📌 리스트
2.1 데이터 추출 - 키 값으로
-
“리스트$키이름”으로 데이터 접근
-
names(리스트): 키이름
-
리스트의 원소는 anything
-
mylist$quiz는 벡터이므로 인덱스 사용 가능
# 리스트 만들기
mylist <- list(name='kim', quiz=c(50,40,30), score=c(80,90))
mylist
print(mylist)
mylist$quiz
mylist$score[2]2.2 리스트를 벡터로 - unlist
- 리스트에 있는 모든 값을 하나의 벡터로
 |  |
|---|

m <- matrix(1:20, 4, 5)
mA matrix: 4 × 5 of type int
1 5 9 13 17
2 6 10 14 18
3 7 11 15 19
4 8 12 16 20
m_df <- as.data.frame(m)
m_dfA data.frame: 4 × 5
V1 V2 V3 V4 V5
1 5 9 13 17
2 6 10 14 18
3 7 11 15 19
4 8 12 16 20
📌 행렬
apply( ) 함수
- 행렬, 리스트, 데이터 프레임은 여러 벡터를 포함
- 행렬과 데이터프레임은 테이블 형식
- 각 벡터에 대하여 평균, 합 등을 적용(apply)하는 함수 그룹
- apply(), lapply(), sapply(), tapply() 등 여러 가지가 있다.
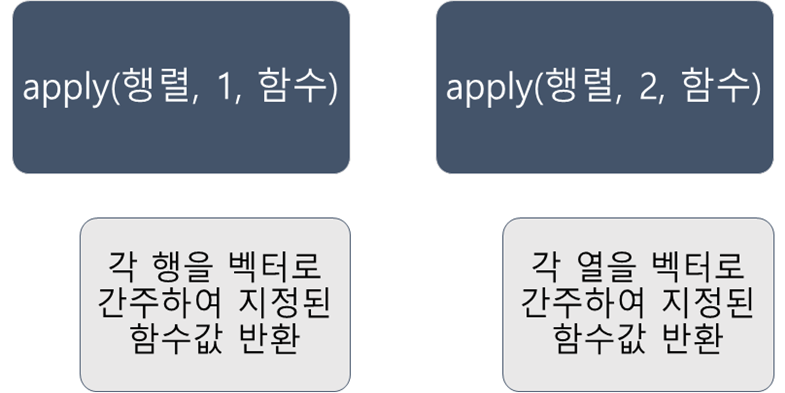
가로합 - apply(A, 1, sum)
세로합 - apply(A, 2, sum)
- 1은 행
- 2는 열
- sum은 합
- mean은 평균
- 행렬, 데이터프레임과 같은 테이블 형식에 사용 가능
m1 <- m[1:2, ]
m1A matrix: 2 × 5 of type int
1 5 9 13 17
2 6 10 14 18
m2 <- m[3:4, ]
m2A matrix: 2 × 5 of type int
3 7 11 15 19
4 8 12 16 20

📌 데이터 필터링 - subset()
- subset(df_name, 조건식)
조건을 만족하는 모든 행 추출 - subset(df_name, 조건식, select=var_name)
지정된 변수만 포함 - subset(df_name, 조건식, select=-var_name)
변수명 앞에 –가 붙으면 그 변수 삭제 - subset(df_name, 조건식, select=c(변수명1,변수명2, ...))
- subset(df_name, 조건식, select=-c(변수명1,변수명2, ...))
# mtcars에서 mpg가 30초과 32 미만인것, mpg, cyl, wt 열만 보여주기
subset(mtcars, mpg > 30 & mpg < 32, select=c(mpg, cyl, wt))
# 3변수 제외하고 보여주기 '-'
subset(mtcars, mpg > 30 & mpg < 32, select=-c(mpg, cyl, wt))
# 다른 방법
mtcars[mtcars$mpg>30, ]library(readxl)
data <- read_xlsx("../mydata/일별평균대기오염도_2023.xlsx")
head(data)
# na.rm=T는 결측값(NA)을 제거하는 옵션이다
print(apply(data[c(7,8)], 2, mean, na.rm=T))
무지(無知)