오늘의 공부 👍
2주차 시간에 배우는 웹 크롤링(Crawling)과 웹 스크래핑(Scraping)을 예습하고 싶어서 정리 해보겠습니다.
📝 웹 크롤링(Crawling)과 웹 스크래핑(Scraping)
- 고객들이 원하는 정보만을 골라 보여주는 기술
📝 웹 크롤링(Crawling)
-
Web상의 정보들을 탐색하고 수집하는 작업을 의미합니다.
-
규칙에 따라 자동으로 웹 문서를 탐색하는 컴퓨터 프로그램
-
검색 포털(네이버, 구글)에 키워드를 입력하면 해당 포털의 URL을 지닌 페이지 뿐만 아니라 외부 사이트도 본문의 요약본이 나오는 것을 볼 수 있습니다.
-
이러한 요약본을 만드는 것이 웹 크롤러가 하는 일입니다.
 출처: https://blog.codef.io/crawling_vs_scraping/
출처: https://blog.codef.io/crawling_vs_scraping/ -
요약
방대한 데이터를 수집하므로, 변화하는 데이터 파악에 유용하다. (내가 찾는 키워드와 연관된 링크)
📝 웹 스크래핑(Scraping)
-
특정 웹 사이트나 페이지에서 필요한 데이터를 자동으로 추출해 내는 것을 의미합니다.
-
자동으로 수집된 특정 정보가 필요한 분야에서 다양하게 활용되고 있습니다.(금융, 주식, 전자상거래 시장 등)
-
가격 변동 이슈를 빠르게 파악하기 위해 스크래핑 기술을 활용하기도 합니다.
-
이러한 데이터를 원하는 대로 사용할 수 있도록 데이터베이스에 저장 해주는 것이 스크래퍼 봇이 하는 일입니다.
 출처: https://blog.codef.io/crawling_vs_scraping/
출처: https://blog.codef.io/crawling_vs_scraping/ -
요약
특정 사이트나 페이지에 대한 데이터를 찾으므로, 정확한 정보를 요구할 때 유용하다. ( 주식 정보, 뉴스 등)
📝 웹 크롤링 vs 웹 스크래핑
- 웹 크롤링은 계속해서 탐색을 이어나가지만,
웹 스크래핑은 특정 웹 사이트에 특정 데이터를 추적하는 차이가 있습니다.
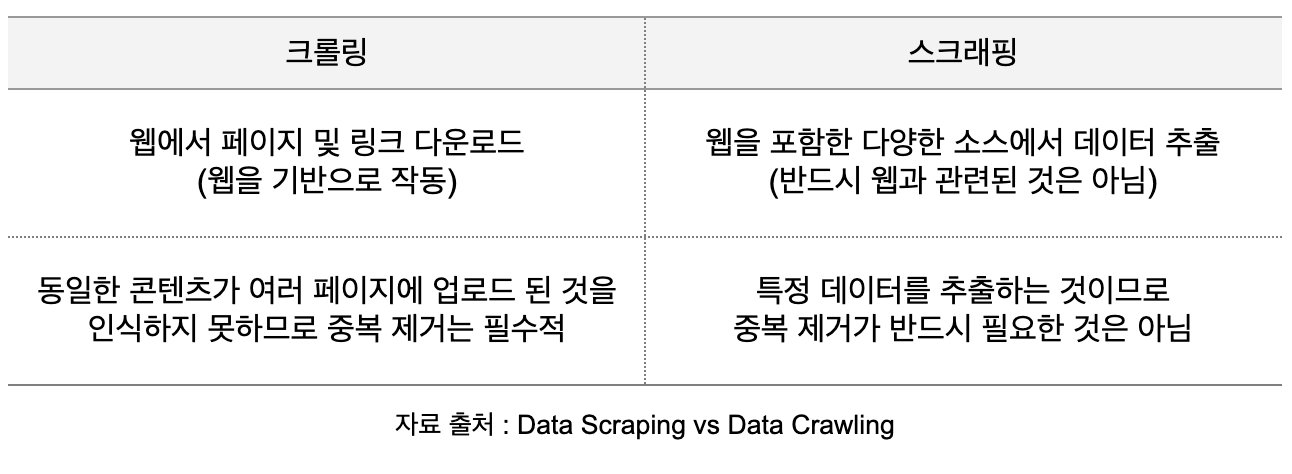
참고: https://blog.codef.io/crawling_vs_scraping/
참고: https://brightdata.com/blog/leadership/web-crawling-vs-web-scraping
참고: https://www.cloudflare.com/ko-kr/learning/bots/what-is-data-scraping/
참고: https://www.cloudflare.com/ko-kr/learning/bots/what-is-a-web-crawler/
