
📌 문자열(Strings)
🎯 base 패키지에 있는 함수
toupper() - 대문자로 변환
tolower() - 소문자로 변환
paste() - 문자열 합치기 구분자로 지정가능
paste0() - 문자열 합치기 공백없이
substr() - 부분 물자열 추출/대체
strsplit()
nchar()
sub() gsub() - 문자열 대체
grep() - * 문자열 검색
# 문자열을 자르기 위한 예제
string <- "ABCDEFG"
# 2번째부터 끝에서 2번째까지 부분 문자열 추출
substr(string, 2, nchar(string) - 2)
# 특정 인덱스의 문자 추출
str_sub("ABCDEFG", -6, -3)
# 부분 문자열을 대체하는 예제
string <- "ABCDEFG"
# 2번째부터 끝에서 2번째까지 ###으로 대체
substr(string, 2, nchar(string) - 2) <- "###"
string
# 이름 데이터를 변형하는 예제
names <- c("허준", "홍길동", "이몽룡", "건국대학교", "과학기술")
# 이름이 두 글자인 경우 첫 글자 + '#', 아니면 첫 글자 + '####' + 마지막 글자
names <- ifelse(
nchar(names) == 2,
paste0(substr(names, 1, 1), "#"),
paste0(substr(names, 1, 1), "####", substr(names, nchar(names), nchar(names)))
)
names
# 문자열 내 특정 문자 변환
# 첫 번째 "a"만 "A"로 대체
sub("a", "A", "abracadabra")
# 모든 "a"를 "A"로 대체 (global)
gsub("a", "A", "abracadabra")
# 동물 이름 리스트에서 특정 문자를 대문자로 변환
animals <- c("tiger", "eagle", "elephant")
# 첫 번째 e만 대문자로 변경
sub("e", "E", animals)
# 모든 e를 대문자로 변경
gsub("e", "E", animals)
# 공백 제거 예제
c_animals <- "tiger eagle elephant"
# 모든 공백을 제거
c_animals1 <- gsub(" ", "", c_animals)
c_animals1
# 문자열 검색 예제
strings <- c("Apple", "Tiger", "Cat", "Banana")
# 문자열 내 "a"가 포함된 요소의 인덱스 반환
grep("a", strings)
# "a"가 포함된 요소 자체를 반환
grep("a", strings, value = TRUE)
# 대소문자를 구분하지 않고 검색
grep("a", strings, ignore.case = TRUE)
# 특정 문자 제외하고 검색
grep("a", strings, ignore.case = TRUE, value = TRUE, invert = TRUE)
# mtcars 데이터셋에서 행 이름을 추출
names <- row.names(mtcars)
names
# mtcars 데이터셋의 첫 6행을 출력
head(mtcars)
# mtcars의 행 이름에서 "toyota" 포함된 행 이름 추출 (대소문자 구분하지 않음)
names <- row.names(mtcars)
grep("toyota", names, ignore.case = TRUE, value = TRUE)
🎯 패키지에 있는 함수
str_to_upper()
str_to_lower()
str_c()
str_detect()
str_split()
str_length()
str_detect()
str_extract()
str_trim()
# 문자열 끝에서 두 자리만 추출
str_sub("20241106", -2, -1)
# 문자열 5번째부터 끝까지 추출
str_sub("20241106", 5)
# 여러 문자열을 하나로 병합
str_flatten(c("2024", "11", "06"))
# 문자열 리스트 예제
text <- c(" 양쪽 모두 ", " 왼쪽만", "오른쪽만 ", "사이에 스페이스")
print(text)
# 문자열 양쪽 공백 제거
str_trim(text)
# 문자열 왼쪽 공백 제거
str_trim(text, side = "left")
# 문자열 오른쪽 공백 제거
str_trim(text, side = "right")
# 주소 문자열에서 특정 단어 추출
addr <- "충북 충주시 충원대로 268"
# 두 번째 단어 추출
word(addr, 2)
📌 정규식(Regular Expression)
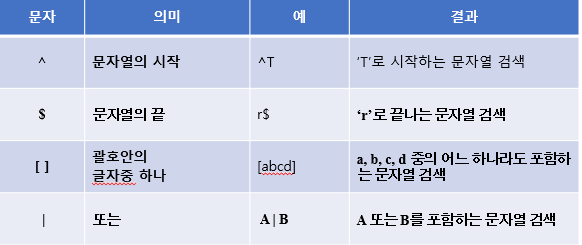
# 도로교통공단 데이터를 CSV 파일에서 읽어오기
data <- read_csv("../mydata/도로교통공단_시군구별 월별 교통사고 통계_20231231.csv",
locale = locale(encoding = "CP949"),
show_col_types = FALSE)
head(data)
# 충북 지역만 필터링하여 데이터 추출
index <- grep("충북", data$`시도`)
cb <- data[index, ]
cb
# 시도별 데이터 개수 출력
table(cb$`시도`)
table(cb$시도)
# '시'로 끝나는 시군구 필터링 후 개수 출력
idx <- grep("시$", cb$`시군구`)
city <- cb[idx, ]
table(city$시군구)
# '남'을 포함하는 시군구 필터링 후 개수 출력
idx <- grep("남", data$`시군구`)
south <- data[idx, ]
table(south$시군구)
# '남'으로 시작하는 시군구 필터링 후 개수 출력
idx <- grep("^남", data$`시군구`)
south <- data[idx, ]
table(south$시군구)
# '남'으로 시작하고 '구'로 끝나는 3글자 시군구 필터링 후 개수 출력
idx <- grep("^남.*구$", data$`시군구`)
south <- data[idx, ]
table(south$시군구)
# '남구'가 어떤 시도에 분포되어 있는지 확인
data$시도2 <- paste(data$시도, data$시군구)
idx <- grep("^남.*구$", data$`시군구`)
south3 <- data[idx, ]
table(south3$시도2)

무지(無知)