오늘 학습 내용
1. VIT (Vision Transformer)
1. VIT (Vision Transformer)
- NLP 분야에 있어서 새로운 기준이 되어왔던 Transformer의 Self-Attention을 CV에 적용시키려는 시도에서 시작되었다.
- 구글에서 발표한 VIT (Vision Transformer) 는 CNN 구조를 전혀 사용하지 않고, Self-Attention 구조를 통해서만 SOTA 모델급 지표를 보였다.
- 기존 SOTA 모델과 비교하여 Cost가 약 1/15 수준으로 감소하였다.
Image를 어떻게 Transformer에 넣어서 다룰 것인가?
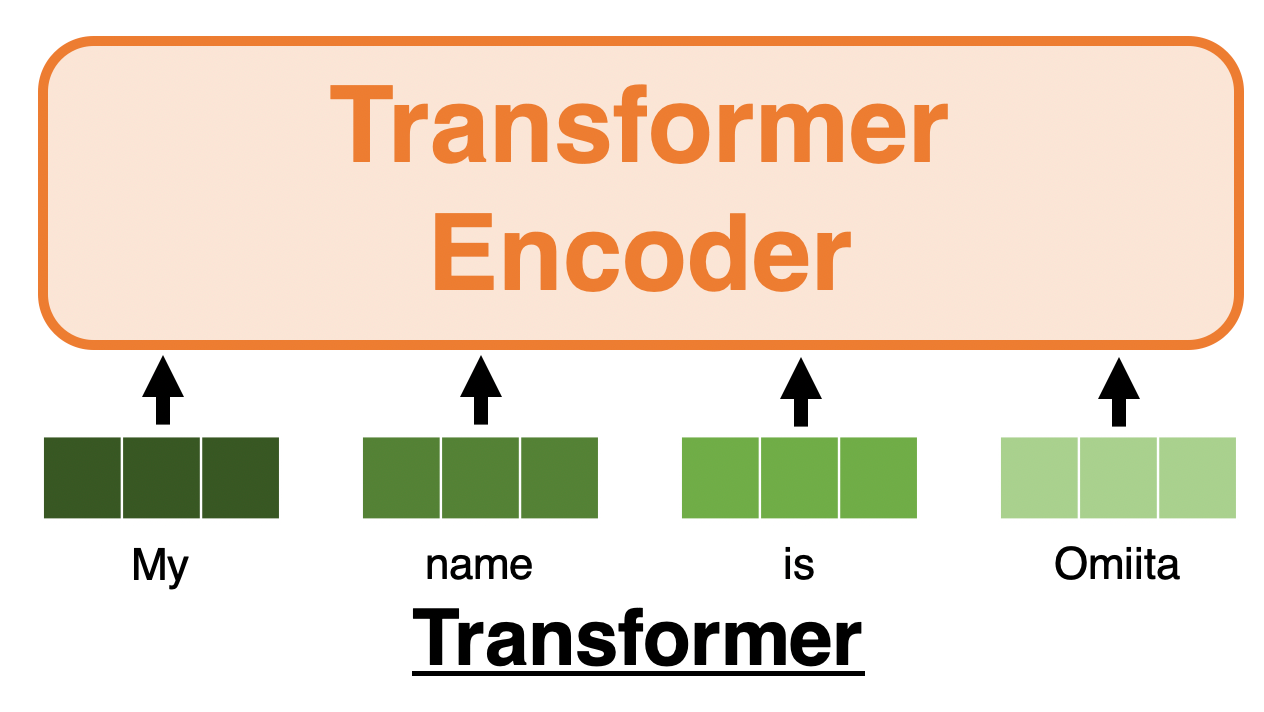
기존 Transformer 의 입력은 아래와 같이 여러 단어들의 벡터들의 나열이었다.
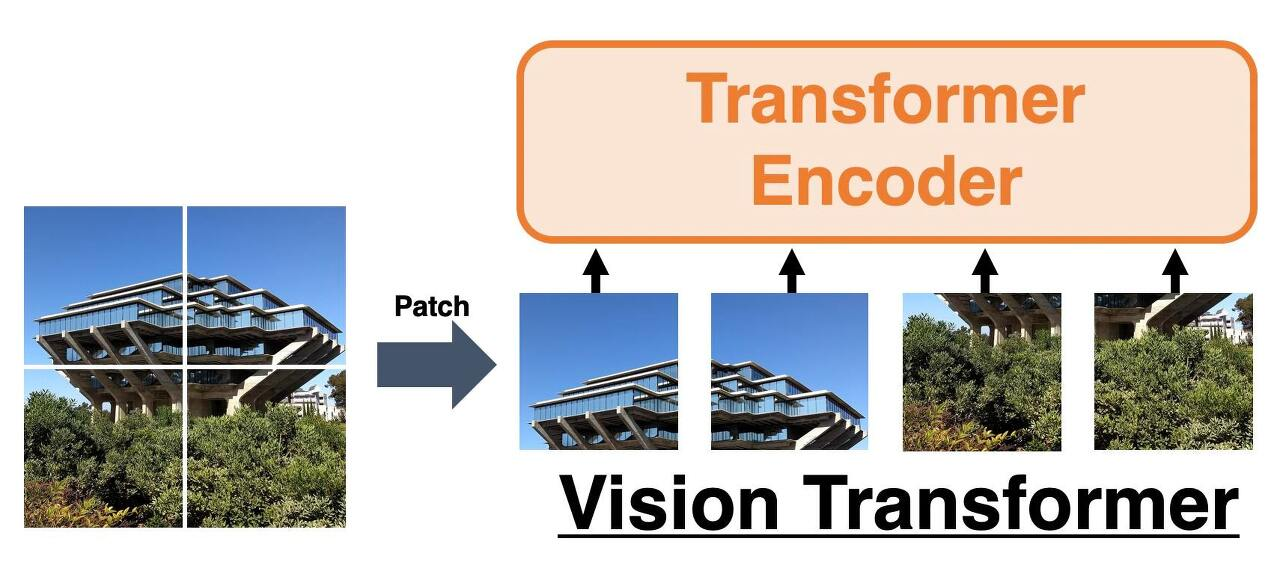
Image 데이터에 있어서 위와 같이 여러 벡터들의 나열로 표현을 하기 위해서는, Image를 동일한 Size의 Patch 라는 단위로 나누는 것이다.
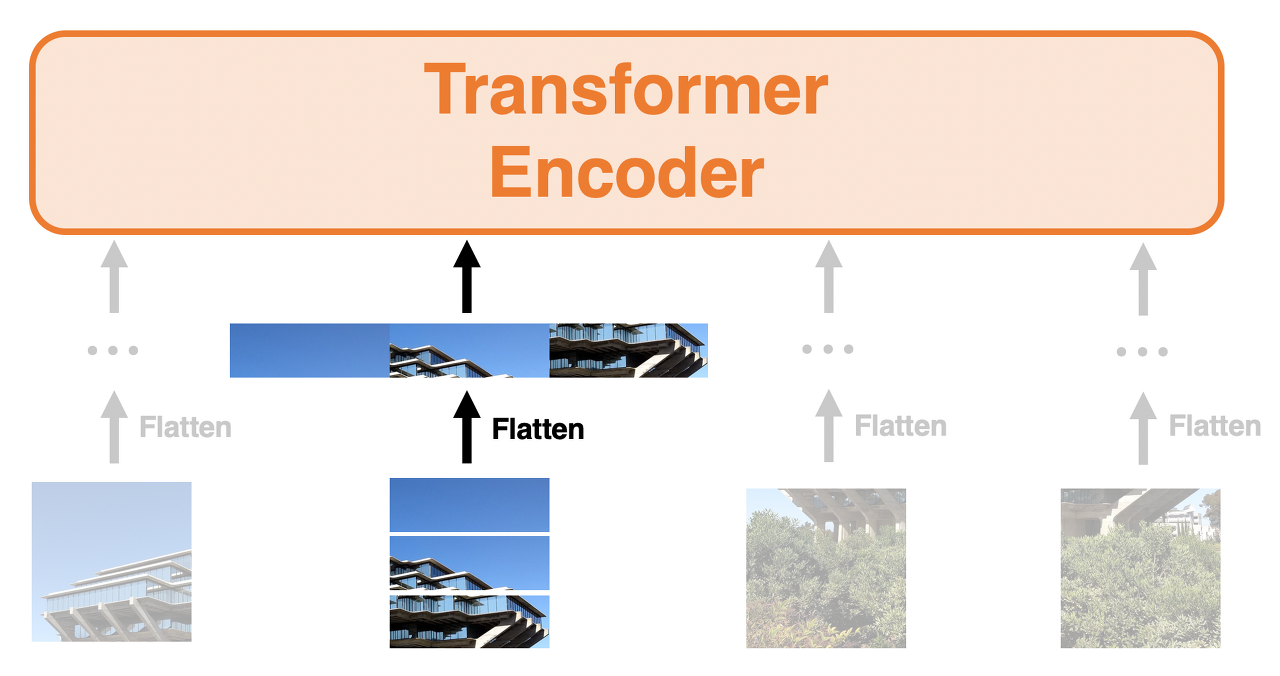
위 그림의 각 패치된 부분의 값들을 Flatten 시킨다면, 기존 Transformer의 Input Data와 유사해진다.
식1. 은 원래의 이미지의 차원수를 의미한다. H는 이미지의 Height, W는 이미지의 Weight, C는 이미지의 Channel이다.
식2. 는 식1. 에서 패치수를 반영 한 것으로, N은 패치의 수, P는 각 패치의 Size를 뜻한다.따라서, 만약 Iamge Size가 224 x 224일 때를 가정하고 각 패치의 Size가 16 x 16 (P=16)이라면, 이므로 N= 196 즉, 즉 패치의 개수는 196개가 될 것 이다.
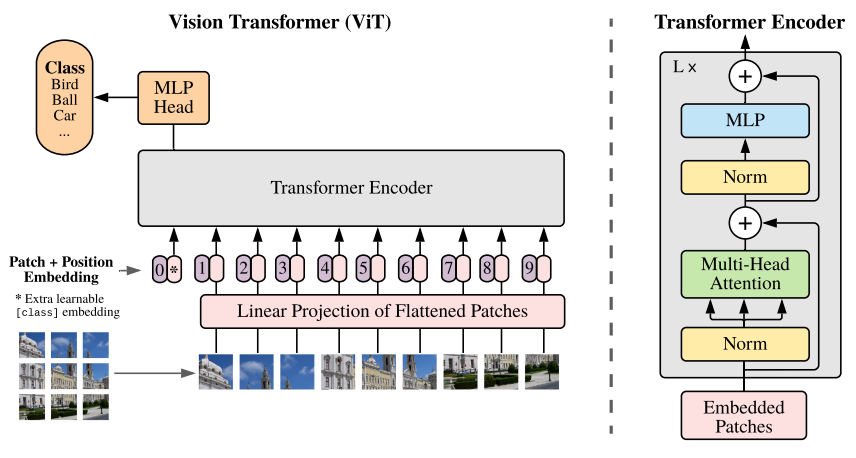
VIT Architecture
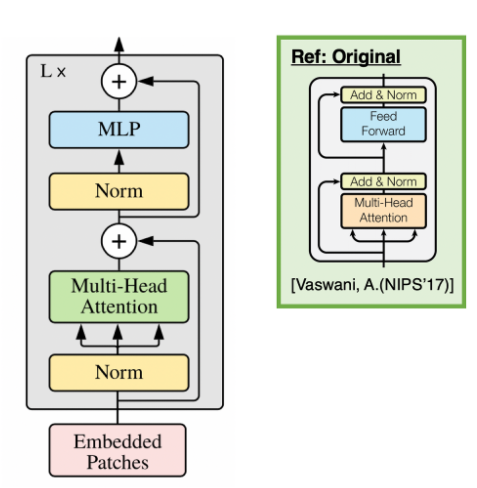
아래의 그림의 왼쪽은 VIT의 Encoder 구조 오른쪽은 기존 Transformer의 Encodder 구조이다.
VIT의 맨 아래부분을 보면 Embedded Patches 를 Input으로 삽입하는 것을 볼 수 있다.
Embedded Patches는 어떻게 구성되어있는지 알아보자.
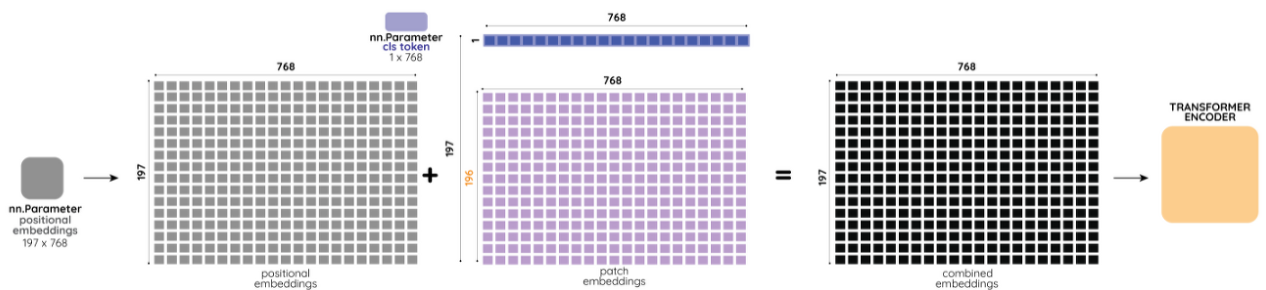
기본적으로 image를 N개의 패치로 나눈뒤 Flatten한 값들이 여기에 해당 될 것이고, 이외에도 2개의 값이 더 존재한다.하나는 기존 Transformer 에서도 사용되었던 Positinal Encoding 값으로, VIT에서도 마찬가지로 각 Input의 값들에 대한 위치 정보가 존재하지 않음으로, Positional Embedding 값들을 더해준다.
나머지 하나는 Class Token 으로 각 시퀀스의 맨 앞에 학습이 가능한 파라미터를 붙여준다. Class Token은 Bert의 Class Token과 동일한 개념으로, 추후 최종 Layer에서 Classification을 위한 전체이미지를 resentation 하는 값이다.
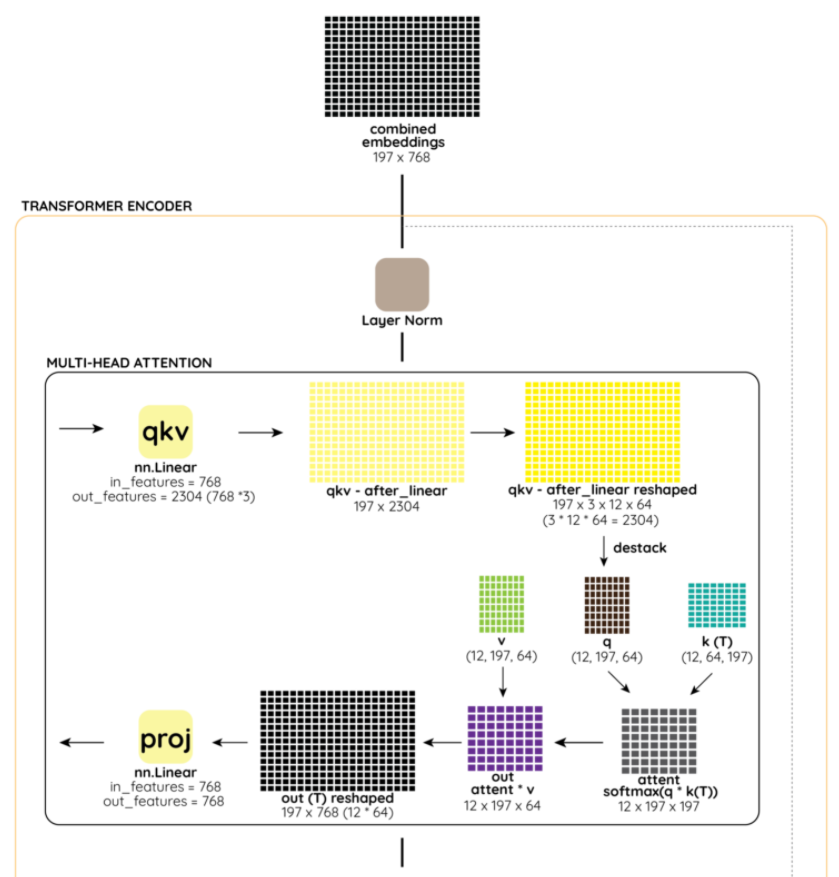
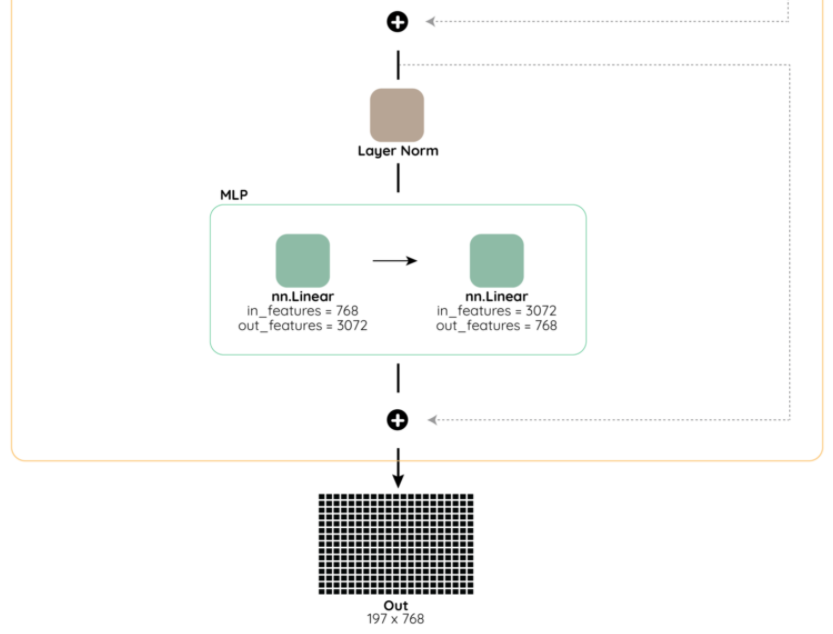
또한, 이렇게 구해진 Embedded Pathces의 값들이 MHA(Multi-Head Attention) Layer로 들어가기전 Normalization을 거치는 것을 볼 수 있는데, 여기서의 Normalization은 Batch Normalization이 아닌 Layer Normalization을 뜻한다. 해당 내용에 대한 자세한 내용은 다음 블로그를 참고하면 쉽게 이해가 갈 것이다. (https://m.blog.naver.com/sogangori/221035995877)아래는 VIT Encoder 의 전체적인 학습 순서에 따른 그림이다.

참고:
