오늘 학습 내용
1. Two-Stage Detector (R-CNN Family)
2. Single-Stage Detector
1.Two-Stage Detector (R-CNN Family)
Selective Search
Selective Search 알고리즘은 Segmentation 분야에 주로 사용 되는 알고리즘이다.
Over-Segmentation 을 통해 Random 한 bounding box 들을 생성하고, 객체와 주변간의 색감(Color), 질감(Texture) 등의 차이를 통해 조금씩 이들을 Merge 함으로써 Object의 bounding box를 찾아나간다.
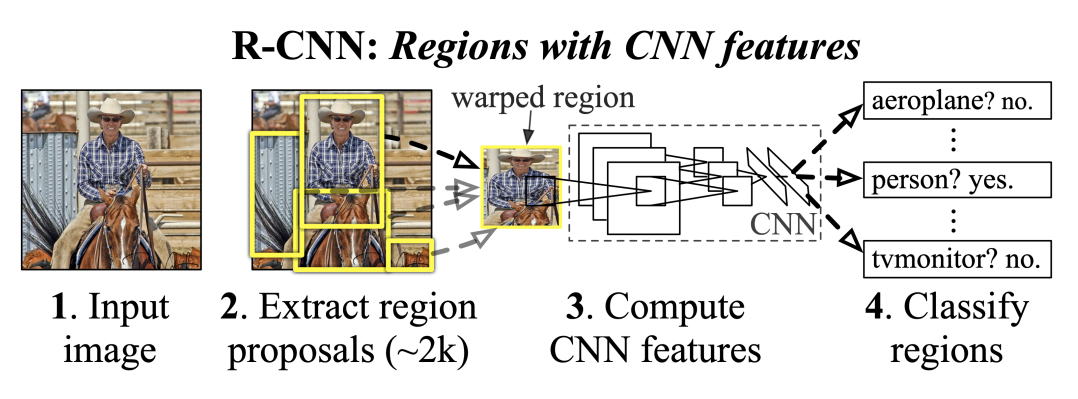
R-CNN
1. Input Image2. Extract Region Proposals
Selective Search 알고리즘을 사용하여 2000개 정도의 Bounding Box를 추출한다.
3. Warping Region
Pre-Trained 된 BackBone CNN 을 사용하기 위하여, 추출된 bounding box 영역을 resize한다.
resize로 인해 input image가 왜곡되고 정보 소실이 어느정도 발생한다.
이때, CNN BackBone의 FC Layer의 Input size 때문에 resize가 강제되는 것이다.
( Feature Extract 단은 Input Size에 영향 받지 않음 → Convolution 연산 특징)
4. Compute CNN Features
3번의 Warped Region 을 BackBone 모델에 넣는다.
5. Classify with SVM
추출된 Feature 를 SVM 을 이용해 Classfication 을 진행한다.
흔히 알려진 Softmax 를 사용하지 않는 이유는 Softmax를 사용하였을때, mAP 가 약 4% 정도 떨어졌다 한다. (본 논문 기재)
6. Bounding Box Regression
Ground Truth 와 BackBone CNN 을 거친 Bbox 의 차이를 이용해 이를 줄이는 과정을 반복한다.
R-CNN의 한계점
Image 를 Warping 하는 과정에서 정보 손실과 왜곡이 발생한다.
Selective Search 에서 나온 2000개의 Region 전부가 각각 CNN 모델로 들어가므로 시간이 오래 걸린다.
CNN, SVM, Bounding Box Regression 3가지 모델이 결합되어 있어 end-to-end 학습이 불가능하다.
Fast R-CNN
이름에서도 볼수 있듯이 기존 R-CNN 의 속도측면을 포함하여,
3가지 모델의 결합으로 인해 end-to-end 학습이 불가능한 한계점등을 극복하고자 나왔다.
1. Feature Extraction from Input ImageInput Image 에서 CNN BackBone을 이용하여 Feature Map을 추출한다.
2. Extract Region Proposal
R-CNN 과 마찬가지로 Selective Search를 통해 2000개의 Bounding Box를 추출한다.
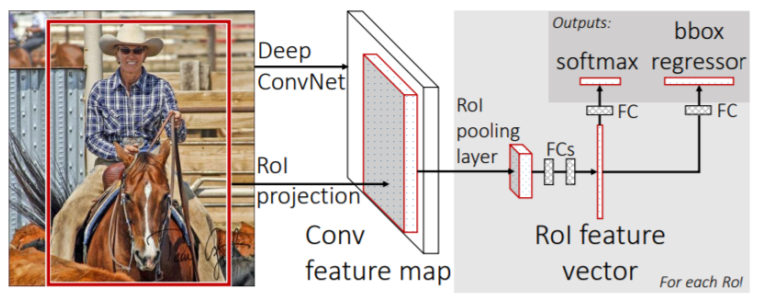
3. ROI Projection
기존 R-CNN 에서는 각각의 Bounding Box의 Feature Map을 추출 했지만,
Fast R-CNN 에서는 Input Image 에 대한 단 1번의 Feature Map을 추출한다.
이후 2번 과정의 Bounding Box 들을 Feature Map에 투영시키는 과정을 거친다.
Feature Map은 sub-sampling 과정을 거치며 크기가 작아 졌기때문에, Bounding Box를 이에 투영 시키기 위해서는 bbox의 크기와 중심 좌표를 sub-sampling ratio에 맞춰 변경 시켜준다.4. ROI Pooling
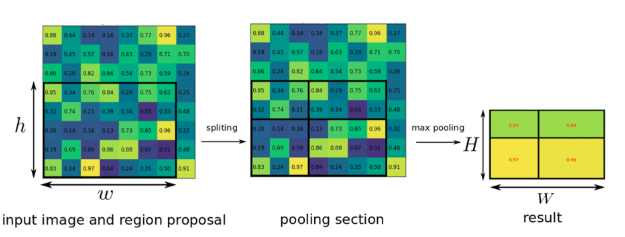
추출된 RoI Feature Map 을 max-pooling 하여 고정된 크기의 pooling map을 만든다.
이때, RoI Feature Map에 Grid를 그리고 각 Cell 에 대해 max-pooling을 수행한다.
이 과정을 수행함으로써 Random 한 크기의 RoI Feature Map 에서상 같은 크기의 pooling map을 추출할 수 있으며, FC Layer의 Input이 될 수 있다.
5. Classfication, BBR(Bounding Box Regression)
고정된 크기의 pooling-map을 FC Layer에 통과시켜, RoI Feature Vector를 얻는다.
Softmax와 Bbox Regressor 를 통해 Classfication 과 bbox Regression을 동시에 진행한다.6. Multi Task Loss
Classfication 과 BBR로 부터 각각의 Loss 를 얻고 이들을 엮어 Multi Task Loss 를 만들후 Backpropagation을 통해 전체 모델을 학습시킨다.
Fast R-CNN의 한계점
- 여전히 Selective Search 의 연산 속도는 느리다.
Faster R-CNN
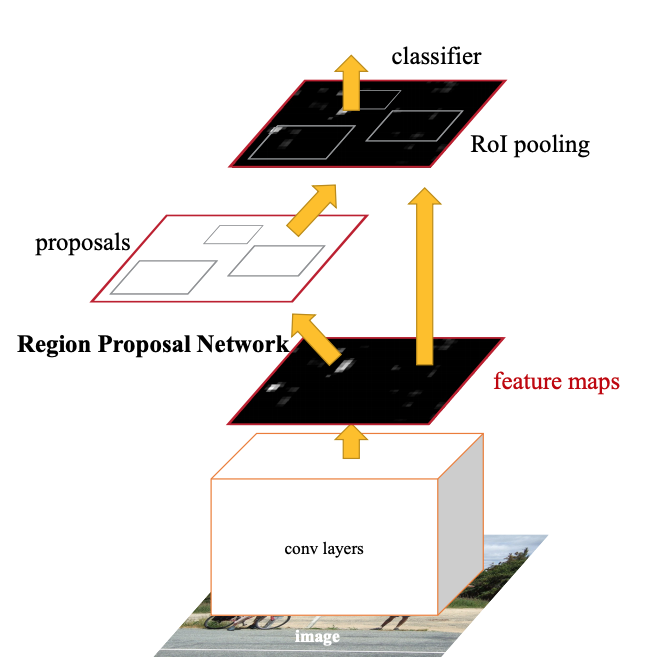
Region Proposal Network (RPN) 을 도입하면서, 더이상 Selective Search 알고리즘을 사용 하지않고 RoI 를 추출한다. RoI 추출 과정 까지 학습이 가능해지면서, 진정한 의미의 end-to-end 학습이 가능해졌다.
Region Proposal Network
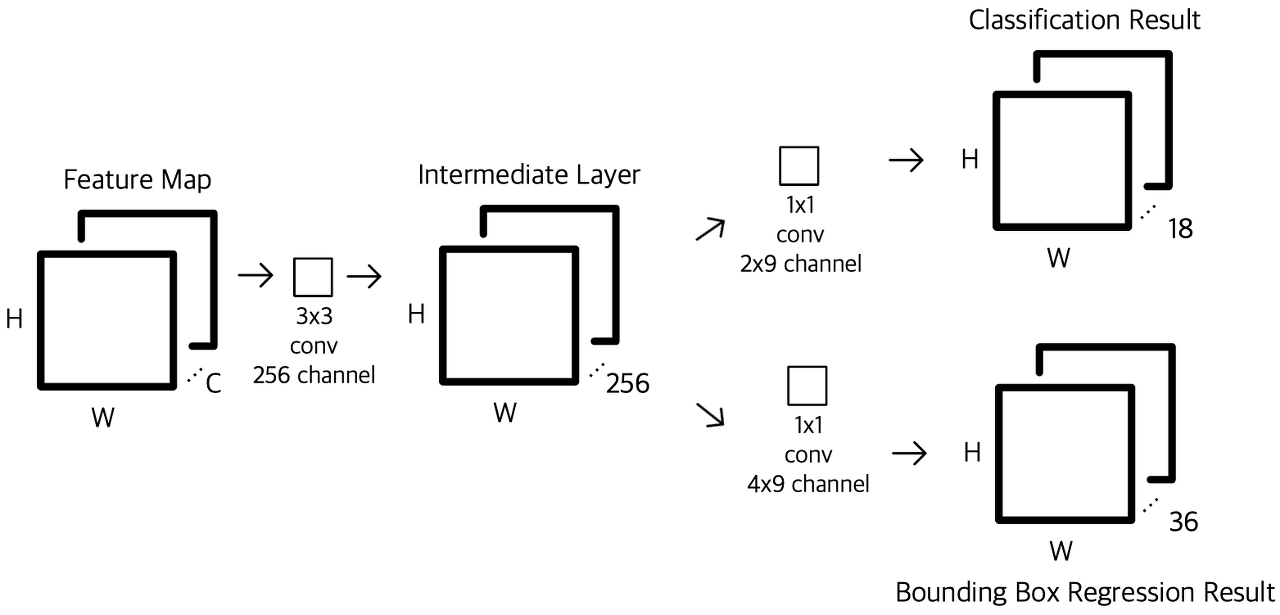
1.CNN BackBone 을 거친 Feature Map을 Input으로 받는다.
- Feature Map에 3x3 Conv 연산을 256 or 512 채널만큼 수행한다. 이때 padding=1 로 하여, 크기를 보존한다. (Intermediate Layer 해당)
- 2번의 output인 256 or 512 채널의 Feature Map에 1x1 Conv 연산을 수행한다. (Input Size 영향 X)
Classificaiton
: 2 (Object의 True,False 여부) X 9 (Anchor 수)의 채널 수 만큼 수행하며, H와W는 Feautre Map 상의 좌표를 의미하고, 18개의 각 Channel 은 해당 좌표에서의 각 앵커가 Object 인지 아닌지에 대한 값들이 존재한다.BBR
: 4(x,y,w,h) X 9 (Anchor 수) 의 채널 수 만큼 수행하며, 각 앵커의 bbox를 나타낼 수 있는 값들이 존재한다.
Classifiction 을 통해 얻은 값들을 정렬 후, 높은 순으로 몇개의 Anchor 만을 추려낸다.
이후, 각 Anchor 에 대해 BBR을 적용 시키고, Non-Maximum-Suppression을 적용하여 RoI 를 추출한다.
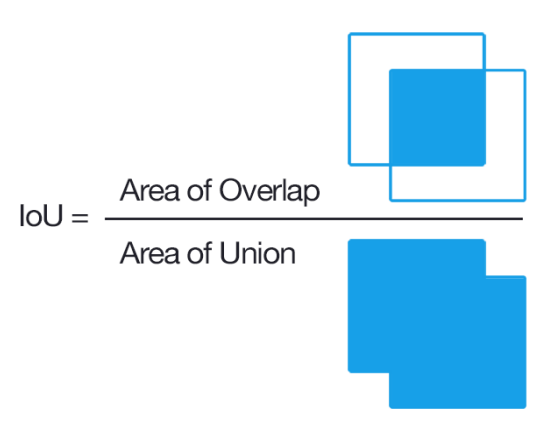
- Non-Maximum-Supperession
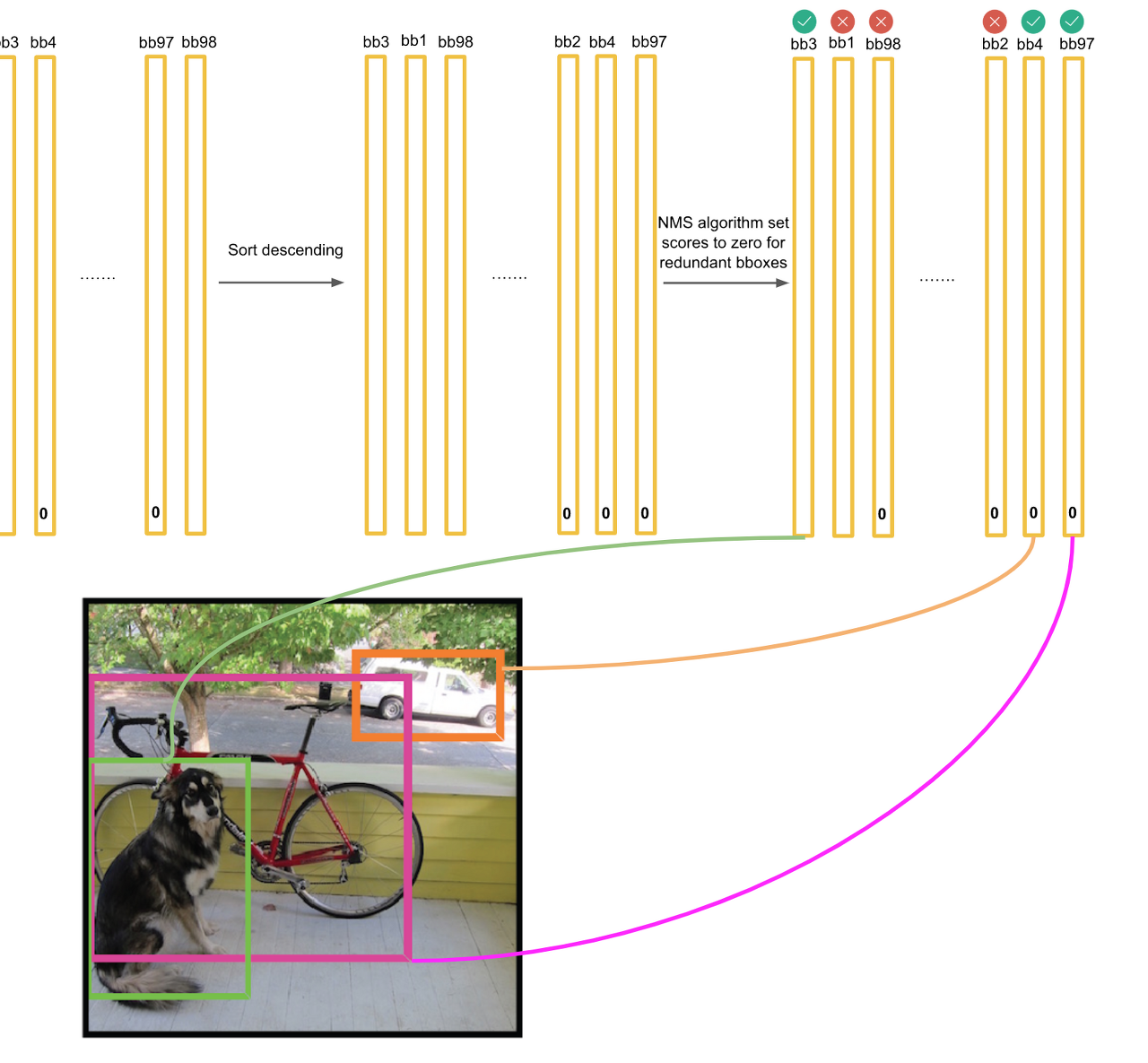
몇개의 선정된 bbox들을 IoU를 이용하여, 가장 높은 IoU를 가지는 bbox 만을 남긴다.
Structure
- Input Image에서 Backbone CNN 을 이용해 Feature Map 을 추출한다.
- Feautre Map을 RPN 에 전달하여, Region Proposal 들을 얻는다.
- Fast R-CNN 과 마찬가지로, RoI Pooling 을 이용하여 고정된 pooling-map을 얻는다.
- pooling-map을 FC Layer에 통과시켜, Feature Vector 를 얻은 후, Classfication 과 BBR을 수행한다.
Training
- RPN과 Classifier 및 BBR를 동시에 학습시키는데에는 한계가 있다.
(RPN에서 RoI 조차 제대로 추출하지 못한다면, 뒷 부분은 학습이 불가)
- 따라서, RPN 만을 따로 먼저 학습 시킨뒤 Fast R-CNN 을 학습시킨다.
이후, 학습된 RPN 과 Fast R-CNN 을 Load 한뒤 RPN 만을 fine-tuning 시킨다.
2.Single-Stage Detector
Single-Stage VS Two-Stage
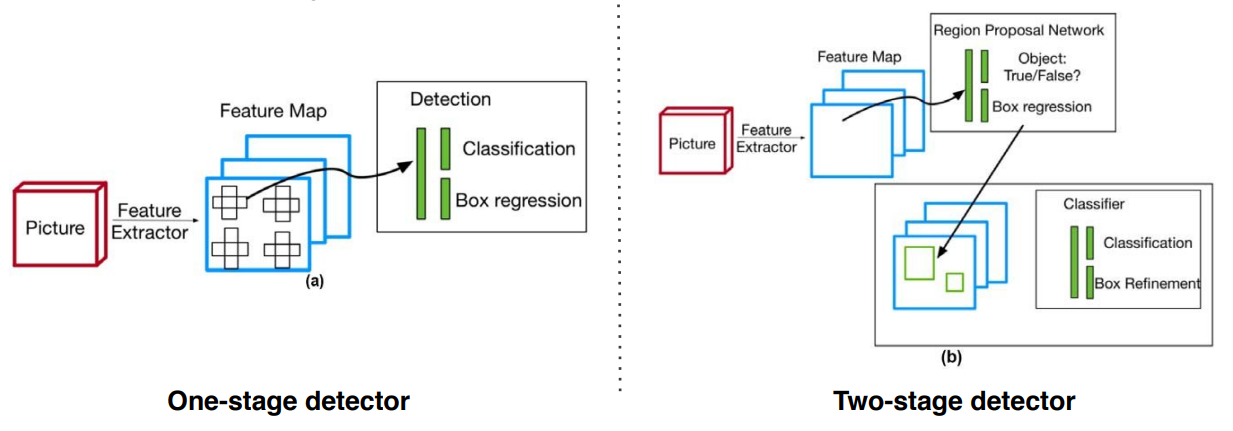
- Single-Stage 에서는 RoI Pooling 과정 없이, 한번에 Classification 및 BBR 을 수행한다.
YoLo
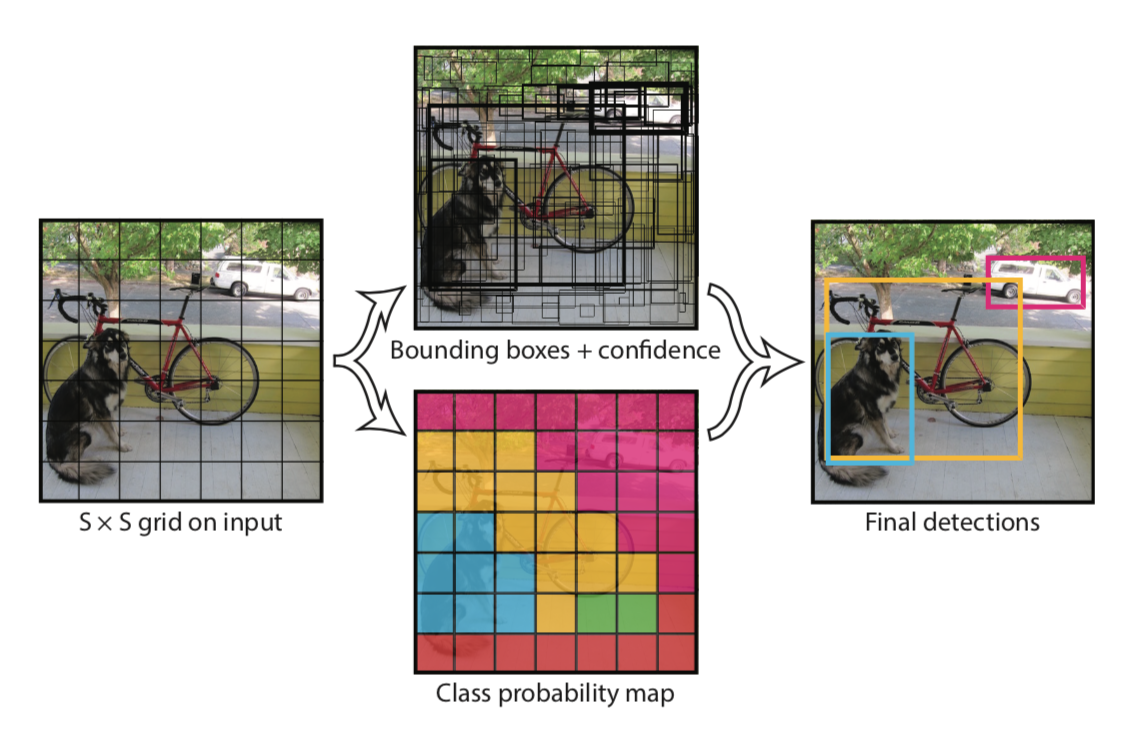
- Input Image 를 S x S Grid 로 나눈다.
- 각 Grid 에서 bbox 를 예측하고, 해당 bbox의 신뢰도에 해당하는 Confidence를 계산한다.
Confidence는 Grid에 물체가 존재할 확률과 예측한 bbox와 Ground Truth box의 IoU를 곱한다.
- 각 Grid 마다 C개의 클래스에 대해 해당 클래스일 확률을 계산하여, Class Probability Map을 구한다.
- Non-Maximum-Suppressionn 을 거쳐 최종 bbox를 이미지 위에 그린다.
Output 분석
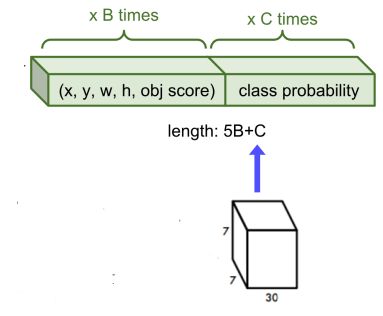
- 7x7 은 Grid Size에 해당하며, 각 인덱스는 30 채널 수를 가진다.
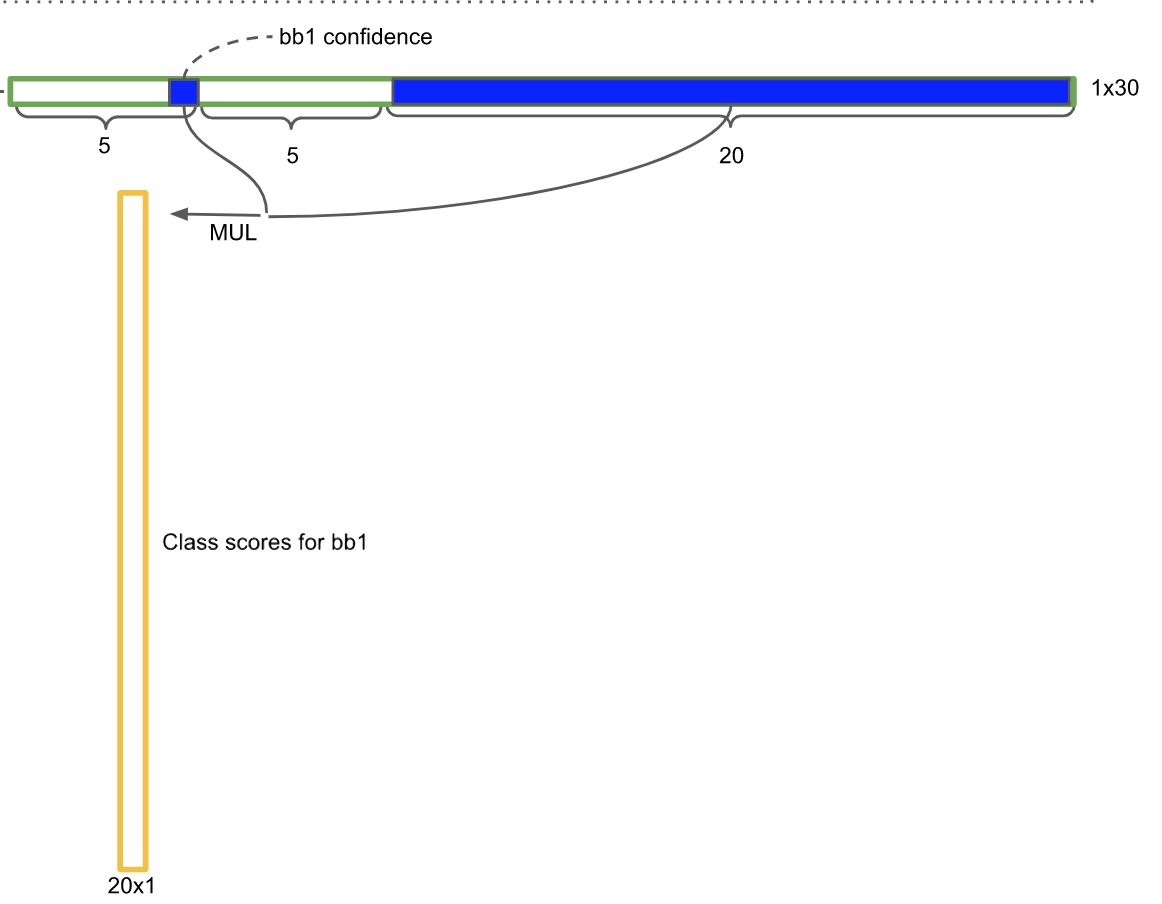
이때, 앞 10개의 채널은 B개(2개) 의 bbox 정보에 해당하며, 뒤 20개 채널은 C개(20개) 의 클래스일 확률의 값들이다.- bbox 정보는 box의 중심점 좌표 (x,y) 와 너비 및 높이 (w,h) 그리고 Confidence 로 나타낸다.
- 각 bbox 의 Confidence에 해당하는 값과 C 개 클래스의 각 확률을 곱하여, 해당 bbox가 특정 클래스일 확률을 구한다.
- 이렇게 구해진 각 그리드에 대한 bbox와 클래스 확률 vector들을 나열 및 정렬 후, NMS(Non-Maximum-Suppression) 기법을 적용시켜 최종 bbox를 구한다.
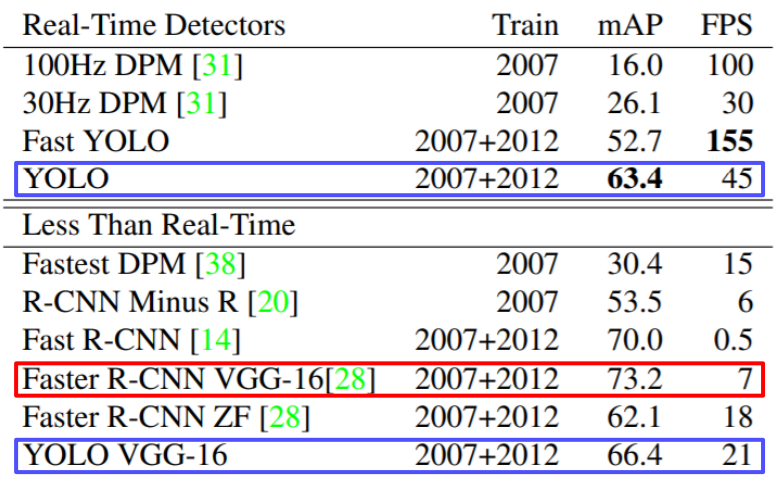
mAP 및 FPS 비교
- Two-Stage Detector 인 R-CNN Family에 비해 FPS가 월등히 높은 것을 알 수 있다.
- 하지만 mAP 측면에서는 떨어진다.
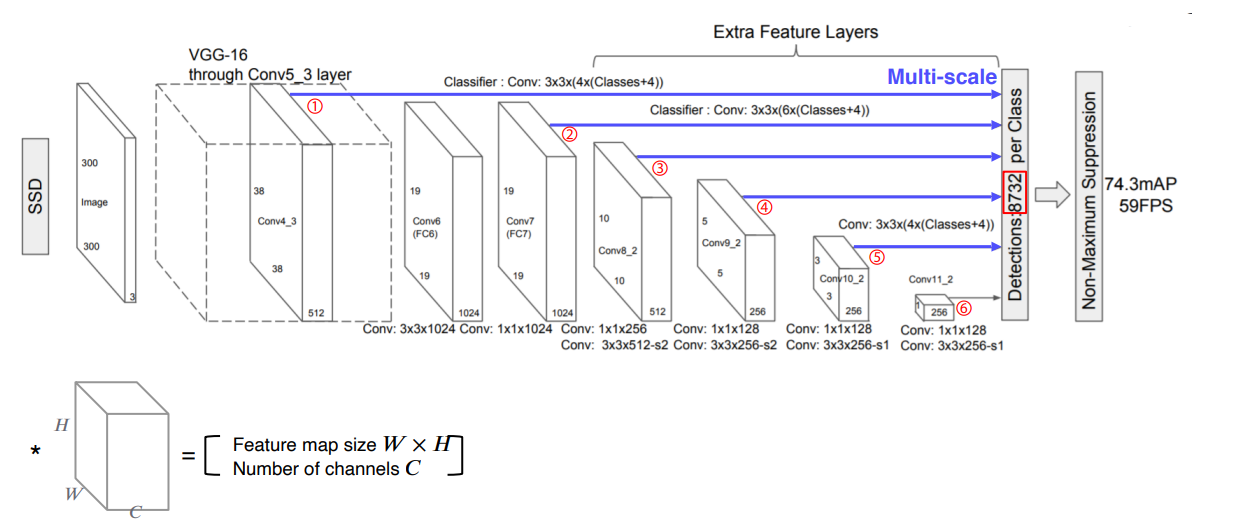
Single Shot MultiBox Detector (SSD)
Two-Stage Detector 에 비해 Single-Stage Detector가 속도는 빠르지만, 정확도가 떨어진다.
- Grid 를 나누고 각 그리드 별로 bbox 를 predict 하기 때문에, 그리드 크기보다 작은 물체는 잘 Detect 하지 못한다
- CNN 을 통과하면서 Size 가 가장 줄어든 마지막 단의 Feature Map만을 사용한다.
- Structure
- 중간 Conv Layer 의 Feature Map을 추출하여, 다음 Layer로 넘기는 동시에 Object Detection을 함께 수행한다.
→ 디테일한 정보들이 사라지는 것을 방지
- 각 Conv Layer 에서 추출되는 Feature Map에 각기 다른 size의 Default Box를 설정한다.
→크기가 큰 Image 에서는 작은 물체를 비교적 잘 잡아낼 수 있다.
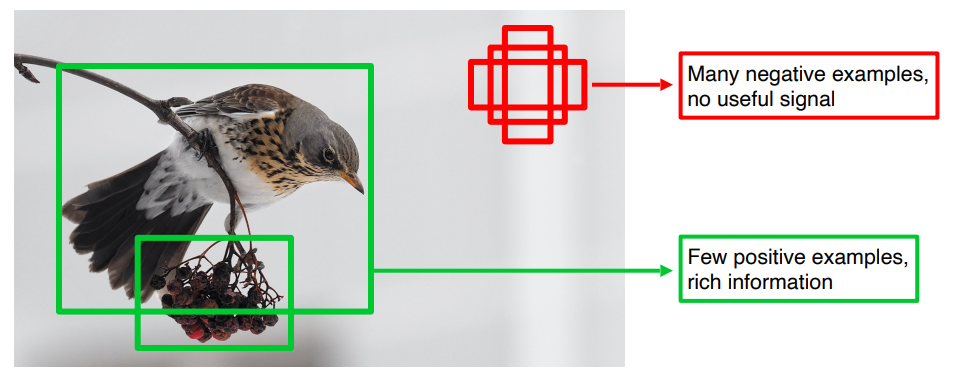
Class Imbalance Problem
- 대체적으로 Image에서 Detect 하고자 하는 Object의 영역보다 background 영역이 훨씬 큼.
- 따라서, Grid 별로 bbox를 predict 하는 Single-Stage Detector 에서는 Neg box 와 Pos box 간의 Class Imbalance 가 발생 할 수 밖에 없다.
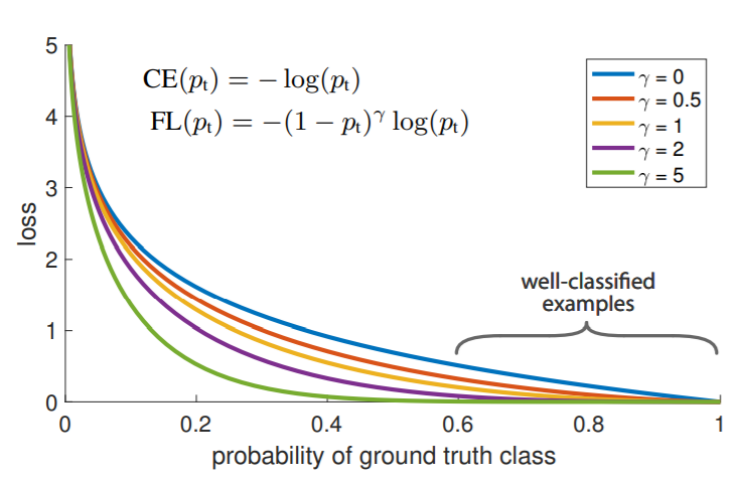
Focal Loss
- CE가 확장된 Loss 로써, gamma 값 조정을 통해 가중치 여부를 결정 할 수 있다.
- gamma 값이 클수록, 맞추기 어려운 class에는 큰 가중치를 쉬운 class에는 작은 가중치를 부여 할 수 있다.
- 그래프를 단순히 loss 값으로 비교하는 것이 아닌 해당 지점의 Gradient 값으로 비교해야한다.
참고:
https://yeomko.tistory.com/13
https://yeomko.tistory.com/15
https://yeomko.tistory.com/17
https://yeomko.tistory.com/19
https://wikidocs.net/136482
