EDA에 대해 어느정도 이해했다면 feature engineering에 대해서 알아야 한다.
Mathematical formulas work on numerical quantities, and raw data isn't exactly numerical. Feature Engineering is the way of extracting features from data and transforming them into formats that are suitable for Machine Learning algorithms.
영업이익률 함 계산해보자
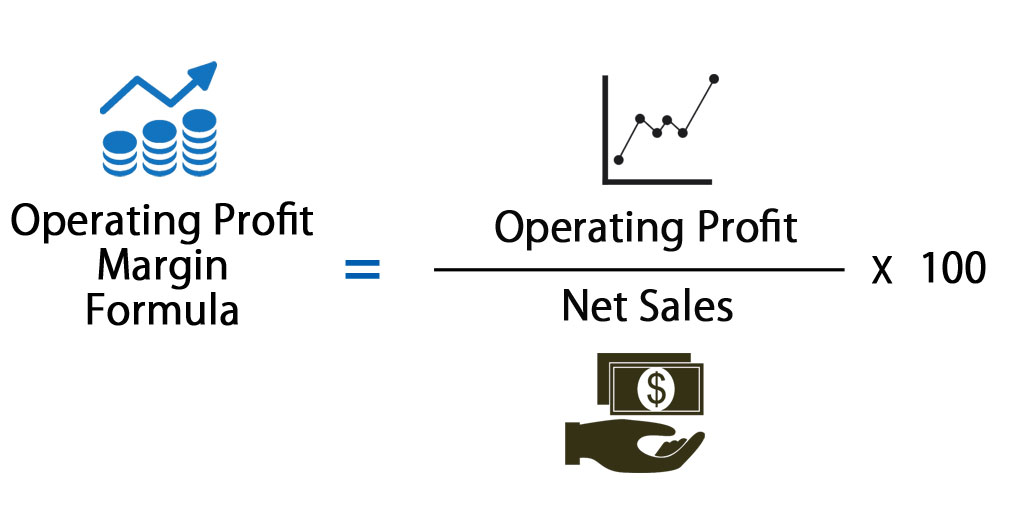
한국어로 한 번 더

이제 파이썬(+판다스)으로 계산해보자
이 때 계산하려고 쓰는 재무재표는 kt&g
불러오기는 아래와 같다.
df = pd.read_csv('kt&gcsv주소', index_col=0)여기서 왜 index_col=0을 쓰나
index0와 false차이 보기
동기들이 실수로 계산하였다 하여 나도 / 로 계산하겠다. (실수:/ 정수: //)
/ 와 //의 차이
df['영업이익률'] = df['영업이익']/df['매출액']에러가 뜬다. $쓰지도 않았는데 keyerror 뜸. 이게 숫자로 안 읽히고 스트링으로 읽혀서 그렇단다.(아래 이미지의 자본총계(비지배)부분 보면 NaN이 보이죵?) 여기서 형변환을 해줘야 하나봄
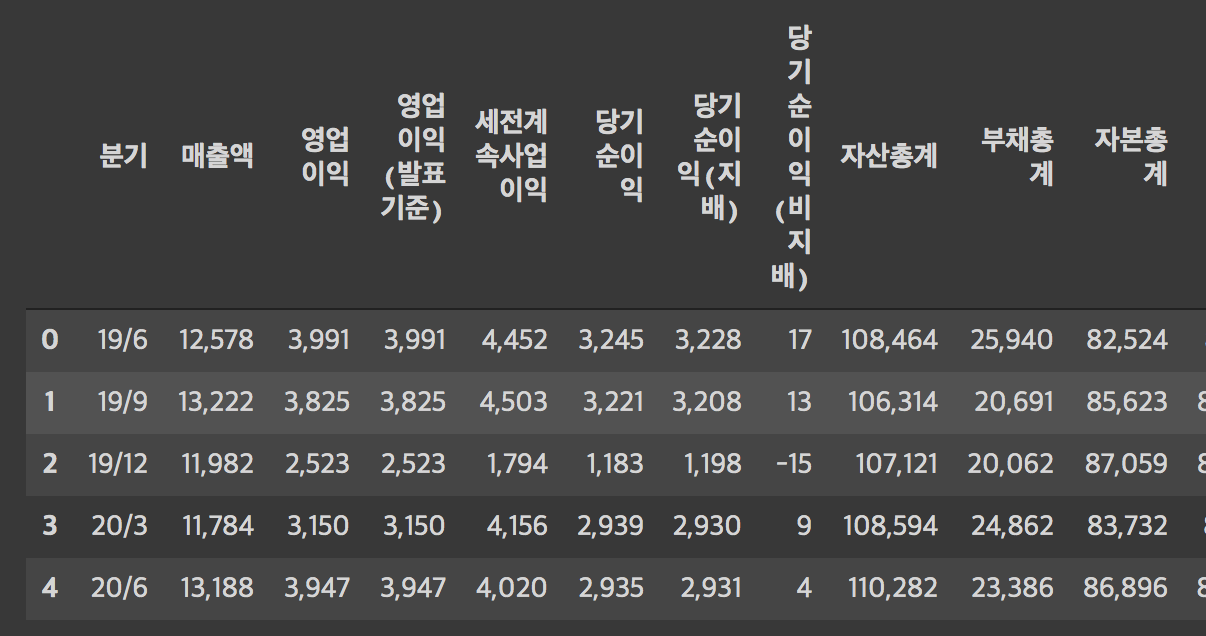
우선 , 를 뺴자
df = df.replace(',','', regex=True)그 다음 형변환
df = df.apply( pd.to_numeric, errors='coerce' )어떻게 나오나 확인 한 번 해주자
df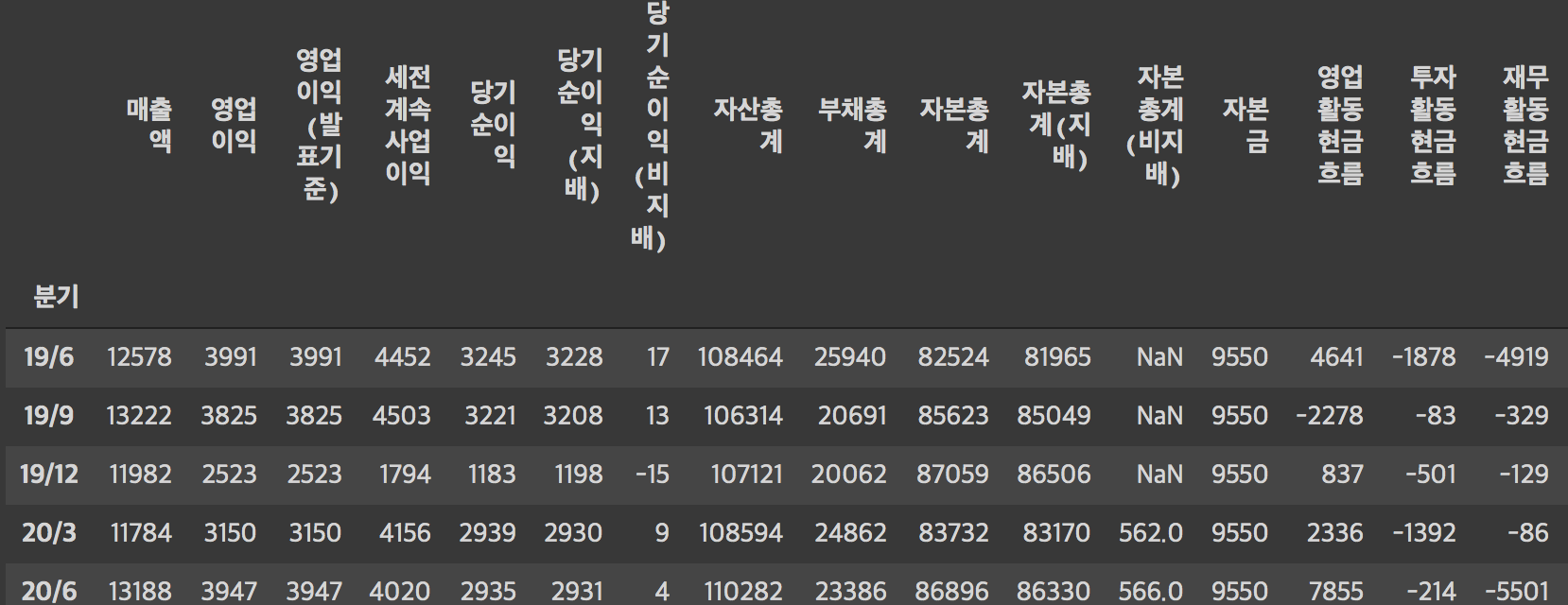
df.dtypes를 하면 타입들을 알 수 있다.
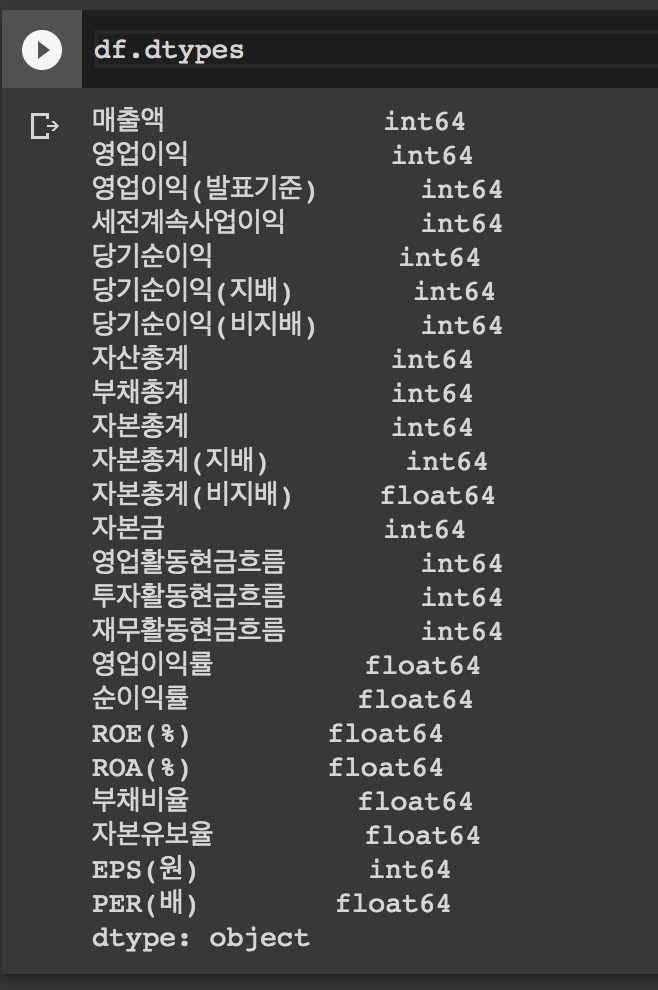
float으로 통일 ㄱ ㄱ
df = df.astype(float)참....길었다...여기까지 하면 이제 드디ㅣ어 데이터가 깔끔해져서 계산을 할 수 있다.
df['영업이익률'] = df['영업이익']/df['매출액'] * 100
df위의 과정들을 조금 더 정리할 수 있다.
우선...위에 쓴 링크가 잘못되었었다. 하지만 방법이 아주 틀린건 아니었으므로 그대로 놔두고
아래에 새로운 내용을 쓰고자 한다.
df = df.replace(',','', regex=True)
df = df.apply( pd.to_numeric, errors='coerce' )
df = df.astype(float)이 부분은 그리고 사실
def to_int(string):
return int(string.replace(",", ""))
df['영업이익'] = df['영업이익'].apply(to_int)
df['매출액'] = df['매출액'].apply(to_int)이렇게 해당 column만 string에서 int으로 바꿀 수 있다.
이 코드가 훨씬 좋은 코드인데 그 이유는 저번에 설명했듯이 한 꺼풀씩 덮어씌워져서 디테일하게 변수를 지정하기에 코드가 간단해지기 때문이다.
여기 보면 def라는 개념이 등장하는데 함수를 생성하는 예약어이다.
나는 아직 이 부분이 약하다.
여기서 함수 연습해보자!
함수기능에서 사실 가장 많이 쓰이는건 근데 위에 처음에 print로 나온 예제보다 return인지라...