들어가며
ML에 대해 2일 동안 DL에 대해 1일 학습을 진행했다. 기간이 짧은 기간 동안 중요한내용을 빠르게 학습하고 바로 실습(코드)으로 진행해 개인이 문제를 해결하기보다 라이브러리 및 함수에 대해 익숙해지고 학습한 모델이 어떤구조와 어떤 흐름으로 이어가는지에 대한 전체적인 이해를 배운 거 같다. 정리해보자
1. 머신러닝 (Machine Learning)
들어가기전 머신러닝은
- 문제 정의
- 데이터 준비(데이터 전처리)
- 모델링(알고리즘 적용)
- 평가
- 성능 최적화(튜닝)
위 사이클을 꼭 기억하기
1-1. 데이터 전처리
알고리즘에 데이터를 넣기 전, 모델이 데이터를 잘 이해할 수 있도록 가공하는 필수 단계
- 결측치 처리: 비어있는 데이터(NaN)를 평균, 중앙값 등으로 채우거나 행 자체를 삭제한다.
- 가변수화 (One-Hot Encoding): 머신러닝 모델은 문자를 이해하지 못하므로, 범주형 데이터(예: 성별, 혈액형)를 0과 1로 이루어진 변수로 변환해 주어야 한다.
- 스케일링 (Scaling): 변수마다 값의 범위가 다르면(예: 나이는 10~80, 연봉은 3000~10000) 단위가 큰 변수에 모델이 가중치를 과도하게 둘 수 있다. 따라서 모든 변수의 범위를 0~1 사이로 맞추는 정규화(MinMaxScaler)나 평균 0, 표준편차 1로 맞추는 표준화(StandardScaler)를 진행한다. 거리 기반 알고리즘(KNN 등)에서는 필수적이다.
1-2. 문제의 정의와 주요 알고리즘: 회귀(Regression) vs 분류(Classification)
목표 변수(Target)의 형태에 따라 접근 방식과 알고리즘을 선택하자!
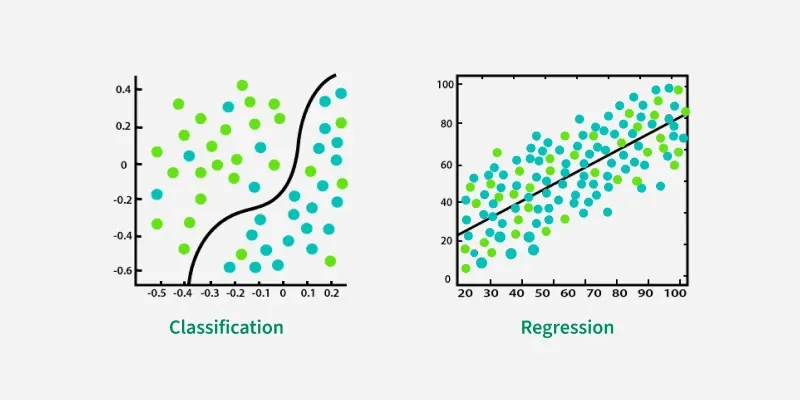
출처/참고 : https://www.geeksforgeeks.org/machine-learning/ml-classification-vs-regression/
[회귀 모델링 (Regression)]
- 목표(Target): 연속적인 '숫자'를 예측하는 문제 (예: 집값 예측, 주가 예측, 매출액 예측). 실제 값과 예측값의 '오차(Error)'를 최소화하는 것이 핵심이다.
- 선형 회귀 (Linear Regression): 데이터의 경향성을 가장 잘 설명하는 하나의 최적의 직선(y = wx + b)을 긋는 방식. 빠르고 해석이 쉽지만 복잡한 패턴을 잡기는 어렵다.
- K-최근접 이웃 회귀 (KNN Regressor): 예측하려는 데이터와 가장 가까운 K개의 이웃 데이터를 찾아, 그 이웃들의 타겟 값 평균을 계산하여 예측한다.
[분류 모델링 (Classification)]
- 목표(Target): 데이터가 속할 '범주(Class)'를 예측하는 문제 (예: 스팸 메일 여부, 질병 유무). 정확하게 경계선을 그어 범주를 나누는 것이 핵심이다.
- 로지스틱 회귀 (Logistic Regression): 이름은 회귀이지만 분류에 사용된다. 시그모이드 함수를 통해 특정 클래스에 속할 확률(0~1)을 계산하여 0.5를 기준으로 분류한다.
- 의사결정나무 (Decision Tree): 스무고개처럼 조건(예: 나이가 30 이상인가? Yes/No)을 분기하여 데이터를 분류한다. 사람이 직관적으로 이해하기 좋고 설명력이 뛰어나다.
- 랜덤 포레스트 (Random Forest): 수많은 의사결정나무를 만들고, 각 나무의 예측 결과를 취합(투표)하여 최종 결과를 내는 앙상블(Ensemble) 기법이다. 단일 모델보다 성능이 훨씬 뛰어나며 과적합을 방지하는 효과가 있다.
1-3. 모델 성능 평가 (Evaluation)
학습된 모델이 처음 보는 데이터(Test Data)에 대해 얼마나 잘 작동하는지 객관적으로 평가
| 평가 지표 | 계산식 |
|---|---|
| MAE (평균 절대 오차) | |
| MSE (평균 제곱 오차) | |
| RMSE (평균 제곱근 오차) | |
| MAPE (평균 절대 백분율 오차) | |
| MPE (평균 백분율 오차) |
[회귀 평가지표]
- MSE (Mean Squared Error): 실제값과 예측값의 차이(오차)를 제곱하여 평균 낸 값. 오차가 클수록 페널티를 크게 부여
- RMSE (Root Mean Squared Error): MSE에 루트를 씌워 실제 값과 단위를 맞춰 직관성을 높인 지표.
- MAE (Mean Absolute Error): 오차의 절댓값의 평균. 오차의 크기를 보여줌
- R2 Score (결정계수): 모델의 설명력을 나타내며 0에서 1 사이의 값을 가진다. 1에 가까울수록 데이터의 변동성을 잘설명한다.
분류 모델 평가 지표 (Classification Metrics)

출처/참고 : https://glassboxmedicine.com/2019/02/17/measuring-performance-the-confusion-matrix/
| 평가 지표 | 설명 | 계산식 |
|---|---|---|
| 정확도 (Accuracy) | 실제 분류를 정확하게 예측한 비율 | |
| 정밀도 (Precision) | Positive로 예측한 것 중 실제 Positive인 비율 | |
| 민감도/재현율 (Recall/Sensitivity) | 실제 Positive(P) 중 Positive로 예측한 비율 | |
| F1-score | 정밀도와 재현율의 조화평균 |
[분류 평가지표와 오차행렬(Confusion Matrix)]
분류 문제는 오차행렬(TP, TN, FP, FN)을 기반으로 평가한다.
- Accuracy (정확도): 전체 예측 중 맞춘 비율. 데이터 불균형(예: 정상 99개, 불량 1개) 시 무조건 정상이라고만 찍어도 99%가 나오므로 신뢰하기 어렵다.
- Precision (정밀도): 모델이 'Positive'라고 예측한 것 중 실제 'Positive'인 비율. (예: 스팸으로 걸러낸 메일 중 진짜 스팸인 비율. 일반 메일을 스팸으로 걸러버리면 안 될 때 중요).
- Recall (재현율): 실제 'Positive'인 것 중 모델이 'Positive'로 찾아낸 비율. (예: 실제 암 환자 중 모델이 암이라고 예측한 비율. 병원 진단 모델처럼 실제 환자를 놓치면 안 될 때 가장 중요).
- F1-Score: 정밀도와 재현율의 조화 평균으로, 데이터가 불균형할 때 모델의 성능을 가장 객관적으로 대변한다.
1-4. 교차 검증(Cross Validation)과 모델 성능 튜닝(Hyperparameter Tuning)
개발자가 알고리즘에 직접 설정해 주어야 하는 '하이퍼파라미터'에 따라 성능이 극명하게 달라지므로, 이를 최적화하는 과정이 필요하다.
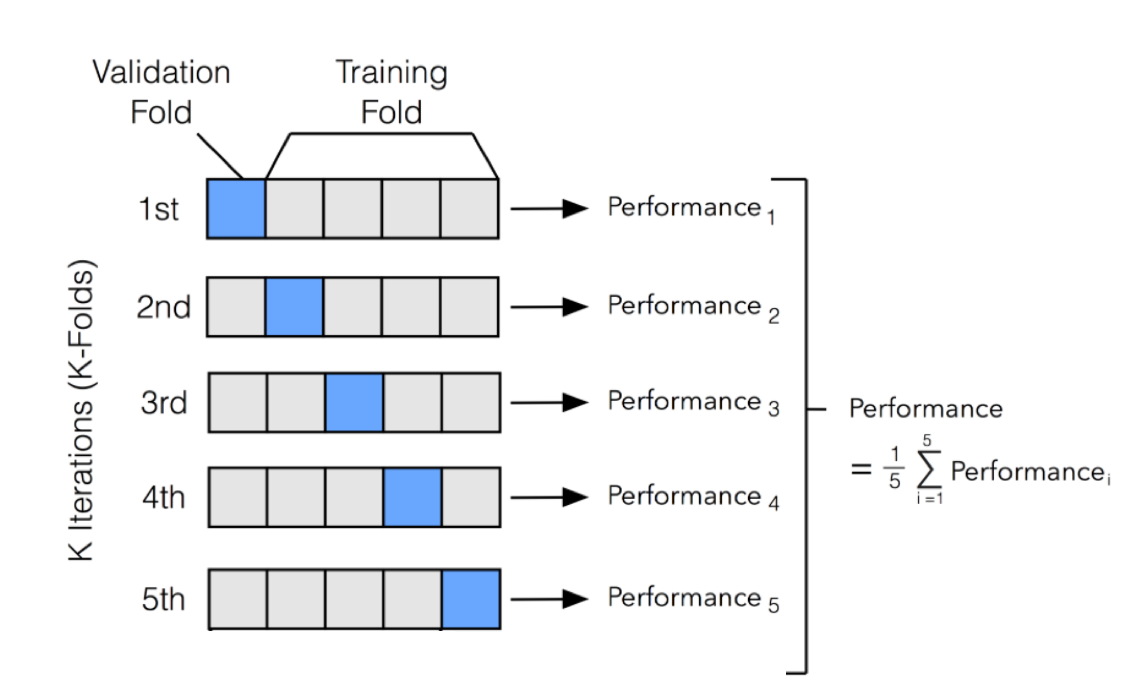
- K-Fold 교차 검증: 훈련 데이터를 통째로 한 번만 학습하는 것이 아니라, 데이터를 K개의 폴드(조각)로 나누어 K번 반복 학습 및 평가를 진행한다. 특정 데이터 셋에만 맞춰지는 것을 방지하고 모델의 평균적인 성능을 신뢰성 있게 평가할 수 있다.
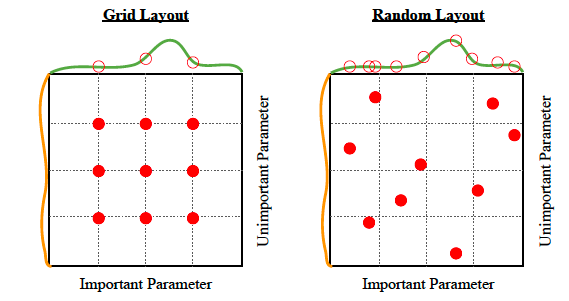
- Grid Search (그리드 서치): 지정한 파라미터 값들의 '모든 경우의 수'를 다 조합해서 학습해 보고 가장 최고 성능(bestscore)을 내는 조합(bestparams)을 찾는 방법. 탐색 공간이 넓어지면 시간이 늘어난다.
- Random Search (랜덤 서치): 파라미터의 범위만 지정해 주고, 그 안에서 랜덤하게 조합을 뽑아 지정된 횟수(n_iter)만큼만 테스트하는 방법. 그리드 서치보다 시간은 훨씬 절약되면서도 꽤 괜찮은 최적의 값을 빠르게 찾아낸다.
출처/참고
https://ethen8181.github.io/machine-learning/model_selection/model_selection.html
https://datarian.io/blog/grid-search-random-search
https://blog.naver.com/hsj2864/222215638480
https://scikit-learn.org/stable/modules/cross_validation.html
https://www.ibm.com/think/topics/fine-tuning
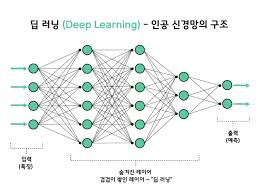
2. 딥러닝 (Deep Learning)
들어가기 전 딥러닝은
- 데이터 준비 (데이터 전처리 및 스케일링 필수)
- 구조 설계 (레이어, 노드, 활성화 함수 구성)
- 모델 컴파일 (손실 함수 및 옵티마이저 설정)
- 모델 학습 (Epoch 반복을 통한 가중치 업데이트)
- 성능 최적화 (Early Stopping, Dropout 등으로 과적합 방지)
- 평가
위 딥러닝 고유의 모델링 사이클을 꼭 기억하기!
머신러닝의 알고리즘 중 '인공신경망(ANN)'을 여러 개의 은닉층(Hidden Layer)으로 깊게(Deep) 쌓아 올린 것이 딥러닝이다.
2-1.작동 원리
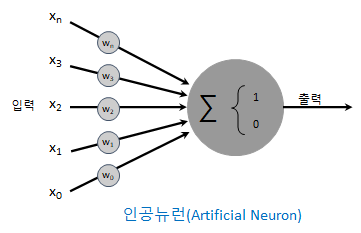
신경망은 Input Layer(입력층), Hidden Layer(은닉층), Output Layer(출력층)로 구성
- 가중치(Weight)와 편향(Bias): 각 노드(뉴런)는 입력값에 가중치를 곱하고 편향을 더한다. 학습이란 이 가중치와 편향의 최적값을 찾아가는 과정이다.
- 역전파(Backpropagation): 출력층에서 예측값과 실제값의 오차를 구한 뒤, 이 오차를 최소화하는 방향으로 출력층에서부터 입력층으로 거꾸로 돌아가며 가중치를 업데이트(미분 활용)한다.
2-2. 활성화 함수(Activation)와 손실 함수(Loss) 설정
딥러닝은 층과 층 사이에 '활성화 함수'를 넣어 비선형성을 추가한다. 이것이 없으면 아무리 층을 깊게 쌓아도 결국 단순한 선형 회귀 모형과 다를 바가 없어진다. 은닉층에서는 주로 'relu'를 사용하여 딥러닝의 고질적 문제인 기울기 소실(Vanishing Gradient)을 방지한다.
문제 유형에 따른 출력층 설계
- 회귀 (연속된 숫자 예측):
- 출력 노드 수: 1개
- 활성화 함수: 없음 (또는 linear)
- 손실 함수(Loss): mse (Mean Squared Error)
- 이진 분류 (O/X, 생존/사망 등 두 개 중 하나 분류):
- 출력 노드 수: 1개
- 활성화 함수: sigmoid (출력값을 0~1 사이의 확률로 변환)
- 손실 함수(Loss): binary_crossentropy
- 다중 분류 (여러 클래스 중 선택):
- 출력 노드 수: 분류하려는 클래스의 개수 (예: 개/고양이/새 분류면 3)
- 활성화 함수: softmax (각 클래스에 속할 확률을 모두 더하면 1이 되도록 변환)
- 손실 함수(Loss): categorical_crossentropy (원핫인코딩 된 경우) 또는 sparse_categorical_crossentropy (정수형 라벨인 경우)
2-4. 학습 방법론과 성능 최적화 (과적합 방지 기법)
딥러닝 모델은 파라미터가 수십만~수천만 개에 달하기 때문에, 훈련 데이터에만 완벽히 맞춰져 새로운 데이터에 취약해지는 '과적합(Overfitting)'에 빠지기 매우 쉽다. 모델의 복잡도를 제어하는 것이 핵심이다.
-
주요 학습 파라미터:
- Epoch (에포크): 전체 데이터를 몇 번 반복해서 학습할 것인가. 에포크가 너무 적으면 과소적합, 너무 많으면 과적합이 발생한다.
- Learning Rate (학습률): 가중치를 업데이트할 때 오차의 최소점을 향해 한 번에 얼마나 크게 이동할 것인가를 결정한다. 너무 크면 최적점을 지나쳐 발산하고, 너무 작으면 학습이 지나치게 느려지거나 지역 최적점(Local Minimum)에 갇힌다.
-
과적합 방지 및 최적화 기법:
- Early Stopping: 모델이 학습하면서 검증 데이터의 오차(val_loss)가 더 이상 감소하지 않고 반등하기 시작하면, 설정해 둔 Epoch가 남아있더라도 학습을 강제로 조기 종료시킨다. patience 옵션으로 오차가 줄지 않아도 몇 번의 에포크를 더 기다려볼지 결정할 수 있다. 과적합으로 넘어가기 전 최적의 타이밍에 학습을 멈추는 필수 콜백 함수다.
- ModelCheckpoint: Early Stopping과 함께 자주 쓰이며, 학습 과정 중 지정한 지표(예: val_loss)가 가장 좋았던 순간의 최적의 가중치를 파일로 자동으로 저장해 둔다.
- Dropout: 은닉층의 노드 중 일부 비율(예: 20~50%)을 무작위로 비활성화한 채로 학습하는 방법이다. 매 에포크마다 끊어지는 노드가 달라지므로 모델이 특정 노드의 가중치에만 과도하게 의존하는 것을 막아준다. 이는 일종의 앙상블 효과를 내어 새로운 데이터에 대한 일반화(Generalization) 성능을 비약적으로 높여준다.
- Regularization: L1 규제, L2 규제 등을 통해 가중치 값이 비정상적으로 커지는 것을 수학적으로 억제하여 모델의 복잡도를 낮추는 기법이다.
출처/참고
https://facerain.github.io/improve-dl-performance/
https://pub.towardsai.net/keras-earlystopping-callback-to-train-the-neural-networks-perfectly-2a3f865148f7
https://kh-kim.github.io/nlp_with_deep_learning_blog/docs/1-14-regularizations/04-dropout/
https://www.geeksforgeeks.org/machine-learning/regularization-in-machine-learning/
생각정리
대학원 면접 보러 갔을 당시 내가 고민하다가 생각한 주제인 Why Multi-class Classification Needs Softmax를 발표하는 장면이 주마등처럼 스쳐가는 수업이었던 거 같다... 수업내용에서는 Multi-class를 크게 다루지 않았지만 학부 연구생때 연구실에 처음 들어가 교수님이 읽으라고 지시해주신 딥러닝 모델들도 생각나게 되는 수업이었던 거 같다.
- ImageNet Classification with Deep Convolutional Neural Networks(AlexNet)
- Deep Residual Learning for Image Recognition
- Densely Connected Convolutional Networks
- Very Deep Convolutional Networks for Large-Scale Image Recognition
구조를 이해하고 최적화기법에 하나하나에 수식을 보는 것이 아닌 전체 흐름 구조 복습 및 실질적인 AICE-associate를 준비하기 앞서 코드를 직접 작성해 보고 구현해 보는 것이 목적이었다고 생각한다. 기간이 너무 짧다 보니(2일/2일) 비전공자/전공자에게 모든 것을 이해시키는 것은 정말 불가능하다고 생각했었기 때문이다. 하나의 내용으로만 2주 내내 수업해도 모자라지 않은 내용이었다고 생각한다. 실습과 복습을 진행하면서 수업 시간에 내용에서 강사님께서 설명해 주신 부분이 맞나?라고 생각했던 부분을 다시 찾아 보면서 이해할 수 있었던 좋은 시간이었다고 생각한다. 배웠던 내용이 오래 기억되고 나의 지식으로 온전히 다 받아들일 수 있게 "반복 학습하자!" 생각을 하며 2주차를 마무리한다.
교수님(대학교 지도교수님)의 말씀 중 :
내가 배운 내용을 정말 이해하고 있는지 의문이 들 때가 있어, 그럴 때는 그 내용을 다른 이에게 설명하고, 상대방에게 설명할 수 있다면 비로소 그것이 내 것이 된 지식일 거야
Github-Private
