DATA 표현
@ Numpy (as np)(Fun7)
-
벡터의 산술연산과 브로드캐스팅연산을 지원하는 다차원 배열
ndarray데이터 타입을 지원 -
Numpy를 이용하기 위해서는
ndarray객체를 만드러야 함.array라고 부르기도함 -
import numpy as np 로 호출
-
np.array([1, 3, 5, 7])는 print했을때
[1 3 5 7]로 보여짐 -
- .size: 행렬내 원소개수
- .shape: 행렬의 모양(행,렬)
- .ndim: 행렬의 축(axis)의 갯수
- .reshape(): 행렬의 모양을 바꿔주는 메소드, 모양을 바꾸기전후 행렬의 총원소개수 맞아야함-> 10개의 원소를 3*3으로 reshape불가
- np.zeros([행, 열]): 0으로 이루어짐
- np.ones([행, 열]) : 1로 이루어짐
np.zeros([2,3]) array([[0., 0., 0.], [0., 0., 0.]])
-
브로드캐스팅
-
random : 다양한 난수생성
- np.random.random(): 0과 1사이 실수형
- np.random.rand() : 0 부터 1사이의 균일분포에서 난수 matrix array 생성, 괄호 안 숫자는 생성할 난수의 크기, 여러개의 인수를 넣으면 해당 크기를 가진 행렬을 생성함
- np.random.randn() : 가우시안 표준 정규 분포에서 난수 matrix array 생성
- 가우시안 표준정규분포
- np.random.randint(0,10): 0~9 사이 정수형난수하나생성
- np.random.choice:
- np.random.permutation(10):원소의순서임의로바꿈
- np.random.normal(loc=0, scale=1, size=5):정규분포를 따르는 변수를 임의로 표본추출, 평균(loc), 표준편차(scale), 추출개수(size)
- np.random.uniform(low=-1, high=1, size=5): 균등분포를 따르는 변수를 임의로 표본추출, 최소(low), 최대(high), 추출개수(size)
- -arr.T
- np.transpose
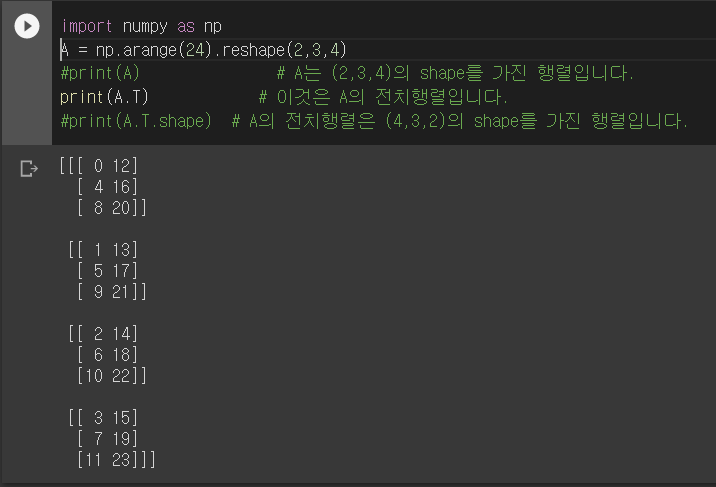
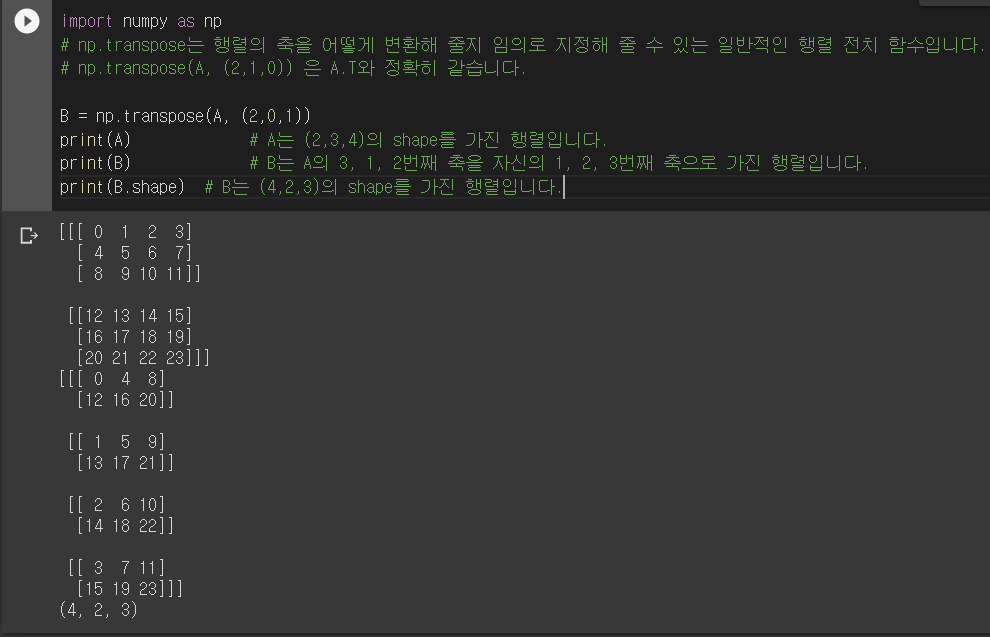
- 이미지의 행렬변환
1) matplotlib
2) PIL
3) from PIL import Image, ImageColor
4) 이미지 조작에쓰이는 메소드- Image.open()
- Image.size : 가로X세로
- Image.filename
- Image.crop((x0,y0,xt,yt))
- Image.risize((w, h))
- Image.save()
5) 이미지파일 행렬로 변환
- Pillow 라이브러리는 손쉽게 이미지를 Numpy ndarray로 변환
import numpy as np
img_arr = np.array(img)
print(type(img))
print(type(img_arr))
print(img_arr.shape)
print(img_arr.ndim)- Data augmentation: 데이터 증강, 딥러닝에서 데이터 개수를 늘릴때 사용되는 기법
- https://www.tensorflow.org/tutorials/images/data_augmentation
- 컬러(RGB)이미지 파일이니 변환된 행렬은 Height X Width X RGB Channel의 모양, 3차원
- 구조화된데이터
- 자체적인 서브구조를 가진 데이터(ex: coin과 pcs 내부구조를 가지고, 테이블형태로 전개, 행(row)과 열(column)을 가진 데이터
.format(): {} 사용해서 문자열출력할때 쓰는 함수(ex: my = "My name is {}, I'm {}".format("mimi",26))
11.Pandas
- 구조화된 데이터를 key& value 로만 나타내기에는 제한적이고 양이 많을때는 일일이 확인이 어렵다.
- 표형태로 보는것이 편하다.
- pandas 라이브러리에서 제공하는 Series와 DataFrame 을 통해 자료구조확인
- NumPy 기반으로 개발,
- 축의 이름에 따라 데이터를 정렬가능,
- 다양한 방식으로 데이터를 다룰수있음, 통합된 시계열 기능과 시계열데이터와 비시계열 데이터를 함께 다룰수있는 통합자료구조,
- 누락된 데이터 처리가능,
- 데이터통합 및 관계연산 수행가능
11- 1. Series
- 객체를 담을수있는 1차원 배열과 비슷한 자료구조, 배열형태(리스트, 튜플)를 통해 만들거나 NumPy 자료형으로 만들수있음
1) index - 딕셔너리의 키가 인덱스로 설정됨
- 인덱스변경가능 -> list의 인덱스(0부터시작하는 정수형태) 이면서 딕셔너리의 키(값이 할당되어있음)와 같은 기능으로 작용가능하다는 의미-> 데이터에 유연하게 접근가능
- 슬라이싱(slicing) 기능을 지원
- ser 이라는 Series 객체를 만듦.
- index와 value가 존재
ser = pd.Series(['a','b','c',3])
ser
0 a
1 b
2 c
3 3
dtype: object- ser.values로 Series 객체를 호출하며 array 형태로 반환됨
array(['a', 'b', 'c', 3], dtype=object) - ser.index는 RangeIndex가 반환
RangeIndex(start=0, stop=4, step=1) - 인덱스에 다른값넣기(.index)
ser2 = pd.Series(['a', 'b', 'c', 3], index=['i','j','k','h'])
0대신에 i, j, k, h가 들어감 ser2.index = ['Jhon', 'Steve', 'Jack', 'Bob']입력하면 i, j, k, h 대신 Jhon..이 들어감
2) name- Series 객체와 Series 인덱스는 모두 name 속성이 존재 DataFrame 에서 매우중요
ser3.name = 'Country_PhoneNumber'
ser3.index.name = 'Country_Name
Country_Name
Korea 82
America 1
Swiss 41
Italy 39
Japan 81
China 86
Rusia 7
Name: Country_PhoneNumber, dtype: int64- Series 객체의 이름을 설정
- Series Index의 name 속성을 이용해 인덱스 이름을 설정(korea가 country_name으로 설정됨)
11-2. DataFrame
- 표(table)와 같은 자료 구조
- 여러개의 칼럼을 나타낼수있다.
- csv 파일이나 excel 파일을 DataFrame으로 변환
- index 는 세로 대표값(변경가능), coloumns는 가로 대표값들(변경가능)
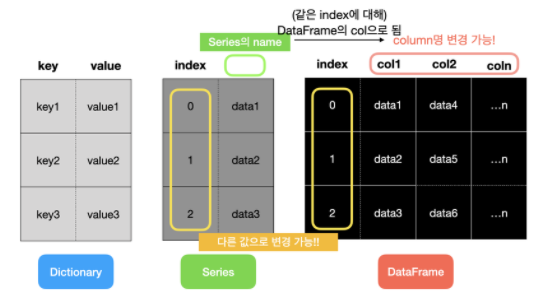
11-3. EDA(데이터탐색)
-
.head() : 데이터셋의 처음 5개 행을 보여줌
-
.tail() : 마지막 5개 행 보여줌
-
.columns : 이용해서 데이터셋에 존재하는 컬럼명을 확인
-
.info() : 각 컬럼별로 Null값과 자료형을 보여주는 메소드
-
.describe()
- 기본적 통계 데이터(평균, 표준편차 등)를 pandas에서 손쉽게 보기
- 각 컬럼별로 기본 통계데이터를 보여주는 메소드
- 개수(Count), 평균(mean), 표준편차(std), 최솟값(min), 4분위수(25%, 50% 75%), 최댓값(max)
-
.isnull().sum()
- 결측값(missing value) 확인시 필요
- 결측값을 isnull()로 확인후, sum()로 데이터갯수총합구하기
-
.value_counts() : 범주형데이터(case,category)로 기재되는 컬럼(가로)이 각 범주별로 값이 몇개 있는지 구할수있다. (피벗같은 느낌..메소드앞에 있는 데이터들의 카테고리별 갯수를 알수있음) ex)
data['RegionName'].value_counts()같은 경우 RegionName열 에 있는 값들의 갯수를 알려줌, -
.value_counts().sum() : sum()메소드 추가해서 컬럼별 통계수치의 합을 구할수있음,
(🤔결측치 확인이 가능할지도..그러나 메소드 앞 데이터명을 써서 일일이 확인해하는것은 비효율적인것같다.) -
.corr()
- 상관관계를 나타내는 메소드. 모든 컬럼이 다른 컬럼 사이에 가지는 상관관계를 일목요연하게 확인해볼수있다.
- EDA에서 매우 중요한 단계. 불필요한 컬럼제외하기 위해 무엇이 불필요한지 알기위해 필요
- 함께 움직이는 경향이 있다는 것, 두 변수의 연관된 정도를 나타낼뿐
- 인과관계를 설명하는 것은 아님. 원인결과를 알고싶으면 회귀분석을 통해 알수있음
- r값은 x와 y가 완전히 동일하면 +1, 전혀다르면 0, 반대방향으로 완전히 동일하면 -1
- .drop(삭제할 값, 행에서 삭제할지 or 열에서 삭제할지, 원본에서 바로 바꾸려면)
data.drop(['Latitude','Longitude','Country','Date','HospitalizedPatients', 'IntensiveCarePatients', 'TotalHospitalizedPatients','HomeConfinement','RegionCode','SNo'], axis=1, inplace=True) - 해석하자면, 행(디폴드값), 열에서 lat~삭제하고, 원본에서 바로 바꾸자
- axis=0 행(디폴드값), aixs=1 열(column):함수에 index, column이라는 파라미터를 사용하지 않을때
- axis = 1의 경우 정 열을 통째로 수정하는게 아닌 열의 각 요소들을 수정
- 원본에서 바로 바꾸고 싶다면 inplace=True
Visualization(시각화)
@ matplotlib(Fun8)
1. 막대그래프
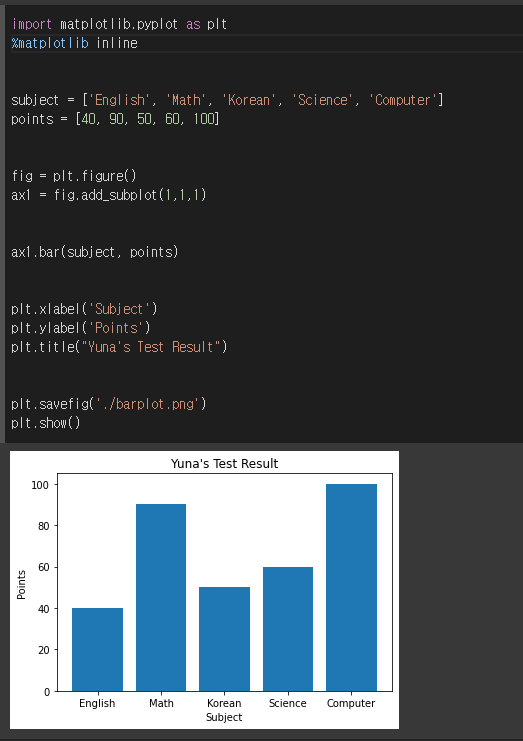
- 코드 뜯어보기
import matplotlib.pyplot as plt: 그래프 그리기 위해 라이브러리 가져오기%matplotlib inline: 주피터 노트북을 실행할때 주로 같이 씀, 쥬피터노트북을 실행한 브라우저에서 바로 그림을 볼수있게함subject = ['English', 'Math', 'Korean', 'Science', 'Computer'] points = [40, 90, 50, 60, 100]: 그래프 데이터fig = plt.figure(): figure()라는 객체는 도화지(그래프)- figsize 인자값을 주어 그래프의 크기를 정할 수 있다.
- fig = plt.figure(figsize=(5,2))
ax1 = fig.add_subplot(1,1,1): figure()객체에 add_subplot 메소드를 이용해 축을 그려준다.- add_subplot의 인자 (행, 열, 그려지는 좌표위치) 좌우순서
ax1.bar(subject, points): bar() 메소드를 이용해 막대그래프를 그립- 인자에 위에서 정의한 데이터들을 x, y순으로 넣어 줌
plt.xlabel('Subject'): x 라벨(제목)
-plt.ylabel('Points'): y 라벨(제목)plt.title("Yuna's Test Result"): 표제목
2. 선그래프
-그래프 데이터
csv_path = os.getenv("HOME") + "/aiffel/data_visualization/AMZN.csv"
data = pd.read_csv(csv_path ,index_col=0, parse_dates=True)
price = data['Close']
-
축 그리기 및 좌표축 설정
fig = plt.figure()도화지
ax = fig.add_subplot(1,1,1)사각형만듬 1*1 총 1개의 그래프 1사분면에
price.plot(ax=ax, style='black')AxesSubplot:xlabel='Date'
plt.ylim([1600,2200])(1600.0, 2200.0) y축 범위
plt.xlim(['2019-05-01','2020-03-01'])(18017.0, 18322.0) x 축 범위 -
주석달기
important_data = [(datetime(2019, 6, 3), "Low Price"),(datetime(2020, 2, 19), "Peak Price")]
for d, label in important_data:
ax.annotate(label, xy=(d, price.asof(d)+10), #주석을 달 좌표(x,y)
xytext=(d,price.asof(d)+100), #주석 텍스트가 위차할 좌표(x,y)
arrowprops=dict(facecolor='red')) #화살표 추가 및 색 설정 -
보여주기
plt.show()# 위에 검은창 사라짐 -
Pandas Series 데이터 활용
- price = data['Close']가 바로 Pandas의 Series
- rice.plot(ax=ax, style='black')에서 Pandas의 plot을 사용
- matplotlib에서 정의한 subplot 공간 ax를 사용
-
plt.xlim(), plt.ylim()을 통해 x, y 좌표축의 범위를 설정
-그래프 안에 추가적으로 글자나 화살표 등 주석을 그릴 때는annotate()메소드 -
grid() 메소드를 이용하면 그리드(격자눈금)를 추가
-plt.plot()-
figure()객체를 생성하고 add_subplot()으로 서브 플롯을 생성하며 plot을 그리는 과정 생략 할수있는 명령
-
matplotlib은 가장 최근의 figure객체와 그 서브플롯을 그림
-
서브플롯이 없으면 서브플롯 하나를 생성
-
x데이터, y데이터, 마커옵션, 색상 이용가능
-plt.plot(x, np.sin(x),'o')
-plt.plot(x, np.cos(x),'--', color='black') -
plt.subplot(2,1,1) (행갯수, 열갯수, 위치(min: 1 max: 행*열)
-
linestyle='dotted'
-
3. 그래프 사대천왕
(1) 데이터준비
- 데이터 불러오기
- Seaborn의 load_dataset() 메소드를 이용하여 api를 통해 다운로드가능
import pandas as pd
import seaborn as sns
tips = sns.load_dataset("tips.csv")
(2) EDA(데이터 살펴보기
- df = pd.DataFrame(tips) / df.head()
(3) 범주형데이터
- 막대 그래프를 사용하여 수치를 요약
- 일반적으로 가로, 세로, 누적, 그룹화된 막대 그래프를 사용
grouped = df['tip'].groupby(df['sex'])- df['tip'] 컬럼을 groupby()한다는 뜻
- 괄호안 인자 그룹에 대한 정보(총합,평균,데이터 량 등)가 grouped객체에 저장됨
grouped.size();성별에 따른 데이터 량(팁 횟수)grouped.mean(): 위에서 선언된 변수 grouped 의 평균(mean)sex = dict(grouped.mean()): sex 변수는 평균데이터가 딕셔너리형태로 들어가있음- x = list(sex.keys()) x값
- y = list(sex.values()) y값
- 그래프그리기
import matplotlib.pyplot as plt plt.bar(x = x, height = y) plt.ylabel('tip[$]') plt.xlabel('sex') plt.title('Tip by Sex')
(4) (3)을 Seaborn과 Matplotlib을 활용해 간단히 보여줌
sns.barplot(data=df, x='sex', y='tip')- sns.barplot의 인자로 df를 넣고 원하는 컬럼을 지정
.barplot: 지정한 변수의 평균을 계산
plt.figure(figsize=(10,6)) # 도화지 사이즈를 정합니다.
sns.barplot(data=df, x='sex', y='tip')
plt.ylim(0, 4) # y값의 범위를 정합니다.
plt.title('Tip by sex') # 그래프 제목을 정합니다.- x값을 day로 주면 요일에 따른 그래프 그릴수있음
- 범주형 그래프를 나타내기에 좋은 violineplot 을 사용
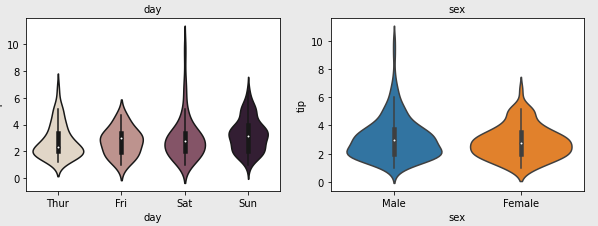
팁을 2달러 받은 사람은 6달러 받은 사람보다 많은것을 알수있게됨 - catplot : 동일한 데이터가 얼마나 모여있는지 알수잇음
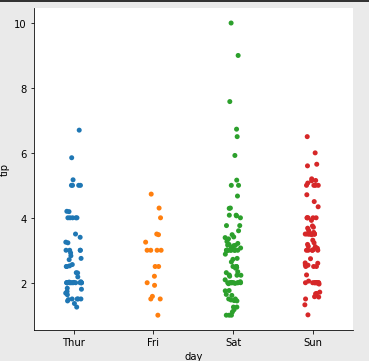
(5) 시계열 데이터 시각화
-
데이터 불러오기
data = pd.read_csv(csv_path)
flights = pd.DataFrame(data) -
그래프그리기
sns.barplot(data=flights, x='year', y='passengers')평균
sns.pointplot(data=flights, x='year', y='passengers')점으로 나타내기
sns.lineplot(data=flights, x='year', y='passengers')선으로 나타내기
sns.distplot(flights['passengers'])히스토그램 -
히스토그램(Heatmap)
- 데이터 차원에 대한 제한은 없으나 모두 2차원으로 시각화하여 표현
- Heatmap을 그리기 위해 데이터를 pivot(어떤 축, 점을 기준으로 바꾸다)
pivot = flights.pivot(index='year', columns='month', values='passengers')index는 왼쪽 첫번째열, colums는 값을 나눌 기준,year과 month로 pivot한을 코드로 짠거
다양한 데이터 전처리기법
1. 결측치(Missing Data)
1) 처리방법
- 결측치가 있는 데이터 제거
- 결측치를 어떤 값으로 대체
2) 결측치 여부 확인하기
trade = pd.read_csv(csv_file_path)len(trade): 전체 데이터 건수len(trade) - trade.count(): 전체 데이터 건수에서 각 컬럼별 값이 있는 데이터 수를 빼기 , 숫자가 클수록 결측치가 많음trade = trade.drop('기타사항', axis=1): 기타사항이 전체다 결측치라 컬럼 삭제 , .drop 메소드로 삭제, axis=1 은 열(칼럼)을 타나냄DataFrame.isnull(): 데이터마다 결측치 여부를 True, False로 반환DataFrame.any(axis=1): 행마다 하나라도 True가 있으면 True, 그렇지 않으면 False를 반환
-trade.isnull().any(axis=1): 각 행이 결측치가 하나라도 있는지' 여부를 불리언 값으로 가진 Series가 출력trade[trade.isnull().any(axis=1)]: 결측치(빈칸)이 있는 데이터만 볼수있음,- 결측치 데이터(수치형)일때 보완할 방법
(1) 특정값 지정 : 결측치 많을 경우 데이터분산이 실제보다 작아지는 문제발생
(2) 평균, 중앙값등으로 대체: 결측치 많을 경우 1번과 같은 문제발생
(3) 예측값으로 대체: 다른 데이터를 이용한 예측값
(4) 시계열 특성을 가진 데이터의 경우 : 앞뒤 데이터를 통해 결측치 대체(ex: 기온측정센서데이터 같은 경우 전후 데이터의 평균으로 보완) DataFrame.loc[행 라벨, 열 라벨]을 입력하면 해당 라벨 데이터를 출력해줌, (ex : trade.loc[[188, 191, 194]] 같은경우 행 188,191,194만 보임, 열라벨이 없으므로)
2. 중복데이터
중복된 데이터 확인
DataFrame.duplicated(): 중복된 데이터 여부를 불리언 값으로 반환trade[trade.duplicated()]: 중복된 값을 직접 확인가능trade.drop_duplicates(inplace=True): 중복된 데이터 삭제, 중복된 값이 있을경우 true 로 불리언값이 나오기때문에
3. 이상치(Outlier)
(1) 이상치는 대부분 값의 범위에서 벗어나 극단적으로 크거나 작은 값
(2) 이상치 찾아내고 판단하기
z score- 평균과 표준편차를 이용하는 방법
- 평균을 빼주고 표준편차로 나눠서 계산 후 z score가 특정 기준을 넘어서는 데이터에 대해 이상치라고 판단
- 기준을 작게 하면 이상치라고 판단하는 데이터가 많아지고, 기준을 크게 하면 이상치라고 판단하는 데이터가 적어짐.
(3) 이상치 판단후 이상치 처리방법 4가지
- 이상치는 원래데이터에서 삭제후 이상치끼리 따로 분석
- 다른값으로 대체: 데이터가 적을 경우 다른값 대체가 나음. 최대값 최솟값을 설정 하여 데이터의 범위를 제한함
- 다른 데이터를 활용하여 예측모델을 만들어 예측값 활용
- binning을 통해 수치형 데이터를 범주형으로 바꾸기
- binning :비닝일과 부름, 변수구간화, 연속형 변수를 특정구간으로 나누어 범주형 또는 순위형 변수로변환하는 방법
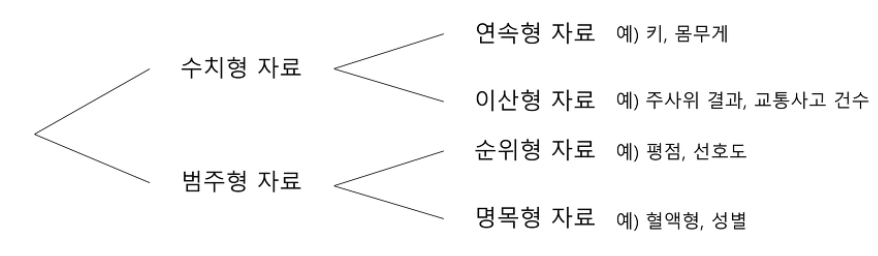
- 수치형데이터 : 양적자료, 관측된 값이 수치로 측정되는 자료, 키, 몸무게, 시험성적 등
- 연속형 자료: 키, 몸무게와 같이 값이 연속적인 자료
- 이산형 자료: 자동차 사고건수와 같이 값이 셀수있는 자료
- 범주형데이터 : 질적자료, 관측 결과가 몇개의 범주 또는 항목의형태로 나타나는 자료, 성별, 선호도(좋다, 그저그렇다, 싫다), 혈액형, 지역 등,머신러닝이나 딥러닝 프레임워크에서 범주형을 지원하지 않는 경우 원-핫 인코딩을 해야 합
- 범주형 자료를 수치형 자료처럼 표현할수 있다. 예로 여자는 1, 남자는 0으로 표현, 수치형 자료처럼 표현되어있는 범주형 자료를 잘 구분해야함
- 순위형 자료 : 범주간에 순서의 의미가 있는 자료, 선호도(매우좋다, 좋다, 그저그렇다...)범주가 주어졌을때 순서가주어짐
- 명목형 자료: 혈액형과 같이 순서의 의미가 없는 자료
(4) z-score 메소드
def outlier(df, col, z)- 이상치인 데이터의 인덱스를 리턴하는 outlier라는 함수 만들기
- 데이터프레임 df, 컬럼 col, 기준 z를 인풋으로 받음
abs(df[col] - np.mean(df[col])): 데이터에서 평균을 빼준 것에 절대값을 취하기abs(df[col] - np.mean(df[col]))/np.std(df[col]): 위에 한 작업에 표준편차로 나눠주기df[abs(df[col] - np.mean(df[col]))/np.std(df[col])>z].index: 값이 z보다 큰 데이터의 인덱스를 추출- z의 값이 클수록 이상치가 적어짐
not_outlier는<= z: 이상치 값이 아닌 데이터만 추출
(5) IQR 메소드
- z-score가 한계점이 있어 그에 따른 대안으로 이상치를 알아내는 방법임
- 한계점 : 평균과 표준편차에 의존하기때문에 그 자체가 이상치의 영향을 많이 받음, 작은 데이터셋의 경우 z-score의 방법으로 이상치를 알아내기 어렵다. 특히 아이템이 12개이하인 데이터셋에서는 불가능함
- 사분위범위수(Interquartile range) 라고 함
- IQR은 제 3사분위수에서 제 1사분위 값을 뺀 값으로 데이터의 중간 50%의 범위
def outlier2(df, col):
q1 = df[col].quantile(0.25)
q3 = df[col].quantile(0.75)
iqr = q3 - q1
return df[(df[col] < q1-1.5iqr)|(df[col] > q3+1.5iqr)] <이상치>
outlier2(trade, '무역수지')
4. 정규화(Normalization)
- 컬럼마다 단위가 다른 스케일이 크게 차이나는 데이터 입력시 머신러닝 모델 학습에 문제발생
- 모델의 파라미터를 업데이트하는 과정에서 범위가 큰 컬럼의 파라메터만 집중적으로 업데이트하는 문제가 생김
- 컬럼간에 범위가 크게 다를 경우 전처리 과정에서 데이터를 정규화
- 방법은 표준화(Standardization) 와 Min-Max Scaling가 있음
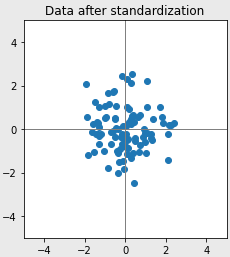
- Standardization 데이터의 평균은 0, 분산은 1로 변환
- 코드로 나타내면 아래와 같음, (mean 평균, std는 표준편차)
- x_standardization = (x - x.mean())/x.std()
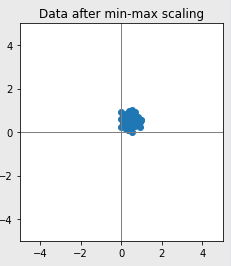
- Min-Max Scaling 데이터의 최솟값은 0, 최댓값은 1로 변환
- 코드로 나타내면 아래와 같음(min 최소값, max 최대값)
- x_min_max = (x-x.min())/(x.max()-x.min())
-원래파일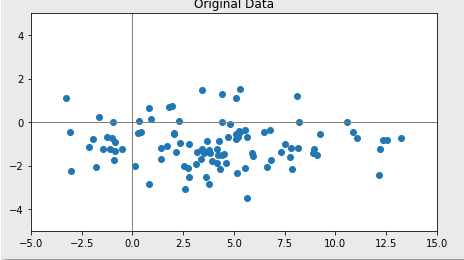
- Standardization 데이터의 평균은 0, 분산은 1로 변환
- 표준화
- Min-Max Scaling
- 그 외 방법으로 scikit-learn의 StandardScaler, MinMaxScaler 도있다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
- 로그 변환 기법도 존재함
5. 원-핫 인코딩(One-Hot Encoding)
- 머신러닝이나 딥러닝 프레임워크에서 범주형을 지원하지 않는 경우
- 원-핫 인코딩이란 카테고리별 이진 특성을 만들어 해당하는 특성만 1, 나머지는 0으로 만드는 방법
- pandas로 함
pd.get_dummies함수- pd.concat(연결함 함수, 연결할 함수, axis=1(열, 옆으로 붙임)
- pd.drop( 삭제할 컬럼명, axis=1 (열삭제), inplace=True)
- inplace 옵션은 drop과 같은 주요 메소드들이 가지고 있으며, 디폴트 값은 False
- inplace 옵션이 True이면, 명령어를 실행 한 후 메소드가 적용된 데이터 프레임으로 반환, 반환값은 컬럼이 삭제된 Dataframe이 됨(삭제된값이 보임)
6. 구간화(Binning)
- 연속된 데이터를 구간을 나눠 분석할때 쓰는 방법
Data binning혹은bucketing라고함- pandas의 cut 과 qcut을 이용해 수치형 데이터를 범주형 데이터로 변형
- pd.cut함수 설명 : https://www.delftstack.com/ko/api/python-pandas/pandas-cut-function/
