들어가기전에
회고록은 자고로 1주일을 마무리며 쓰는 게 제일 효과적이라고 생각했다.. 그렇게 생각했지만.. 미루고 미루다 보니 4주 차가 끝나는 시점에 블로그로 기록을 남기게 되었다. 아주 부끄럽지만 지금부터라도 수업이 끝난 주 주말에 1주일에 회고록을 담아 내가 생각하고 배웠던 내용을 생생히 담아보려고 한다.
1주차
자기소개/인사말

간단하게 입교식 및 AIVLE-EDU 사용법에 대해 매니저님께서 설명해 주셨다. 수업내용과 자료는 AIVLE-EDU사이트에서 다운로드해 활용하고 Teams를 이용해 5,6반 에의 블러 팀원들과 매니저님과 소통할 수 있게 되었다. 1주 차에서는 깃허브 사용법과 Colab-Python 데이터 전처리를 간단하게 배웠다. 복습을 해보자 (깃 README.md에 정리된 내용)
Pandas DataFrame 데이터 처리
1. 데이터프레임 인스턴스 생성 및 데이터 로드
데이터 분석의 초기 공정은 다양한 소스의 원천 데이터를 Pandas의 핵심 객체인 Series 또는 DataFrame으로 적재(Loading)하는 과정이다.
데이터프레임의 직접 정의
import pandas as pd
# 데이터 본체(data), 행 식별자(index), 열 명칭(columns)을 명시하여 객체를 생성함
df = pd.DataFrame(data=data_source, index=idx_list, columns=col_list)외부 데이터셋 가독 (CSV)
# index_col: 특정 열을 데이터프레임의 인덱스로 지정함
# header: 열 이름이 포함된 행의 번호를 지정하며, 부재 시 None으로 설정함
df = pd.read_csv("path/to/data.csv", index_col='Date')2. 데이터 탐색 및 기술통계 (Exploration & Descriptive Statistics)
데이터의 물리적 구조, 자료형, 분포 및 결측치 현황을 파악함으로써 이후 전처리 전략의 기초를 수립하는 정찰 단계이다.
구조 및 메타데이터 참조
-
df.head(n) / df.tail(n) : 데이터셋의 상위 및 하위 표본을 추출
-
df.shape : 데이터프레임의 차원(행과 열의 개수)을 확인함
-
df.info() : 인덱스 구성, 각 열의 자료형(dtypes) 및 비결측치(Non-Null) 개수 등 전체 요약을 출력함
-
df.columns / df.index : 열 명칭 및 행 인덱스 정보를 참조함
-
df.values : 내부 데이터를 Numpy 다차원 배열 형태로 반환함
통계적 특성 및 분포 파악
-
df.describe() : 수치형 데이터에 대한 주요 기술통계량(평균, 표준편차, 사분위수 등)을 요약함
-
df['col'].value_counts() : 범주형 데이터의 각 항목별 출현 빈도를 산출함
-
df['col'].unique() / nunique() : 고유값의 목록 및 고유값의 총 개수를 확인함
-
df['col'].mode() : 데이터셋 내 최빈값을 산출함
-
df.sum(), df.mean(), df.median(), df.std() : 산술 합계, 평균, 중앙값, 표준편차 등 통계 함수를 적용함
3. 데이터 조회 및 필터링 (Selection & Filtering)
특정 분석 목적에 부합하는 서브셋(Subset)을 추출하기 위한 다양한 인덱싱 기법을 포함한다.
데이터 인덱싱 및 정렬
차원 선택
- df['col'] : 단일 열 추출 시 Series 객체가 반환됨
- df[['col1', 'col2']] : 다중 열 추출 시 리스트를 사용하여 DataFrame 형태를 유지함조건부 조회 및 위치 기반 조회
- df.loc[row_condition, col_name] : 레이블 기반 조회 방식으로, 불리언 인덱싱(Boolean Indexing)을 통한 조건부 필터링에 최적화됨
- df.iloc[row_idx, col_idx] : 정수 위치 기반 조회 방식으로, 행과 열의 물리적 순서에 따라 데이터를 추출함
- df.isin([list]) : 특정 열의 값이 주어진 리스트 내에 포함되는지 여부를 판단하여 필터링함정렬 프로토콜
- df.sort_values(by=['col1', 'col2'], ascending=[True, False]) : 복수의 열을 기준으로 정렬 방식을 개별 적용할 수 있음4. 데이터프레임 구조의 변형 (Structural Modification)
열(Column) 및 행(Row) 관리
식별자 변경: df.rename(columns={'old': 'new'}, inplace=True)를 통해 특정 열의 명칭을 수정한 후 원본 객체에 직접 반영함
열의 추가 및 삽입:
- df['new_col'] = values : 데이터프레임의 최우측에 새로운 열을 추가함
- df.insert(pos, 'name', values) : 지정된 위치(pos)에 특정 열을 삽입하여 구조를 정밀하게 제어함제거 프로세스:
- df.drop(list, axis=1, inplace=True) : 명시된 열 리스트를 제거함 (열 삭제 시 axis=1 설정 필수)
- df.pop('col') : 특정 열을 반환함과 동시에 원본 데이터프레임에서 영구히 삭제함인덱스 재설정: df.reset_index(drop=True, inplace=True)는 기존 인덱스를 제거하고 연속적인 정수 인덱스로 초기화하는 공정으로, 데이터 결합 후 인덱스 정합성 확보를 위해 수행함
5. 데이터 가공 및 변환 (Transformation & Mapping)
데이터의 유효성을 확보하고 분석에 용이한 형태로 값을 변환하는 과정이다.
- replace() : 스칼라 값을 탐색하여 지정된 값으로 정밀하게 치환함
- map() : 딕셔너리 또는 함수를 매개로 Series의 개별 요소를 일대일 대응 변환함 (범주형 데이터 인코딩 시 유용함)
- pd.cut() : 수치형 연속 변수를 지정된 경계값에 따라 범주형 데이터로 이산화(Discretization)함6. 결측치 관리 (Handling Missing Values)
데이터의 완전성을 저해하는 결측값(NaN)에 대한 체계적인 처리 방안을 명시한다.
-
현황 파악: df.isna().sum() 또는 df.isnull().sum()을 통해 열 단위 결측치 발생 빈도를 집계함
-
제거 전략: df.dropna(subset=['col'], axis=0, inplace=True)를 실행하여 특정 핵심 변수에 결측이 존재하는 레코드를 제외함
-
보간 및 대체: df.fillna(value) 또는 전방/후방 보간법(method='ffill'|'bfill')을 적용하여 결측값을 통계적 추정치로 대체함
7. 데이터 집계 및 그룹 연산 (Aggregation & Grouping)
특정 기준 열을 중심으로 데이터를 그룹화하여 고차원적 통계 정보를 추출하는 방법론이다.
Groupby 연산
분할(Split)-적용(Apply)-결합(Combine) 패러다임을 통해 그룹별 분석을 수행함.
# 범주별 타겟 열에 대해 다중 통계량(합계, 평균 등)을 동시에 산출함
df.groupby('Category', as_index=True)['Target'].agg(['sum', 'mean'])8. 데이터프레임 병합 및 연결 (Merging & Concatenation)
다양한 출처에서 기인한 데이터를 단일 데이터프레임으로 통합하는 고도화된 결합 기법이다.
물리적 연결 (Concat)
- axis=0 : 수직 방향 연결을 수행하며, 인덱스 중복 여부를 고려하여 reset_index를 병행할 것을 권장함
- axis=1 : 수평 방향 연결을 수행하며, 조인 방식(join='inner'|'outer')에 따라 데이터 유지 범위가 결정됨논리적 병합 (Merge)
관계형 데이터베이스의 Join 연산과 유사하게 공통된 키(Key) 컬럼을 기준으로 데이터를 병합함.
- how='inner' : 양측 데이터프레임에 공통으로 존재하는 키값만을 추출함
- how='left' / 'right' : 좌측 또는 우측 데이터프레임을 기준으로 데이터를 유지하며, 대응값이 없는 경우 NaN으로 처리함
- how='outer' : 모든 데이터를 보존하는 완전 외부 조인을 수행함생각정리
깃허브를 배우는 수업에서 VScode-Git-graph 이용법에 대해 배웠던 점이 인상 깊었다. 항상 터미널로 작업하던 입장으로써 눈으로 직관적으로 brnach들을 볼 수 있다는 점 그리고 간단하게 클릭으로 Checkout, Merge, Rebase, Reset, Revert 등을 적용할 수 있다는 점이다. 유용하게 프로젝트를 진행할 때 사용할 거 같았다. (코드 리뷰할 때도 편할 거 같았다)
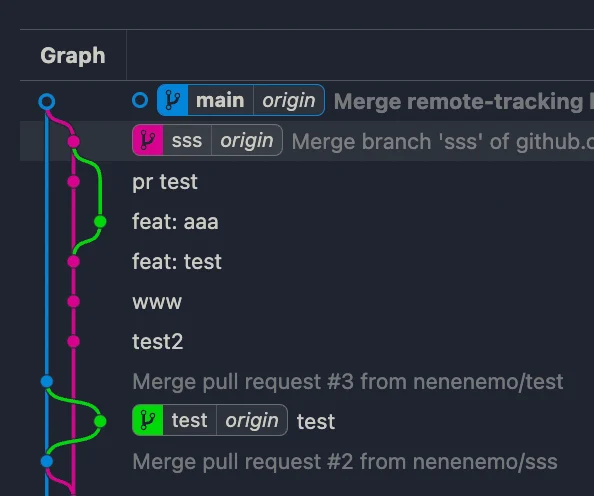
데이터 전처리 코드를 수없이 봐왔던거 같다(캐글, 자격증 준비, 전공) 이번 1주차에서는 기본적인 내용으로 짧고 빠르게 많은 함수에 사용법을 알아가는 시간이었던 거 같다. 수업 시간이 09~18시까지 온라인으로 이어지다 보니 아침에 일어나 적응하는 시간이 아직 익숙해지지 않았던 거 같다. 날마다 체크인과 체크아웃 시간에 자기소개 시간을 가지며 같은 반 에이블러님들이 어떤 목표로 부트 캠프에 참여하게 된 걸 알게 되어 좋았던 거 같다. (같은 목표를 바라보는 에이블러님들이 많았던 거 같다) 자기소개 이외에 교육을 진행하는 동안 미래의 나에게 전하는 시간이 있었는데 (코딩테스트 업그레이드, 공모전 수상, 개근하기 등등)그 말을 이룰 수 있도록 열심히 임해 후회 없는 시간들을 보냈으면 좋겠다고 생각하며 1주 차를 마무리한다.
강사님의 말씀 중
"하루살이라고 생각하고 오늘 하루의 최선을 다하세요!"
Github-Private
