비지도 학습 및 앙상블 주요 코드
목차
- 파트 4: CART: 분류 트리 (Classification Tree)
- 파트 5: CART: 회귀 트리 (Regression Tree)
- 파트 6: 모델 일반화 평가 & 교차 검증
- 파트 7: Bagging
- 파트 8: AdaBoost
- 파트 9: Voting Classifier
- 파트 10: Random Forest Regressor
파트 4. CART: 분류 트리 (Classification Tree)
# 페이지 15
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 데이터 분할 (80% train, 20% test)
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
stratify=y,
random_state=1
)
# 모델 선언 & 학습
dt = DecisionTreeClassifier(criterion='gini', random_state=1)
dt.fit(X_train, y_train)
# 예측 & 평가
y_pred = dt.predict(X_test)
print(accuracy_score(y_test, y_pred))파트 5. CART: 회귀 트리 (Regression Tree)
# 페이지 20
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE
# 데이터 분할 (80% train, 20% test)
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=3
)
# 모델 선언 & 학습
dt = DecisionTreeRegressor(max_depth=4, min_samples_leaf=0.1, random_state=3)
dt.fit(X_train, y_train)
# 예측 & 평가 (RMSE)
y_pred = dt.predict(X_test)
rmse = MSE(y_test, y_pred) ** 0.5
print(rmse)파트 6. 모델 일반화 평가 & 교차 검증
# 페이지 21-23
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import mean_squared_error as MSE
# 설정
SEED = 123
# 데이터 분할 (70% train, 30% test)
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.3,
random_state=SEED
)
# 모델 선언
dt = DecisionTreeRegressor(max_depth=4, min_samples_leaf=0.14, random_state=SEED)
# 10-fold CV MSE 계산
mse_cv = -cross_val_score(
dt, X_train, y_train,
cv=10,
scoring='neg_mean_squared_error',
n_jobs=-1
)
# 학습 & 예측
dt.fit(X_train, y_train)
y_train_pred = dt.predict(X_train)
y_test_pred = dt.predict(X_test)
# 결과 출력
print('CV MSE:', mse_cv.mean())
print('Train MSE:', MSE(y_train, y_train_pred))
print('Test MSE:', MSE(y_test, y_test_pred))파트 7. Bagging
# 페이지 8-9, 15
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
SEED = 1
# 데이터 분할 (70% train, 30% test)
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.3,
stratify=y,
random_state=SEED
)
# 기본 모델 선언
dt = DecisionTreeClassifier(max_depth=4, min_samples_leaf=0.16, random_state=SEED)
# Bagging 모델 선언 (n_estimators=300)
bc = BaggingClassifier(
base_estimator=dt,
n_estimators=300,
n_jobs=-1
)
# 학습 & 예측
bc.fit(X_train, y_train)
y_pred = bc.predict(X_test)
print('Bagging Accuracy:', accuracy_score(y_test, y_pred))
# OOB 평가 (oob_score=True 설정 시)
# bc = BaggingClassifier(base_estimator=dt, n_estimators=300, oob_score=True, n_jobs=-1)
# bc.fit(X_train, y_train)
# print('OOB Accuracy:', bc.oob_score_)파트 8. AdaBoost
# 페이지 8-9
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
SEED = 1
# 데이터 분할 (70% train, 30% test)
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.3,
stratify=y,
random_state=SEED
)
# Decision Stump 선언
dt = DecisionTreeClassifier(max_depth=1, random_state=SEED)
# AdaBoost 모델 선언 (n_estimators=100)
adb_clf = AdaBoostClassifier(base_estimator=dt, n_estimators=100)
# 학습 & 예측 확률
adb_clf.fit(X_train, y_train)
y_proba = adb_clf.predict_proba(X_test)[:, 1]
# 평가 (ROC AUC)
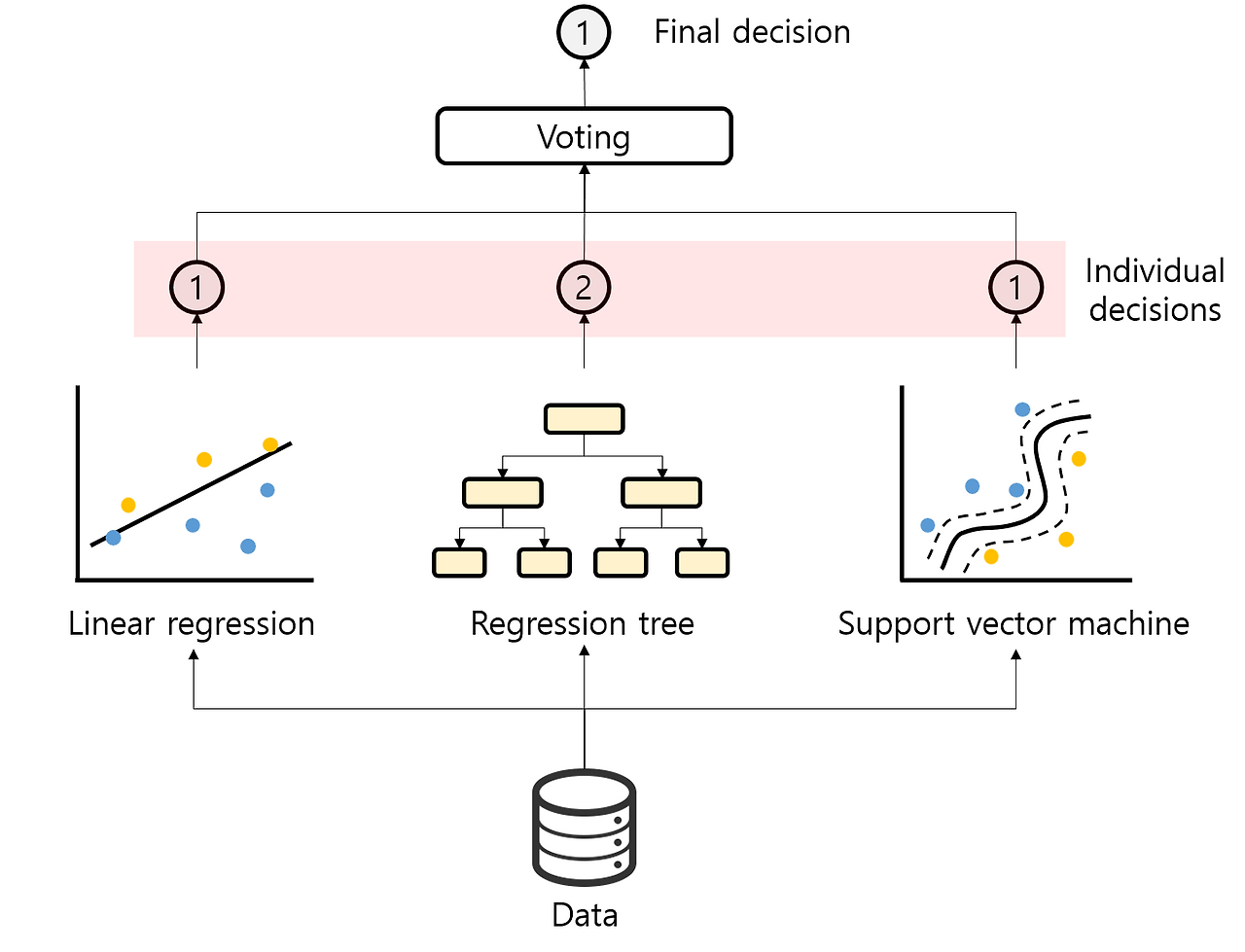
print('ROC AUC:', roc_auc_score(y_test, y_proba))파트 9: Voting Classifier
# 1) 라이브러리 임포트
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier
# 2) 데이터 분할
SEED = 1
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.3,
random_state=SEED
)
# 3) 기본 분류기 선언
lr = LogisticRegression(random_state=SEED)
knn = KNeighborsClassifier()
dt = DecisionTreeClassifier(random_state=SEED)
# 4) 앙상블 메타 모델 선언 및 학습
voting_clf = VotingClassifier(
estimators=[('lr', lr), ('knn', knn), ('dt', dt)],
voting='hard'
)
voting_clf.fit(X_train, y_train)
# 5) 예측 및 평가
y_pred = voting_clf.predict(X_test)
print(accuracy_score(y_test, y_pred))파트 10: Random ForestRegressor
# 1) 라이브러리 임포트
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE
# 2) 데이터 분할
SEED = 1
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.3,
random_state=SEED
)
# 3) 모델 선언 및 학습
rf = RandomForestRegressor(
n_estimators=400, # 트리 개수
min_samples_leaf=0.12, # 리프 노드 최소 샘플 비율
random_state=SEED
)
rf.fit(X_train, y_train)
# 4) 예측 및 평가 (RMSE)
y_pred = rf.predict(X_test)
rmse = MSE(y_test, y_pred) ** 0.5
print(f'Test set RMSE of rf: {rmse:.2f}')

發現(발현)