Mass-Storage Structure
Mass-Storage
종류
-
HDD(Hard Disk Drive): 우리가 흔히 아는 저장소
-
SSD(Solid State Disk): NAND flash memory, Controller로 이를 통제하는 저장소
-
RAM disk: RAM을 저장소처럼 사용하는 기법
ex) 32bit OS에서 4GB의 램만 인식하는데 그 이상의 램을 저장소처럼 사용 -
Other: Magnetic Tape(카세트 테이프), CD, DVD 등
Disk Attachment
-
Host Attached: 호스트(컴퓨터 자체)에 붙어있는 저장소
ex) IDE, SCSI
Network Attached Storage(NAS)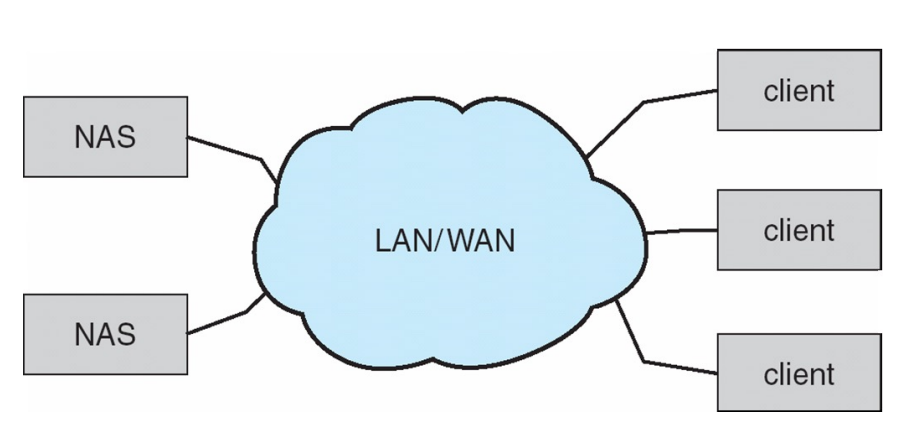
- IP주소를 통해 클라이언트가 원격 스토리지로 접근
- 파일시스템 형태, File-level access로 제공 → NFS(리눅스), CIFS(윈도우)
- 원격의 파일 스토리지를 LAN/WAN 등의 인터넷으로 제공
Storage Area Network(SAN)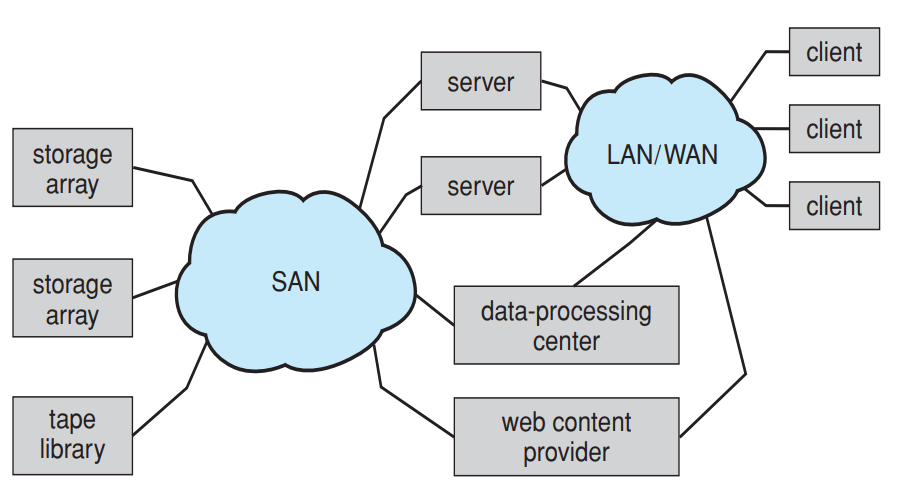
- NAS는 저장공간 개념이라면 SAN은 네트워크 개념
- 저장공간을 하나의 그룹으로 묶어서 SAN으로 운용
- 광섬유, SCSI같은 프로토콜을 사용, IP인터넷 접근을 하지 않음
- Block-level access(파일을 블록으로 나눔)
- 파일시스템: GFS(google file system: 대용량의 데이터를 다루는 곳에서 사용)

- 데이터센터에가면 SAN으로 묶인 수많은 storage array 존재
HDD
Disk Performance
- Seek time: 암이 움직여서 원하는 섹터로 가는 시간
- Rotation time: 정보가 저장된 실린더가 암의 위치에 오도록 회전하는 시간
- Transfer time: 암이 섹터의 정보를 읽은 후 요청으로 보내는데까지의 시간
- Seek time이 제일 큰 시간이라서 이것을 줄이는 것이 목표
Disk Scheduling Algorithm
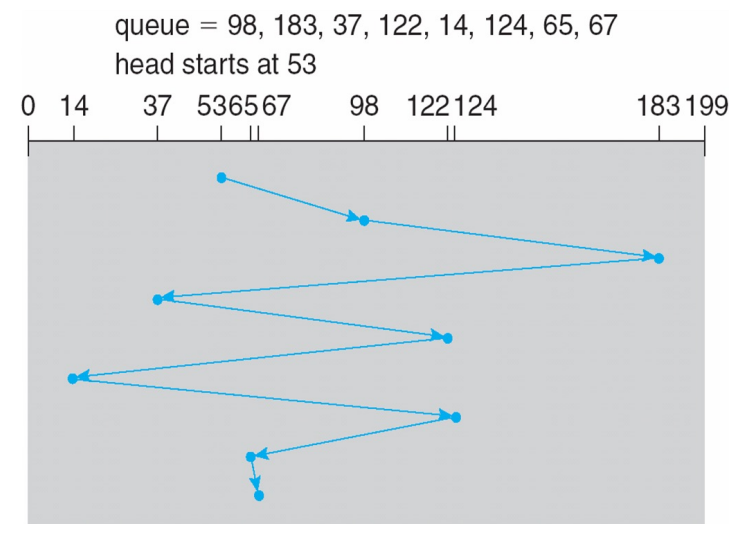
- FCFS: 읽어야하는 순서대로 읽음
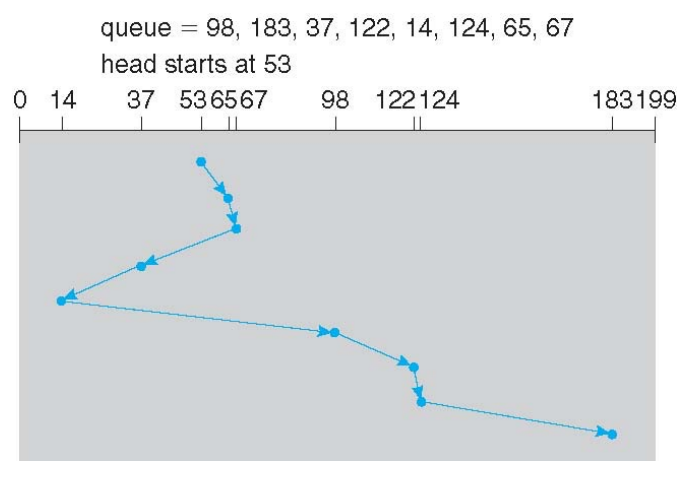
- SSTF: 근처에 있는 데이터부터 읽음
계속 근처의 데이터가 추가되면 starvation 발생
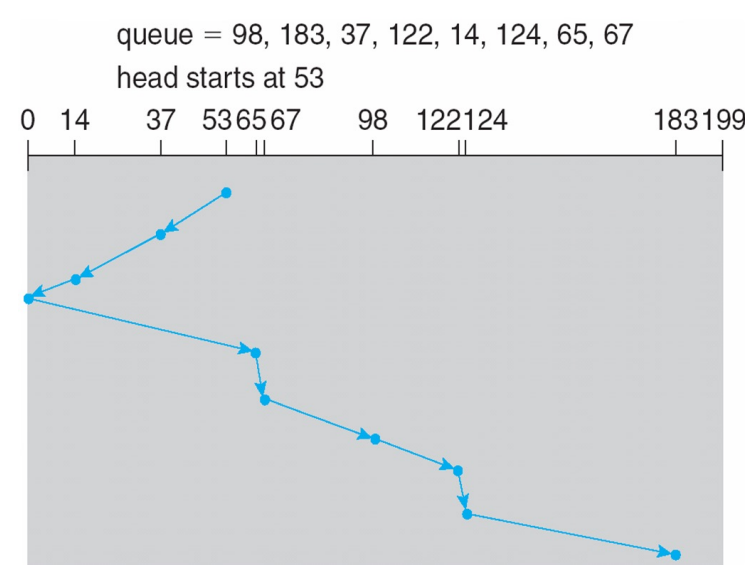
- SCAN: 엘레베이터처럼 한방향으로 끝까지 증가시키거나, 감소시키면서 읽음
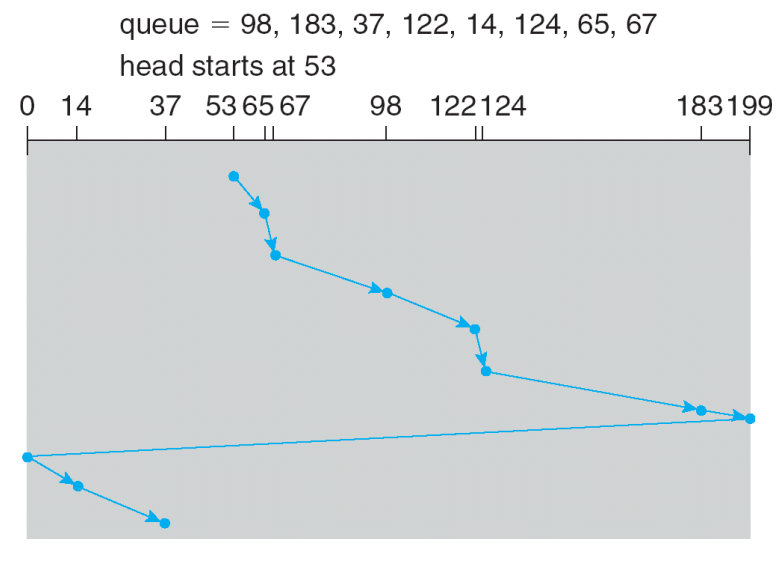
- C-SCAN: SCAN은 양방향이나, C-SCAN은 증가시키며 쭉 읽고 0으로 되돌아가 또 증가시키며 읽음
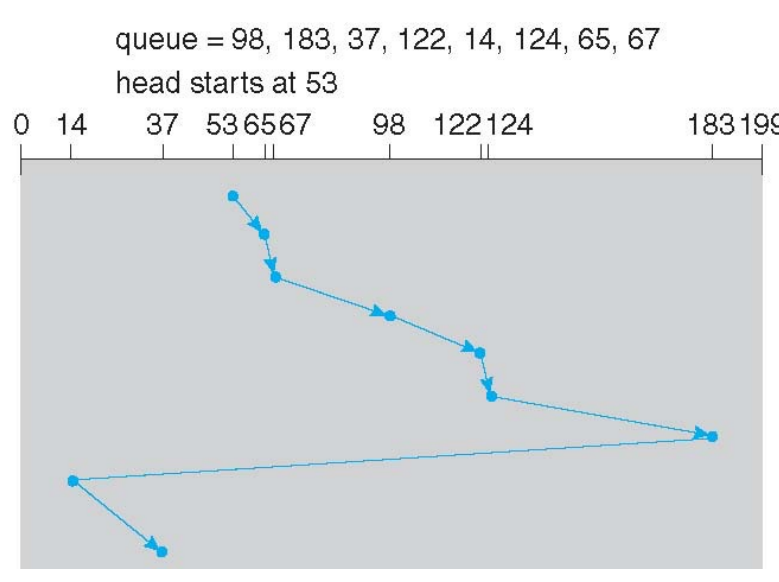
- C-LOOK: SCAN은 끝까지 읽지만, LOOK은 현재 Queue에 lT는 범위까지만 읽음
Disk Controller
- HDD의 내부동작(Platter, 헤드의 움직임 등)을 CPU가 관리하기엔 오버헤드가 너무 커서 대신 수행
- Read-ahead: spetia llocality 특성을 활용서 옆에 있는 데이터도 같이 읽음
- Caching: 자주 읽는 블록을 캐싱
- 하드웨어 문제 발생하면 다시 읽으라고 요청
- 디스크 손상으로 섹터가 고장나면 이 부분을 찾아서 쓰지 못하도록 remapping
Swap-Space Management
- VM에서 사용할 디스크의 공간을 관리해야함
- 윈도우는 빈파일을 만들어서 그 공간을 정의→ 공간을 늘리고 줄이기 용이하나 Protection은 잘 되지 않음
- 리눅스는 그 공간에 별도의 파티션을 분할
→ Protection, 접근 관점에서 좋으나 공간 관리가 어려움
RAID
목적
-
다수의 디스크를 하나의 디스크처럼 묶어 사용하는 기술
-
Reliability
-
Mirroring(Shadowing)
파일이 손상돼도 백업할 수 있도록 똑같은 데이터를 복제 -
Parity Code, Error-Correcting Code
손상이 일어나더라도 복구할 수 있는 코드
-
-
Performance
- Data Striping
- 데이터를 bit-elvel, block-level로 쪼개서 저장
- 실제로는 block-level striping을 사용
bit-level로 세세하게 나누면 locality 성질을 잃음 - 기존에 한 디스크에 저장했다면 arm seek time이 길어서 오래 걸리나, 여러 디스크에 나눠 저장하면 병렬적으로 찾을 수 있어서 성능 개선 가능
- Data Striping
RAID 0
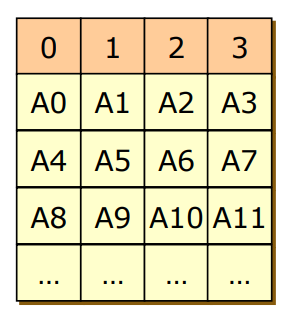
- Block Striping O, Mirroring X
- 하지만 하나의 디스크의 블록에 에러가 나면 모든 0~3번의 디스크들이 쓸모없게 됨
RAID 1
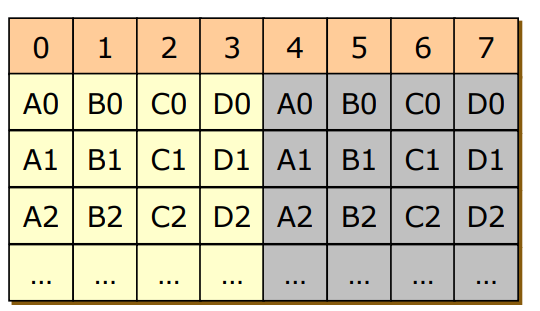
- Block Striping X, Mirroring O
- Reliability는 올라가지만 디스크 공간을 2배 줄어들고 돈도 2배나 소모
RAID 2
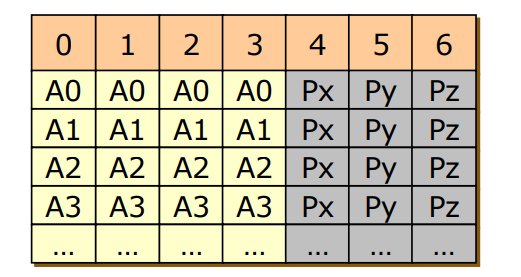
- Bit Striping + Error Correcting Code
- 블록을 비트단위로 더 쪼개어 여러 디스크에 분배해서 저장하고 ECC를 다른 디스크에 생성
- 거의 쓰지 않는 방식, 오로지 Reliability에만 전념한 기술
RAID 3
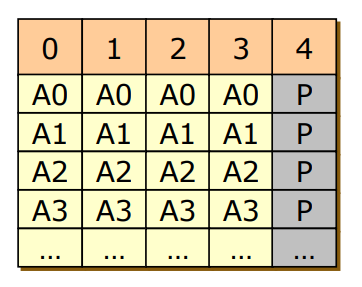
- Bit Striping + Parity Code
- 블록을 비트단위로 더 쪼개어 여러 디스크에 분배해서 저장하고 Parity Code를 다른 디스크에 생성
- Parity Code를 써서 ECC를 쓴 RAID 2보다 Reliability는 적어도 공간은 덜 사용
RAID 4
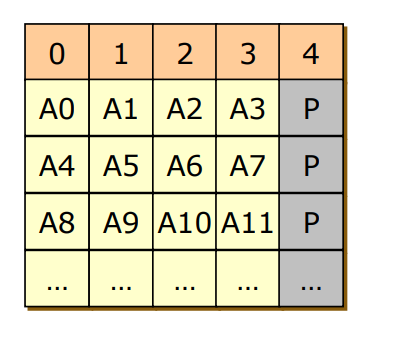
- Block striping + Parity Code
- Bit Striping은 너무 세세하게 쪼개서 별로이므로, 차라리 Block Striping을 하자
- 각 블록들을 여러 디스크에 분배해서 저장하고 ECC를 다른 디스크에 생성
- A0, A9, A2, A7를 수정하면 마지막 4번 디스크를 3번 수정해야해서 성능 저하
RAID 5
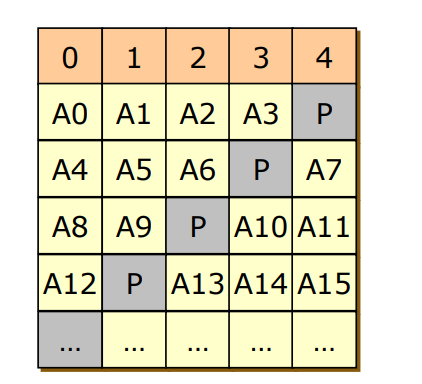
- RAID 4 + Parity의 위치를 조정
- RAID 4의 Parity 블록은 혼자 오버헤드를 많이 받음
- Parity 블록을 분산시킴으로써 과부화를 분배
RAID 6
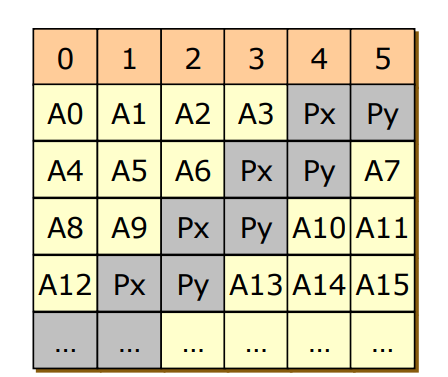
- RAID5 + Pairty Code를 Error Correcting Code와 섞음
- Parity Code만으로는 Reliability가 떨어지므로 ECC와 혼합
RAID 0+1
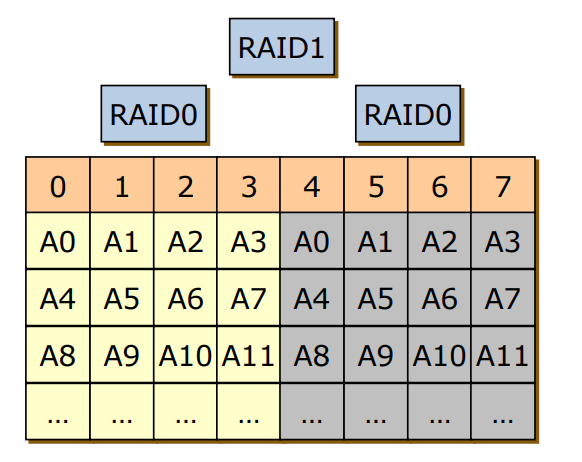
- RAID 0인 Striping을 먼저하고 RAID 1인 Mirroring을 함
- Striping을 통해 Performance를 챙기고 Mirroirng으로 Relability를 챙김
- 1번 디스크의 A5가 고장나면 0~3번 디스크 모두 쓸모없게 되는 문제 발생
RAID 10
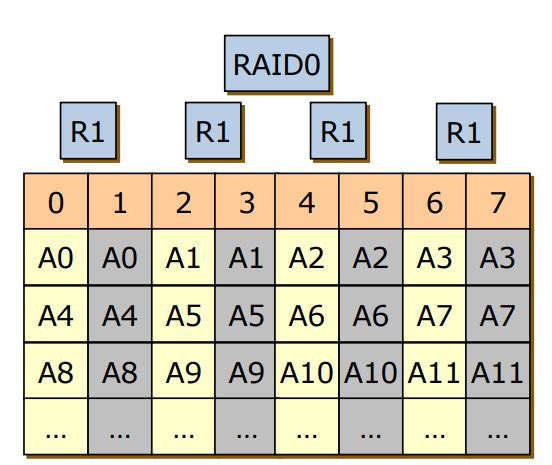
- RAID 0+1의 순서를 바꿧기에 성능면에선 RAID 0+1와 유사하나 Reliability는 더 좋음
- 기존의 RAID 0+1은 4개의 디스크를 손상입지만,
RAID 10은 2번 디스크의 A5가 고장나면 2번 디스크만 쓸모없어짐
