
들어가며
이번 주차에서는 LLM을 활용한 마지막 03 MiniProject를 진행하고, AIVLE DAY를 보내며 코딩테스트와 자소서 특강 강의를 진행했다. 이번 글(7주차-1)에서는 먼저 프로젝트 진행 내용을 정리하고, 다음 글(7주차-2)에서 코딩테스트 리뷰와 강의를 통해 느끼고 배워간 점들을 함께 정리해보려고 한다.
이번 프로젝트 역시 01, 02 MiniProject 때와는 또 다른 팀원들과 함께하게 되어 설레는 마음으로 시작했다. 주제는 상품 리뷰 분석 Agent 서비스 구축이었다.
프로젝트의 배경은 다음과 같다.
- 멤버십 쇼핑라운지 데이터분석팀은 AI 기반 감성 분석 프로젝트를 통해 리뷰 데이터를 구조화하고, 각 속성별 감성 정보를 추출하여 입점 업체에 제공함으로써 제품 기획, 마케팅, 고객 응대 등 비즈니스 전반에 실질적인 인사이트를 제공하는 서비스 체계를 구축하고자 했다.
- 단기적으로는 리뷰 분석 자동화를 목표로 하고, 중장기적으로는 리뷰 기반 상품 추천, 자동 요약, VOC 클러스터링 등 고도화된 서비스로 확장하기 위한 첫 단계로 프로젝트가 기획되었다.
- 최종적으로는 프로젝트의 성공을 바탕으로 전체 입점 업체까지 서비스를 확산하는 것을 목표로 하고 있었다.
이번 프로젝트 역시 이전 프로젝트들과 비슷하게 기본적인 틀은 제공되었지만, 각 팀이 회의를 통해 방향성을 구체화하고 어떤 부분에 집중해 서비스를 고도화할 것인지 결정하는 과정이 핵심이었다고 생각한다. 같은 주제를 바탕으로 하더라도 어떤 사용자 경험에 초점을 맞추고, 어떤 기능을 강화하느냐에 따라 서비스의 색깔이 완전히 달라지기 떄문이다.
특히 이번에는 Streamlit을 활용한 시각화와 LangSmith 기반의 실행 과정 모니터링 및 추적 기능까지 적용하면서, 이전 프로젝트보다 결과물을 더욱 직관적이고 완성도 있게 보여줄 수 있을 것이라는 기대가 컸다. 이러한 과정 속에서 우리 조가 어떤 방향으로 프로젝트를 진행했는지 소개해보려고 한다.
ABSA 알고 있나요?
본격적인 시스템 구현에 앞서, 이번 프로젝트의 핵심 방법론인 속성 기반 감성 분석(ABSA: Aspect-Based Sentiment Analysis)에 대해 먼저 짚고 넘어가고자 한다. 우리 서비스가 실제 비즈니스 환경에서 입점 업체들에게 '실질적인 액션 아이템'을 제시하기 위해서는 일반적인 감성 분석만으로는 괜찮을까?라는 생각이 들고 이는 강의에서 언급된 내용이기도 하지만 자세하게 다루지 않았기에 ABSA 개념에 대해 조사했다.

속성 기반 감성 분석(ABSA)이란?
단순히 전체 리뷰를 '긍정' 혹은 '부정'으로만 분류하는 기존의 감성 분석과 달리, 리뷰 내에 포함된 '구체적인 속성(Aspect, 예: 가격, 향, 성분 등)'과 그에 대응하는 '감성(Sentiment)'을 쌍으로 매칭하여 세밀하게 추출하는 자연어 처리 기법이다.
예를 들어, "가격은 저렴해서 좋은데, 향이 너무 강해서 아쉬워요."라는 리뷰가 있다면 일반적인 감성 분석은 문장 전체의 극성을 모호하게 판단하겠지만, ABSA는 다음과 같이 데이터를 구조화하여 명확한 의미를 도출해낸다.
속성 1: 가격 → 감성: 긍정(1)
속성 2: 향 → 감성: 부정(0)
왜 이번 프로젝트의 핵심이었나?
이번 프로젝트의 목표는 단순히 "고객들이 이 제품을 좋아한다/싫어한다"라는 단편적인 피드백을 전달하는 것이 아니었다고 생각한다. 입점 업체가 고객의 소리(우레에겐 리뷰)를 기반으로 제품을 개선하고 마케팅 전략을 수정할 수 있도록, "제품의 어느 부분(가격, 제형, 성분, 디자인, 배송 등)에서 만족하고, 또 어느 부분에서 구체적인 불만을 느끼는지"를 파악하는 것이 프로젝트의 핵심 과제라고 생각한다.
이러한 정성적 데이터를 정량화된 JSON 포맷으로 변환하는 ABSA 체계를 구축함으로써, 우리는 다량의 리뷰 데이터 속에서 특정 속성의 만족도 추이를 통계적으로 추출할 수 있었다. 결과적으로 이 ABSA 기법은 우리 팀의 멀티 에이전트 시스템에서 에이전트들이 문제를 인지하고 각 전문가 노드로 업무를 할당하는 판단의 기준이 되는 중요한 로직으로서 기능하게 되었다.
ABSA란? 참고
https://abluesnake.tistory.com/173
https://www.ibm.com/kr-ko/think/topics/sentiment-analysis
https://www.elastic.co/kr/what-is/sentiment-analysis
https://www.sciencedirect.com/science/article/abs/pii/S0950705121009059 (논문 궁금하면)
주제 : 상품 리뷰를 구조화된 감성 데이터로 변환하는 Multi - Agent AI 분석 시스템
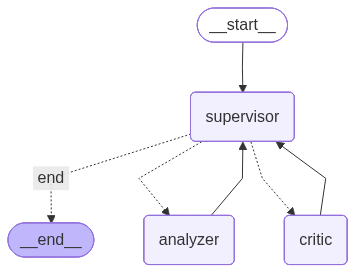
기본 시스템 구조
전체 시스템은 LangGraph를 기반으로 설계되었으며, Supervisor, Analyzer, Critic이라는 핵심 에이전트들이 상호작용하며 리뷰 데이터를 반복적으로 분석하고 검증하는 구조로 이루어져 있다.
-
작업 분배 및 흐름 제어 (Supervisor Node): 워크플로우의 중심에서 전체 프로세스를 조율한다. 리뷰 데이터가 들어오면 먼저 Analyzer에게 분석을 지시하고, 이후 결과에 따라 Critic으로 검증을 넘기거나, 혹은 검증이 완료되면 워크플로우를 종료시키는 조건부 분기역할을 수행함
-
리뷰 데이터 1차 분석 (Analyzer Node): 사용자의 원시 리뷰 텍스트가 입력되면, 제시된 후보 속성 중 리뷰에 언급된 항목을 추출한다. 해당 속성에 대한 만족(1)과 불만족(0) 여부를 판별한다.
-
결과 검증 및 피드백 (Critic Node): Analyzer가 내놓은 분석 결과의 품질을 꼼꼼히 검토한다. 추출된 속성이나 감정 라벨링 등에 오류가 없는지 평가하고, 재작성이 필요한 경우 구체적인 피드백(예: 범위 오류, 근거 부족 등)과 함께 Analyzer가 다시 분석하도록 유도한다.
|
|
우리가 생각한 고도화 방법
1. 리뷰분석 Agent의 평점 산정 기준
- 고객이 입력한 별점이 있는 경우 -> 입력된 별점 숫자가 0보다 크면 그 숫자를 그대로 사용
- 별점이 누락되었거나 0점인 경우 -> Agent가 리뷰 원문의 직접 분석해 1점부터 5점 사이로 알아서 별점을 책정하도록 설계 (매우 만족은 5점, 만족은 4점, 보통 3점, 불만족 2점, 매우 불만족 1점)
2. 정성데이터의 정량화 (텍스트 리뷰를 수치 데이터로 변환)
- 속성(Aspect) 추출 -> 우리조는 data.csv를 미리 화장품 리뷰에 나올 법한 후보 속성 리스트(예: 가격, 향, 보습 등 50여 개)를 세팅해두고, 리뷰에서 실제로 언급된 속성 키워드를 추출
- 긍정/부정(Label) 매칭: 추출해 낸 각 속성에 대한 만족도를 판별해서, 만족/긍정은 '1', 불만족/부정은 '0'으로 라벨링을 진행
- 데이터 매칭: 결과적으로 추출된 속성 리스트와 0 또는 1로 이루어진 라벨(label) 리스트를 1:1로 정확하게 매칭했으며, 정성적인 텍스트를 JSON 데이터 형식으로 변환
3. 시스템의 우선순위 판단 기준
분석 결과에서 '불만족(0)'으로 나온 속성들을 해결하기 위해 분야별 전문가 에이전트에게 업무를 할당했다. 이때 처리 우선순위를 잡았다. (화장품 특성상 제품의 핵심 기능과 가격이 최우선이라고 판단)
그래서 매칭된 에이전트 리스트에 performance_llm(효능/성분 개선 전문가)이나 Texture_llm(제형/사용감/자극 개선 전문가)이 포함되어 있다면, 무조건 리스트의 최우선 순위에 오도록 정렬 규칙을 세웠다.
예외 처리(불만족이 없는 경우)
만약 라벨 리스트에 불만족(0)이 하나도 없는 '완전 만족' 리뷰라면?
이때는 전반적인 감사 및 고객 관리를 위해 Service_llm(배송/고객 경험 관리 전문가)을 출력하도록 예외 처리도 진행
4. 복합 불만에 대응하는 유연한 배열 반환 구조
Router Agent가 반환하는 결과값은 단일 문자열이 아니라 배열 형태의 데이터이다.
예를 들어 고객이 "크림 성분은 좋은데 뚜껑이 안 열려서 화가나요"라고 리뷰를 남겼다면? Router Agent는 이 복합적인 불만을 캐치하여 ["performance_node", "design_node"] 형태의 리스트를 반환한다.
이를 받은 LangGraph 시스템은 두 개의 전문가 노드를 모두 활성화시켜 각자의 관점에서 개선안을 작성하도록 만든다. 딱 필요한 전문가 노드만 선택적으로 깨워서 일하게 만드는 매우 효율적이게 구축했다.
5. JSON 파싱 에러에 대비한 Fallback
LLM이 결과를 뱉을 때 가끔 포맷을 무시해서 JSON 형식이 깨지는 경우가 있다. 우리는 실제 서비스 투입을 가정하고 이런 에러 상황까지 완벽하게 대비했다.
- Router Agent 코드 내에 파싱을 처리하는 try-except json.JSONDecodeError 구문을 적용
- 만약 LLM의 출력 에러로 인해 JSON 디코딩에 실패하더라도, 시스템이 에러를 뿜으며 다운되지 않고 안전하게 기본값인 ["Service_llm"]으로 향하도록 방어 로직을 구축
Batch처리 (동기 vs 비동기)
1. 기존의 방식동기식 처리 (Synchronous)
먼저, 시스템은 DB에 새롭게 쌓인 '미처리 리뷰(아직 분석되지 않아 aspect IS NULL인 상태)'들을 한꺼번에 불러와 분석을 시작한다.
초기에는 extract_review_elements라는 동기식(Sync) 함수로 진행했다.
동작 방식은 단순 -> 파이썬의 기본 for문을 돌면서, 첫 번째 리뷰를 Agent(app.invoke())에 던지고 답변이 올 때까지 가만히 기다렸다.
첫 번째 리뷰 분석이 완전히 끝나면, 그제야 두 번째 리뷰가 진행되었다.
# 기존 방식: 하나씩 순서대로 처리 (동기)
def extract_review_elements(clean_reviews):
result = []
for review in clean_reviews:
print("-리뷰 분석 시작합니다.-")
initial_state = {
"input_review": review,
"score": 0,
"aspect_list": ['가격', '보습', '제형', '디자인', '배송', ...], # 생략
"max_num": 3,
"current_num": 0,
"messages": []
}
final_state = app.invoke(initial_state)
result.append({
"aspect": final_state["result"]["aspect"],
"label": final_state["result"]["label"],
"score": final_state["result"]["score"]
})
return result문제점: LLM 기반 에이전트는 단점이 있다. 바로 네트워크 I/O 대기 시간(API 응답을 기다리는 시간)이 길다. 앞선 리뷰의 분석이 끝날 때까지 CPU가 아무 일도 하지 않고 놀고 있으니, 처리 속도가 턱없이 느릴 수밖에 없었다.
2. 개선한 비동기식 처리 (Asynchronous)
답답한 처리 속도를 해결하기 위해, 저희 조는 파이썬의 asyncio 라이브러리를 활용하여 시스템을 수정했다.
새롭게 extract_review_elements_async라는 비동기(Async) 함수를 도입다.
이제는 for문을 돌면서 무작정 기다리지 않고 비동기 호출(app.ainvoke())을 통해 여러 개의 리뷰 분석 요청을 동시에 병렬로 API에 던져준다.
import asyncio
async def extract_review_elements_async(clean_reviews, concurrency=6):
# API 호출 제한 방지: 한 번에 최대 6개의 일꾼(Concurrency)만 일하도록 설정
semaphore = asyncio.Semaphore(concurrency)
async def analyze_one(review):
async with semaphore:
initial_state = {
"input_review": review,
"score": 0,
"aspect_list": ['가격', '보습', '제형', '디자인', '배송', ...],
"max_num": 3,
"current_num": 0,
"messages": []
}
# 핵심 포인트! ainvoke()를 사용해 비동기적으로 API 호출
# 응답을 기다리는 동안 다른 리뷰 분석을 동시에 진행.
final_state = await app.ainvoke(initial_state)
return {
"aspect": final_state["result"]["aspect"],
"label": final_state["result"]["label"],
"score": final_state["result"]["score"],
}
# 수많은 리뷰 요청을 한꺼번에 모아서(gather) 동시 실행!
results = await asyncio.gather(*[analyze_one(r) for r in clean_reviews])
return results
# 배치 실행 트리거 함수
async def start_batch_async():
# DB에서 미처리 리뷰 불러오기 등 초기화 과정 생략
...
# 비동기 함수 호출
analyzed_results = await extract_review_elements_async(None_analyze_reviews, 6)
# DB 업데이트
update_db(None_analyze_reviews, analyzed_results)3. 트러블슈팅 및 결과: 5.52배 성능 향상
동기 방식에서 비동기 방식으로 파이프라인을 완전히 리팩토링한 결과는 성공적이였다.
우선, API 응답을 하염없이 기다리게 만들었던 원흉인 app.invoke()를 비동기 호출 메서드인 app.ainvoke()로 전면 교체하고 파이썬의 asyncio.gather를 활용해 수많은 미처리 리뷰 데이터를 개별적으로 보내지 않고 한 번에 묶어 쏘아 올리는 병렬 구조로 변경했다.
이렇게 설계하니 기존 동기 방식에서 아무것도 하지 못하고 버려지던 '응답 대기 시간'들을 완벽하게 겹쳐서(Overlap) 사용할 수 있게 되었고, 병목 현상을 해결 할 수 있었다.
Rate Limit 방어
무작정 수천, 수만개 등의 리뷰 요청을 동시에 던지면 어떻게 될까?
십중팔구 LLM API 서버에서 'Rate Limit' 에러를 뿜어내며 전체 시스템이 다운될것이다.
저희 조는 이 치명적인 문제를 방지하기 위해 asyncio.Semaphore(6)를 도입했다. 동시에 일하는 워커의 개수를 최대 6개로 제한하여, API 서버에 과부하를 주지 않으면서도 시스템이 낼 수 있는 최대의 효율을 뽑아내는 안정적인 타협점을 찾았다.
그 결과, 한 번의 API 에러나 멈춤 없이 시스템이 아주 안정적으로 돌아갔다. 동일한 수량의 리뷰 데이터를 배치 처리하는 데 걸리는 전체 시간이 획기적으로 줄어들었으며, 최종적으로 기존 대비 약 5.52배라는 성능을 향상시켰다.
LangSmith 모니터링
우리 조의 역할을 분담하는 과정에서 나는 LangSmith 파트를 맡게 되었다. 이에 따라 이번 화장품 리뷰 분석 AI 에이전트 프로젝트에서는 LangSmith 기반의 모니터링 시스템 구축에 검증하고 조사했다.
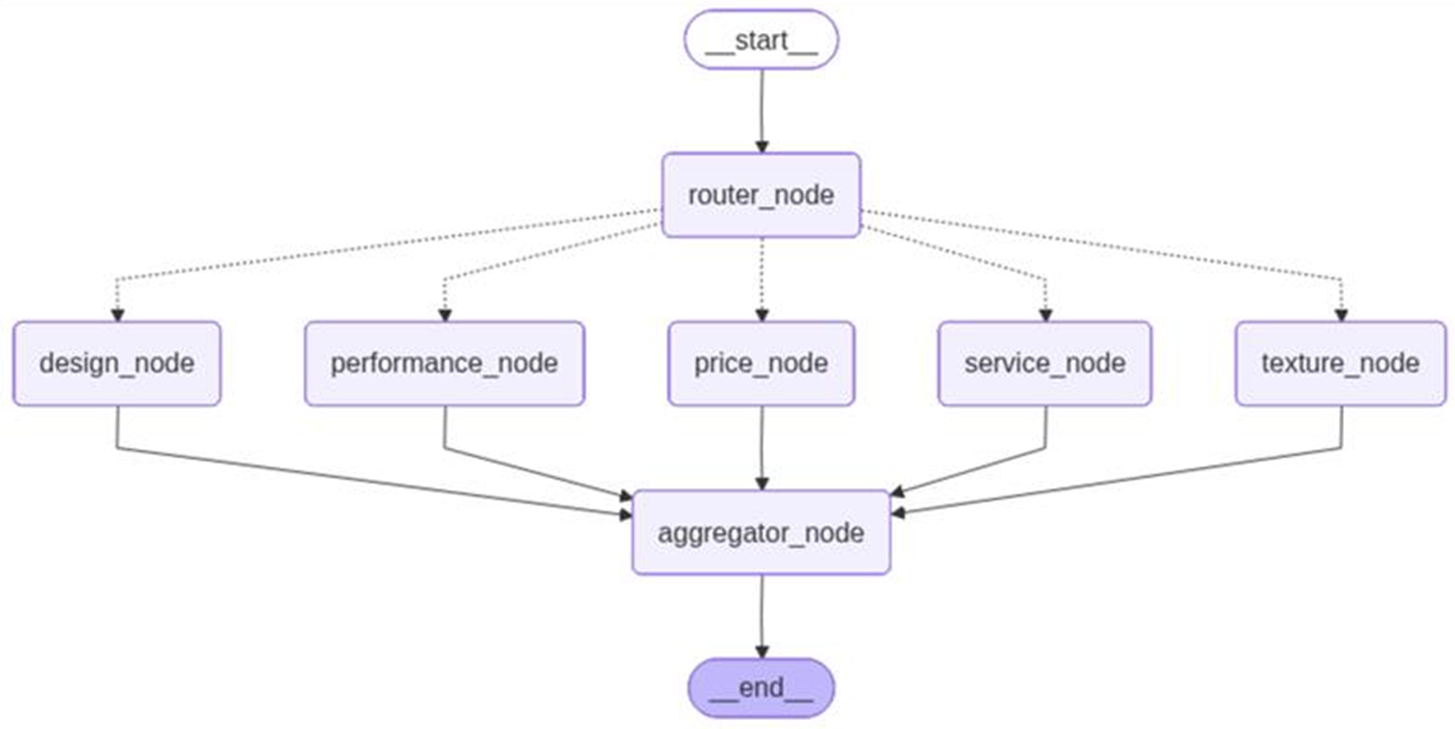
1. Trace Tree 시각화를 통한 동적 라우팅 및 병렬 처리 검증
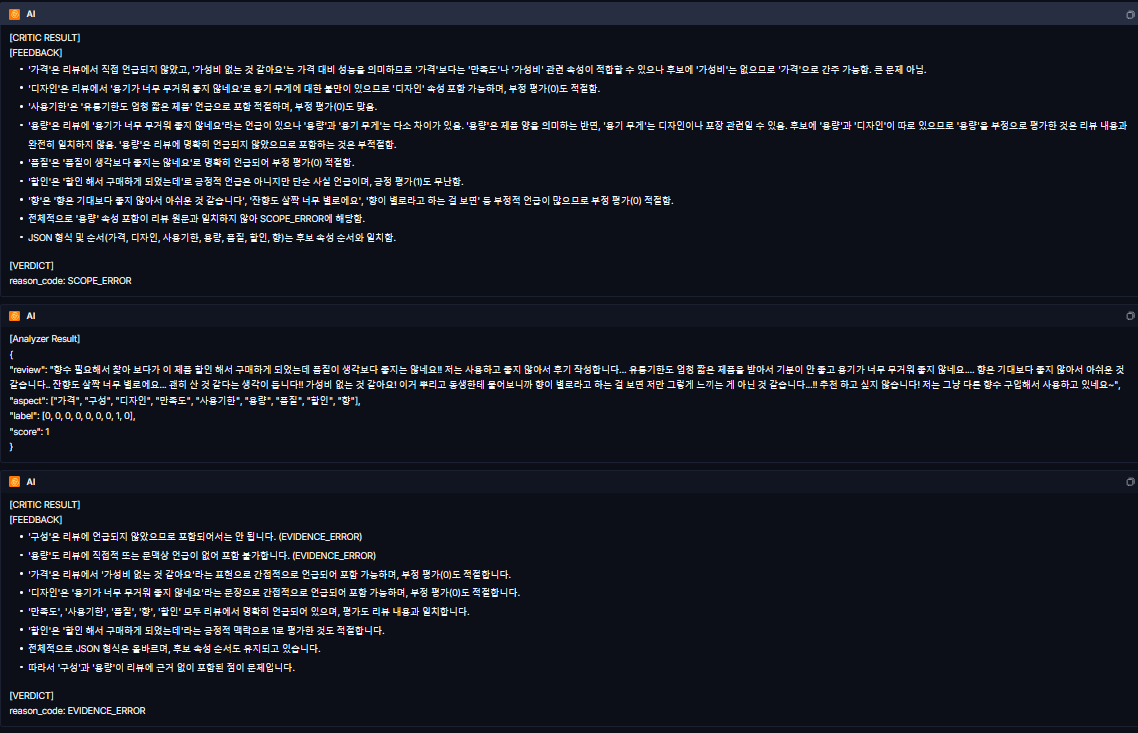
코드로 설계한 LangGraph 아키텍처가 실제 트래픽 환경에서 어떻게 동작하는지 LangSmith의 Trace Tree를 통해 가장 먼저 확인했다.
-
동적 라우팅(Dynamic Routing) 확인: 로그를 보면 START 노드에서 시작된 리뷰 데이터가 가장 먼저 router_node로 진입하고 라우터는 리뷰의 불만족 속성을 파악하여 어떤 전문가 에이전트를 호출할지 결정하는 역할을 수행한다.
-
Send API 기반의 병렬 실행 증명: 트리의 하단부를 보면 저희 조 아키텍처의 핵심인 '병렬 처리'가 완벽하게 기록되어 있다. router_node 이후 add_conditional_edges와 Send API를 통해 performance_node(성분/효능), design_node(패키징), service_node(CS) 등의 여러 전문가 노드가 직렬이 아닌 동시에(병렬로) 분기되어 실행되는 흐름을 시각적으로 확인할 수 있었습니다. 이는 비동기 처리가 의도대로 작동하여 전체 처리 시간을 획기적으로 단축시키고 있음을 보여준다.
2. 노드별 I/O 심층 추적을 통한 프롬프트 디버깅 및 제어
단일 실행 기록(Run)의 세부 내역으로 들어가면, 각 전문가 에이전트에게 LLM모델이 어떤 입력을 받고 어떤 출력을 반환하는지 정확히 추적이 가능하다.
Router Node의 매칭 정확도 검증
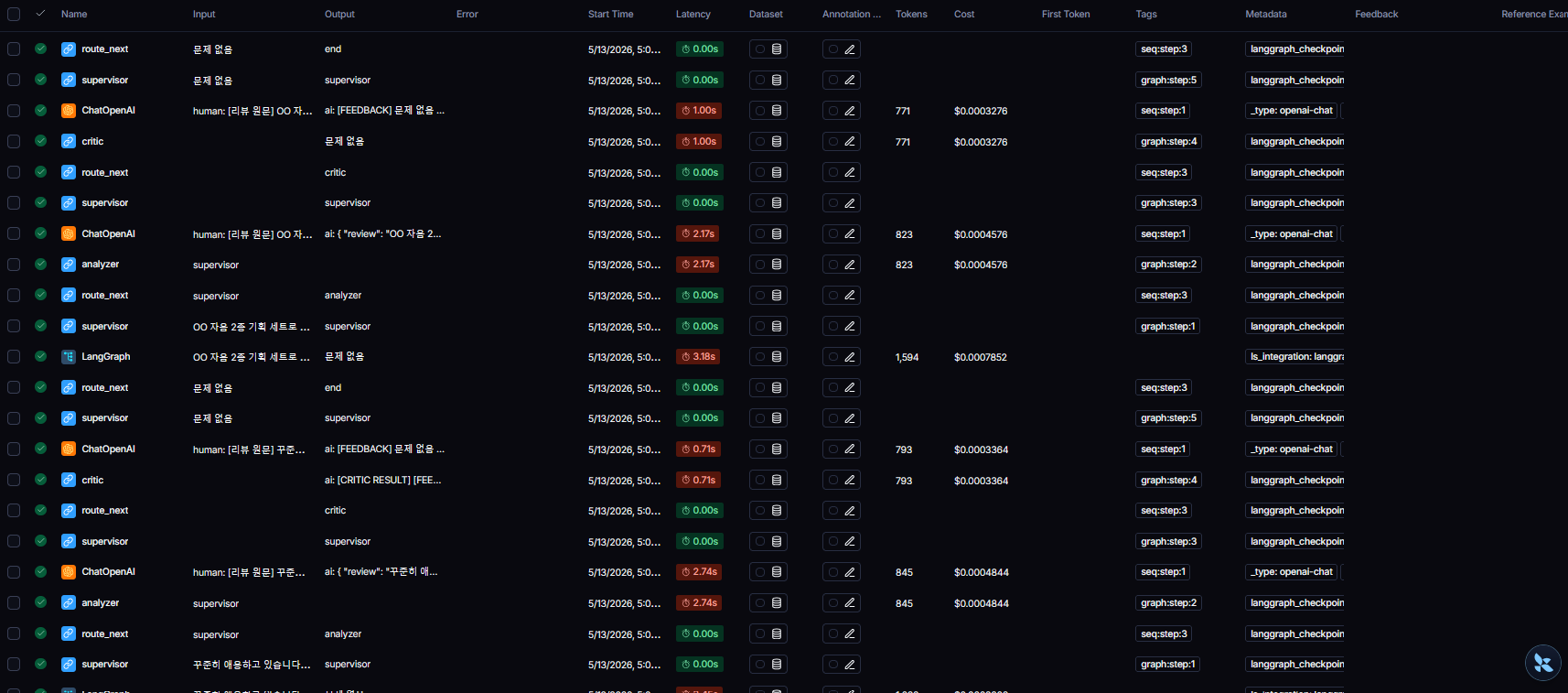
router_node의 상세 로그를 통해, 50여 개의 화장품 속성(aspect)과 불만족(label=0) 데이터가 어떻게 파싱되는지 확인했다. 예를 들어 '보습' 불만은 performance_node로, '포장' 불만은 design_node로 정확히 분류하여 ["performance_node", "design_node"] 형태의 리스트를 반환하는 것을 디버깅했습니다. 파싱 에러 발생 시 Fallback으로 ["service_node"]가 정상 호출되는 예외 처리 로직도 이 화면을 통해 검증을 진행했다.
전문가 Node(Expert Agents)의 도메인 특화 추론 확인
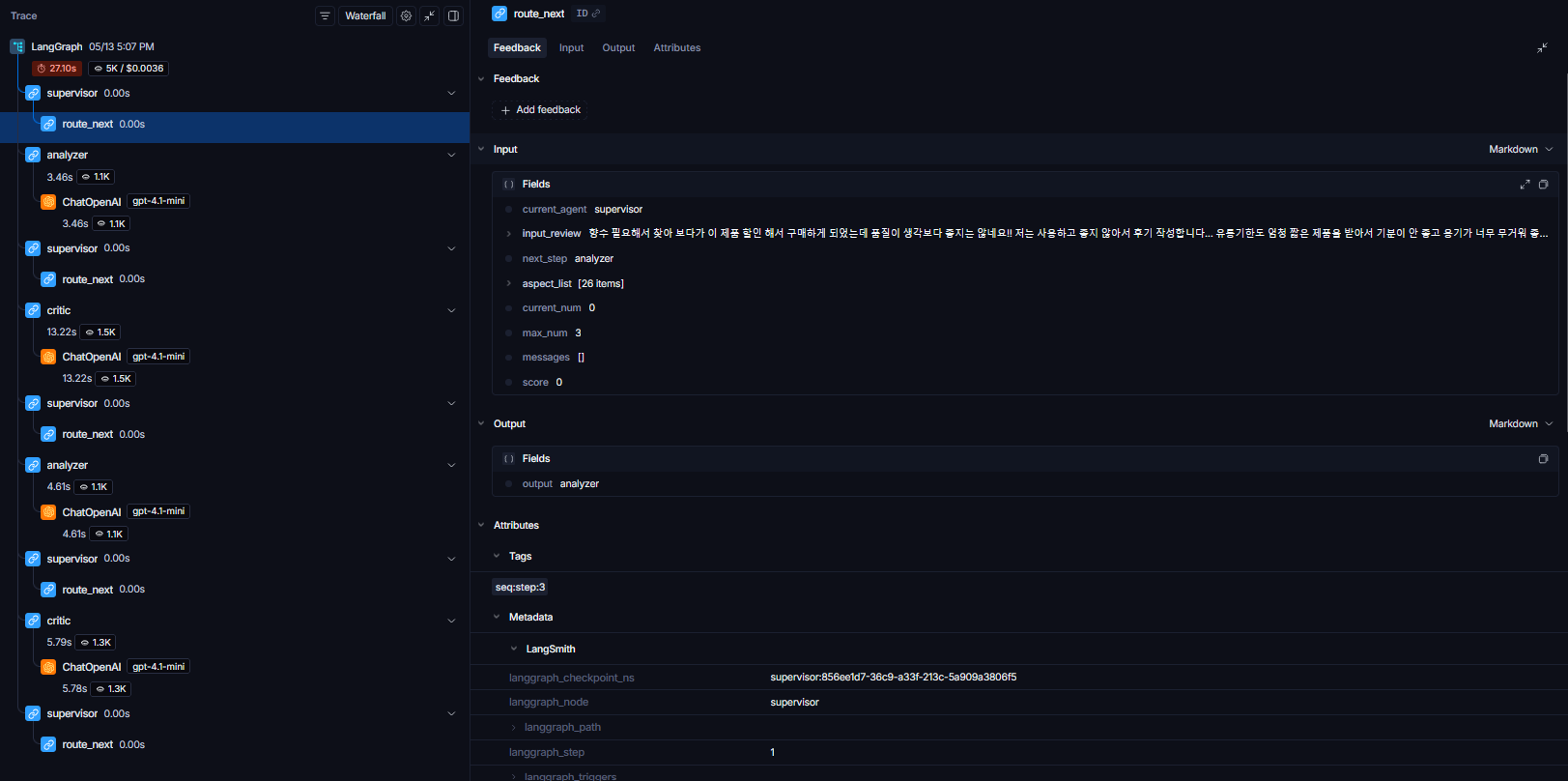
특정 전문가 노드(예: design_node 또는 texture_node)의 내부 추론 로그다. 모델이 프롬프트 지시사항에 따라 자신의 담당 영역이 아닌 불만(예: 디자이너 노드에 입력된 배송 불만)은 철저히 무시하고, 오직 자신의 도메인에 맞춰 "- 속성: ... - 원인 분석: ... - 개선 방안: ..." 형태의 규격화된 텍스트로 해결책을 제시하고 있음을 확인했습니다. 이를 통해 모델의 환각 현상을 통제하고 전문성을 극대화한다.
Aggregator Node의 최종 데이터 병합
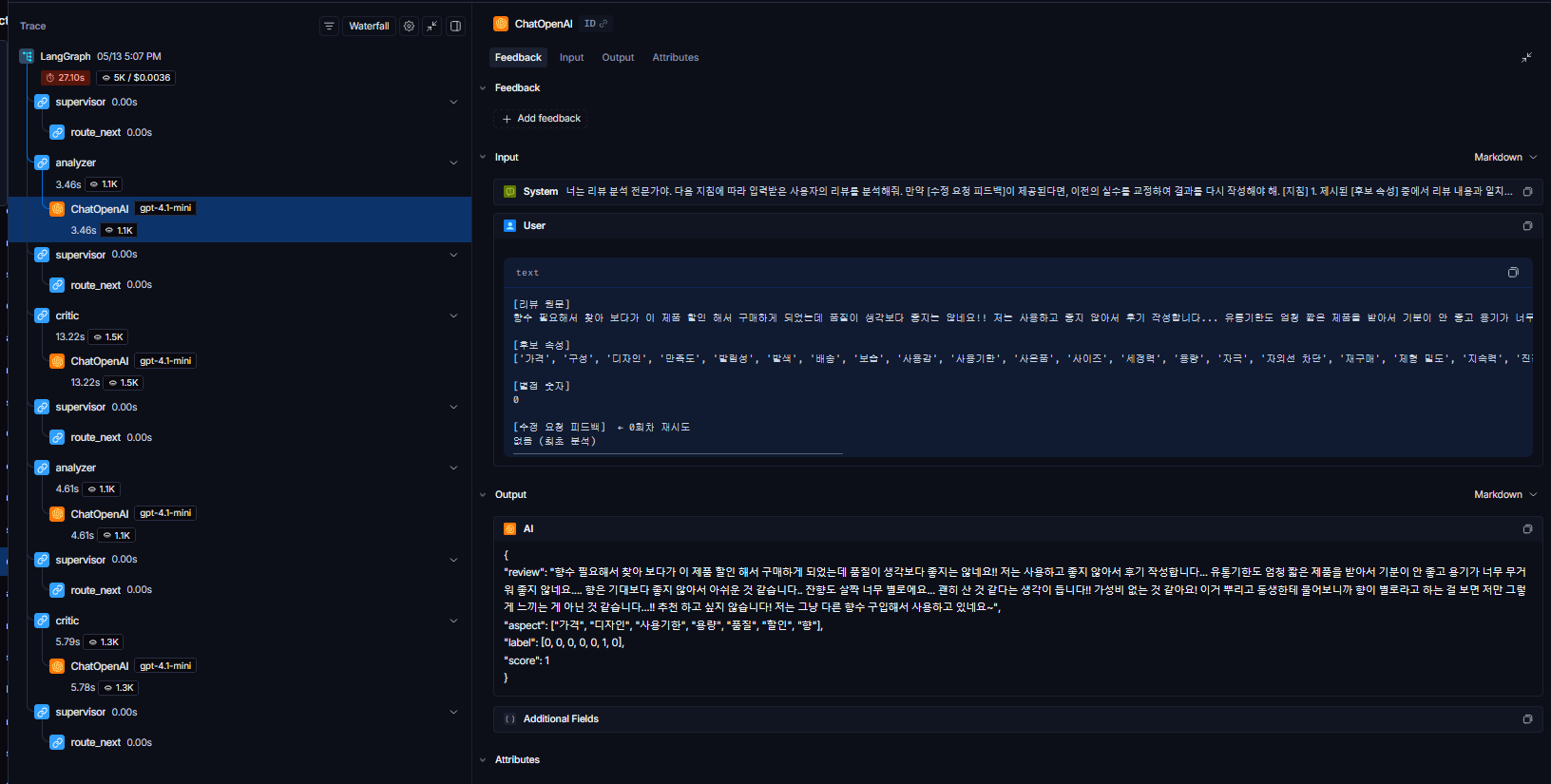
개별적으로 실행된 전문가 에이전트들의 result_list가 최종적으로 aggregator_node에 모여 데이터 소실 없이 하나의 [종합 제품 개선 제안서] 텍스트 포맷으로 완벽하게 병합되는 마지막 단계를 확인했다.
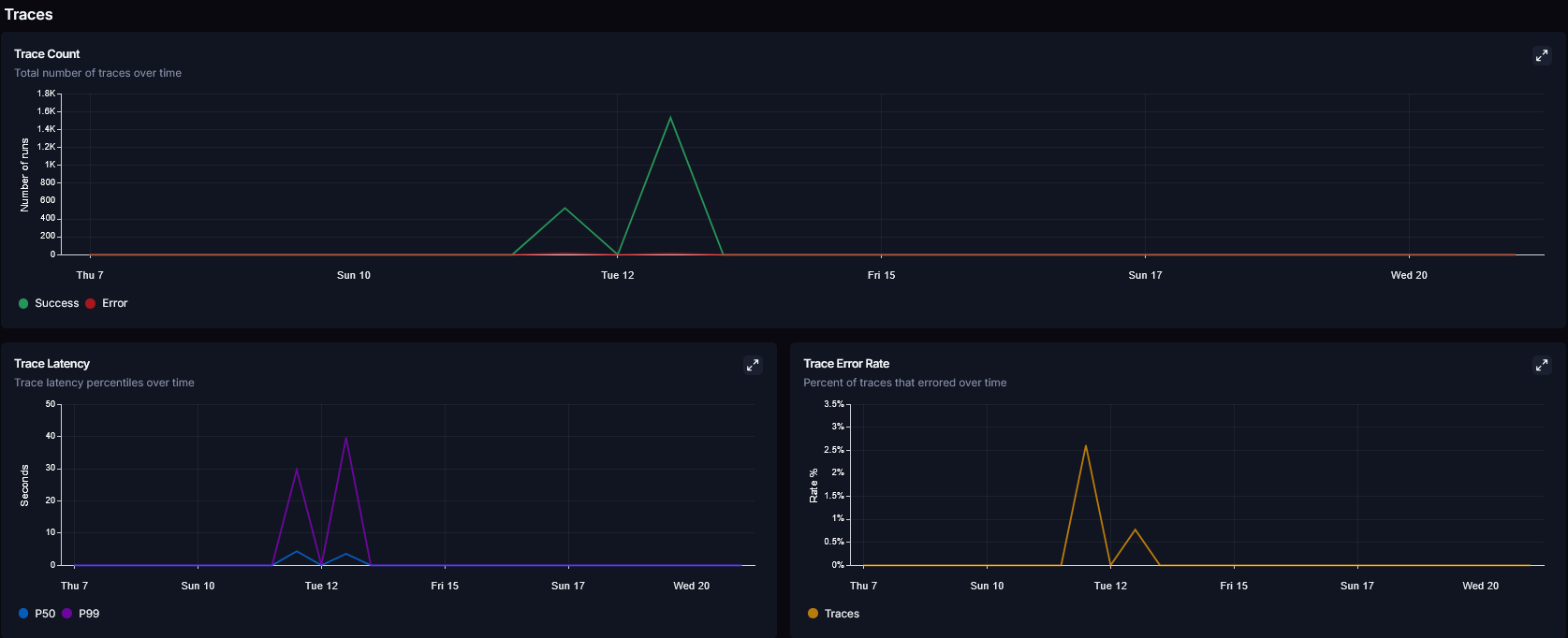
3. 대시보드 지표 분석과 토큰/비용 최적화
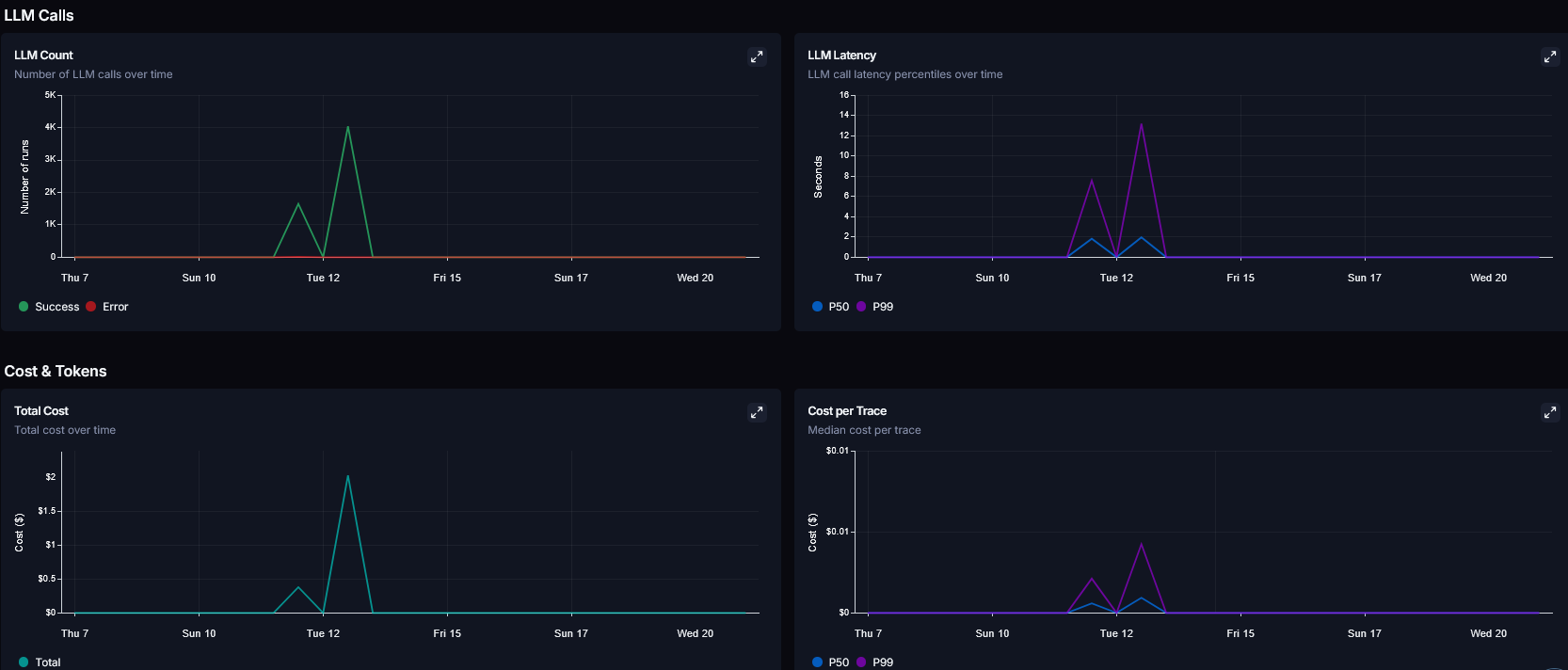
|
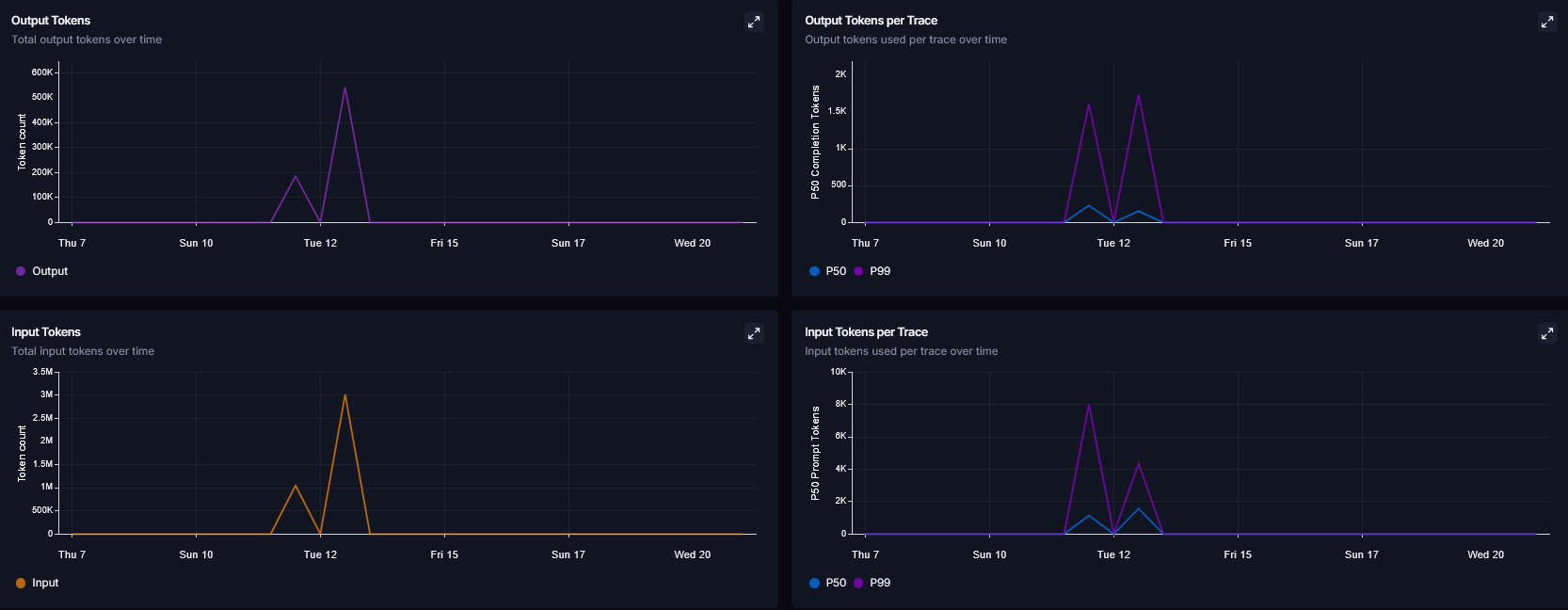
|
LangSmith의 대시보드 지표는 시스템의 부하 상태를 정량적으로 파악하고 아키텍처를 개선하는 결정적인 근거가 된다.
병렬로 수많은 에이전트가 동시에 LLM(OPEN_API) API를 호출하는 구조이다 보니, 토큰 사용량과 Rate Limit 관리의 중요성이 매우 컸다.
Metrics 탭의 Latency 차트와 Token Usage 리스트를 상시 모니터링하여, 여러 전문가를 동시에 깨우는 병렬 라우팅 구조가 동기식 순차 처리 방식보다 지연 시간방어에 훨씬 유리함을 지표 추이로 입증했다.
결과 시각화 (Streamlit)
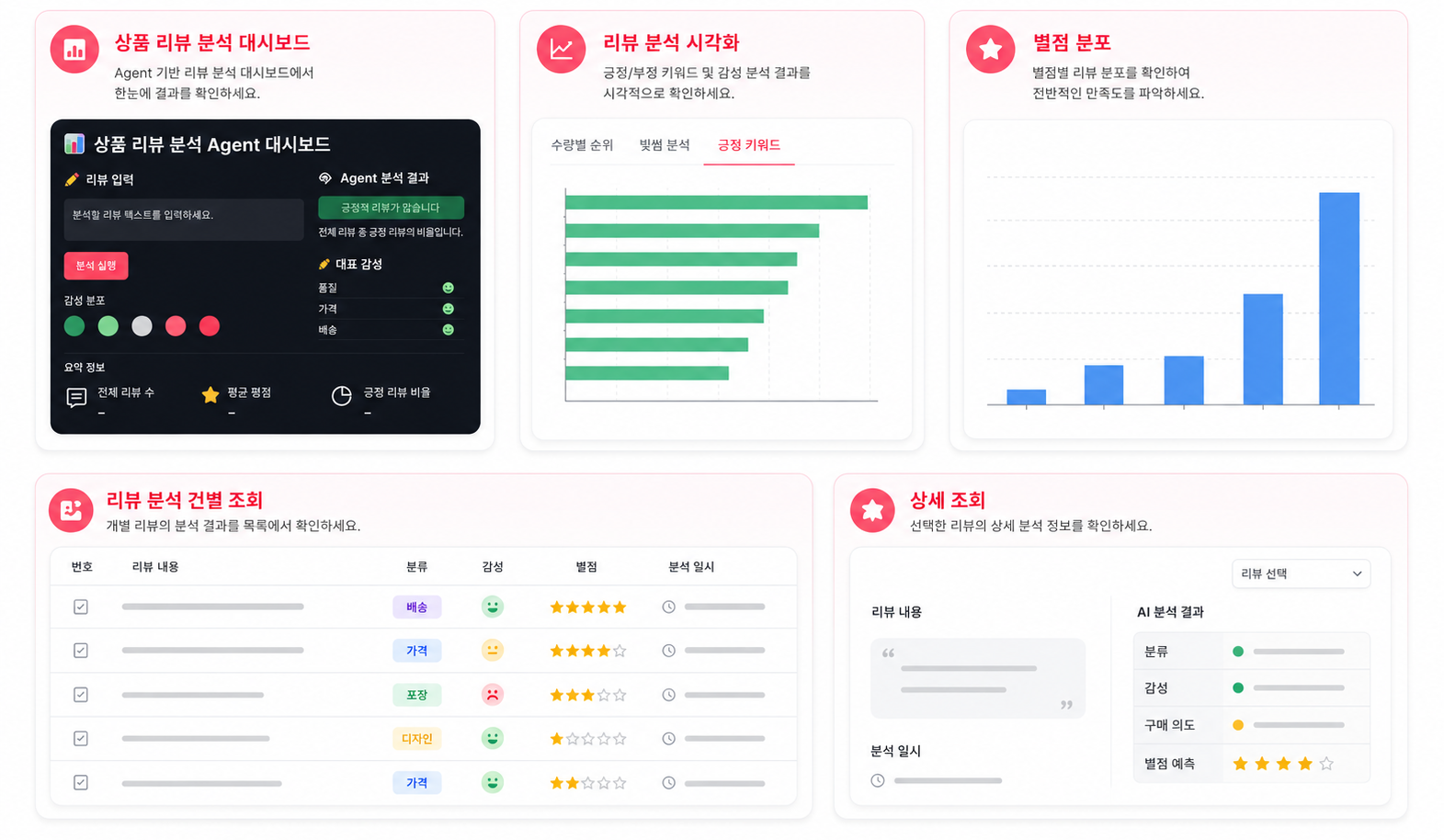

|

|
생각정리
이번 3차 Mini Project는 단순히 LLM을 호출해 결과를 출력하는 것이아닌, 실제 서비스 환경에서 AI 시스템을 어떻게 안정적으로 운영하고 관리할 것인가에 대해 생각해볼 수 있는 프로젝트이지 않을까? 라는 생각이 든다.
리뷰 분석이라는 하나의 기능 뒤에도, 우리가 고도화 과정에서 다뤘던 Rate Limit 대응, JSON 파싱 오류 처리, 병렬 처리 구조 설계, 응답 지연 시간(Latency) 개선, 토큰 비용 최적화 등 생각보다 훨씬 많은 시스템적 문제들이 존재했다. 또한 다른 조들의 발표를 들으며 같은 주제를 가지고도 팀마다 전혀 다른 방향으로 프로젝트를 발전시킨 점이 인상 깊었다. 어떤 조는 LangSmith를 활용한 모니터링과 분석 체계에 더욱 집중해 AI 파이프라인의 흐름과 안정성을 강조했고, 또 다른 조는 리뷰 데이터를 활용한 실제 서비스 아이디어를 구체적으로 제시하기도 했다. 반면 사용자 관점에서 리뷰를 어떻게 더 직관적으로 받아들이고 활용할 수 있을지에 집중해 UX 측면을 강화한 조도 있었다. 단순히 모델 성능만이 중요한 것이 아니라, 어떤 문제를 정의하고 어떤 사용자 경험을 제공할 것인지에 따라 같은 AI 기술도 완전히 다른 결과물로 이어질 수 있다는 점에 시야가 넓어진거같다..
이번 프로젝트에서 내가 맡았던 LangSmith 기반 모니터링 파트에서는 반복적인 로그를 보는 것이 아닌, LangGraph 기반 멀티 에이전트 구조가 실제로 어떤 흐름으로 동작하는지 Trace 단위로 분석하고 검증하는 경험을 할 수 있었다.
각 Agent가 어떤 입력을 받고 어떤 판단을 내리는지, 병렬 라우팅이 실제로 의도한 대로 수행되는지, 그리고 특정 프롬프트가 왜 잘못된 결과를 만드는지까지 시각적으로 추적하며 디버깅할 수 있었고, 이를 통해 AI 시스템의 신뢰성과 제어 가능성을 크게 높일 수 있었다. 또한 프로젝트를 진행하면서 좋은 프롬프트 하나로 모든 문제가 해결되지는 않는다는 점도 크게 느꼈다.
실제로 Trace 로그를 분석해보면 모델의 성능 부족보다는 프롬프트의 모호함, 예외 처리 부족, 출력 포맷 불일치 같은 시스템 설계 영역의 문제가 더 자주 발생했다. 이를 해결하기 위해 Few-shot 예시를 반복적으로 수정하고, Fallback 로직과 검증 규칙을 추가하며 프롬프트 엔지니어링을 더 수정하고 발전해나갔다. 더 개선할점이 있고 발전할점도 있지만 짧은 기간동안 조원들과 토의하고 이뤄낸 결과이기에 이번 03Miniproject결과물은 만족한다.
좋은 팀원들과 함께 수없이 테스트하고, 실패하고, 개선해 나가며 완성했던 만큼 개인적으 정말 많이 배우고 성장할 수 있었던 프로젝트였다. 7주차-1을 마무리한다.
12조 조원분들 고생하셨습니다!
Github Private
