들어가며

최근 AX 공모전 제출 준비로 인해 블로그 활동이 조금 뜸해졌다. 문서화 작업에 예상보다 많은 시간이 들어가면서, GitHub PR 정리부터 노션 문서화, 보고서 작성까지 꽤 많은 에너지를 쏟게 된 것 같다. 그래도 그만큼 열심히 준비한 만큼 좋은 결과가 있기를 바라고 있다.
관심 있다면 프로젝트도 한번 구경해 보세요 :)
그 사이 03차 미니프로젝트와 에이블 데이(코딩 테스트 3문제 및 특별 강의)도 진행했는데, 이것들도 천천히 기록해 보려고 한다. 우선은 6주 차에 학습했던 LLMOps 개념부터 다시 정리하며 복습해보려 한다.
1. LLMOps 개념/필요성
최근 챗GPT나 Claude 같은 거대 언어 모델(LLM)을 활용한 서비스가 쏟아지고 있다. 나 역시 간단한 프롬프트 엔지니어링만으로도 그럴듯한 챗봇이나 자동화 스크립트를 만들어본 경험이 있다. (최근 뜻깊게 보고 있는 Claude.md 포함)이번 강의를 들으며, 단순히 API를 호출해 답변을 얻어내는 '데모 수준의 장난감'과 실제 비즈니스 환경에서 신뢰하고 사용할 수 있는 '상용 AI 시스템' 사이에는 거대한 벽이 존재한다는 것을 깨달았다.
그 벽을 넘기 위해 알아야 하는 개념이 바로 LLMOps(Large Language Model Operations) 다. 'LLMOps의 개념과 필요성'에 대해 내가 이해하고 정리한 내용을 다루어 보려고 한다.
1.1 LLMOps란 무엇이며, 기존 MLOps와 어떻게 다른가?
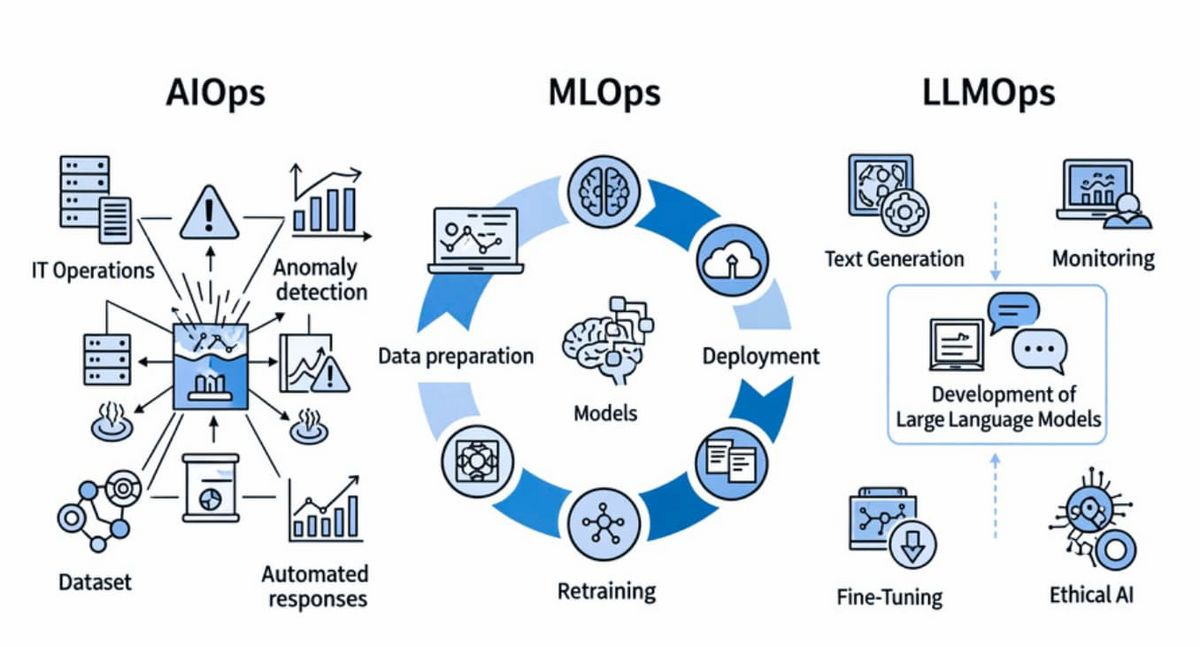
소프트웨어 개발에 관심이 있다면 데브옵스(DevOps)나 머신러닝 옵스(MLOps)라는 단어를 들어보았을 것이다. LLMOps는 쉽게 말해 LLM 기반의 애플리케이션을 개발, 배포, 유지보수하는 전체 생애주기를 관리하는 방법론이다. 처음에는 LLMOps가 기존의 MLOps와 비슷한 것이 아닐까 생각했다. 하지만 둘은 초점을 맞추는 영역 자체가 완전히 달랐다.
- MLOps의 핵심 (데이터와 모델의 학습): 기존의 인공지능 프로젝트는 우리가 직접 양질의 데이터를 수집하고, 정제하여, 모델을 학습시키고 정확도를 높이는 데 집중했다. 즉, '어떻게 하면 똑똑한 모델을 만들 것인가'가 주된 과제였다.
- LLMOps의 핵심 (시스템 통합과 통제): 반면 LLMOps 환경에서는 이미 오픈AI나 구글이 천문학적인 비용을 들여 학습시켜 놓은 초거대 모델을 가져다 쓴다. 모델 자체를 뜯어고치거나 재학습시키는 파인튜닝(Fine-tuning)보다는, 이 똑똑하지만 통제하기 힘든 모델을 '어떻게 우리 비즈니스 로직에 맞게 오케스트레이션하고 제어할 것인가' 에 집중한다.
프롬프트를 어떻게 버저닝(Versioning)하여 관리할 것인지, 모델이 외부 API나 도구(Tool)를 사용할 때 발생하는 오류를 어떻게 복구할 것인지, 복잡한 체인(Chain)의 흐름을 어떻게 시각화할 것인지가 LLMOps의 최대 관심사다.
1.2. 왜 LLMOps가 필수적인가?
전통적인 소프트웨어 프로그래밍은 명확하다. A라는 입력값을 주면 정해진 로직을 거쳐 반드시 B라는 출력값이 나온다. 하지만 LLM은 기본적으로 다음에 올 단어를 확률적으로 예측하는 모델이다. 이러한 태생적 특징 때문에 상용 서비스를 구축할 때 치명적인 3가지 리스크가 발생하게 되며, 이를 제어하기 위해 LLMOps가 필요하다.
1) 비결정론적 출력 (Non-deterministic Output)
가장 개발자를 괴롭히는 요소다. LLM은 동일한 프롬프트를 입력해도 어제 다르고 오늘 다른 답변을 내놓을 수 있다.
소프트웨어를 개발할 때는 코드가 정상적으로 작동하는지 확인하기 위해 단위 테스트를 작성한다. 하지만 LLM의 결과물은 매번 텍스트의 형태나 문맥이 미세하게 바뀌기 때문에 전통적인 방식의 테스트 코드(assert output == "정확한 텍스트")를 작성하는 것이 불가능하다.
이러한 비결정성 때문에 시스템이 예기치 못한 에러를 뱉었을 때 버그를 재현하기가 극도로 어려우며, 출력 결과의 포맷(예: JSON 형식으로만 응답해달라는 요청)이 깨지는 현상이 빈번하게 발생한다.
2) 기하급수적인 비용(Cost)과 지연 시간(Latency)
API를 통해 LLM을 사용할 때는 입력과 출력에 사용된 토큰의 수량만큼 요금이 부과된다. 단순한 1회성 질문과 답변이라면 큰 문제가 되지 않지만, 에이전트시스템으로 넘어가면 이야기가 달라진다.
최근의 AI 시스템은 문제를 스스로 계획하고, 검색하고, 코드를 실행하고, 결과를 스스로 검토하여 틀리면 다시 처음으로 돌아가는 루프 구조를 가진다. 만약 모델이 방향을 잘못 잡아 무한 루프에 빠지게 된다면, 에이전트는 계속해서 이전까지의 대화 기록을 통째로 짊어지고 모델을 호출하게 된다. 이는 순식간에 막대한 API 과금으로 이어질 수 있다.
또한, 하나의 최종 답변을 만들기 위해 모델을 내부적으로 5~10번씩 호출하게 되면, 사용자가 화면 앞에서 응답을 기다리는 지연 시간이 수십 초 단위로 길어져 서비스의 사용자 경험을 심각하게 훼손하게 된다.
3) 환각(Hallucination)의 연쇄 작용
LLM이 사실이 아닌 내용을 그럴듯하게 지어내는 환각 현상은 널리 알려져 있다. 하지만 멀티 에이전트(Multi-Agent) 시스템에서는 이 환각이 훨씬 더 무서운 결과를 초래한다.
예를 들어, 계약서를 분석하는 에이전트 파이프라인이 있다고 가정해 보자. 첫 번째 정보 추출 에이전트가 존재하지 않는 위약금 조항을 환각으로 만들어냈다. 만약 이 결과가 필터링 없이 두 번째 요약 에이전트, 세 번째 메일 발송 에이전트로 그대로 전달된다면 어떻게 될까? 단순한 오답 하나가 눈덩이처럼 불어나 기업의 법적 책임 문제나 심각한 비즈니스 리스크로 직결될 수 있다.
1.3. '잘 작동하는 AI' -> '통제 가능한 AI'
앞서 말한 리스크들을 완벽하게 0으로 만드는 것은 현재의 LLM 기술로는 불가능에 가깝다. 그렇다면 어떻게 접근해야 할까? 강의에 핵심 메시지는 바로 '통제 가능성' 을 확보하는 것이었다. 성공적으로 작동할 때의 데모 영상은 누구나 화려하게 만들 수 있다. 하지만 진정한 엔지니어링은 실패했을 때 발견된다.
- 가시성과 투명성: 시스템 내부에서 에이전트들이 어떤 프롬프트를 주고받았고, 어떤 도구를 사용했으며, 어느 지점에서 시간이 가장 오래 걸렸는지 한눈에 추적할 수 있어야 한다.
- 상태 추적과 재현성: 에러가 발생했다면, 그 에러가 발생하기 직전의 데이터 상태로 돌아가 디버깅을 하고 재실행할 수 있는 구조가 필요하다.
- 안전장치(개입 가능성): AI가 중요한 의사결정을 내리기 직전, 혹은 특정 비용 한도에 도달했을 때 프로세스를 멈추고 인간이 직접 개입하여 승인하거나 수정할 수 있는 연결 고리를 만들어 두어야 한다.
결국 LLMOps의 첫걸음은 "AI 모델을 그냥 믿고 맡겨두면 알아서 잘하겠지"라는 환상을 버리는 것에서 시작한다. AI는 매우 유능한 인턴이지만, 그 인턴이 사고를 치지 않도록 업무 프로세스를 잘게 쪼개고, 결재 라인을 만들고, 업무 지시서를 명확히 문서화하며, 중간 보고를 받도록 시스템을 설계하는 과정이 반드시 필요하다.
이러한 통제 가능한 아키텍처를 만들기 위해 어떠한 방식의 설계 절차를 거치고, 어떤 문서들을 작성해야하는지 알아보자.
참고/출처
https://tech.ktcloud.com/entry/2026-01-ktcloud-mlops-llmops-%EC%9A%B4%EC%98%81%EC%B2%B4%EA%B3%84-%EC%A0%84%ED%99%98 (많이 배웁니다..)
https://www.databricks.com/blog/what-is-llmops
https://solutionshub.epam.com/blog/post/aiops
https://www.redhat.com/ko/topics/ai/llmops
2. AI Agent 시스템 설계 절차와 5대 핵심 문서화 전략
강의를 들으며 내 기존 개발 방식을 다시 돌아보게 되었다. 나는 그동안 아이디어가 떠오르면 전체적인 흐름을 먼저 머릿속에 그리고, 이를 여러 섹션으로 나눈 뒤 어떻게 개발하고 연결할지 구상하며 부분적으로 기능을 붙여나가는 식으로 개발을 진행해 왔다. 일반적인 애플리케이션이나 단순한 스크립트를 짤 때는 이 방식이 꽤 유용했다. 하지만 데모 수준을 넘어선 LLM 기반의 멀티 에이전트 시스템을 구축할 때 이런 머릿속 구상이나 점진적인 기능 추가 방식은 한계가 명확했다. 에이전트가 두세 개만 넘어가도 서로 어떤 데이터를 주고받는지, 예외 상황에서 흐름이 어떻게 꼬이는지 정확히 추적하고 통제하기가 불가능해지기 때문이다.
성공적인 AI Agent 시스템을 위해서는 코딩 전에 완벽한 문서화 형태의 설계가 선행되어야 한다. 이번 글에서는 내가 학습한 에이전트 시스템 설계의 5단계 흐름과, 5개 설계 문서에 대해 정리해 보았다.
2.1. AI Agent 시스템 설계 5단계 흐름
개발자가 가장 저지르기 쉬운 실수는 '문제'보다 'AI 모델'을 먼저 생각하는 것이다. LLMOps 관점에서는 철저하게 비즈니스 문제 해결을 위한 소프트웨어 공학적 설계 절차를 따른다.
- 문제 정의 (Problem): 우리가 현재 어떤 비즈니스적 어려움을 겪고 있으며, 기존 시스템의 한계는 무엇인지 명확히 한다.
- 목표 정의 (Goal): AI 시스템을 도입해서 얻고자 하는 최종 결과물과 성공을 측정할 수 있는 평가 지표를 수립한다.
- 시나리오 정의 (Scenario): 사용자가 시스템에 어떻게 접근하고, 어떤 입력을 주며, 최종적으로 어떤 형태의 출력을 받게 되는지 Use Case 기반의 서비스 흐름을 그린다.
- 구조 설계 (Architecture Design): 요구사항을 해결하기 위해 어떤 역할을 가진 에이전트들이 필요한지 쪼개고, 이들이 어떻게 상호작용할지 전체적인 워크플로우 초안을 그린다.
- 상세 설계 (Detailed Design): 본격적인 구현 직전, 각 에이전트의 구체적인 입력/출력값, 프롬프트 내용, 데이터의 상태 구조를 상세 문서로 명세화한다.
이 중에서 시스템의 안정성과 직결되는 가장 중요한 작업이 바로 마지막 5단계인 '상세 설계'다.
2.2. 통제를 위한 5대 핵심 설계 문서
강의에서 제공된 설계 문서 양식들을 직접 뜯어보면서, 시스템을 톱니바퀴처럼 맞물려 돌아가게 만드는 요소가 무엇인지 파악할 수 있었다. 프로젝트를 진행할떄 아래의 5가지 문서를 통해 에이전트를 완벽하게 제어하는것이 목표다.
1) Agent 역할 정의서 (Agent Role Definition)
각 에이전트에게 명확한 자아와 책임 범위를 부여하는 문서다. 하나의 에이전트가 너무 많은 일을 하면 환각이 발생할 확률이 급격히 높아지므로 역할을 철저히 분리해야 한다.
- 목적 및 역할: 예를 들어 Planner Agent는 계획만 세우고, Executor Agent는 계획에 따라 계약서에서 정보만 추출하며, Critic Agent는 결과물의 품질만 평가하도록 쪼갠다.
- 입력과 출력: 해당 에이전트가 실행되기 위해 필요한 필수 데이터(Input)와 다음 노드로 넘겨줄 결과 데이터(Output)를 명시한다.
- 제약 조건 및 실패 리스크: 문서에 없는 내용은 절대 추측하지 말 것, 실행 로직을 포함하지 말 것 같은 엄격한 규칙과, 이 에이전트가 실패했을 때 전체 워크플로우에 미치는 파급력을 기록한다.
2) Workflow 명세서 (Workflow Specification)
역할이 부여된 에이전트들이 어떤 순서로 동작하는지 전체적인 실행 뼈대를 정의한다.
시작 단계에서 어떤 데이터가 입력되는지, 그리고 Planner에서 Executor, Critic, Supervisor를 거쳐 종료에 이르는 각 단계마다 데이터가 어떻게 가공되고 전달되는지를 한눈에 볼 수 있도록 도식화 및 문서화한다. 이 문서가 있어야만 무한 루프에 빠지는 설계적 결함을 사전에 방지할 수 있다.
3) State 정의서 (State Specification)
개인적으로 멀티 에이전트 시스템에서 가장 중요하다고 느낀 부분이다. 에이전트 시스템은 'State(상태)'라는 전역 객체를 메모리처럼 서로 공유하며 작업을 진행한다.
- 변수 및 데이터 타입 정의: 전체 과정을 기록할
messages, 사용자의 최초 요구사항인user_request, 에이전트 간 주고받을extracted_info나summary등 상태에 담길 모든 변수를 정의한다. - 업데이트 방식 (Reducer vs Overwrite): 특정 변수에 새로운 값이 들어왔을 때, 이전 값을 지우고 덮어쓸 것인지(Overwrite), 아니면 기존 배열에 값을 계속 누적하여 추가할 것인지(Reducer)를 설계한다. 예를 들어 대화 기록인
messages는 누적되어야 하고, 현재 실행 단계를 나타내는current_step_index는 다음 숫자로 덮어써져야 한다. 이 규칙이 어긋나면 시스템은 과거의 기억을 잃거나 불필요한 데이터 폭탄을 안고 실행을 반복하게 된다.
4) Decision Policy (의사결정 정책서)
분기점(라우팅)에서 어떤 조건일 때 어떤 에이전트를 실행할지, 언제 반복을 종료할지 명확한 수학적/논리적 조건식으로 정의한 문서다.
- 실행 및 평가 제어: 계획된 단계가 남아있으면 다음 Executor를 실행하고, 모든 단계가 끝났으면 Critic을 호출하여 평가를 받게 한다.
- 재실행 및 강제 종료 정책: Critic의 평가 결과가 거절일 때 무조건 다시 실행하는 것이 아니라, 현재 반복 횟수가 최대 허용 횟수 미만일 때만 Planner로 돌아가 재계획을 수행한다. 만약 제한 횟수에 도달했다면 비용 폭증을 막기 위해 현재까지의 결과만 반환하고 강제로 종료하도록 조건을 촘촘하게 설정한다.
5) Prompt 명세서 (Prompt Specification)
개발자가 코딩할 때 변수명을 정하듯, LLM에게 전달할 프롬프트의 골격을 문서로 고정한다.
- 페르소나와 지침: 에이전트가 맡은 역할에 몰입할 수 있도록 구체적인 전문가 페르소나를 부여하고, 수행해야 할 과업을 간결하고 명확하게 지시한다.
- 엄격한 출력 형식(Formatting): 비결정론적 특성을 통제하기 위해 응답 형식을 매우 엄격하게 제한한다. 예를 들어 Planner는 반드시 파이썬 리스트 형태로만 응답하도록 강제하고, 다른 부연 설명은 일절 금지한다. 이러한 출력 포맷을 사전에 문서로 확정해야만 코드로 파싱할 때 발생하는 오류를 막을 수 있다.
이 5가지 문서를 꼼꼼히 작성하는 과정이 처음에는 꽤나 번거롭고 시간이 오래 걸리는 작업처럼 느껴졌다. 부분적으로 기능을 떼어 붙여가며 코딩하던 나의 익숙한 방식과는 다소 거리가 있었기 때문이다. 하지만 복잡도를 높여가며 테스트를 해보니, 이 설계 문서들이야말로 개발 시간을 줄여주고 시스템을 내 장악하는데 큰 영향을 준다. 기능이 얽혀서 버그가 났을 때 어디를 고쳐야 할지, 어떤 상태 값이 잘못되었는지 문서에 이미 답이 다 적혀 있기 때문이다.
참고/출처
https://wikidocs.net/blog/@jaehong/9475/
https://www.youtube.com/watch?v=UCV3lAo0fhQ
https://lobehub.com/skills/openclaw-skills-naver-search (이런것도 있구나)
3. 역할 기반 설계와 워크플로우를 지휘하는 Supervisor 패턴
구체적으로 에이전트들의 역할을 어떻게 분리하고 이들의 실행 흐름을 어떻게 중앙에서 강력하게 통제하는지 그 아키텍처의 핵심인 역할 기반 설계(Role-based Design)와 Supervisor 패턴에 대해 복습해보려고한다.
3.1. 머릿속의 섹션 구상을 에이전트의 역할 분리로 구체화하기
나는 위에서 한번 언급 했듯 평소에 새로운 아이디어가 떠오르면 전체적인 흐름을 먼저 머릿속에 그려둔 뒤, 이를 여러 섹션으로 나눈다. 그리고 각 섹션별로 어떻게 개발하고 연결해야 할지 틀을 잡은 다음, 부분적으로 기능을 하나씩 붙여가며 살을 붙이는 방식으로 개발을 진행해 왔다. 이러한 탑다운(Top-down) 방식의 접근과 점진적인 기능 결합은 일반적인 애플리케이션 개발에서 코드를 깔끔하게 유지하는 데 큰 도움이 되었다.
강의를 들으며 놀라웠던 점은, 내가 평소에 하던 이 개발 습관이 LLMOps에서 복잡한 문제를 해결하기 위해 사용하는 역할 기반 설계의 철학과 정확히 맞물려 있다는 사실이었다. 거대하고 모호한 비즈니스 문제를 하나의 프롬프트로 해결하려 하지 않고, 전체 흐름을 논리적인 섹션으로 쪼갠 뒤 그 섹션마다 전담 전문가(에이전트)를 배치하여 부분적인 기능을 독립적으로 수행하게 만드는 것이다.
다만 결정적인 차이점이 있었다. 일반적인 소프트웨어에서는 내가 나눈 섹션들이 정해진 로직에 따라 완벽하게 맞물려 돌아가지만, LLM 환경에서는 각 섹션을 담당하는 주체가 비결정론적인 인공지능이라는 점이다. 따라서 머릿속 구상에만 의존해 대강 기능을 붙여 나가면 에이전트들이 서로 엉뚱한 데이터를 주고받으며 전체 파이프라인이 쉽게 무너진다. 이를 방지하기 위해 전문가 에이전트들의 역할을 수학적으로 명확히 분리하고, 이들을 유기적으로 연결하는 고도화된 아키텍처 패턴이 필요하다.
3.2. Planner, Executor, Critic의 전문가 삼각 편대
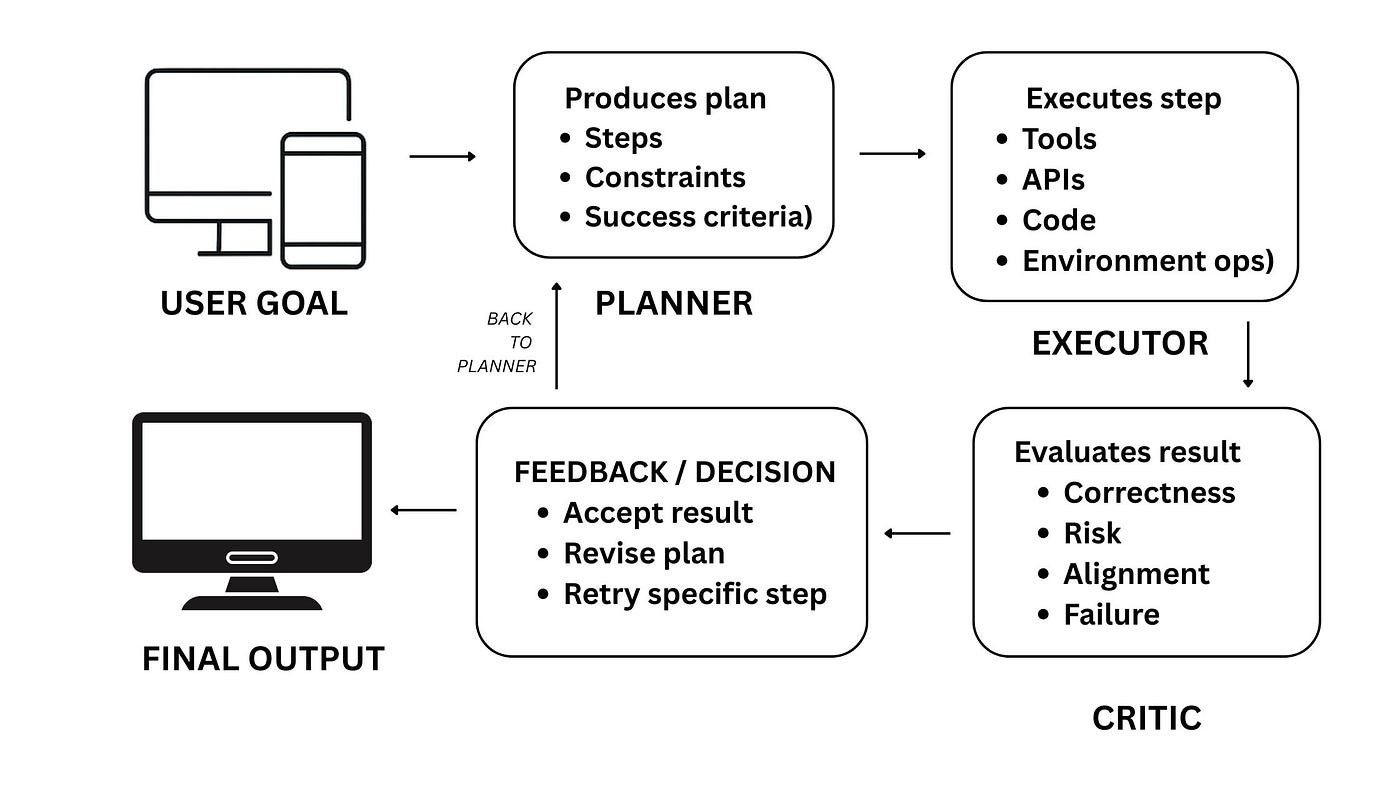
역할 기반 설계에서 가장 널리 쓰이면서도 강력한 구조는 복잡한 과업을 Planner(기획자), Executor(수행자), Critic(검토자) 이라는 세 가지 축으로 분리하는 것이다. 하나의 AI에게 "문서를 분석하고 요약해서 검증까지 끝내라"고 하면 과부하가 걸려 환각을 일으키기 쉽지만, 역할을 쪼개면 각 단계에서 모델이 집중해야 할 컨텍스트의 크기가 줄어들어 품질이 극대화된다.
1) Planner Agent: 전략과 계획 수립의 사령탑
Planner는 사용자의 최초 요구사항과 분석해야 할 원문 데이터를 입력받아, 직접 문제를 해결하는 대신 문제를 해결하기 위한 '단계별 실행 계획(Plan)'을 수립하는 역할을 한다.
- 동작 원리: 사용자가 아무리 복잡하거나 모호한 요청을 하더라도, Planner는 자신이 사용할 수 있는 도구나 하위 에이전트들의 목록을 고려하여 최적의 실행 순서를 정의한다. 예를 들어 프롬프트 명세서에 정의된 규칙에 따라 반드시 파이썬 리스트 형태(
["executor1", "executor2"])로만 실행 계획을 출력하도록 강력히 통제된다. 부연 설명이나 변명을 일절 배제함으로써 후속 코드가 결과를 안정적으로 파싱할 수 있게 만든다. - 재계획(Replanning) 기능: Planner의 진짜 가치는 실패했을 때 드러난다. 뒤에서 설명할 Critic에 의해 결과물이 거절(REJECTED)되면, Planner는 단순하게 이전 계획을 반복하는 것이 아니라 State에 누적된 Critic의 구체적인 거절 사유(Critique reason)를 읽어 들인다. "어느 지점의 정보 추출이 부실했다"는 피드백을 바탕으로 계획을 전면 수정하거나 새로운 단계를 추가하는 재계획을 수행한다.
2) Executor Agent: 철저하게 지침에 따르는 유닛
Executor는 Planner가 수립한 계획의 단위를 하나씩 넘겨받아 실제 데이터 가공 및 분석을 수행하는 에이전트다. 프로젝트의 특성에 따라 여러 개의 Executor를 독립적으로 배치할 수 있다. 이번 계약서 분석 워크플로우 예시에서는 두 가지 Executor로 세분화되었다.
- Executor1 (정보 추출 전문가): 계약서 원문과 사용자 요청을 비교하여 계약 당사자, 계약 기간, 계약 금액 및 사용자가 별도로 요구한 특약 사항 등의 핵심 정보만 항목형으로 깔끔하게 추출한다. 프롬프트 지침에 "문서에 없는 내용은 절대로 유추하거나 추측하지 말 것"이라는 제약 조건을 엄격하게 고정하여 환각 발생을 차단한다. 작업을 마치면 추출된 정보를 State에 기록하고, 현재 진행 단계를 나타내는 인덱스(
current_step_index)를 1 증가시킨 뒤 제어권을 넘긴다. - Executor2 (요약 전문가): 원문 문서와 Executor1이 앞서 추출해 둔 핵심 정보를 동시에 입력받아 전체 내용을 명확하게 요약하는 실무를 담당한다. 추출된 정보를 레퍼런스로 삼기 때문에 완전히 엉뚱한 내용으로 요약할 위험이 현저히 줄어든다. 지침에 따라 3문장 이내의 bullet-point 형식 등 일관된 포맷으로 결과물(
summary)을 작성하여 State를 업데이트한다.
3) Critic Agent: 타협 없는 품질 검증관
Critic은 앞선 Executor들이 만들어낸 최종 결과물(extracted_info, summary)이 사용자의 최초 요구사항을 완벽하게 충족하는지 제3자의 시선에서 냉정하게 평가하는 에이전트다.
- 평가와 사유의 명시: Critic은 새로운 정보를 창출해서는 안 되며, 오직 검증만 수행해야 한다. 결과가 합격점이라면 승인(
critique_decision = "APPROVED")을 내리고 워크플로우를 종료 단계로 이끈다. 만약 지침이 누락되었거나 품질이 떨어진다면 과감하게 거절(critique_decision = "REJECTED") 판정을 내린다. 이때 가장 중요한 것은 단순히 거절하는 것에 그치지 않고, Planner가 계획을 보정할 수 있도록 구체적인 불합격 사유(critique_reason)를 논리적 문장으로 기록하여 State에 남겨야 한다는 점이다.
3.3. 왜 Supervisor 패턴인가? 중앙 집권식 흐름 통제의 힘
Planner, Executor, Critic을 각각 잘 만드는 것보다 훨씬 더 중요한 과제는 이 에이전트들을 어떻게 연결할 것인가이다.
에이전트 시스템을 처음 개발할 때 흔히 하는 실수는 에이전트가 직접 다음 행동을 결정하게 만드는 것이다. 예를 들어 Executor1이 끝나면 스스로 판단해서 Executor2를 호출하고, Critic이 끝나면 Critic 내부 로직 안에서 판단해 Planner로 직접 데이터를 던지는 방식이다. 이런 구조는 내가 평소 하던 대로 섹션을 나눠 기능을 붙여나갈 때 자칫 발생하기 쉬운 끈끈한 결합 상태를 유발한다. 에이전트가 많아질수록 화살표가 사방으로 얽히며 코드가 스파게티처럼 꼬이고, 예외 처리가 불가능해진다.
이 문제를 해결하는 아키텍처가 바로 Supervisor 패턴이다. 모든 하위 에이전트들은 서로의 존재를 알 필요가 없다. 이들은 오직 전역 상태(State)에서 자신에게 필요한 입력값만 가져와 작업을 수행하고, 결과물만 다시 State에 던진 뒤 실행을 종료한다. 그리고 에이전트들의 다음 실행 노드를 결정하고 라우팅하는 모든 제어권은 중앙의 Supervisor가 전담한다.
Supervisor 패턴이 제공하는 통제력의 이점은 명확하다.
1) 제어 로직과 실행 로직의 완전한 분리
Critic 에이전트는 품질 평가만 담당할 뿐, 시스템의 흐름을 바꾸는 라우팅 코드를 내포하지 않는다. Critic이 내린 판정 결과(critique_decision)가 State에 저장되면, 규칙 기반으로 설계된 Supervisor가 Decision Policy(의사결정 정책서)에 맞춰 물리적인 조건 분기를 실행한다. AI의 모호한 판단에 시스템 흐름 제어를 맡기지 않고, 개발자가 작성한 명확한 소스코드 라인 위에서 흐름을 제어하기 때문에 시스템 가시성이 극대화된다.
2) 비용 방어를 위한 루프 통제 (max_iterations)
비결정론적인 LLM 특성상 Planner와 Critic 사이에 갇혀 무한히 수정을 반복하는 루프가 발생할 수 있다. 이는 상용 서비스에서 심각한 API 비용 폭증의 원인이 된다.
Supervisor는 중앙에서 반복 횟수(iteration)라는 상태 값을 직접 카운트하고 관리한다. Critic이 아무리 거절 판정을 내렸더라도, Supervisor 단에서 사전에 설정된 최대 허용 횟수(max_iterations)에 도달했다고 판단하면 재계획을 차단하고 현재까지의 결과물만 들고 프로세스를 강제 종료(END) 시킬 수 있는 강력한 브레이크 역할을 수행한다.
3.4. 통제 가능한 아키텍처가 주는 확신
아이디어를 섹션별로 분리하고 부분적인 기능을 결합해 나가던 나의 개발 방식이, Supervisor라는 명확한 조정자와 상태 중심의 통제 구조를 만나면서 비로소 상용 수준의 AI 에이전트 아키텍처로 완성될 수 있음을 배웠다. 각 에이전트의 독립성을 보장하고 중앙에서 규칙 기반으로 흐름을 장악하는 이 아키텍처는 시스템이 복잡해질수록 진가를 발휘할 것이라고 생각이 들었다.
이러한 대규모 시스템 통제 기법을 깊이 있게 학습하면서, 자연스럽게 내가 프로젝트를 진행하면서 관심 있게 바라보던 구체적인 엔지니어링 도메인에 이 아키텍처를 대입해 보게 되었다. 특히 수많은 회로와 커넥터, 배선 지침이 복잡하게 얽혀 있어 엄격한 규칙과 품질 검증이 필수적인 하네스 엔지니어링 분야가 떠올랐다. 방대한 하네스 설계 표준 문서를 분석하고, 사양에 맞춰 회로 배치를 계획하며, 설계 결함을 검증하는 일련의 과정을 오늘 배운 Planner, Executor, Critic 삼각 편대와 Supervisor 패턴으로 구조화한다면 대단히 강력한 자동화 시스템을 만들 수 있겠다는 생각이 들었다.
참고/출처
https://medium.com/@servifyspheresolutions/planner-executor-critic-engineering-reliable-ai-agents-4eed3b5ddb54
https://dl-pkw.tistory.com/entry/8-2-%EC%97%AD%ED%95%A0-%EB%B6%84%EB%A6%AC-Planner-Worker-Critic
https://breyta.ai/blog/ai-agent-architecture-patterns
4. 시스템의 안전장치를 확보하는 인간 개입(Human-In-The-Loop) 설계
구조적으로 완벽해 보이는 에이전트 아키텍처를 설계하고 나면, 모든 것을 AI에게 맡겨두고 알아서 완벽하게 처리해 주기를 기대하게 된다. 하지만 LLM의 본질적인 한계인 환각과 비결정성을 완벽하게 제거할 수 없는 한, 100% 완전 자동화는 비즈니스 환경에서는 폭탄과 같다. 특히 금융 거래, 법률 계약서 검토, 혹은 내가 관심을 두고 있는 하네스 엔지니어링의 배선 설계 사양 검증처럼 작은 오류 하나가 막대한 자산 손실이나 안전사고로 직결되는 고위험 도메인에서는 더욱 그렇다.
이러한 문제를 해결하기 위해 시스템 내부의 가장 강력한 방어선이자 통제 장치로서 사람을 워크플로우에 명시적으로 포함하는 HITL(Human-In-The-Loop) 설계에 대해 깊이 있게 학습했다.
4.1. 완전 자동화의 환상과 HITL의 본질
처음 에이전트 시스템을 접했을 때는 인간의 개입이 없는 완전한 자동화만이 정답이라고 생각했다. 사람이 일일이 확인해야 한다면 인공지능을 도입하는 의미가 퇴색되는 것이 아닌가 하는 의문이 들었기 때문이다. 하지만 상용 수준의 LLMOps를 구축할 때 HITL은 자동화의 실패를 의미하는 것이 아니라, 오히려 시스템의 신뢰성을 완성하는 컴포넌트임을 배웠다.
비즈니스 프로세스에서 AI는 매우 빠르고 효율적으로 방대한 데이터를 처리하는 유능한 일꾼이지만, 최종적인 법적 책임이나 안전성에 대한 담보는 오직 인간만이 할 수 있다. 따라서 HITL은 시스템의 실행 과정 중에 사람이 검토하고 승인하거나 수정할 수 있는 연결 고리를 의도적으로 배치하는 설계 기법이다. 이를 통해 AI가 가진 한계를 인간의 판단력으로 보완하며, 동시에 인간이 모든 과정을 처음부터 끝까지 수작업으로 처리하던 비효율을 획기적으로 줄이는 균형점을 찾을 수 있다.
4.2. 사전 통제(Proactive Control) 계층으로서의 HITL
인간의 개입을 설계할 때 가장 주의해야 할 점은 문제의 발생 시점이다. 많은 개발자가 저지르는 실수는 시스템이 예측하지 못한 에러를 뱉으며 멈추거나, 이미 잘못된 결과물이 고객에게 발송된 이후에야 사람이 개입하는 사후 조치(Reactive) 방식으로 시스템을 만드는 것이다.
LLMOps에서 다루는 HITL은 철저하게 사전 통제(Proactive Control) 계층으로 설계되어야 한다.
- Reactive (사후 조치): 에이전트가 환각 기반의 잘못된 분석 결과를 담아 이메일을 발송한 뒤, 고객의 항의를 받고 관리자가 로그를 보며 수동으로 수습하는 방식이다. 이미 비즈니스적 신뢰가 무너진 상태이므로 시스템으로서 가치가 떨어진다.
- Proactive (사전 통제): 에이전트가 분석 결과를 완성하더라도 즉시 발송 노드로 진입하지 못하도록 워크플로우 중간에 의도적인 '대기 상태(Pause)' 노드를 설계한다. 관리자가 해당 결과를 화면에서 검토하고 승인 버튼을 누르기 전까지는 다음 프로세스로 절대 진행되지 않도록 기술적 안전장치를 걸어두는 방식이다.
이러한 사전 통제 구조를 통해 AI가 무한 루프에 빠져 API 비용을 날리거나, 치명적인 결함이 외부로 노출되는 리스크를 완벽하게 차단할 수 있다.
4.3. Supervisor 패턴 내에서의 HITL 구현 원칙
인간 개입을 시스템에 녹여낼 때, 아무렇게나 사람을 호출하도록 코드를 짜면 아키텍처가 순식간에 붕괴된다. 강의를 통해 배운 Supervisor 패턴 기반의 HITL 구현에는 두 가지 철저한 엔지니어링 원칙이 존재했다.
1) 하위 Worker 에이전트는 절대로 사람을 직접 호출하지 않는다
만약 정보 추출을 담당하는 Executor1이나 요약을 담당하는 Executor2가 작업을 하다가 "이 부분은 모호하니 사람이 확인해 주세요"라고 직접 인간 개입 노드로 흐름을 넘기게 되면, 전체 워크플로우의 제어권이 사방으로 분산된다. 에이전트가 늘어날수록 어떤 노드에서 사람을 호출했는지 추적하기 어려워지며, 중앙의 의사결정 정책이 무력화된다.
따라서 Worker 에이전트들은 오직 자신이 맡은 기능만 수행하고 결과물과 상태를 공유 객체(State)에 기록한 뒤 종료되어야 한다. 상태를 읽은 중앙의 Supervisor만이 현재 에이전트의 수행 결과나 카운트된 리스크 점수를 기반으로 HITL 노드(human_review)를 트리거할 수 있어야 한다. 제어권을 중앙 집권식으로 유지해야만 일관된 운영 정책을 적용할 수 있다.
2) 인간을 비결정론적인 외부 노드로 취급한다
시스템 아키텍처 관점에서 볼 때, 인간은 일반적인 파이썬 함수처럼 즉각적인 응답을 주는 존재가 아니다. 검토하는 데 수 분에서 수 시간이 걸릴 수도 있고, 한 사람의 인건비가 소요되므로 비용도 높다. 또한 사람마다 판단 기준이 조금씩 다를 수 있으므로 비결정론적인 특성을 지닌다.
즉, 시스템 입장에서는 인간 역시 LLM 모델이나 외부의 거대한 검색 API를 호출하는 것과 다름없는 '외부 도구 혹은 독립된 노드'로 취급해야 한다. 그래프 상에 인간 개입 노드를 명시적으로 배치하고, 사람이 응답을 줄 때까지 상태를 안전하게 보존하며 대기할 수 있는 구조가 뒷받침되어야 상용 서비스 환경에서 시스템이 멈추지 않고 매끄럽게 구동될 수 있다.
4.4. 인간 개입 이후의 사후 흐름 처리
인간 개입 노드가 트리거되어 관리자가 에이전트의 중간 결과물을 검토한 후, 내릴 수 있는 의사결정의 유형은 명확하게 구조화되어야 한다. 시스템은 사람이 입력한 피드백에 따라 이후의 워크플로우 흐름을 크게 세 가지 분기로 나누어 처리하도록 설계한다.
1) APPROVE (승인)
에이전트가 수행한 정보 추출이나 요약의 품질이 완벽하다고 판단하여 승인하는 경우다. 이 조건이 만족되면 Supervisor는 해당 상태를 확인하고 프로세스를 성공적으로 종료하거나, 실제 메일 발송이나 데이터베이스 반영과 같은 다음 후속 노드로 흐름을 이어가게 만든다.
2) ABORT (중단)
에이전트가 도저히 해결할 수 없는 잘못된 방향으로 계획을 세웠거나, 분석 대상 문서 자체가 훼손되어 있어서 더 이상 프로세스를 진행하는 것이 의미가 없다고 판단하는 경우다. 이 경우 추가적인 API 비용 낭비를 막기 위해 전체 워크플로우를 즉시 강제 종료 시키고 시스템을 초기화한다.
3) REVISE (수정 및 재계획)
결과물에 일부 누락이나 오류가 있어 보정이 필요한 경우다. 이때 인간은 단순히 거절 버튼만 누르는 것이 아니라, 무엇이 잘못되었는지 구체적인 가이드라인이나 지침을 텍스트 형태의 피드백으로 작성하여 공유 상태에 저장한다.
Supervisor는 이 REVISE 신호와 함께 저장된 피드백을 확인하면, 시스템의 제어권을 다시 맨 앞단의 Planner Agent로 돌려보낸다. Planner는 사용자의 최초 요청뿐만 아니라, 방금 전 인간이 남긴 구체적인 피드백(human_feedback)까지 컨텍스트로 함께 입력받는다. "인간 검토자가 이 지점의 수치 오류를 지적했으니, 이를 반영하여 실행 계획을 수정하자"라며 계획을 전면 보정하는 재계획을 수행하게 된다. 인간과 AI가 협력하는 유기적인 피드백 루프가 완성되는 지점이다.
4.5. 인간과 AI의 협업 체계가 주는 안정감
HITL 설계를 배우면서 AI 에이전트 시스템을 대하는 시야가 넓어졌다. 모든 것을 인공지능이 완벽하게 처리하도록 프롬프트를 깎는 데 시간을 허비하는 것보다, 중요한 길목에 사람이 검토할 수 있는 안전장치를 아키텍처적으로 배치하는 것이 훨씬 현명하고 강력한 통제 방법이라는 것을 배웠다.
HITL 설계를 직접 프로젝트에도 사용해보자고..
참고/출처
https://macgence.com/blog/hitl-human-in-the-loop/
https://wikidocs.net/316360
https://www.ibm.com/kr-ko/think/topics/human-in-the-loop
5. 시점 관리와 실행 관측
5.1. 시점 관리
에이전트 시스템이 구동될 때 가장 곤란한 상황은, 총 10단계로 이루어진 복잡한 파이프라인에서 8번째 단계에 치명적인 오류가 발생했을 때다. 일반적인 스크립트라면 처음부터 다시 실행하면 되지만, 토큰당 과금이 이루어지고 결과가 매번 달라지는 LLM 환경에서는 처음부터 재실행하는 것이 비용 낭비이자 또 다른 오류를 낳을 수 있다.
이를 해결하기 위해 프레임워크 내부에 존재하는 것이 바로 전역 상태의 변화 과정을 매 노드마다 사진 찍듯 저장해 두는 스냅샷(Snapshot) 기능이다.
1) MemorySaver와 체크포인트 이력 추적
그래프 컴파일 단계에서 MemorySaver와 같은 체크포인터를 연결해 두면, 에이전트가 한 노드를 통과할 때마다 당시의 모든 변수 상태(messages, extracted_info, current_step_index 등)가 고유한 ID(checkpoint_id)와 함께 저장된다.
문제가 발생했을 때 개발자는 graph.get_state_history() 메서드를 호출하여 시간 역순으로 상태 변화 이력을 모두 꺼내볼 수 있다. "아, Executor2가 요약을 수행할 때 extracted_info 값이 이미 빈 문자열로 넘어왔구나" 하는 식으로 에러의 근본 원인이 발생한 정확한 노드와 시점을 특정할 수 있게 된다.
2) 타임 트래블 (Time Travel)과 부분 재실행
스냅샷의 진정한 가치는 단순히 기록을 보는 것을 넘어, 과거의 특정 시점으로 시스템의 상태를 되돌려 거기서부터 다시 실행하는 타임 트래블에 있다.
에러가 발생하기 직전의 정상적인 checkpoint_id를 찾아 설정(Config) 객체에 담아 그래프를 호출(graph.invoke(None, config))하면, 시스템은 처음부터 API를 호출하지 않고 과거의 상태를 그대로 이어받아 실패한 노드부터 재실행을 시작한다. 프롬프트를 일부 수정하거나 버그를 고친 뒤 곧바로 해당 시점부터 테스트해 볼 수 있어, 디버깅 시간과 API 비용을 획기적으로 절약할 수 있다.
5.2. 실행 관측
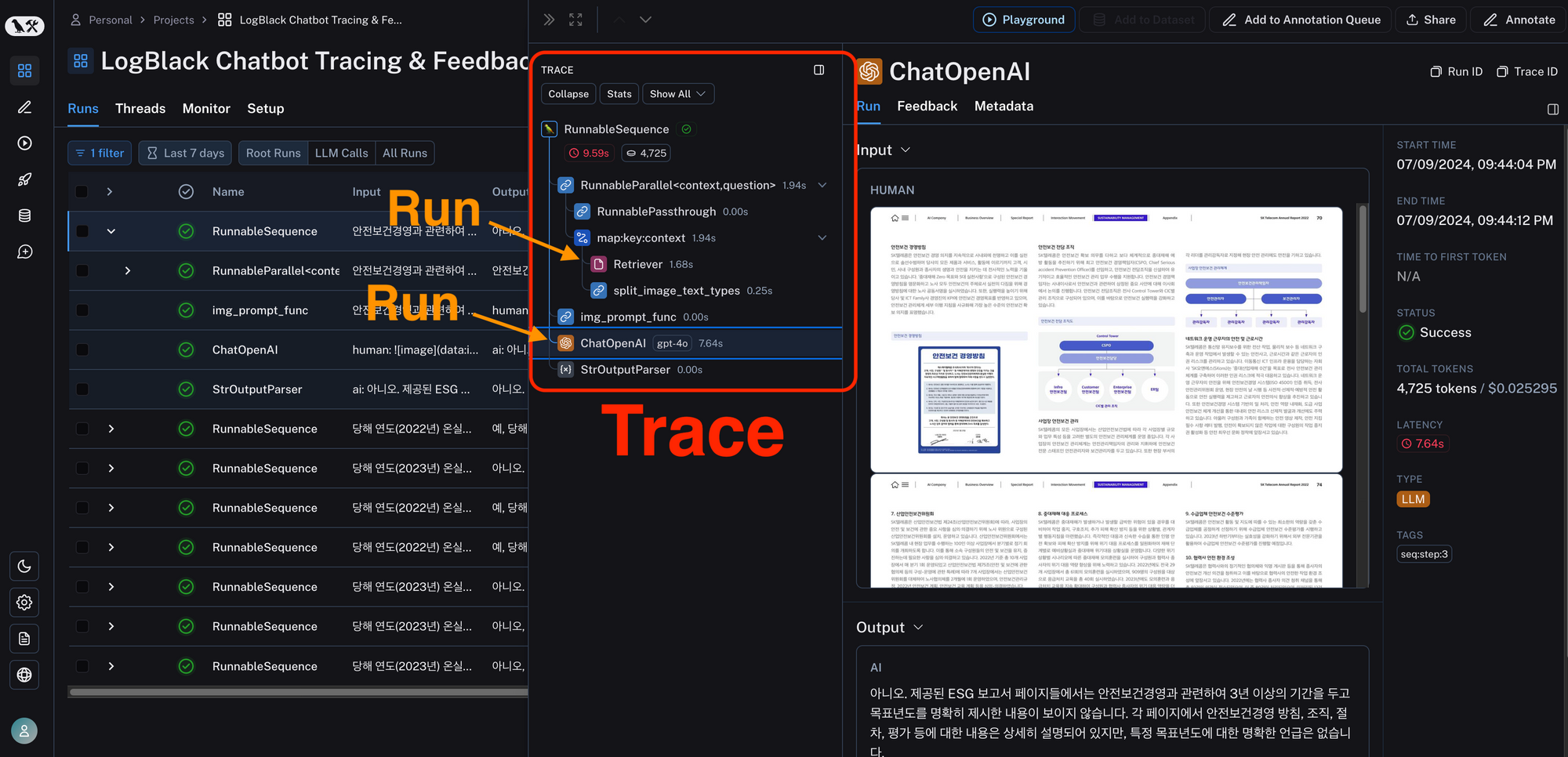
상태 데이터가 '무엇'이 변했는지 알려준다면, 실행 관측은 시스템이 '어떻게' 실행되었고 자원을 '얼마나' 소모했는지 알려주는 모니터링 체계다. LangSmith 같은 전문 관측 플랫폼을 연동하여 시스템의 성능을 계측한다.
1) Run Tree와 Waterfall 시각화
코드에 환경 변수 단 한 줄(LANGSMITH_TRACING=true)만 추가하면, 런타임에 발생하는 모든 LLM 호출, 도구사용, 에이전트 라우팅 내역이 중앙 서버로 전송된다. 플랫폼 대시보드에서는 이 복잡한 실행 과정을 트리 구조와 시간 축 기반의 Waterfall 차트로 시각화하여 보여준다. 어떤 에이전트가 다른 에이전트를 호출했는지, 그 과정에서 주고받은 프롬프트의 원문은 무엇인지 블랙박스 같았던 내부가 투명하게 드러난다.
2) 지연 시간(Latency) 및 비용(Cost) 병목 진단
Waterfall 뷰를 보면 전체 응답 시간이 30초 걸렸을 때, 어느 노드에서 가장 오랜 시간(예: 25초)이 정체되었는지 한눈에 파악할 수 있다. 특정 검색 도구의 API 지연인지, 특정 프롬프트가 너무 길어서 LLM 응답이 늦어지는 것인지 병목 구간을 정확히 진단 가능하다. 또한 각 단계별로 입력 토큰과 출력 토큰이 얼마나 소모되었고, 이것이 실제 달러($) 비용으로 얼마인지 실시간으로 계산되어 나타난다. 불필요하게 토큰을 많이 소모하는 프롬프트를 최적화하는 기준점이 된다.
찰고/출처
https://oidea.tistory.com/entry/AI-%EC%97%90%EC%9D%B4%EC%A0%84%ED%8A%B8-%EC%9B%8C%ED%81%AC%ED%94%8C%EB%A1%9C-%EC%9A%B4%EC%98%81-%EB%A1%9C%EA%B7%B8-%ED%8F%89%EA%B0%80-%EA%B4%80%EC%B8%A1%EC%84%B1%EC%9D%84-%EC%84%A4%EA%B3%84%ED%95%98%EB%8A%94-%EB%B2%95
https://smith.langchain.com/
https://sudormrf.run/2024/08/17/langsmith_review/
https://wikidocs.net/250954
생각정리
그동안의 나는 AI API를 호출해 원하는 결과물을 빠르게 만들어내는 과정 자체에 만족해왔던 것 같다. 프롬프트를 조금 더 정교하게 다듬고, 모델을 연결해 자동화를 구성하며 “AI로 이런 것도 가능하구나”를 체감했다면, 이번 LLMOps 학습을 통해서는 완전히 다른 관점을 배우게 되었다. 이제는 단순히 모델의 성능을 보는것이 아닌, 비결정론적인 AI를 어떻게 로직 안에서 안정적으로 묶고 통제할 것인가를 고민하는, 조금은 시스템 아키텍트에 가까운 시야를 가지게 된 느낌이다. 글을 정리하면서 가장 크게 와닿았던 문장은 결국 이것이었다.
“진정한 AI 엔지니어링은 완벽한 AI를 만드는 것이 아니라, 불완전한 AI를 안전하게 제어하는 시스템을 만드는 것이다.”
처음에는 왜 이렇게까지 복잡하게 설계해야 하는지 이해하지 못했다. Agent 역할 정의서, Workflow 명세서, State 정의서, Decision Policy, Prompt 명세서까지 이어지는 5대 설계 문서는 단순히 개발 속도를 늦추는 귀찮은 작업처럼 느껴졌고, Planner-Executor-Critic 구조나 Supervisor 패턴 역시 “굳이 이렇게까지 역할을 잘게 나눠야 하나?” 싶은 생각이 들었다. 하지만 직접 멀티 에이전트 흐름을 구성하고 Trace를 따라가 보니, 이런 구조들이 단순한 형식이 아니라 통제 불가능한 LLM을 상용 수준의 신뢰성을 가진 시스템으로 바꾸기 위한 엔지니어링 장치라는 사실을 배운거같다.
특히 LangSmith 기반의 실행 관측을 경험하면서 시야가 크게 넓어졌다. 예전에는 에이전트가 실패하면 단순히 “모델이 이상하게 답했네” 정도로 넘어갔지만, 이제는 어떤 노드에서 프롬프트가 비대해졌는지, 어느 시점에서 토큰 사용량이 급증했는지, 어떤 에이전트가 잘못된 상태를 전달했는지를 Waterfall 형태로 추적하며 병목과 오류를 분석할 수 있게 되었다. Planner가 잘못된 실행 계획을 세운 순간부터, Executor가 불완전한 정보를 추출하고, Critic이 왜 특정 결과를 Reject 했는지까지 전부 Trace 상에서 이어지는 흐름으로 확인할 수 있었다. LLM 시스템을 더 이상 “감과 반복”으로 디버깅하는 것이 아니라, 로그와 상태 기반으로 분석하는 소프트웨어 엔지니어링의 영역으로 다루게 된 것이다.
또 하나 인상 깊었던 부분은 Snapshot과 Time Travel 기반의 상태 복구였다. 기존에는 에이전트 시스템이 중간에 실패하면 처음부터 다시 실행하는 경우가 많았지만, 이제는 특정 checkpoint 시점으로 되돌아가 실패한 노드만 재실행하며 디버깅할 수 있다는 점이 굉장히 강력하게 느껴졌다. 특히 토큰 비용이 곧 운영 비용으로 이어지는 LLM 환경에서는 단순한 편의 기능이 아니라, 실제 서비스 운영을 위한 안전장치에 가깝다고 생각했다. 이러한 경험들을 하면서 자연스럽게 내가 관심있던 하네스 엔지니어링(Harness Engineering) 분야와 연결 지어 보게 되었다. 최근 AI 분야에서 말하는 하네스 엔지니어링은 단순히 더 뛰어난 LLM 모델을 만드는 기술이 아니다. 오히려 비결정론적인 AI가 실제 업무 환경 안에서 안정적으로 동작할 수 있도록, 주변의 시스템과 실행 환경, 제약 조건, 평가 체계를 설계하는 엔지니어링에 가깝다.
즉, 프롬프트 하나를 잘 작성하는 수준을 넘어:
어떤 컨텍스트(Context)를 제공할 것인지,
어떤 도구(Tool)를 어디까지 사용할 수 있게 허용할 것인지,
어떤 조건에서 실행을 중단하거나 재시도할 것인지,
결과를 어떤 방식으로 검증(Evaluation)할 것인지,
문제가 발생했을 때 어떻게 추적(Trace)하고 복구할 것인지
까지 전부 포함하여, AI가 “통제 가능한 상태” 안에서 동작하도록 만드는 것이다.
강의를 들으며 배운 LLMOps의 구조들이 하네스 엔지니어링의 맞닿아 있다. 처음에는 단순히 복잡해 보였던 Planner-Executor-Critic 구조, Supervisor 패턴, HITL, State 관리, Snapshot 기반 복구, Trace 관측 같은 요소들이 사실은 모두 AI를 안전하게 통제하기 위한 장치였던 것이다. 특히 LangSmith 기반의 Trace 관측은 내가 생각하던 하네스 엔지니어링의 핵심과 굉장히 잘 연결되었다.
기존에는 에이전트가 잘못된 결과를 생성하면 단순히 “모델 성능이 아쉽다” 정도로 받아들였지만, 이제는
어떤 프롬프트에서 토큰이 과도하게 사용되었는지,
어떤 Agent가 잘못된 상태(State)를 전달했는지,
어느 시점에서 Decision Policy가 잘못된 분기를 탔는지,
어떤 이유로 Critic이 Reject 판정을 내렸는지
를 Trace 기반으로 전부 추적할 수 있게 되었다. 결국 중요한 것은 “AI가 얼마나 똑똑한가”가 아니라, AI가 실수하더라도 시스템 전체는 무너지지 않도록 만드는 구조를 설계하는 것이라고 느꼈다. 앞으로는 단순히 모델 성능이나 프롬프트 최적화만 바라보는 것이 아니라, AI가 실제 서비스 환경 안에서 안정적으로 동작할 수 있도록
실행 환경을 구조화하고,
제약 조건을 설계하고,
평가 루프를 만들고,
상태를 추적하며,
인간 개입(HITL)을 연결하는
이러한 하네스 엔지니어링 관점의 AI 시스템 설계를 더 깊이 있게 공부해보고 싶다.
아직은 배워야 할 것도 많고, 직접 구현해보며 부딪혀야 할 문제들도 많다. 하지만 이번 학습을 통해 단순히 “AI를 잘 사용하는 개발자”도 좋지만, AI를 안전하게 통제하고 운영할 수 있는 시스템을 설계하는 사람에 방향성을 조금이나마 잡게 된 것 같다. 6주차 정리를 마무리한다.
기술에 발전이 무섭습니다.. 새로 나오는 기능, 서비스, 모델들 잘 활용하고 찍먹 해봅시다.
Github Private
