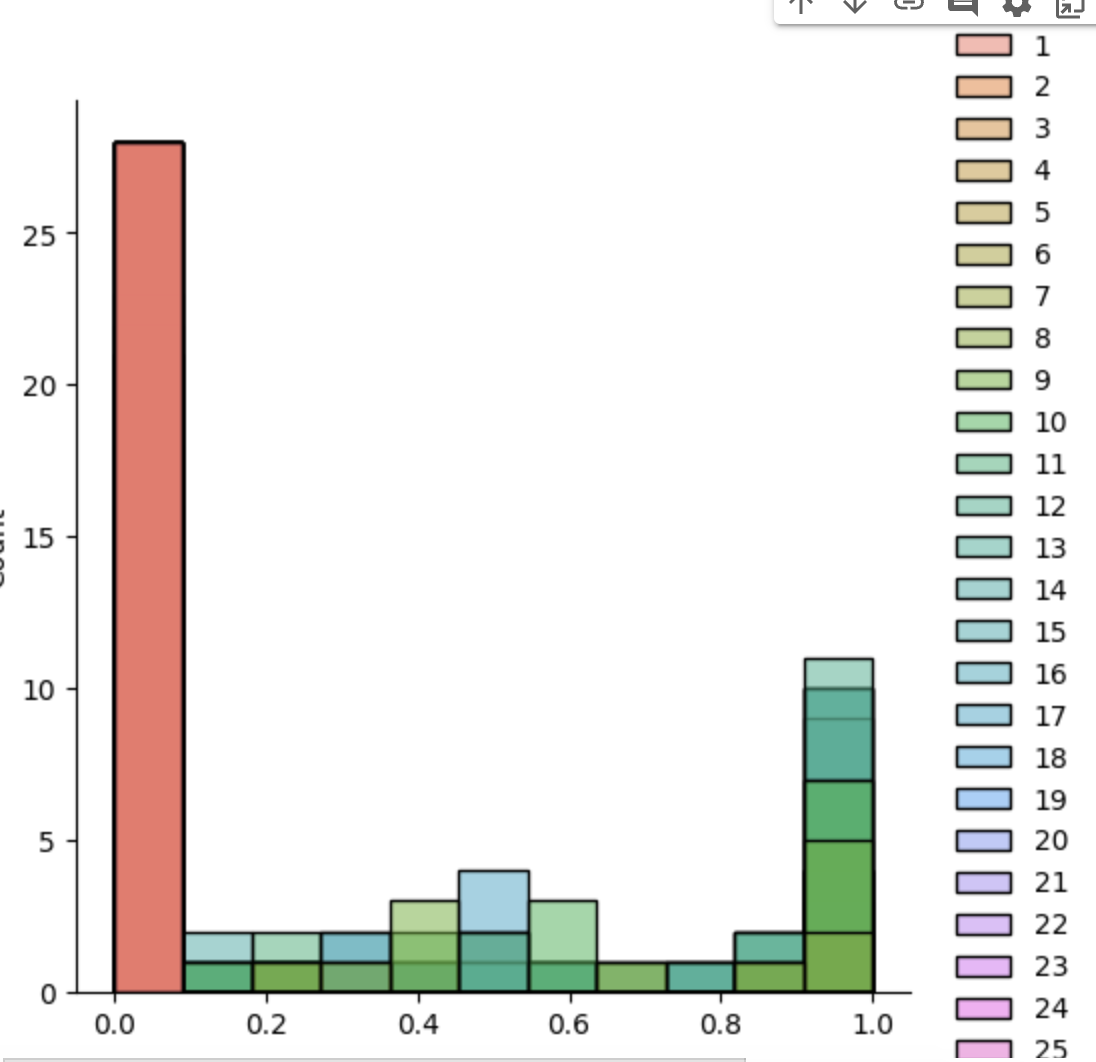
preprocessing - 클래스로 만들기
class DataLoader():
def __init__(self):
(self.X_train, self.y_train), (self.X_test, self.y_test) = tf.keras.datasets.mnist.load_data()
def validate_poxel_scale(self, x):
return 255 >= x.max() and 0 <= x.min()
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
feature, target = dataset
validated_x = np.array([x for x in feature if self.validate_poxel_scale(x)])
validated_y = np.array([y for x, y in zip(feature, target) if self.validate_poxel_scale(x)])
# scale
scaled_x = np.array([self.scale(x) for x in validated_x])
# flatten
flattend_x = scaled_x.reshape((scaled_x.shape[0], -1))
# label encoding
ohe_train_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_y])
return flattend_x, ohe_train_y
def get_train_dataset(self):
return self.preprocess_dataset((self.X_train, self.y_train))
def get_test_dataset(self):
return self.preprocess_dataset((self.X_test, self.y_test))mnist_loader = DataLoader()
train_x, train_y = mnist_loader.get_train_dataset()
test_x, test_y = mnist_loader.get_test_dataset()
print(train_x.shape)
print(test_x.shape)
print(train_y.shape)
print(test_y.shape)
# (60000, 784)
# (10000, 784)
# (60000, 10)
# (10000, 10)Modeling
# 모델 정의
from tensorflow.keras.layers import Dense, Activation
model = tf.keras.Sequential()
model.add(Dense(15, input_dim=784))
model.add(Activation('sigmoid'))
model.add(Dense(10))
model.add(Activation('softmax'))
model.summary()
# 학습 로직
opt = tf.keras.optimizers.SGD(0.03)
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer=opt, loss=loss, metrics=['accuracy'])
# 학습 실행
hist = model.fit(train_x, train_y, epochs=10, batch_size=256)Evaluation
# 학습 과정 추적
plt.figure(figsize=(10,5))
plt.subplot(121)
plt.plot(hist.history['loss'])
plt.subplot(122)
plt.plot(hist.history['accuracy'])
plt.show()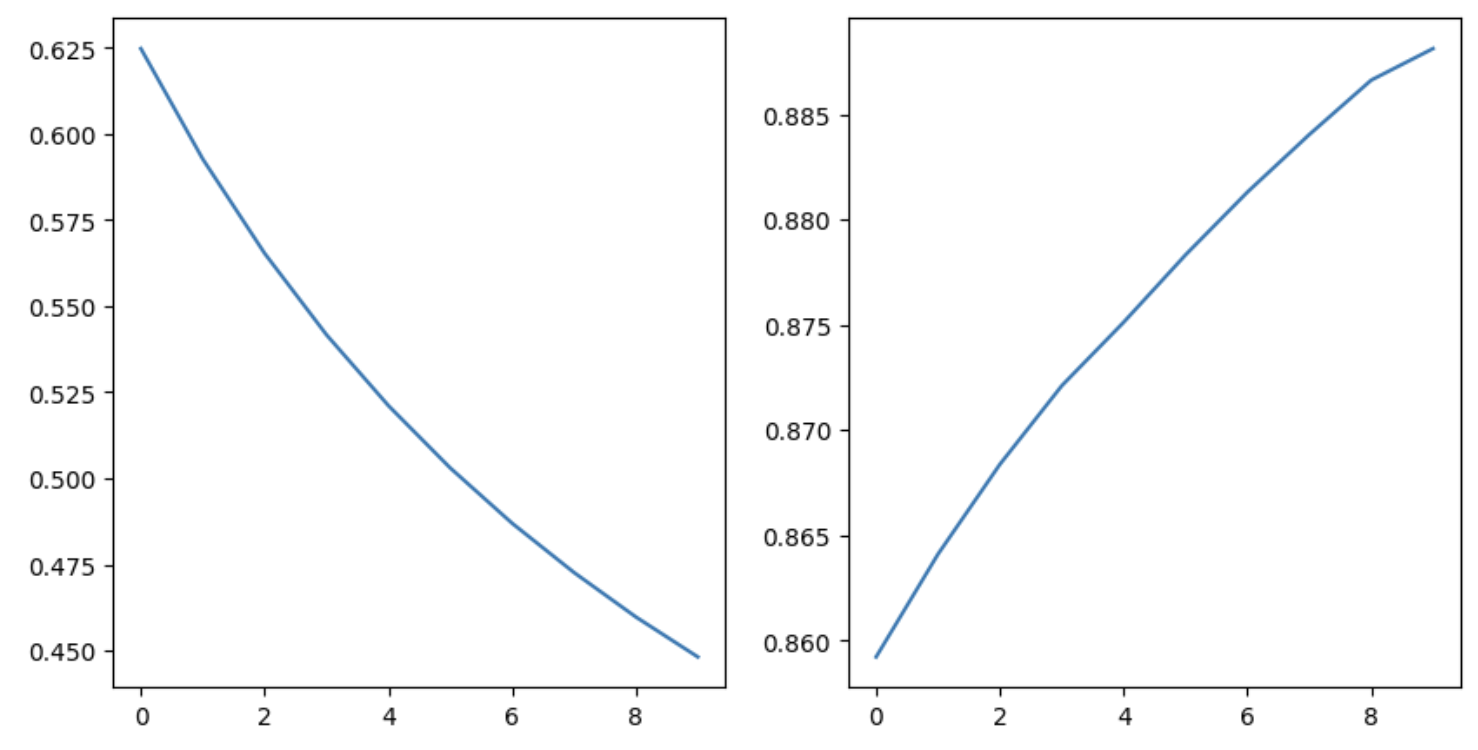
# 모델 검증
model.evaluate(test_x, test_y)
# [0.42903026938438416, 0.8946999907493591]
# 후처리
pred = model.predict(test_x[:1])
pred.argmax() # 7
test_y[0]
# array([0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], dtype=float32)
sample_img = test_x[0].reshape((28,28)) * 255
plt.imshow(sample_img)
plt.show()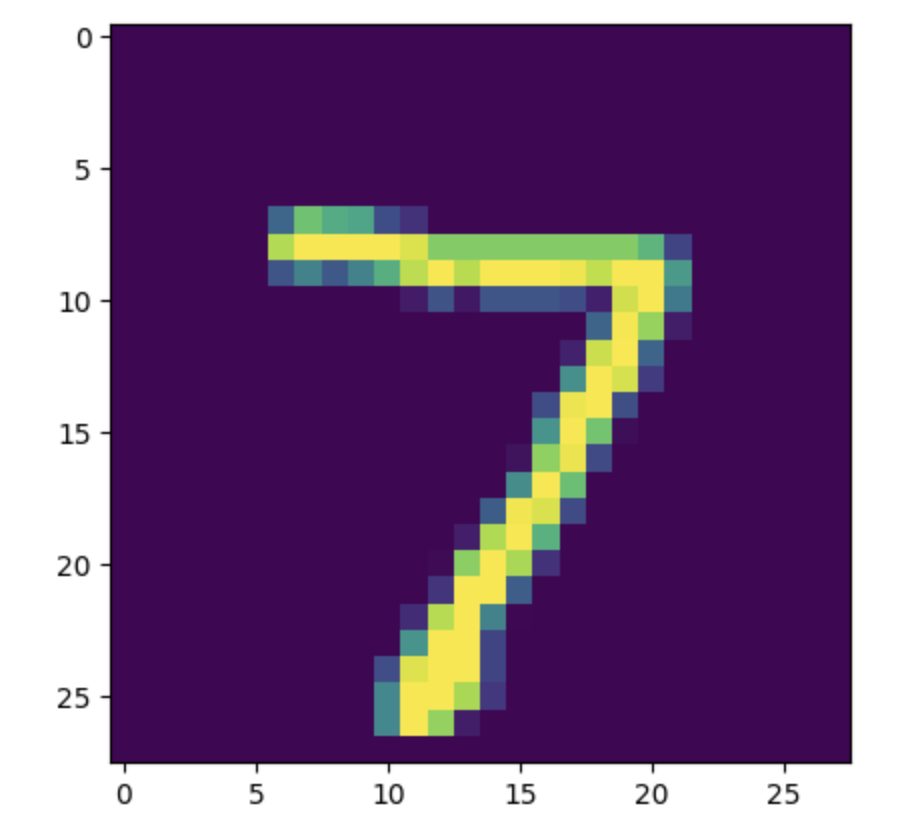
정리
def validate_poxel_scale(x):
return 255 >= x.max() and 0 <= x.min()
def scale(x):
return (x / 255.0).astype(np.float32)# 데이터 가져오기
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
# 전처리
validated_train_x = np.array([x for x in X_train if validate_poxel_scale(x)])
validated_train_y = np.array([y for x, y in zip(X_train, y_train) if validate_poxel_scale(x)])
scaled_train_x = np.array([scale(x) for x in validated_train_x])
flattened_train_x = scaled_train_x.reshape((60000, -1))
ohe_train_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_train_y])
# 모델링
model = tf.keras.Sequential()
model.add(Dense(15, input_dim=784))
model.add(Activation('sigmoid'))
model.add(Dense(10))
model.add(Activation('softmax'))
opt = tf.keras.optimizers.SGD(0.03)
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer=opt, loss=loss, metrics=['accuracy'])
# 학습
hist = model.fit(train_x, train_y, epochs=10, batch_size=256, validation_data=(test_x, test_y))
# 학습할 때 validation_data=(test_x, test_y) 하면, 검증 안 해도 됨
# 검증
model.evaluate(test_x, test_y)
pred = model.predict(test_x[:1])
pred.argmax() VGGNet
- 3 x 3
Sequential
from tensorflow.keras.layers import Conv2D, MaxPool2D, Flatten, Dense
np.random.seed(7777)
tf.random.set_seed(7777)클래스
class DataLoader():
def __init__(self):
(self.X_train, self.y_train), (self.X_test, self.y_test) = tf.keras.datasets.mnist.load_data()
def validate_poxel_scale(self, x):
return 255 >= x.max() and 0 <= x.min()
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
feature, target = dataset
validated_x = np.array([x for x in feature if self.validate_poxel_scale(x)])
validated_y = np.array([y for x, y in zip(feature, target) if self.validate_poxel_scale(x)])
# scale
scaled_x = np.array([self.scale(x) for x in validated_x])
# expand
expanded_x = scaled_x[:, :, :, np.newaxis]
# label encoding
ohe_train_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_y])
return expanded_x, ohe_train_y
def get_train_dataset(self):
return self.preprocess_dataset((self.X_train, self.y_train))
def get_test_dataset(self):
return self.preprocess_dataset((self.X_test, self.y_test))mnist_loader = DataLoader()
train_x, train_y = mnist_loader.get_train_dataset()
test_x, test_y = mnist_loader.get_test_dataset()
print(train_x.shape)
print(test_x.shape)
print(train_y.shape)
print(test_y.shape)
# (60000, 28, 28, 1)
# (10000, 28, 28, 1)
# (60000, 10)
# (10000, 10)모델링
model = tf.keras.Sequential()
model.add(Conv2D(32, kernel_size=3, padding='same', activation='relu', input_shape=(28,28,1)))
model.add(Conv2D(32, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPool2D())
model.add(Conv2D(64, kernel_size=3, padding='same', activation='relu'))
model.add(Conv2D(64, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPool2D())
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
lr = 0.03
opt = tf.keras.optimizers.Adam(lr)
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer=opt, loss=loss, metrics=['accuracy'])
hist = model.fit(train_x, train_y, epochs=2, batch_size=128, validation_data=(test_x, test_y))plt.figure(figsize=(10,5))
plt.subplot(221)
plt.plot(hist.history['loss'])
plt.subplot(222)
plt.plot(hist.history['accuracy'])
plt.subplot(223)
plt.plot(hist.history['val_loss'])
plt.subplot(224)
plt.plot(hist.history['val_accuracy'])
plt.tight_layout()
plt.show()Functional API 모델링
- Sequential보다 더 유연하게 모델 정의 가능
from tensorflow.keras.layers import Input
input_shape = (28,28,1)inputs = Input(input_shape)
net = Conv2D(32, kernel_size=3, padding='same', activation='relu')(inputs)
net = Conv2D(32, kernel_size=3, padding='same', activation='relu')(net)
net = MaxPool2D()(net)
net = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net)
net = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net)
net = MaxPool2D()(net)
net = Flatten()(net)
net = Dense(128, activation='relu')(net)
net = Dense(64, activation='relu')(net)
net = Dense(10, activation='softmax')(net)
model = tf.keras.Model(inputs=inputs, outputs=net)ResNet
- input과 output을 더함(Add)
Functional API 모델링
from tensorflow.keras.layers import Add클래스
class DataLoader():
def __init__(self):
(self.X_train, self.y_train), (self.X_test, self.y_test) = tf.keras.datasets.cifar10.load_data()
def validate_poxel_scale(self, x):
return 255 >= x.max() and 0 <= x.min()
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
feature, target = dataset
validated_x = np.array([x for x in feature if self.validate_poxel_scale(x)])
validated_y = np.array([y for x, y in zip(feature, target) if self.validate_poxel_scale(x)])
# scale
scaled_x = np.array([self.scale(x) for x in validated_x])
# label encoding
ohe_train_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_y])
return scaled_x, np.squeeze(ohe_train_y, axis=1)
def get_train_dataset(self):
return self.preprocess_dataset((self.X_train, self.y_train))
def get_test_dataset(self):
return self.preprocess_dataset((self.X_test, self.y_test))함수
def build_resnet(input_shape):
inputs = Input(input_shape)
net = Conv2D(32, kernel_size=3, strides=2, padding='same', activation='relu')(inputs)
net = MaxPool2D()(net)
net1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net2)
# net3과 net을 더해야 하는데 64, 32로 다르니깐
# net1_1 생성
net1_1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net = Add()([net1_1, net3])
# 반복
net1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net2)
net = Add()([net, net3])
net = MaxPool2D()(net)
net = Flatten()(net)
net = Dense(10, activation='softmax')(net)
model = tf.keras.Model(inputs=inputs, outputs=net)
return modelmodel = build_resnet((32,32,3))
loader = DataLoader()
train_x, train_y = loader.get_train_dataset()
test_x, test_y = loader.get_test_dataset()
print(train_x.shape)
print(test_x.shape)
print(train_y.shape)
print(test_y.shape)
# (50000, 32, 32, 3)
# (10000, 32, 32, 3)
# (50000, 10)
# (10000, 10)
lr = 0.03
opt = tf.keras.optimizers.Adam(lr)
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer=opt, loss=loss, metrics=['accuracy'])
hist = model.fit(train_x, train_y, epochs=2, batch_size=128, validation_data=(test_x, test_y))Sub class 모델링
- layer를 만드는지, model을 만드는지
-tf.keras.layers.Layer
-tf.keras.layers.Model
from tensorflow.keras.layers import Input, Conv2D, MaxPool2D, Flatten, Dense, Add클래스
# layer
class ResidualBlock(tf.keras.layers.Layer):
def __init__(self, filters=32, filter_match=False):
super(ResidualBlock, self).__init__()
self.conv1 = Conv2D(filters, kernel_size=1, padding='same', activation='relu')
self.conv2 = Conv2D(filters, kernel_size=1, padding='same', activation='relu')
self.conv3 = Conv2D(filters, kernel_size=1, padding='same', activation='relu')
self.add = Add()
self.filters = filters
self.filter_match = filter_match
if self.filter_match:
self.conv_ext = Conv2D(filters, kernel_size=1, padding='same')
def call(self, inputs):
net1 = self.conv1(inputs)
net2 = self.conv2(net1)
net3 = self.conv3(net2)
if self.filter_match:
res = self.add([self.conv_ext(inputs), net3])
else:
res = self.add([inputs, net3])
return res
# Model
class ResNet(tf.keras.Model):
def __init__(self, num_classes):
super(ResNet, self).__init__()
self.conv1 = Conv2D(32, kernel_size=3, strides=2, padding='same', activation='relu')
self.maxp1 = MaxPool2D()
self.block1 = ResidualBlock(64, True)
self.block2 = ResidualBlock(64)
self.maxp2 = MaxPool2D()
self.flat = Flatten()
self.dense = Dense(num_classes)
def call(self, inputs):
x = self.conv1(inputs)
x = self.maxp1(x)
x = self.block1(x)
x = self.block2(x)
x = self.maxp2(x)
x = self.flat(x)
return self.dense(x)
class DataLoader():
def __init__(self):
(self.X_train, self.y_train), (self.X_test, self.y_test) = tf.keras.datasets.cifar10.load_data()
def validate_poxel_scale(self, x):
return 255 >= x.max() and 0 <= x.min()
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
feature, target = dataset
validated_x = np.array([x for x in feature if self.validate_poxel_scale(x)])
validated_y = np.array([y for x, y in zip(feature, target) if self.validate_poxel_scale(x)])
# scale
scaled_x = np.array([self.scale(x) for x in validated_x])
# label encoding
ohe_train_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_y])
return scaled_x, np.squeeze(ohe_train_y, axis=1)
def get_train_dataset(self):
return self.preprocess_dataset((self.X_train, self.y_train))
def get_test_dataset(self):
return self.preprocess_dataset((self.X_test, self.y_test))model = ResNet(10)
loader = DataLoader()
train_x, train_y = loader.get_train_dataset()
test_x, test_y = loader.get_test_dataset()
print(train_x.shape)
print(test_x.shape)
print(train_y.shape)
print(test_y.shape)
# (50000, 32, 32, 3)
# (10000, 32, 32, 3)
# (50000, 10)
# (10000, 10)
lr = 0.03
opt = tf.keras.optimizers.Adam(lr)
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer=opt, loss=loss, metrics=['accuracy'])
hist = model.fit(train_x, train_y, epochs=2, batch_size=128, validation_data=(test_x, test_y))
21세기 주인공