들어가며
이번 글에서는 2차 미니 프로젝트로 진행한 AI 강사 Agent 구축 과정에 대해 정리해보려고 한다. PPT에 내용을 슬라이드별로 데이터를 분석하고 이를 음성 및 영상과 연결하여 하나의 완성된 강의 콘텐츠를 만들어내는 에이전트를 개발하는 것이 이번 프로젝트의 핵심이었다. 나는 이 과정에서 각 기능을 담당하는 노드들을 설계하고 이들을 연결하는 그래프 관리자 역할을 맡았다.
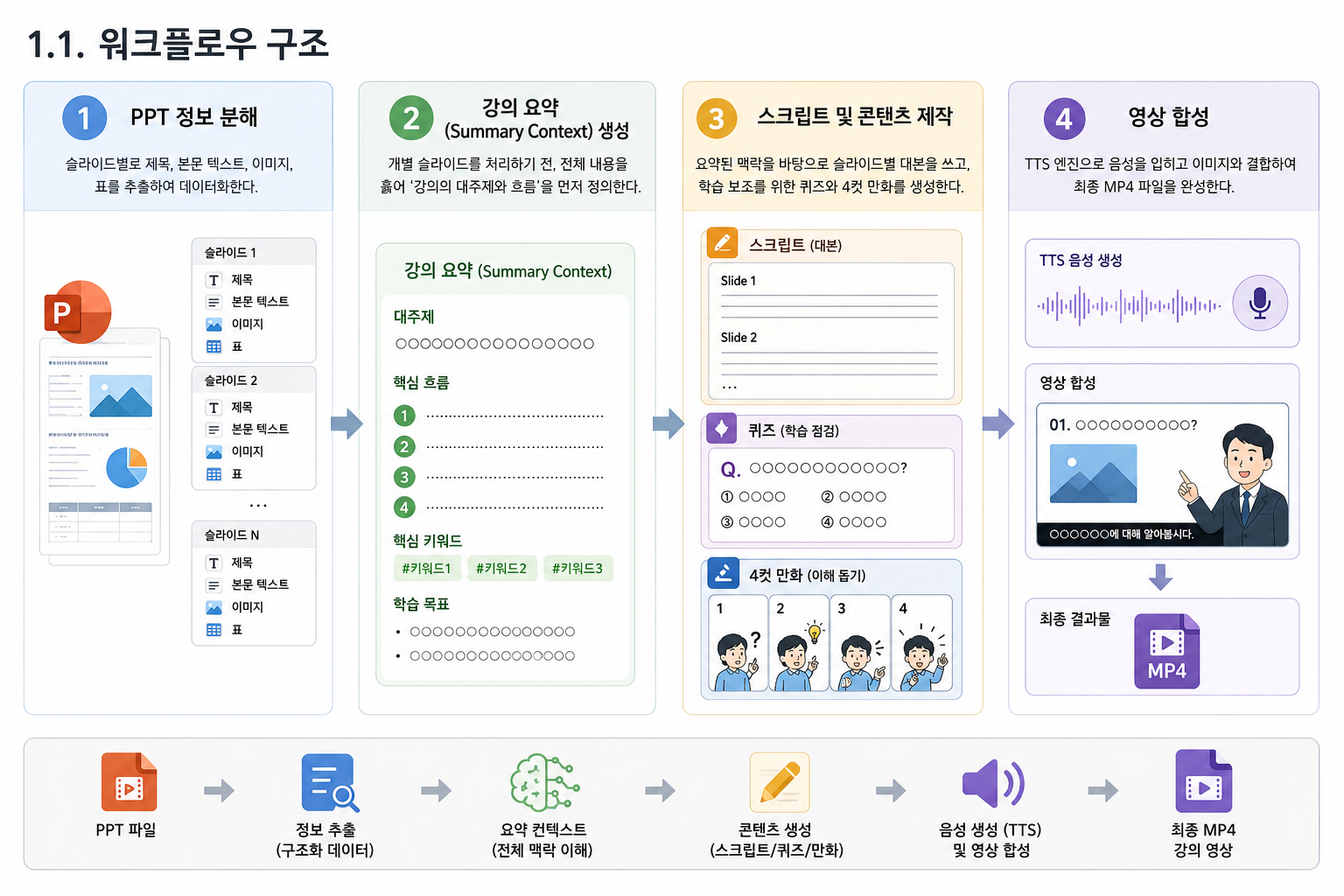
1. 프로젝트의 핵심 흐름
이번 프로젝트의 목표는 영상 제작 시간을 단축하고 품질을 균일화하여 강의 자료 학습의 효율성을 극대화하는 것이었다. 우리 조는 단순히 텍스트를 읽어주는 기능을 넘어, 교안의 전체 맥락을 이해하고 학습을 돕는 부가 콘텐츠(퀴즈, 만화 등)까지 생성하는 에이전트를 설계했다.
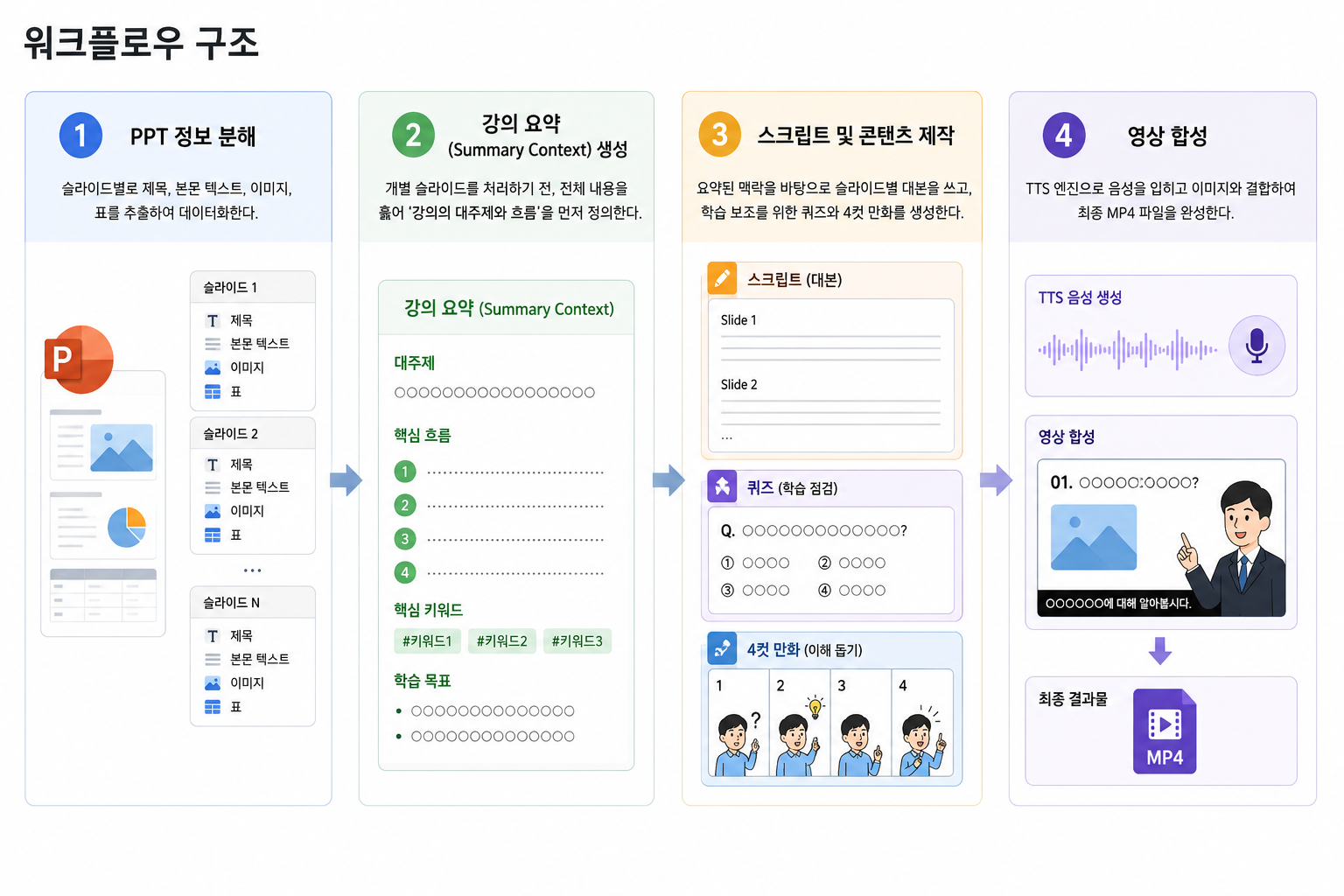
전체 워크플로우는 다음과 같은 구조로 진행된다.
- PPT 정보 분해: 슬라이드별로 제목, 본문, 이미지, 표를 추출하여 데이터화한다.
- 강의 요약 및 맥락 정의: 모든 슬라이드를 처리하기 전, 전체 내용을 훑어 강의의 대주제와 흐름을 정의한다. 이는 나중에 페이지별 대본을 쓸 때 일관성을 유지하는 기준이 된다.
- 콘텐츠 제작 루프: 각 슬라이드별로 외부 검색을 통해 내용을 보충하고, 스크립트와 퀴즈를 생성하며 음성(TTS) 및 영상 클립을 만든다.
- 최종 합성: 생성된 만화, 아웃트로, 슬라이드 영상들을 하나로 합치고 자막을 입혀 최종 결과물을 완성한다.
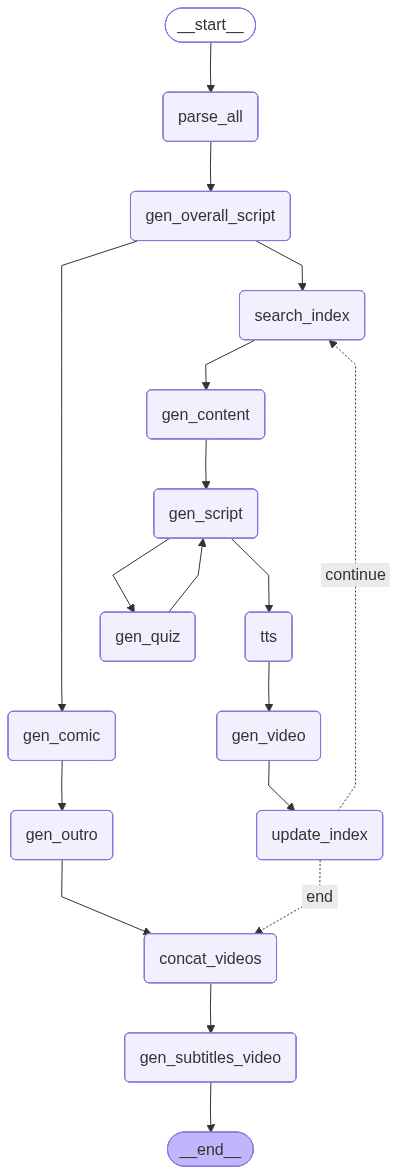
2. 핵심 노드 구성 및 역할
우리 조가 설계한 그래프의 각 노드는 독립적인 기능을 수행하면서도 State를 통해 긴밀하게 데이터를 주고받는다. 코드 로직을 바탕으로 정리한 주요 노드의 역할은 다음과 같다.
- parse_all: 프로젝트의 시작점으로, PPTX 파일에서 텍스트, 표, 이미지 등을 완벽하게 추출한다.
- gen_overall_script: 추출된 모든 정보를 토대로 강의 전체의 초안 스크립트를 작성한다.
- search_index: 슬라이드 제목을 키워드로 외부 검색을 수행한다. 교안에 담긴 내용 외에도 최신 정보나 보충 설명이 필요한 부분을 채워줌으로써 에이전트의 지식울 확장한다.
- gen_content & gen_script: 검색 결과와 교안 내용을 결합하여 페이지별 핵심 내용을 구성하고, 이를 바탕으로 실제 강사가 강의하는 듯한 자연스러운 대본을 작성한다. 이때 앞서 만든
overall_script를 참조하여 전체적인 톤앤매너를 유지한다. - gen_quiz: 작성된 스크립트를 바탕으로 학습자의 이해를 돕는 퀴즈를 생성한다.
- gen_comic & gen_outro: 강의 요약본을 바탕으로 4컷 만화를 생성하고 아웃트로 영상을 만든다.
- tts & gen_video: OpenAI의 TTS 엔진을 활용해 대본을 음성으로 변환하고, 슬라이드 이미지와 결합하여 개별 비디오 클립을 생성한다.
- update_index & node_check_finish: 조건부 엣지의 핵심이다. 모든 슬라이드가 처리될 때까지 인덱스를 업데이트하며 루프를 제어하고, 모든 작업이 완료되면 최종 영상 합성을 위한 단계로 흐름을 넘긴다.
- concat_videos & gen_subtitles_video: 흩어져 있던 영상 클립들과 만화 영상을 하나로 통합하고, Whisper 모델을 사용하여 자동 자막을 입히며 프로세스를 종료한다.
3. 설계한 그래프 구조 및 핵심 코드
그래프 관리자 역할을 맡고 내가 신경 쓴 부분은 비동기적인 작업 분기와 루프 제어의 정확성이었다. 아래는 LangGraph를 활용해 구축한 우리 조의 에이전트 구조이다.
from langgraph.graph import StateGraph, END
# 그래프 구축
w = StateGraph(State)
# 노드 추가
w.add_node("parse_all", node_parse_all)
w.add_node("gen_overall_script", node_gen_overall_script)
w.add_node('gen_comic', node_gen_comic)
w.add_node("gen_outro", node_gen_outro)
w.add_node("search_index", node_search_index)
w.add_node("gen_content", node_gen_content)
w.add_node("gen_script", node_gen_script)
w.add_node("tts", node_tts)
w.add_node("gen_video", node_gen_video)
w.add_node("update_index", node_update_slide_index)
w.add_node("concat_videos", node_concat_videos)
w.add_node("gen_quiz", node_gen_quiz)
w.add_node("gen_subtitles_video", node_gen_subtitles_video)
# 엣지 및 흐름 설계
w.set_entry_point("parse_all")
w.add_edge("parse_all", "gen_overall_script")
# 분기 1: 만화 및 아웃트로 생성
w.add_edge("gen_overall_script", "gen_comic")
w.add_edge("gen_comic", "gen_outro")
w.add_edge("gen_outro", "concat_videos")
# 분기 2: 슬라이드별 콘텐츠 제작 루프
w.add_edge("gen_overall_script", "search_index")
w.add_edge("search_index", "gen_content")
w.add_edge("gen_content", "gen_script")
w.add_edge("gen_script", "tts")
w.add_edge("gen_script", "gen_quiz")
w.add_edge("gen_quiz", "gen_script")
w.add_edge("tts", "gen_video")
w.add_edge("gen_video", "update_index")
# 조건부 분기: 모든 슬라이드 완료 여부 체크
w.add_conditional_edges(
"update_index",
node_check_finish,
{
"continue": "search_index",
"end": "concat_videos"
}
)
w.add_edge("concat_videos", "gen_subtitles_video")
w.add_edge("gen_subtitles_video", END)
app = w.compile()
4. 프로젝트를 통해 배운 점
이번 프로젝트는 단순히 기술적인 구현보다는 에이전트 시스템을 설계하고 협업하는 경험을 한거같다.
첫째로, 상태(State) 관리의 중요성을 깨달았다. LangGraph 내에서 데이터가 노드 사이를 흐를 때, 어떤 형식으로 저장되고 업데이트되는지 명확히 정의하지 않으면 전체 워크플로우가 꼬이기 쉽다. 특히 여러 팀원이 만든 노드를 통합할 때 공통된 데이터 규격을 유지하는 인터페이스 설계 능력이 필수적임을 느꼇다.
둘째로, 맥락(Context) 유지의 힘이다. 초기 모델에서는 슬라이드별로 대본을 따로 쓰다 보니 내용이 겹치거나 말투가 달라지는 문제가 있었다. 이를 해결하기 위해 Summary Context를 공유하도록 설계함으로써 전체 영상의 일관성을 확보할 수 있었다.
마지막으로, 협업의 가치이다. 팀원들이 각자의 노드에 역할을 맡아 개발을 진행해 만든 노드들을 최적의 경로로 엮어냈을 때, 혼자서라면 진행하기 힘들었던 부분들도 완성되는 과정에서 큰 보람을 느꼈다.
생각하기
마감시간 전까지 프로젝트를 무사히 제출하고, 다른 조들의 최종 발표를 들으며 참 많은 생각이 들었다. 프로젝트 초기 기획 단계부터 '이 에이전트를 누가, 어떻게 사용할 것인가'에 대한 타겟 유저를 명확히 정의하고 출발한 팀들도 있었고, 퀴즈나 만화 같은 보편적인 기능을 넘어 노드 자체에 참신한 아이디어를 녹여낸 팀들도 보였다.
우리 조의 경우 R&R을 나누고 각자 맡은 기능 구현에 몰두하느라, 프로젝트의 본질적인 주제나 기획의 방향성에 대해 깊게 토론할 시간이 부족했다. 서로 의견을 나누며 전체적인 그림을 다듬기보다 각자의 역할에만 집중했던 것 같아 결과물에 아쉽다..
아쉬운점도 남지만 오히려 시스템을 설계해 보면서, 아키텍처 관점에서 시스템을 더 고도화하고 싶은 생각이 들었다. 이번 경험을 발판 삼아 앞으로 다음 두 가지 주제를 더 깊이 파고들어 보려 한다.
1. State 최적화 및 메모리 관리
현재 구조는 추출된 텍스트, 요약본, 그리고 파일 경로들이 모두 하나의 State 딕셔너리에 담겨 노드 사이를 이동한다. 작은 규모의 프로젝트에서는 당장 문제가 없지만, 처리해야 할 슬라이드가 많아지거나 데이터의 크기가 커지면 메모리 효율성이 크게 떨어질 수밖에 없다. (우리는 3p 슬라이드만 실험을 했기때문에 후에 진행 해봐야겠다.)
이를 해결하기 위해 매번 전체 데이터를 복사해서 넘기는 대신, 필요한 정보만 선별하여 전달하는 방식을 고민해야 한다. 더 나아가 메타데이터(ID) 식별자만 State에 남기고, 실제 무거운 데이터는 외부 DB와 연동하여 필요할 때만 불러오는 효율적인 구조를 설계해봐야겠다.
2. RAG 고도화
현재 우리 에이전트는 부족한 내용을 채우기 위해 단순한 웹 검색 노드(TavilySearch)를 활용하고 있다. 하지만 타겟 사용자가 명확하게 정해진 교육용 에이전트로 거듭나려면 이를 넘어 벡터 데이터베이스를 활용해야 한다.
사내 문서나 전공 서적, 특정 도메인의 전문 지식을 청크 단위로 벡터화하여 저장해 두고, 스크립트를 작성할 때 이를 정확하게 검색해오는 고급 RAG 파이프라인으로 발전시키고 싶다. (공모전에서 사용할 수 있다면 해봐야겠다.)
02miniproject, 2번째 미니로젝트 회고록을 마무리한다.
협업은 언제나 재밌다.
