오늘 학습 내용
1. Image Classification
2. CNN Architectures
3. Annotation data efficient learning
1. Image Classification
-
Classifier 는 Image를 하나의 Category 로 Mapping 하는 f() 역할이다.
-
데이터가 존재한다면, 모든 Classificaiton 문제는 K-NN 으로 해결가능하다.
→ But, real world의 모든 데이터 저장은 불가능 ! -
Single Fully Connected layer network 는 Classification 문제 해결에 부적합하다.

-
Locally Connected CNN 은 Classification 문제 해결에 적합하다.
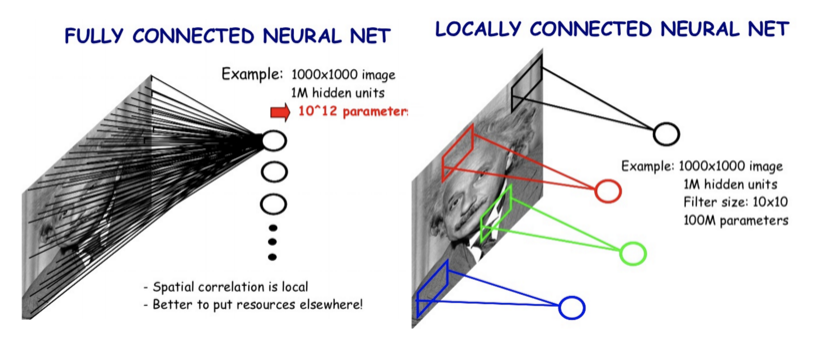 ( 출처: https://legacy.gitbook.com/@leonardoaraujosantos )
( 출처: https://legacy.gitbook.com/@leonardoaraujosantos )
-
CNN 은 CV 분야의 다양한 Task 에 있어 Feature Map 을 추출하는 BackBone으로 활용 된다.
-
Receptive Field 는 Input Space 상에서 특정 CNN Feature 이 도출되는 Field 이다.
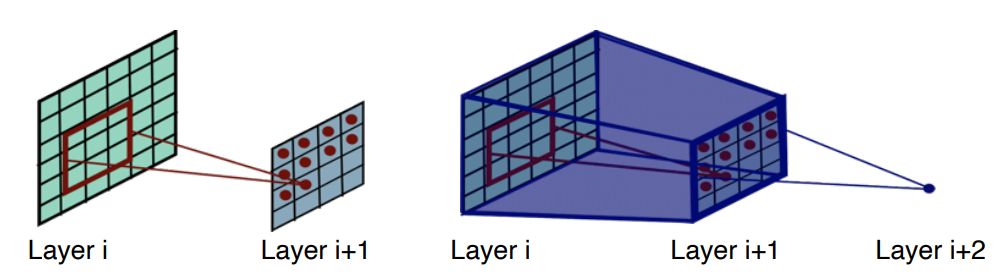
-
Layer 가 깊을수록 일반적으로 성능이 향상된다.
→ Large Receptive Fields, More Capacity, Non-linearity -
Layer 가 깊을수록 Optimization 이 어렵다.
→ Not Overfitting,
But, Gradient Vanishing/Exploding , Computaionally Complex
2. CNN Architectures
Alexnet
- LeNet-5 을 기반으로 하였으며, LeNet-5 에 비해 더 많은 Layer 를 가진다.
- ImageNet 을 이용하여 학습 시켰다.
- Actavation Function 으로 ReLu 를 사용하였으며, dropout 기법을 적용하였다.
- 당시 GPU 의 성능 문제 때문에, 2 Level 로 나누어 Parallel 하게 학습시켰다.
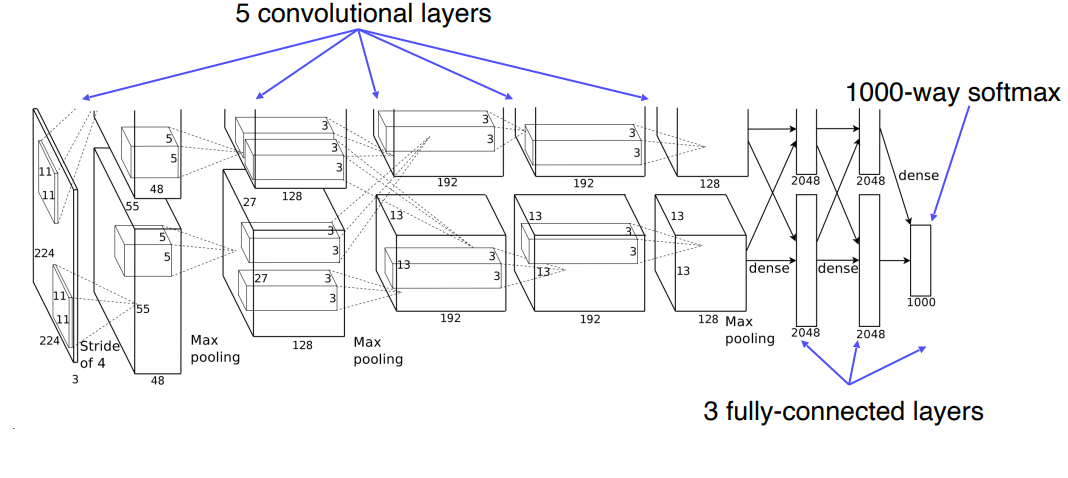
VGGNet
- Layer 를 Deep 하게 쌓음으로써, 성능 향상을 이루어 냈다.
- Large Size Filter 대신 3x3 CNN Filter 의 사용으로, Receptive Field Size 를 크게 하고, 더욱 작은 파라미터 수를 유지할 수 있게 하였다.
AlexNet VS VGGNet
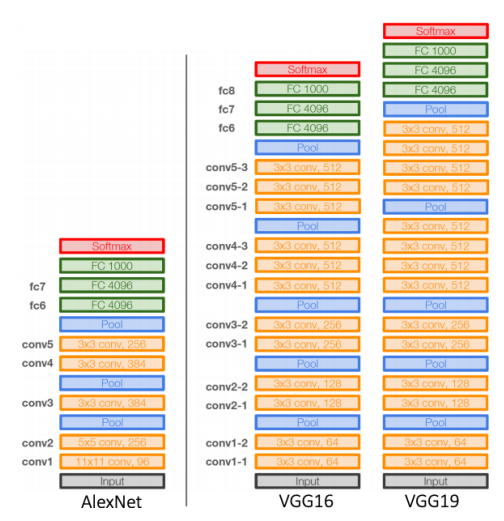
GoogLeNet
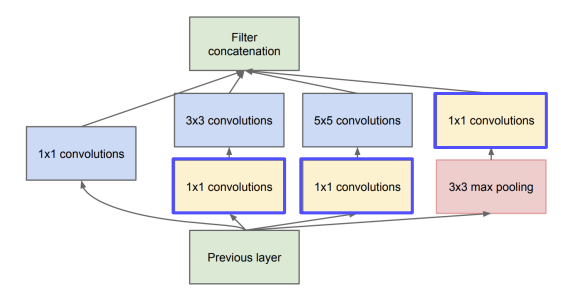
Inception Module
- GoogLeNet 의 Key Design 요소이다.
- 1x1, 3x3, 5x5 CNN 연산과 3x3 pooling 연산을 Concatenate 한다.
- 1x1 CNN 연산을 통해, 연산량을 줄인다.
- 이러한 Inception Module 의 Stack 으로 설계된 모델이 GoogLeNet 이다.
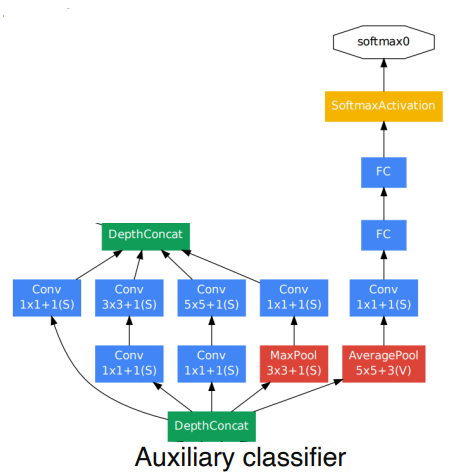
Auxilary Classifiers
Layer 가 깊어지면서, Backpropagation 시 Gradient Vanishing 문제가 발생한다.
이를 방지하기 위해, Layer 중간에 Addigional Gradients 를 넣어준다.
Training Step 에서만 사용되며, Test Time 에는 사용되지 않는다.
ResNet
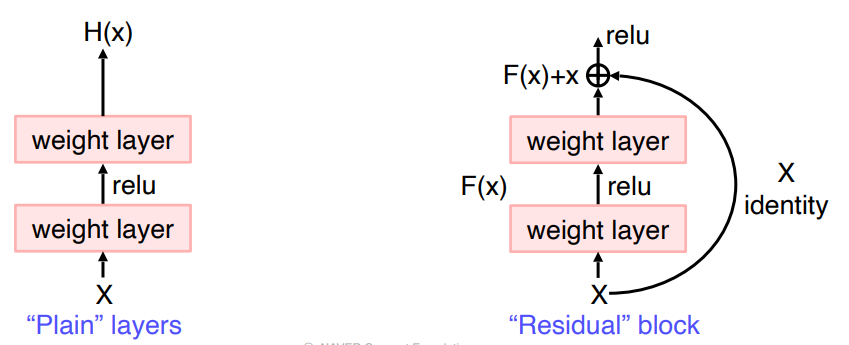
- Layer를 아주 깊게 쌓음으로써, 성능 향상을 이루어냈다.
- 이로인한 Optimization, Gradient Vanishing 문제 등을 Skip-Connection 으로 해결하였다.
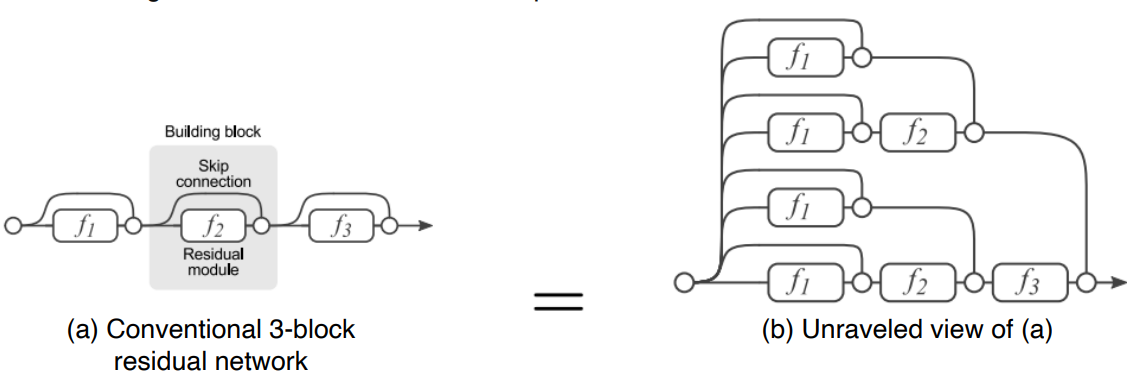
- Skip-Connection 으로 인해, Backpropagation 시 여러개의 Path 가 존재한다.
Skip-Connection
Path
Beyond ResNet
1. DenseNet
2. SENet
3. EfficientNet
3. Annotation data efficient learning
Augmentation
-
Dataset 은 항상 Biased 하다.
-
Training Dataset 은 Real Data 의 sparse sample 이다.
-
따라서, Training Dataset 과 Real Data 는 항상 gap이 존재한다.
-
Augmentatiopn 은 real data 와의 gap을 어느정도 채울 수 있다.
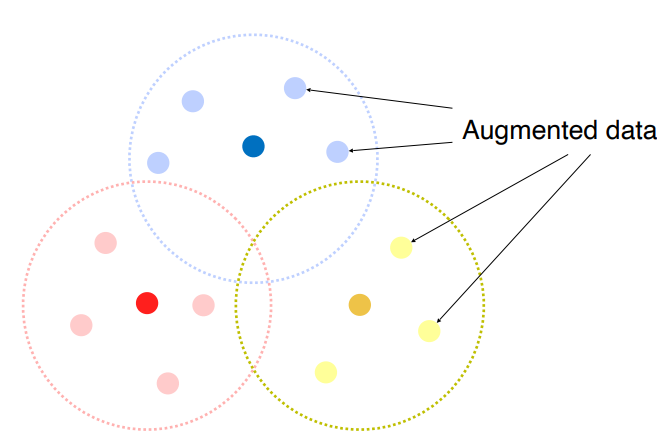
-
Rotate, Flip, Brightness Adjustment, Crop 등 여러가지 기법이 존재한다.
-
Affine Transformation 은 특정 좌표를 다른 좌표로 매핑시키는 기법 이다.
-
CutMix 는 두 Image를 자르고 Concatenate 한 뒤, Soft Label을 취하는 방법이다.
-
RandAugment 는 다양한 Augmentation 기법의 최적의 조합을 찾아준다.
Transfer Learning
-
Transfer Learning 은 Pre-trained knowledge 를 기반으로, 새로운 task에 적용시키는 것이다.
-
Knowledge Distillation
- Teacher Model 에서 Student Model을 학습시키는 방법이다.
- Pseudo-labeling 기법을 사용한다.
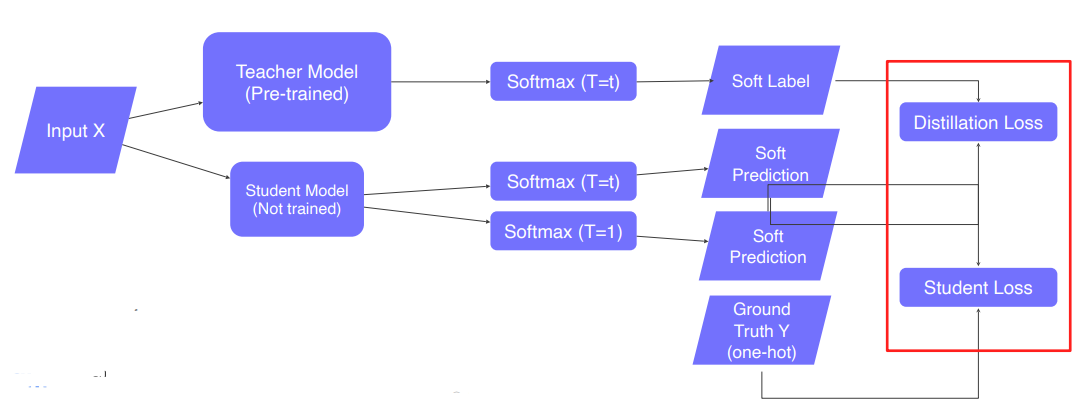
- Teacher Model 로 Input X를 Prediction 한다. (Soft Label)
-
Student Model 로 Input X를 Prediction 한다. (Soft Prediction)
-
Teacher Model 의 Output 과 Student Model 의 Output의 차이를 Distillation Loss 로 정의하며, KLdiv Loss 를 이용한다.
-
Student Model 의 Output 과 실제 Label 값이 차이를 Student Loss 로 정의하며, Cross Entropy Loss를 이용한다.
- Self-training
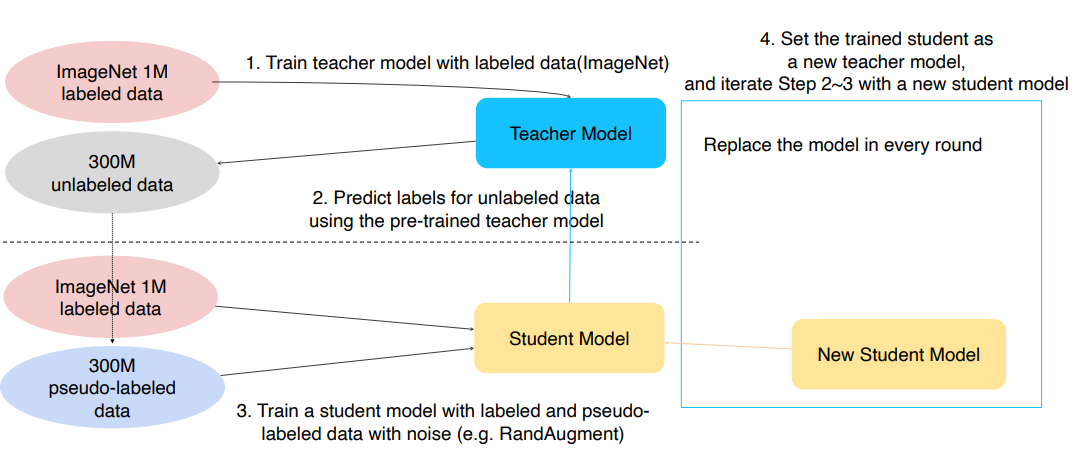
- Teacher Model 을 Labeled data 로 학습시킨다.
- 학습된 Teacher Model 로 Unlabled data 를 Predict 한다. (Pseudo-labeling)
- Pseudo-labeling Data와 Labeled Data로 Student Model을 학습시킨다. (With Augmentation)
- 학습된 Student Model을 새로운 Teacher Model 로 설정한다.
- 위의 과정을 2~3회 반복한다.
- Teacher Model 을 Labeled data 로 학습시킨다.
