오늘 학습 내용
1. Transformer
1. Transformer
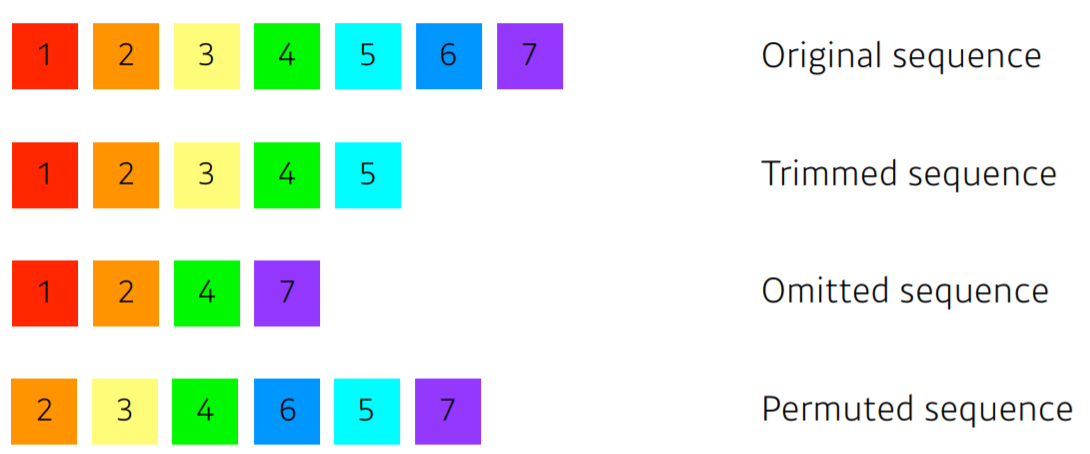
- Sequential Data는 아래와 같이 순서의 변형에 취약해 학습시키기 어렵다.
Basic Structure
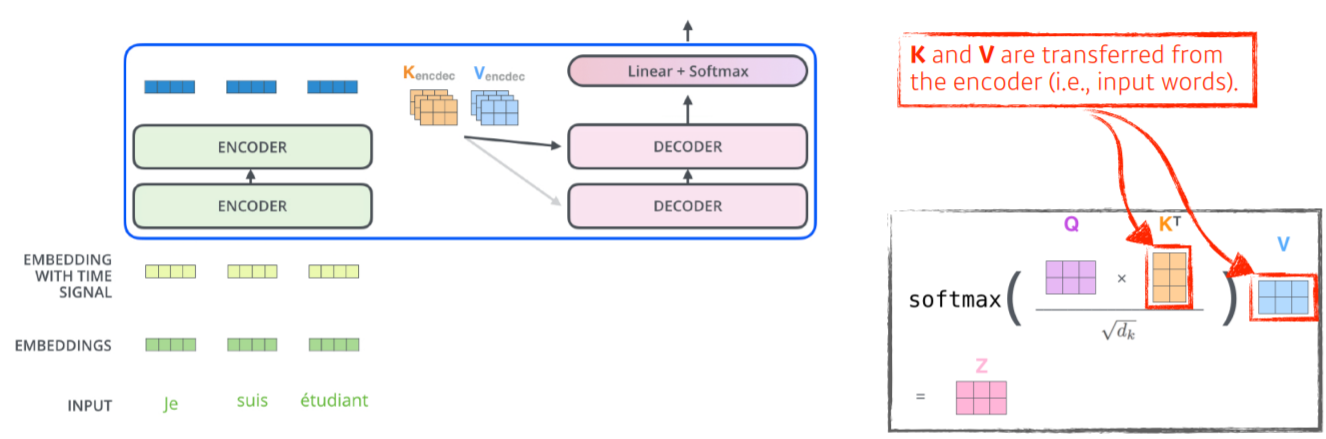
Transformer 는 Sequence Data to Sequence Data 의 구조이며, NLP 분야뿐만이 아닌 여러 분야에서 사용이 가능하다.
Input 과 Output Data의 Size와 Domain은 서로 다를 수 있다.
Encoder 단에서 Input Data를 동시에 처리하며, 각각의 Encoder와 Decoder는 서로 Parameter를 공유하지 않는 독립적인 층이다.
Encoder
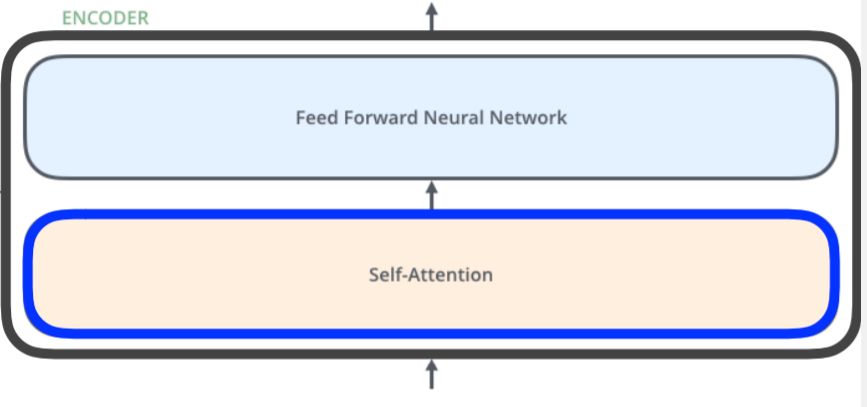
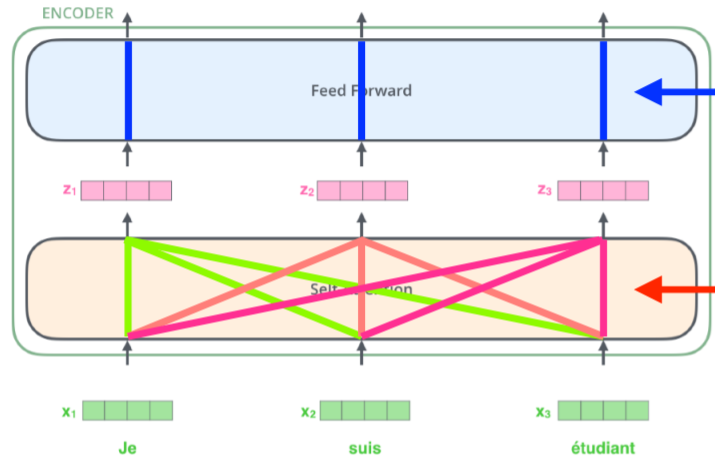
- Encoder는 Self-Attention과 Feed Forward Nenural Network의 Stack으로 이루어져 있으며, Feed Forward Nenural Network는 MLP의 구조와 동일하다.
- Word Embedding 이란 어떠한 단어들을 컴퓨터가 연산을 할 수 있게 벡터화하는 것이다.
- 단순 빈도 나열
- CBOW (Word2Vec)
- Skip-Gram (Word2Vec)
- Self-Attention layer 는 하나의 단어에대한 Output을 출력 할 때, 나머지 단어들을 고려하여 출력하며, 이후 Feed-Forward Layer에서 각각의 Output이 독립적으로 처리된다.
Self-Attention Layer의 진행과정
1. 각각의 단어를 Embedding 기법을 통해 벡터화(vectorization) 한다.
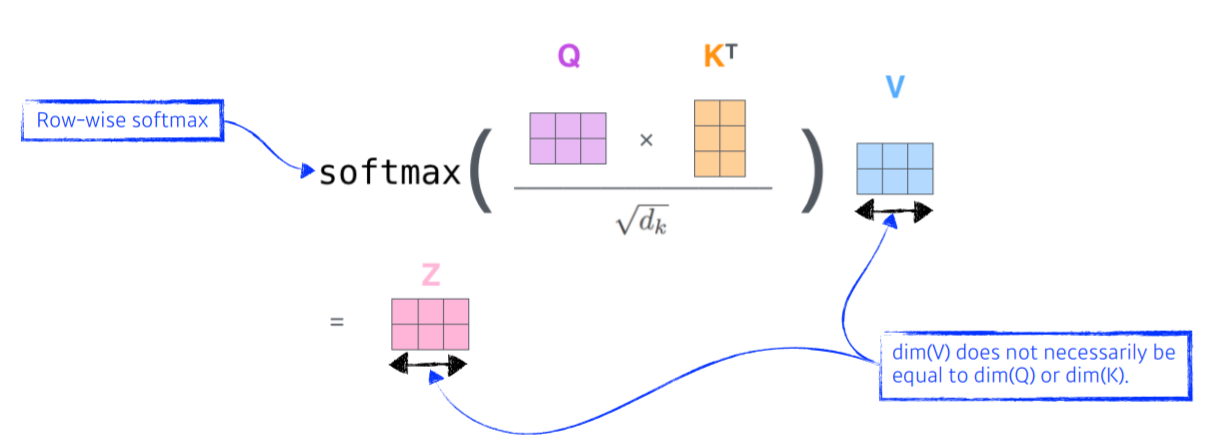
2. 각 단어에 대한 Queries, Keys, Values 벡터를 계산한다.
3. 한 단어의 Query 벡터와 나머지 모든 단어들의 Key 벡터를 Inner Prodcut(내적)하며, 이 값을 Score라 한다.
4. Score를 Key Vector의 Dimension의 제곱근으로 나누어준다. (Normalization)
5. (4)의 값들을 Softmax 함수에 적용시키며, 이 값은 Attention Weight 가 된다.
6. Attention Weight 들을 해당 단어의 Value Vector와 Multiply 해주고, 최종적으로 모든 값을 합하여 representation을 구한다.
Query와 Key의 차원은 내적을 하기위해 같아야 하지만, Value Vector의 경우 달라도 상관 없다.
Array를 이용한 Self-Attention Layer
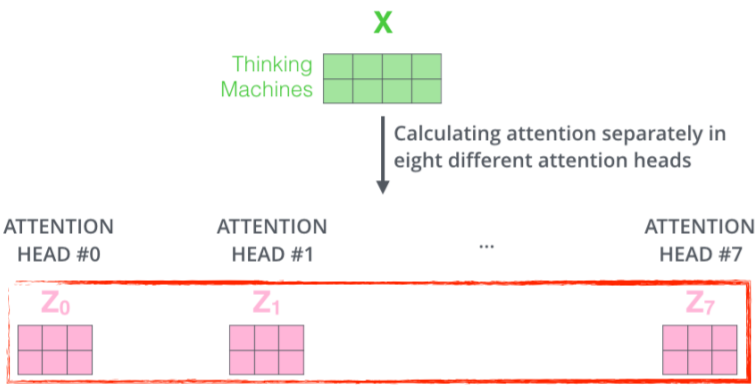
Multi-Headed Attention(MHA)
- Head의 수 만큼 한 단어에 대해 각각의 Query,Key,Value Vector를 적용하여, Attention Weight를 계산한다.
- 각 Attention Weight를 Concatenate한 뒤, Matrix Multiply 연산을 이용하여 Reshape 한다.
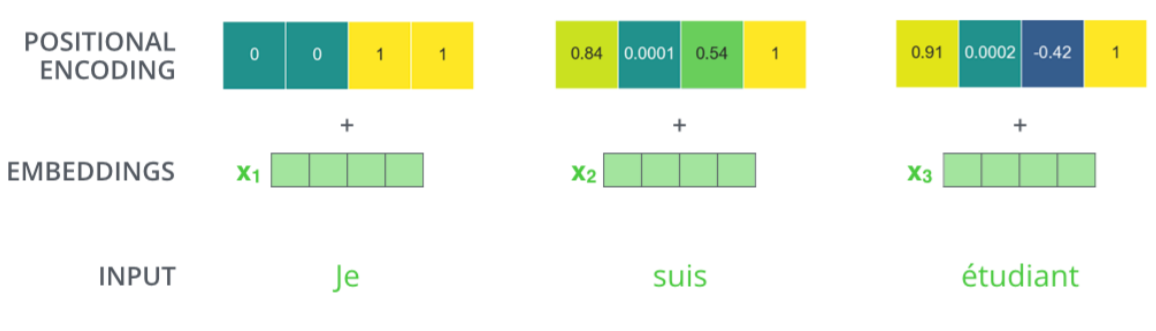
Positional Encoding
- 어순은 언어를 이해하는데 있어 중요한 역할을 하기에 이에 따른 정보 처리가 필요하다.
- 기존 정의 되어있는 값을 사용하여 Embedding 된 Vector에 더해준다.

Decoder
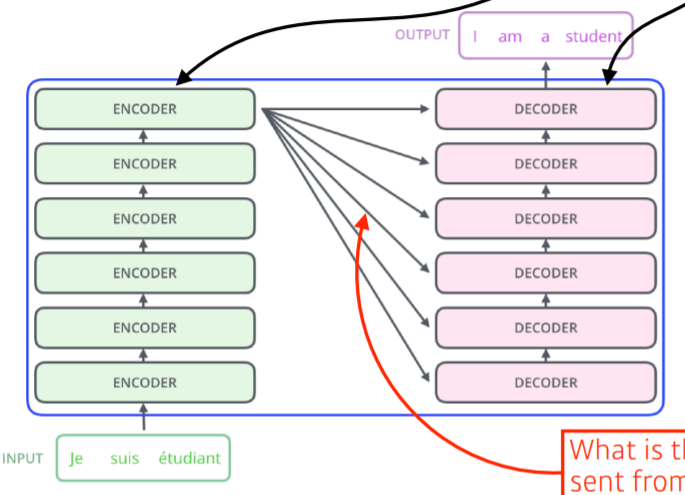
Encoder는 Query Vector에 따른 Key Vector와 Value Vector 정보를 Decoder로 넘긴다.
Decoder의 Output은 Autoregressive 방법으로 Generate 된다.
이전 단어들에만 Dependent 하게하고 미래 즉, 뒤에 나오는 단어들에 대해서는 Independent 하기위해 Masking 기법을 사용한다.