
Goals of EDA
데이터를 제대로 파악하기 위한 필수관문
잘못된 데이터는 아무짝에 쓸모 없고 가설을 머릿속으로 세우고 검증을 안 할 수 없다.
가설을 세우기 위해서도 명확한 파악은 당연 필수, 시각화를 위해서도 당연 필수...
그래서 탄생한게 EDA, 더 깔끔한 설명은 위의 링크로 확인하자.
실무에서 EDA를 사용하고자 할 때 어떻게 접근하는지 정리해보자.
1. 데이터 파악 (이봉성이면 이 모든 분석 다 무쓸모)
2. 데이터를 불러오자
3. 히스토그램으로 만들자(좀 읽기 쉽게)
굵직하게 나누자면 저렇게 될 수 있겠다.
이제 어떤 방식으로 데이터셋을 확인할 것인가?
나는 배운대로 파이썬(코랩)을 사용하여 앞으로 정리할 것이다.
- 데이터 파악 (Data description)
경제학에서 파악하는 방법
파이썬으로 파악하는 방법
시간이 부족해서 나머지는....나중에 출근ㅠㅠ
03/6 복습하러 와따아
일단 나는 아무것도 모르는 사람에게 일부터 열까지 가르친다는 생각으로 이 글을 쓰고 있다.
나는 금붕어니까 히히
Pandas
일반적으로
1차원 배열 형태의 데이터 구조를 Series
2차원 배열 형태의 데이터 구조를 DataFrame
라고 하는 것을 알고있자
한 줄로 더 줄여보자.
Series는 행, DataFrame은 행렬이다.
이 때
행을 구분하는 행제목을 index
열을 구분하는 열제목을 column
이라고 한다. (나 저 column이 헤더랑 짱 헷갈렸움...용어를 제대로 모르니 cheet sheet를 봐도 써먹을 줄 모름...)
- 데이터 프레임 기본 형태로 만들어보자 아래와 같다

그리고 중요한 게
import pandas as pd
import numpy as np
index = pd.date_range('1/1/2000', periods=8)
df = pd.DataFrame(np.random.rand(8,3), index=index, columns=list('ABC'))
print(df['B'])위와 같이 하면 결과가
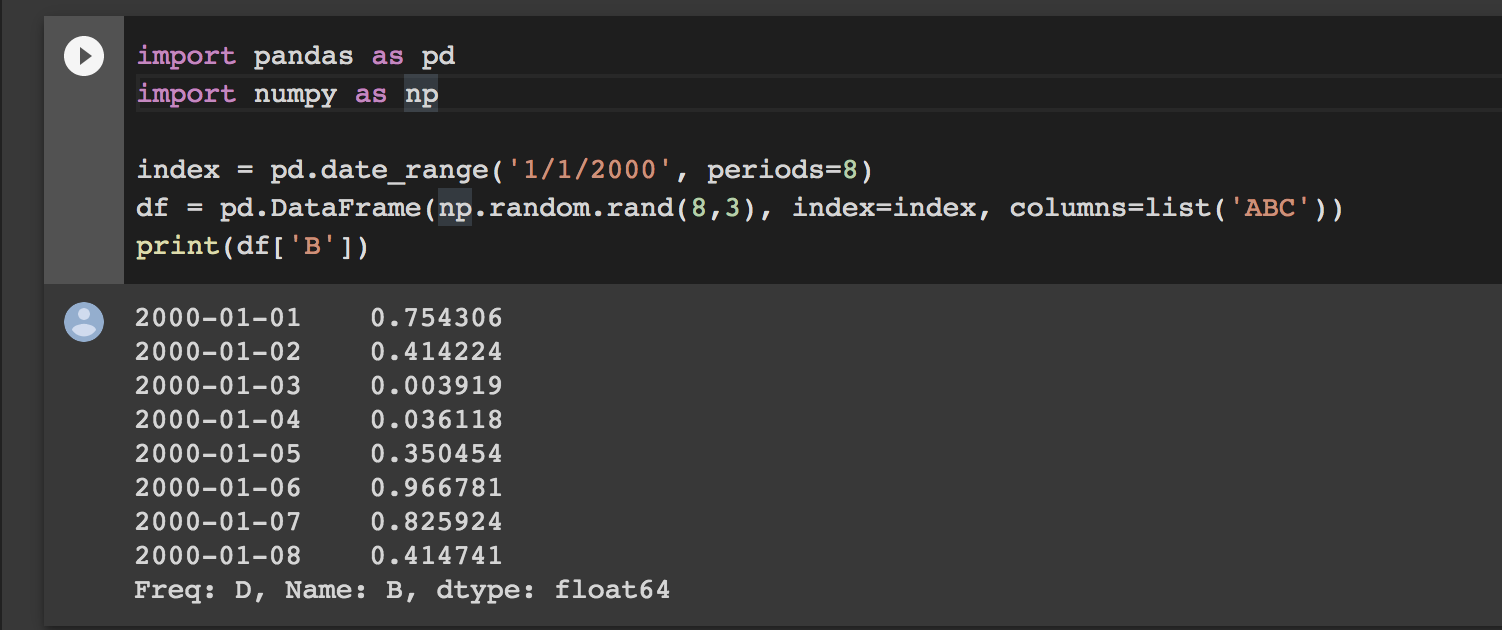
이렇게 나오는데 마치 열처럼 보이지만 여전히 행이고 0.754306의 index가 2000-01-01이 되는 것이다. 이거 처음에 용어 헷갈림 그니까 Series가 열이 아예 없는게 아니라
Series = 열1 행n
당연한 소리를 왜 쓰냐면... 머리가 막 꼬이면 이거도 안 당연해 보임...ㅋ
- B열의 값이 0.4보다 큰 값이 True인 애들만 모아서 새로 DataFrame 만들자
df2 = df[df['B']> 0.4]
위의 '열이름'을 앞으로는 header라고 부를 것이다.
1.데이터셋 가져오기
2.데이터 확인
3.데이터의 특정 부분 확인 및 시각화
4.File export
실무에서 데이터를 어떻게 불러오냐
1. csv 파일
2. excel 파일
3. html 파일
이렇게 3개를 자주 불러오고 보통 파일 자체를 직접 로컬(그니까 내 피씨에 저장되어 있는 파일들을 부를 때 로컬에서 부른다고 한다)에서 부르지 않고 url을 따와서 불러온다.
- Basic
import csv
f = open('Travel.xlsx') # f = file handler(just a variable)
- To import from colab(local_mydrive)
from google_colab import files
uploaded = files.upload()
import io
df = pd.read_excel(io.BytesIO(uploaded['Travel.xlsx']))
- To import from URL(using Pandas library) **강추
data_url = 'http://~~~Travel.xlsx'
df = pd.read_excel(data_url)
# If you want to import by sheet
df_sheet01 = pd.read_excel(data_url, sheet_name=0)
df_sheet02 = pd.read_excel(data_url, sheet_name=1)
df_sheet03 = pd.read_excel(data_url, sheet_name=2)
.
.
.
여기서 만약 행과 열을 바꾸고 싶으면 df_sheet01.T, df_sheet02.T를 하면 된다
여기까지를 하나의 코드로 다시 정리하면
# 한글 안 깨지게 히히 근데 이거 리눅스 언어 아님?
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
# 기본 설정
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#Pandas 이용하여 URL에서 액셀 파일 불러오기
data_url = 'https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/stocks/Travel.xlsx'
df = pd.read_excel(data_url)
df.head()
#sheet 별로 불러오고 all of rows와 all of columns 변경
df1 = pd.read_excel(data_url, sheet_name=0)
df2 = pd.read_excel(data_url, sheet_name=1)
df1 = df1.T
df2 = df2.T
df1
df2*근데 시트 수가 개많으면 저렇게 일일이 쓰고 싶지 않을 거 같은데...이건 어떻게 안 되나? 3/20일날 요거 다시 한 번 확인해서 해보자. 지금은 모르겠음
자 여기까지 하면 뭔가 쓸모없어 보이는 숫자 한 줄이 보일텐데 이게 바로
한 때 index였던 가장 맨 위 column(위에서 이걸 '열이름' 혹은 header로 부르기로 했다)이다. 이렇게
 *
*벨로그 아니 쓰다보니 개불편하네 왜 img src 사이즈 조절했는데 걍 다시 커지냐 글자색이랑 크기는 또 왜 조절 안되냐 수료하면 갈아탄다
저거 거슬리니까 없애자.
df1.rename(columns=df1.iloc[0]).drop(df1.index[0])*축약어 설명
iloc() = index location
drop() = drop(버릴것)
1.데이터셋 가져오기
2.데이터 확인
3.데이터의 특정 부분 확인 및 시각화
4.File export
.
.
3/09 다시 eda 정리하러 옴
오늘 4일차인데 이제 1일차는 완전히 이해되었기에 설명에서 빠트린 부분을 다시 추가하러 왔다. 내가 완전히 이해되는 주기가 3일이라 3일에 한 번 씩 다시 와서 회고하겠다.
"데이터를 확인" 한다는 말은 잘못된 값이 섞여있지 않은지를 확인한다는 뜻인데
수많은 데이터를 일일이 확인 할 수 없어서 행과 열로 나눈뒤 예상되는 수를 보고 맞지 않는 값은 0으로 처리하거나 버리는 방식으로 잘못된 데이터를 지운다.
나는 뼛속까지 예체능이라 차원이라 하면 이상하게 3차원만 느낌이 오는데
지금 우리가 사용하는 pandas는 1차원과 2차원을 제공한다.
아래 링크를 보며 판다스에서 말하는 차원에 대한 이해도를 높이자.
Summary of all ways to get info on dimensions of DataFrame or Series 와씨 설명 개깔끔 난 언제 저렇게 하지
여기가 공식보다 더 설명 잘 함;;
잘못된 값을 확인한 뒤 이 값들을 어떻게 할 것인가?
그리고 이 '잘못된 값'을 뭐라고 구글에 검색해야 나올까? 보통
missing value
missing feature
NA(Not available)
NAN(Not a number)
null(garbage)
결측치 대체 이 한자 쓰는 이 습관 진짜 누가 시작했냐 죽이고 싶다.
위와 같이 부르는 말이 매우 많고 어떤 종류냐에 따라 분류된다.
missing value에 대한 설명은 결측치에 대한 자세한 설명 여기 클릭
여기가 정말 잘해놓은 듯 하다. 꼭 참고하길! 제발 블로그 이전한다고 없애지 말아주세요!
깃허브 이전한다고 지우는 블로그 넘 많음...근데 나도 그럴거임...ㅎ
아래의 코드와 같은 방식을 기본형으로 생각하고 접근해보자.
나는 주피터가 아니라 코랩을 기준으로 작성하고 있다.
주피터사용자는 print를 써줘야 리턴값을 볼 수 있으니 양해부탁
위 코드와 연결되니 아래가 실행 안 되거나 이해 안 되면 처음부터 다시 꼼꼼히 해보길 권장
# 1. check dimension
df.shape
df1.info() # df로 해보고 뭐가 이상한지 확인해보세용
df2.info()
2. find missing value
df1.isnull() # 해보면 알겠지만 이거는 실용성 1도 없음
df1.isnull().sum #사실상 이게 기본좌
df2.isna().sum() # isnull최신버전 둘 차이 1도 없음
3. drop or fill missing value
df1.fillna(0) # 0으로 채워라 *dropna도 있다. 나는 아직 안 써봄
df1 = df1.fillna(0) #변수에 저장해라
df2 = df2.fillna(0)
위의 부분이 사실상 가장 중요하다 생각한다.
데이터 생김새와 정보 확인, na확인하고 다 합친 뒤, 0으로 바꾸자.
1.데이터셋 가져오기
2.데이터 확인
3.데이터의 특정 부분 확인 및 시각화
4.File export
이 부분은 방법이 매우 다양하다.
우선 계속 위의 과정을 이어서 할텐데
지금 다루고 있는 자료는 재무재표이다. 당기순손실을 제외한 이익잉여금을 투자유치자한테 보여주며 투자를 받고 싶다고 하자.
그렇다면 '당기순이익'이라는 header(column)에 해당하는 값들만 이용하여 그래프를 그리고 싶을 것이다. (이익잉여금은 이전의 당기순이익이 모두 누적된 값을 말하며 만약 당기순손실이 지속적으로 일어나 이익잉여금을 모두 까먹고 적자로 가는 경우 미처리 결손금이라 한다.)
우선 해당 열을 확인하자
df1['당기순이익']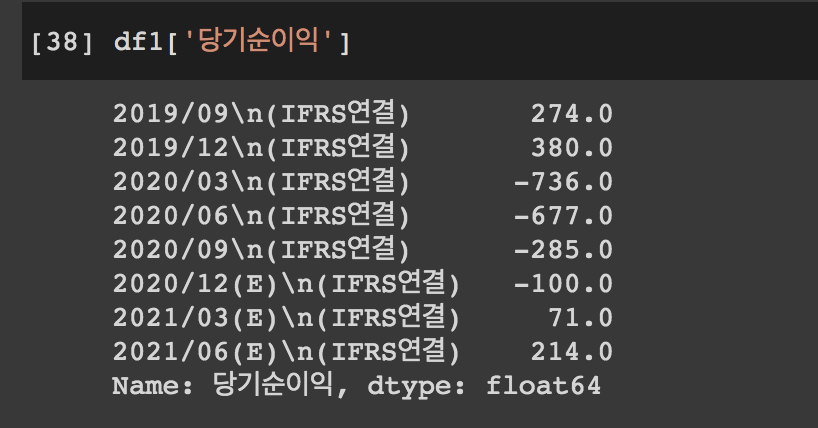
앗...0 이하의 값은 스리슬쩍 없어애 할 거 같다. 너무 적자네. 투자자 식겁해서 도망갈 듯!
#특정 조건을 만족시키는 index 찾기
df1.iloc[np.where(df1['당기순이익'] > 0)]
#특정 조건을 만족시키는 index와 column 찾기
df1.iloc[np.where(df1['당기순이익'] > 0)].loc[:,'당기순이익']위의 코드는 여기개꿀진짜 에서 참고하였다. 여기 진짜 천국
자 그러면
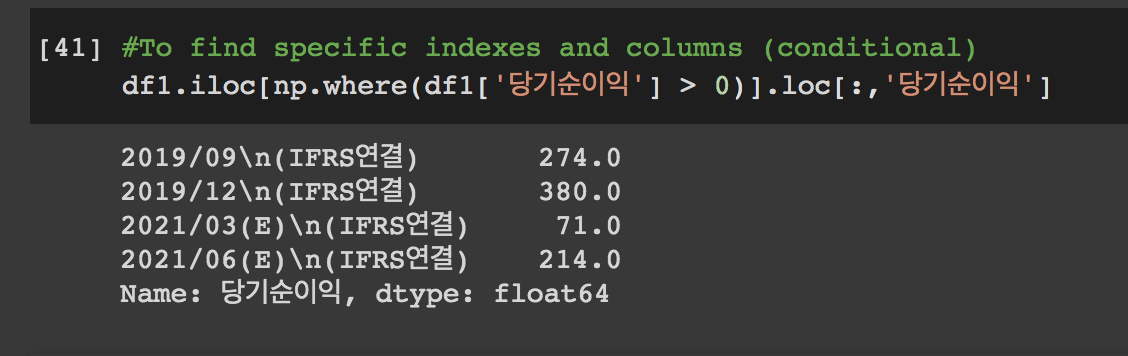
이렇게 뜬다. 이 숫자를 그냥 보여줄 수 없지 않나! 그래프로 그려서 보여주자!
시각화 (Data visualization)
시각화를 하는 방법도 참 많더라.
하지만 가장 먼저 matplotlib를 먼저 만나게 된다.
우리나라 재무재표니 한글이고 코랩은 영어기반이라 이거 깨짐 아래 다시 참고하라고 올림
[코랩한글깨짐방지](https://teddylee777.github.io/colab/colab-korean !sudo apt-get install -y fonts-nanum)
여기 나온 방법 그대~~로 안 하면 한글 계쏙 꺠짐 matplot보다 먼저 폰트 설치해놓고 런타임 돌린 뒤 다시 실행해야함;;;
어찌되었든 시각화는 나중에 한 번 자세히 다루고 싶지만 우선
matplot.pyplot의 가장 기본요소들을 하나로 모았다.
import matplotlib.pyplot as plt
#한글지정
#mac: encoding='utf8'
#window: ecoding='cp949'
#한글깨짐 고치기
#plt.rc('font', family ="AppleGothic") #mac
#plt.rc('font', family ='Malgun Gothic') #window
#plt.rcParms['axes.unicode_minus'] = False #마이너스 기호 깨질 경우 참고
from matplotlib import rc
from matplotlib import rcParams
plt.title("Sample")
#graphe01 = plt.plot(['여기는','x축','이란다'],['여기는','y축','이란다',])
#graphe02 = plt.plot(['하지만','list하나일땐','y축','기준'])
graphe03 = plt.plot([1,2,3],label='asc') # 여기서 label이 있어야 범례명 지정가능 asc = ascend
graphe04 = plt.plot([3,2,1],label='desc') # desc = descend
plt.legend() #이거는 그래프 여러개일 때 어느 그래프가 어떤 그래프인 알려주는 거 "범례(legend)"라고 부름 label 써줘야함
# plt.show # colab은 이거 안써도 알아서 나옴 마찬가지로 colab에선 print()도 안 써도 알아서 잘 나옴. 주피터도 그러나?? barplot은 리스트를 받는다 FCF는 DataFrame이기 때문에 바로 인식 안됨
index=x축, value=y축 만들고 싶다. 어떻게 할까?
#다행히 변수.함수() 형태로 하면 됨
plt.rc('font', family='NanumBarunGothic')
df1['FCF'].plot()
plt.show
나는 아직도 저 "." 이라는 애로 함수를 뒤에 붙이는 형태가 잘 안 와닿는다.
좀 더 보기 쉽게 다시 정리해서
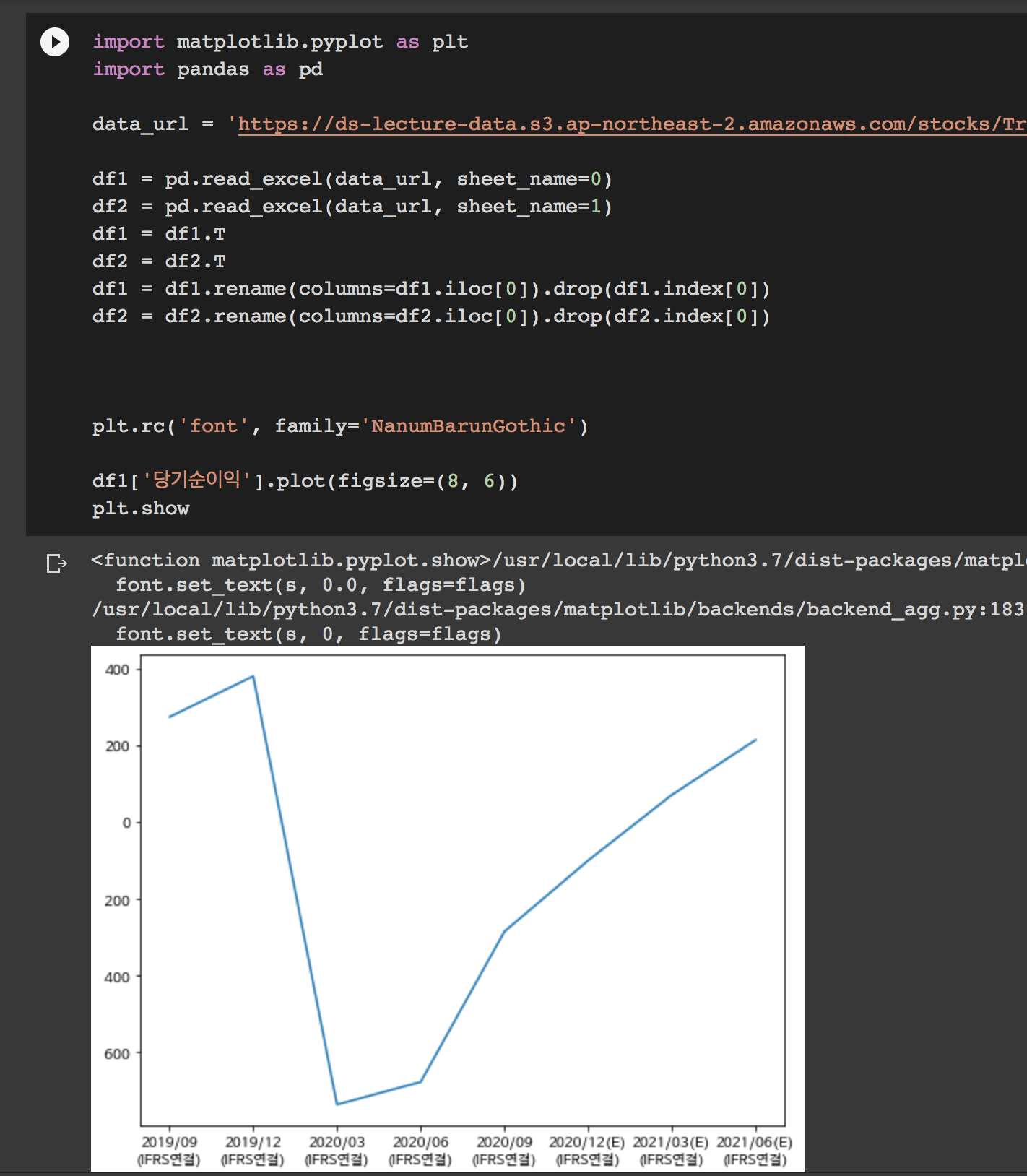
2020년에 대체 무슨 일이 있던거야...
어쨌든 아까 0이상의 값만 보여주고 싶었으니
그 값을 그래프로 만들어보자 어떻게 만들 수 있을까?
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
data_url = 'https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/stocks/Travel.xlsx'
df1 = pd.read_excel(data_url, sheet_name=0)
df2 = pd.read_excel(data_url, sheet_name=1)
df1 = df1.T
df2 = df2.T
df1 = df1.rename(columns=df1.iloc[0]).drop(df1.index[0])
df2 = df2.rename(columns=df2.iloc[0]).drop(df2.index[0])
plt.rc('font', family='NanumBarunGothic')
#df1['당기순이익'].plot(figsize=(8, 6))
df1.iloc[np.where(df1['당기순이익'] > 0)].loc[:,'당기순이익'].plot(figsize=(8, 6))흠...차라리 df1['당기순이익'].plot() 에서 2020/06을 기준으로 드라마틱하게 성장하는 걸 보여주는게...더 나을 거 같다 ㅎ;;
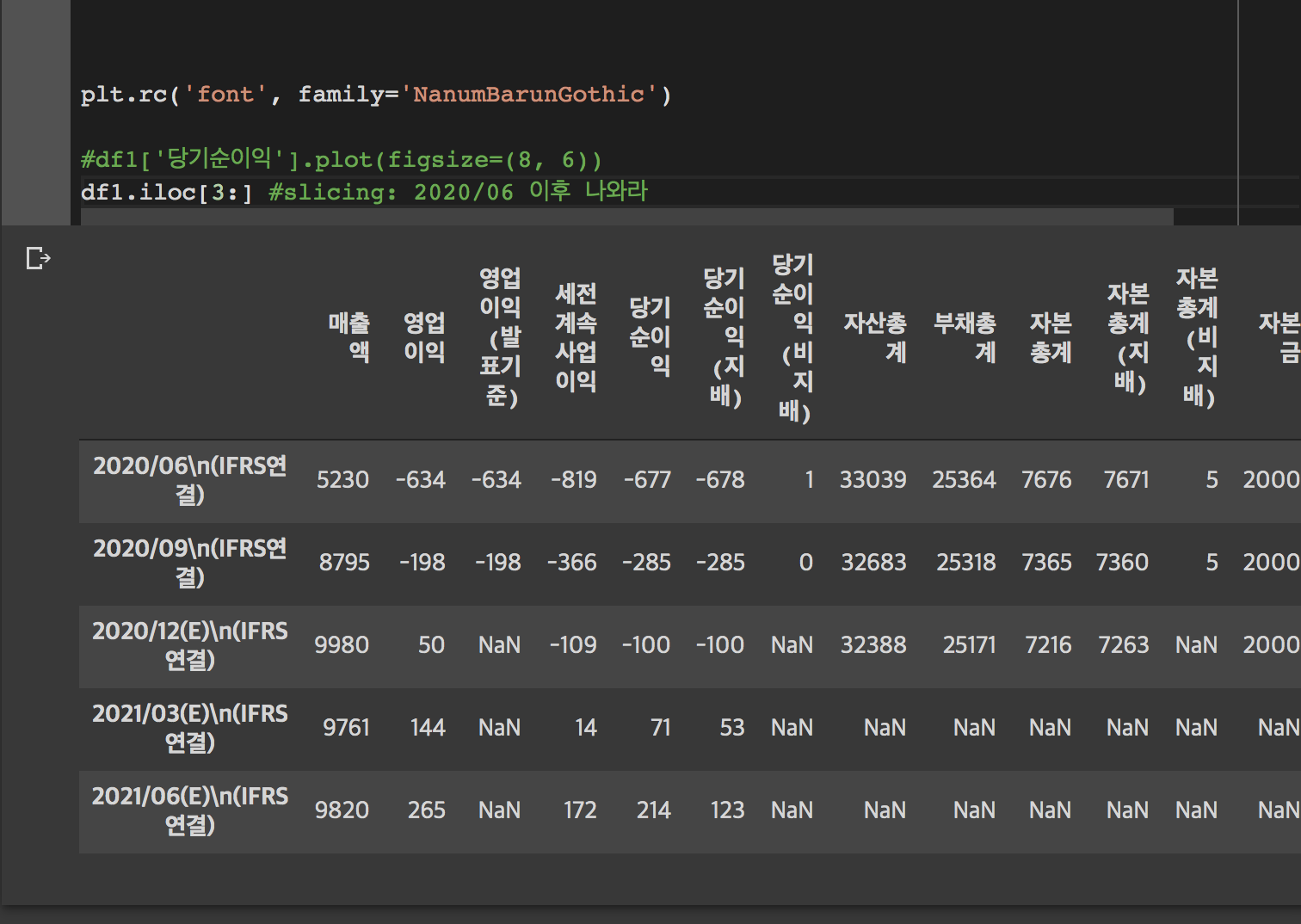
슬라이싱은 파이썬에서 리스트를 다룰 때 나오는 개념이다. 아직 익숙치 않아서 나는 매번 할 때마다 직접 돌려보고 순서가 맞는지 확인한 후 진행한다..ㅎ;
index(row)를 기준으로 코드를 쓰려고 했으나 header(column)를 기준으로 하는게 더 보기 쉽고 쉬웠다. 코드는 아래와 같다.
df1['당기순이익'].iloc[3:].plot()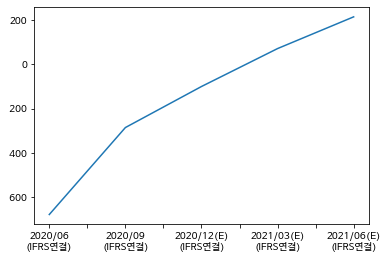
좋다. 이제 이 그래프를 들고가 무지한 개미 한 명 붙잡고 뻥치면 된다. 여기 이렇게 가파르게 성장한댜!! 주식사라!
1.데이터셋 가져오기
2.데이터 확인
3.데이터의 특정 부분 확인 및 시각화
4.File export
거의 다 왔...다...
이렇게 다듬은 데이터 소장하고 싶지 않는가?
그래서 보통
df1.to_csv("df1.csv")이라는 아주 간단한 코드로 csv파일로 저장을 할 수 있다.
참고로 코랩에서 이미지는 그냥 우클릭 복사하면 옮길 수 있으니 그대로 ppt로 옮겨서 사용해보자.
여기까지가 원래는 1일차로 공부해야 했던 양이었따. 눙물줄줄 정리는 4일 걸리네;;
마지막 코드 처럼 내가 원하는 데이터 프레임한테 함수를 한꺼풀씩 붙여서 디테일하게 접근하는 방식이 파이썬에서 사용되는 방식이다. 액셀에서는 눈에 바로 보이기 때문에 바로 적용이 가능하지만 파이썬은 바로 볼 수 없기 때문에 행렬이 굉장히 중요하다. 게다가 지금은 스몰데이터지만 빅데이터를 처리해야 할 때는 눈으로 일일이 확인 할 수 없으니 수학적으로 계산을 꼼꼼히 하고 진행을 해야 오류가 없다. 그렇기에...나는...이번 주말에...선형대수를...해야겠...ㅠ
*개인적인 이야기
31일까지 아이디어 공모전에 제출할 기획안에 사용할 자료조사를 하기 위해 다시 이부분을 다각도로 복습했는데 문제는 내가 원하는 데이터를 찾을 수가 없었다. 어떤 기획안을 만들든 간에 데이터 수집이 생각보다 엄청난 관건일 듯 싶다... 예방과 관련된 정돈된 데이터, 그것도 한국에서? 와 쉽지 않더라...이번 기수를 수료함과 동시에 aws 클라우드 공부와 함께 자료조사를 넉넉잡아 1년정도 같이 진행해야 할 듯 싶다. 애당초 예방이란게 표본이 모집단을 대표할 수는 있는걸까? ACE reserch에서 만명도 안되는 수로 조사를 진행했었다. 너무 적어. 전세계를 대상으로 데이터를 수집해서 증거로 보여줘야 사람들이 움직일 거 같다. 인터넷이 안 되는 곳의 사람들을 어떻게 조사하지? 종교문제는? 어떻게 접근해야 차별없이 더 효과적인 예방을 할 수 있을까. 일일이 데이터 수집을 하지 않고도 자동으로 집계되는 통계는 만들 수 없을까?