오늘 학습 내용
1. AutoEncoder
2. Variational AutoEncoder
1. AutoEncoder
- AutoEncoder 는 입력을 낮은 차원의 Latent Vector(잠재벡터)로 변환시킨 뒤 원래 차원으로 복원 시키는 과정을 반복 함으로써 학습하는 방법을 뜻한다.
- 이렇게 하여 학습된 Encoder는 Input Data로 부터 특정한 Feature를 추출 할 수 있다.
- Decoder는 주어진 Latent Vector를 원본 데이터와 비슷한 데이터로 복원한다.
- Label이 주어지지 않는 Unsupervised Learning 이며, Decoder의 Output 과 Input Data의 차이를 Loss 로 활용한다.
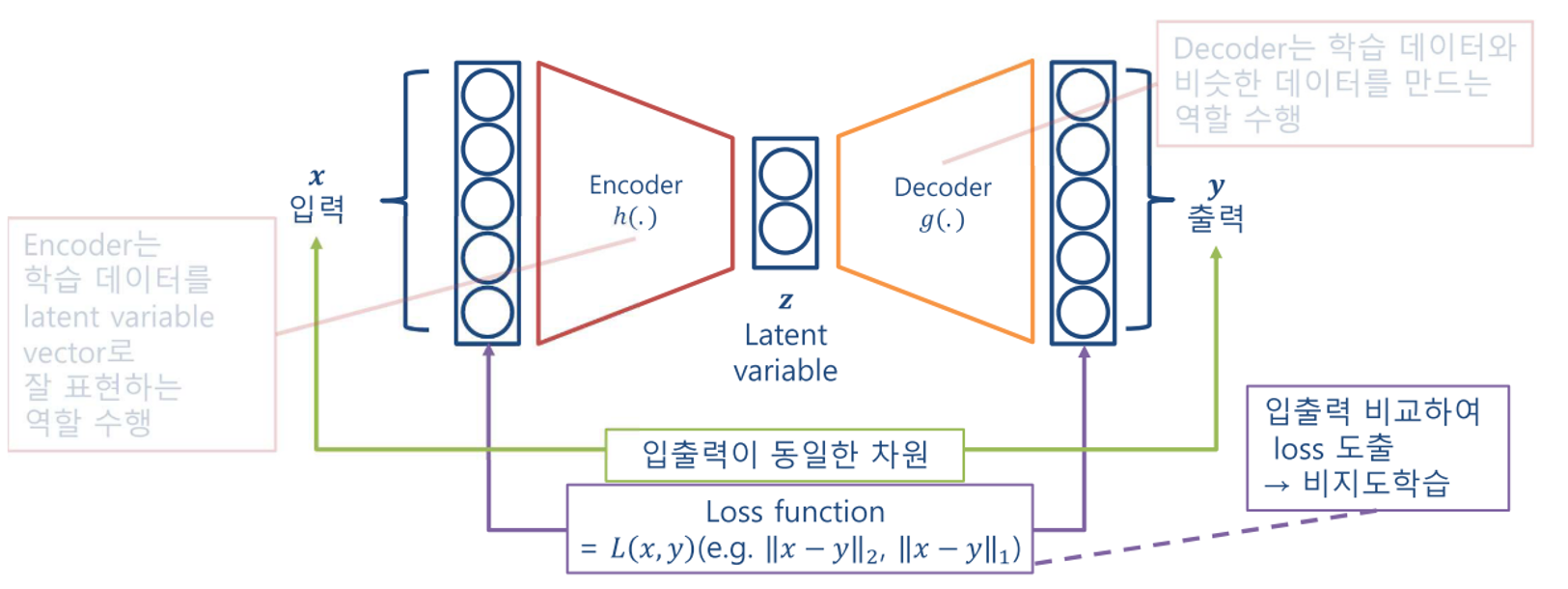
- Latent Vector에는 아래와 같은 특정 Feature 정보들이 저장된다.
- Train Step에서 겉으로 보이지는 않으므로, 잠재(Latent) Vector라고 불리운다.

따라서, AutoEncoder에서 Encoder는 Latent Vector를 생성하고 Decoder는 Latent Vector로 부터 생성한다고 볼 수 있다.
(Generative Model은 아님!)
2. Variational AutoEncoder
- Variational AutoEncoder는 AE와 구조만 동일 할 뿐 다른 개념을 다룬다.
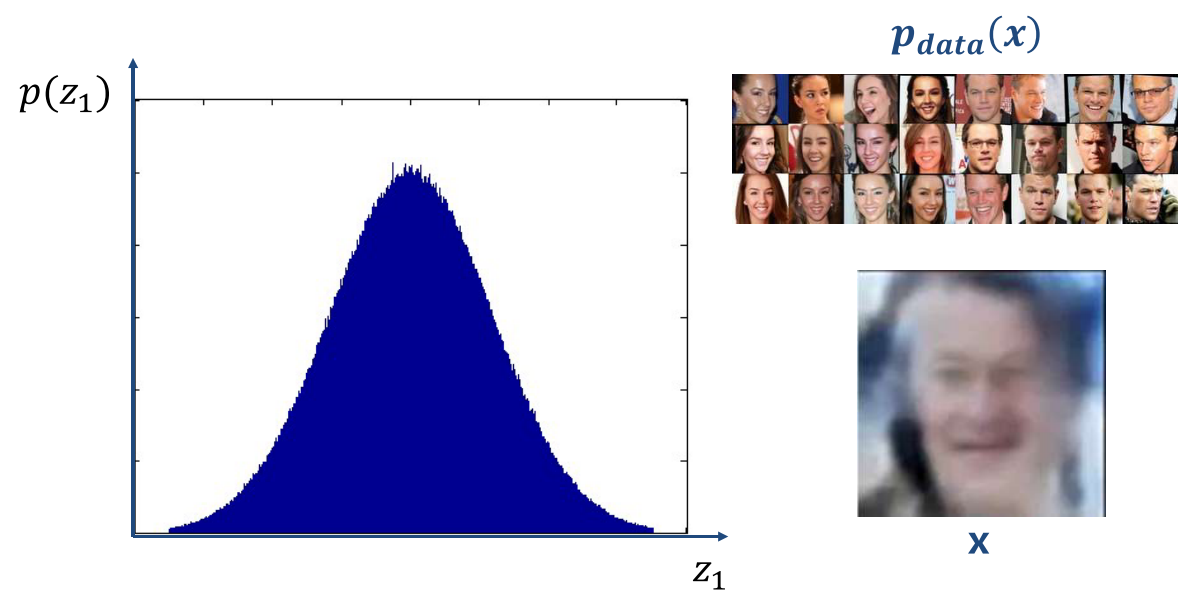
2-D Random Noise 이미지에서의 Sampling
왼쪽 상단의 Noise Image를 Input으로 하여금 오른쪽 여성 사진과 같은 이미지를 만들어 낼수 있는가?
→ 사실상 불가능 하다.height X width X 3(channel) 수 만큼의 픽셀 하나 당 0~255의 값을 가짐.
과 같다.하지만, 확률 분포를 이용하여 하나의 데이터를 Sampling 한다면?
위의 그림에서 라는 데이터셋이 존재하고, 이 데이터셋에서 왼쪽과 같은 분포를 만들어 냈다고 해보자. 이때, 만약 아까의 Ranom Noise Image가 이러한 분포를 따른다고 생각하면, 오른쪽 그림 X와 같은 흐릿하지만 상당히 유사한 이미지를 출력할 수 있다. 이때, 해당 분포는 AE에서 동일하게 다루었던 Latent Variable Distribution 이다.

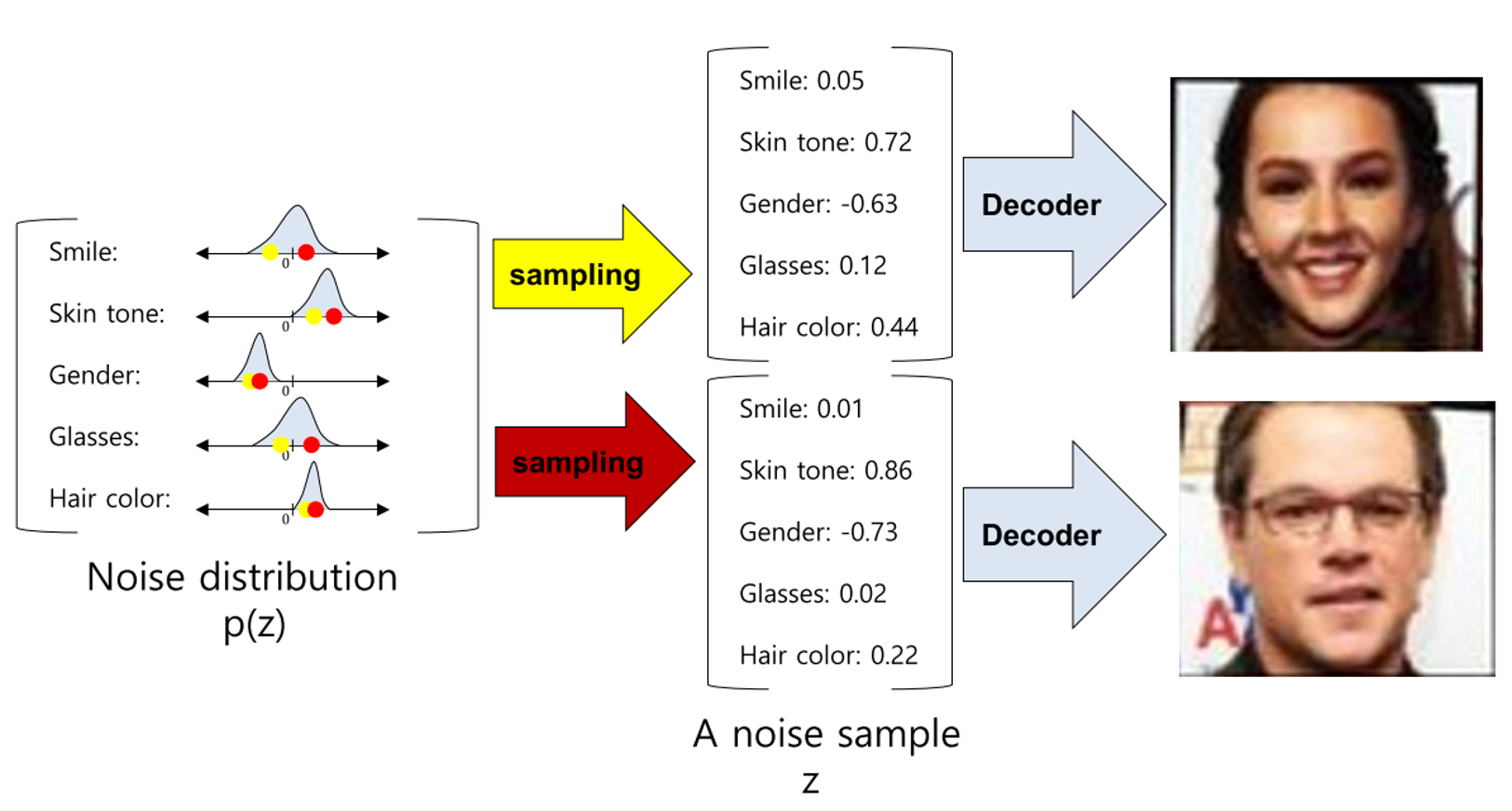
AutoEncode와의 정확한 차이는 무엇인가?
AutoEncoder에서는 Input Data를 저차원으로 변환하는 과정 (Encoder)을 통해 Latent Vector를 추출하고, 이를 다시 복원 (Decoder)시켰다.
하지만, VAE 에서는 어떠한 Latent Variable의 Distribution이 주어졌을 때, 이를 이용하여 해당 분포를 따르는 Sample을 만들어 내는 것이다. (Decoder)
Latent Vector와 Latent Vector의 Distribution 이라는 차이점도 있지만, AE는 Feature Extract을 담당하는 Encoder가 핵심이지만, VAE는 Sample을 Generate하는 Decoder가 핵심이다.
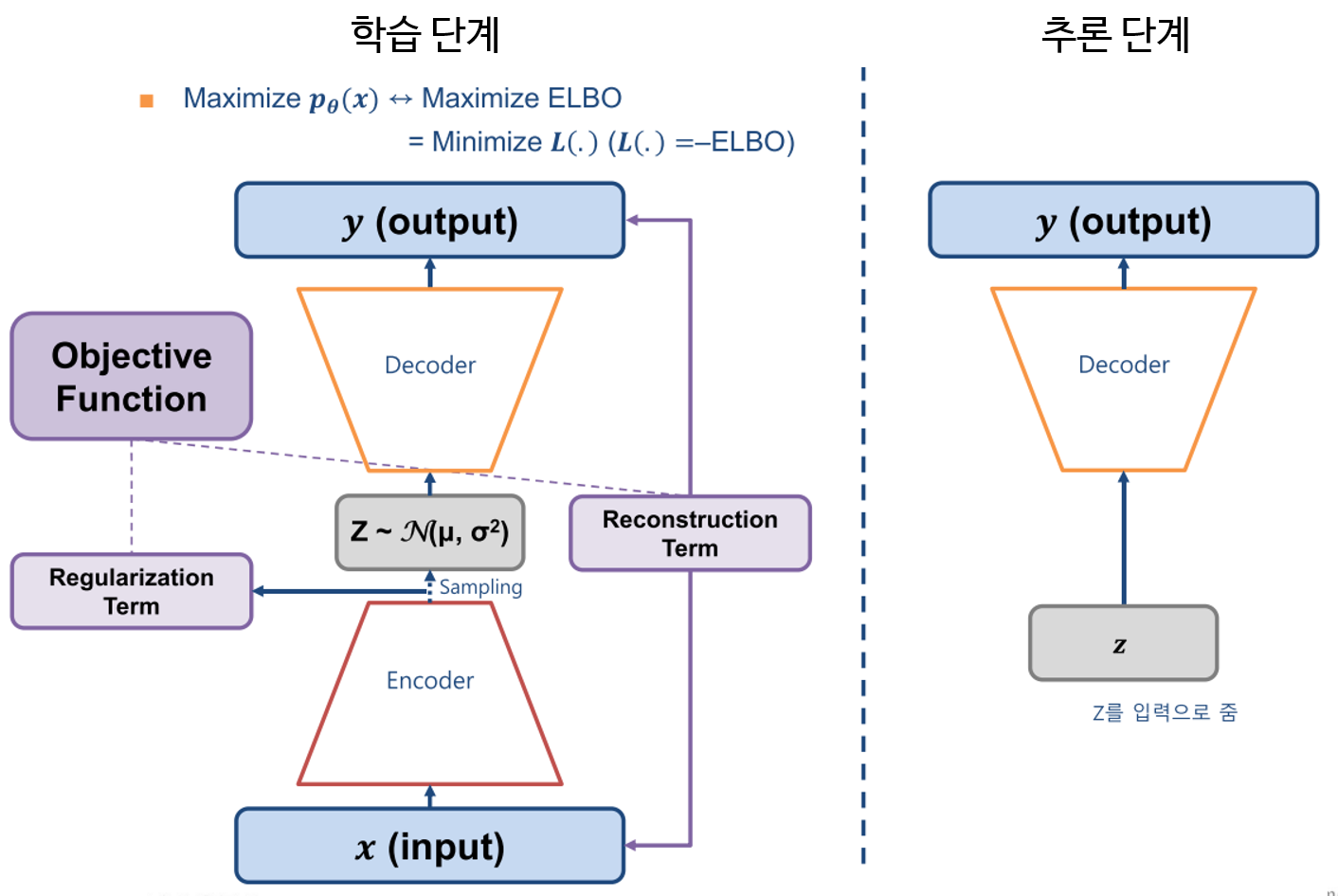
따라서, 실제 Inference 시에도 VAE는 Input으로 Latent Distribution을 주고, Decoder를 이용하여 출력만 시킨다.
참고 및 이미지 출처 : https://gaussian37.github.io/dl-concept-vae/
