Filter Images First, Generate Instructions Later: Pre-Instruction Data Selection for Visual Instruction Tuning
논문
Abstract
LVLM의 tuning에는 대규모 image-text pair의 데이터셋이 필요하며, 이는 비용이 많이 든다.
최근 Visual instruction Tuning(VIT) data selection 연구는 고품질의 소수의 image-text pair의 데이터만을 골라내어 전체 training과 유사한 성능을 유지하면서, 실행시간을 줄이는 데 초점을 맞추고 있다.
VIT란, VLM에게 image에 대한 사람의 지시를 이해하고 따르는 능력을 학습시키는 과정
- V-L task에 대해 general한 능력을 갖게하는 과정
하지만, 여기에서의 문제는, text가 붙지 않은 이미지(Label이 없는 image)에서 text를 생성하는 비용이 매우 높다는 것이다.
현재 대부분의 VIT 데이터셋은 사람의 수작업 주석이나, GPT API같은 유로 서비스에 의존해서 비용이 높다.
기존 Data selection 방식은 image-text pair가 만들어진 뒤 그 중 일부를 고르는 방식
- 애초에 image-text pair를 만들 때의 주석 처리 비용이 크다.
이를 해결하기 이해, Pre-Instruction Data Selection, PreSel)이라는 Data selection 방법을 제안한다.
가장 유익한 Label이 없는 image를 선별하고, 선택된 image에 대해서만 instruction을 생성한다.
주석을 만들기 전에 image 자체를 먼저 선별하고, 선택된 이미지에 대해서만 주석 생성
1. Introduction
LVLM은 멀티모달 task에서 좋은 성능을 보여주고 있는데, Visual Instruction Tuning은 LVLM을 training할 때 핵심 단계로, 모델이 지시를 따르고 다양한 task 전반적으로 general하게 수행할 수 있게 한다.
이때, 지시는 다양한 vision-language task에서 사용하는 지시들을 포함하고 있다.
여기서 말하는 지시는 단순한 image에 대한 caption이 아니라, 모델이 task를 수행할 수 있게 설계된 text 프롬프트
예)
- “이 이미지에서 개의 수를 세어라” (counting)
- “사진 속 음식은 무엇인가?” (VQA)
- “이 장면을 설명하라” (captioning)
또한, 일반적인 VIT data들은 label이 없는 image와 그 image에 대해서 사람이 직접 주석처리하거나, GPT API를 통해 만들어낸 지시문으로 이루어진 image-text instruction pair로 이루어져 있다.
그러나, 현재 VIT 과정에는 2가지 핵심 문제가 존재
-
다양한 task에서 온 instruction들을 결합한 data에서는 data간 중복이 발생해 학습 시간이 크게 늘어나면서, 늘어난 시간에 비해 성능이 비례하지 않는다.
-
고품질의 instruction을 생성하는 데 비용이 매우 높다.
GPT-4같은 서비스로 image에 대해 instruction을 만들면 API비용이 매우 많이 들고, 품질을 보장하기 위해선 사람의 개입이 자주 필요하다.
그래서, 최근에는 정보량이 높은 고품질의 image-instruction만 selection해서 LVLM을 tuning하여 데이터 중복 문제를 해결하고 학습 시간 문제를 해결하려 했지만,
1. 대규모 VIT dataset을 위해 instruction을 생성하는 높은 비용 문제는 간과되어 왔다.
2. 또한, 이러한 방법들은 이미 image-instruction pair의 데이터셋이 준비되어 있다는 것을 가정하여, selection 알고리즘을 수행하는 것이다.
따라서, 이를 해결하기 위해 이런 질문을 제기한다.
여러 vision-language task에서 수집된 image가 주어졌을 때, instruction 생성 이전에 LVLM fine-tuning에 가장 영향력있는 image를 어떻게 고를 것인가?
본 논문에서는 Pre-Instruction data Selection이라는 새로운 접근 방법을 제안
- Task 중요도 측정
- Task별 cluster기반 selection
Contribution
-
Pre-Instruction data Selection을 처음으로 도입하여, 학습 시간뿐 아니라 instruction 생성 비용까지 줄일 수 있다.
-
Instruction 생성 비용의 15%만 사용해도 전체 VIT dataset으로 fine-tuning한 LVLM과 거의 비슷한 성능을 보였다.
2. Related Work
Vision Instruction Tuning
Instruction tuning은 LLM이 instruction을 따르고 general한 task에서 수행할 수 있도록 하는 training 단계이다.
이러한 자연어 처리 영역에서 multimodal을 위한 training으로 확장되며 LVLM을 위한 Vision Instruction Tuning으로 확장하고 있다.
이를 위해 대규모 VIT dataset이 필요한데, 이러한 VIT dataset을 만들기 위한 작업은 대부분 GPT모델을 사용하며 이는 비용이 많이 든다.
Data Selection for Visual Instruction Tuning
높은 training cost로 인해 최근 연구에서는 data에 효율적인 instruction tuning을 수행하고 있다.
최근 몇 가지 연구들에서 VIT를 위한 data selection이 수행되고 있는데, 이 연구들은 모두 전체 training cost를 증가시켜 data selection을 하는 목적에 모순된다.
3. Methodology
먼저 VIT를 위한 Pre-Instruction data Selection를 공식화하였다.
< Problem Formulation >
Label이 없는 image들의 집합 가 있다고 가정
이 image들은 다양한 dataset에서 모여 개의 서로 다른 vision task 집합 을 구성
여기서 이고, 안의 샘플의 개수는 라 한다.
각 task 는 Label이 없는 image들의 집합으로 이루어진다.
여기서 task는 image에 대해 겹칠 수 있음에 유의해야 한다.
Label이 없는 image 가 task 에 속한다면, 그에 해당하는 text instruction 는 로 생성된다.
는 task 의 instruction 생성 과정
Pre-instruction Data Selection의 목표는, Label이 없는 image 집합 에서 높은 가치가 있는 작은 부분 집합 을 고른 뒤, 이 작은 집합에 대해서만 instruction을 생성하는 것이다.
이후 과 같은 image-text instruction pair로 LVLM을 fine-tuning하면, 모델의 instruction 이해 능력을 크게 향상시키고, 전체 dataset으로 tuning한 경우와 유사한 성능을 얻을 수 있다.
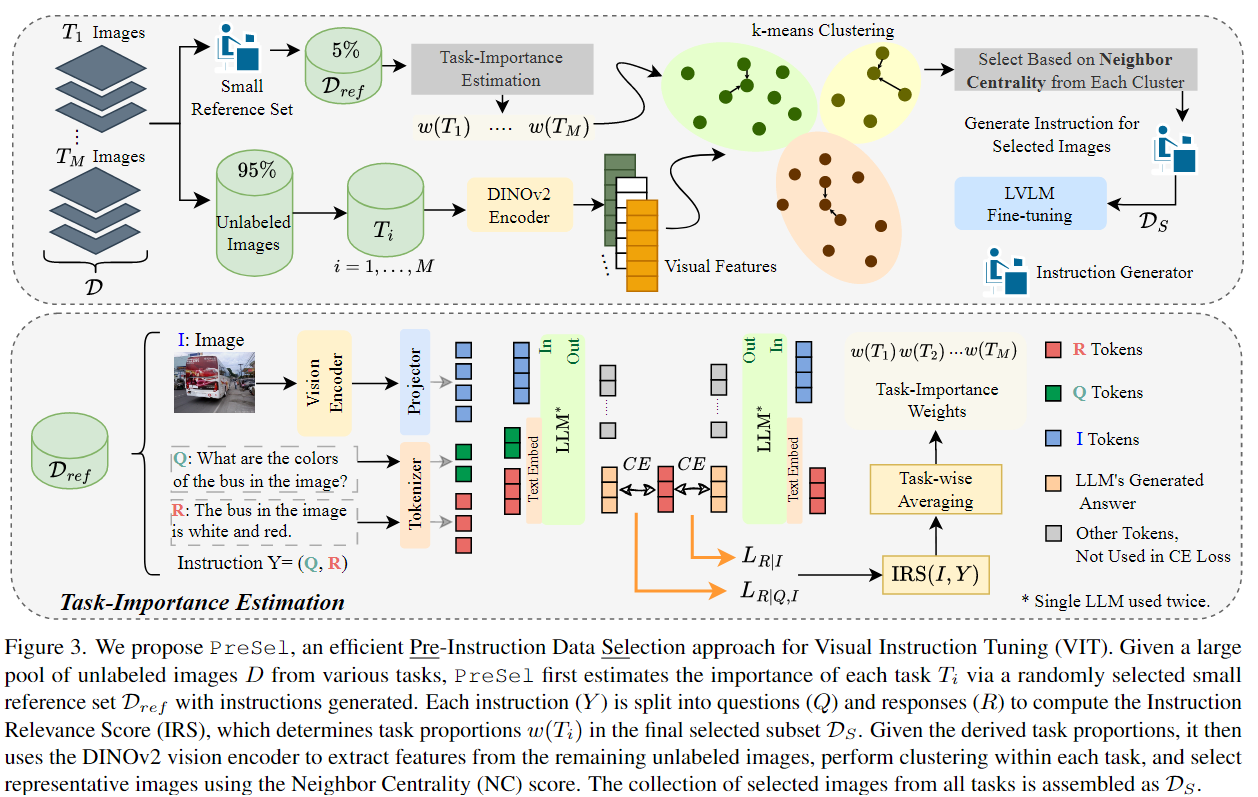
3.1. Task-Importance Estimation
최종 선택 집합 에 각 task별 샘플을 얼마나 배분할지 결정하는 것은 매우 중요하다
단순히 각 task에 사용 가능한 이미지 수에 비례해서 배분하면 task마다 중복되는 학습 능력이 다르기 때문에, 최적 이하의 성능으로 이어질 수 있다.
어떤 task는 유사한 task를 통한 학습만으로도 충분히 수행될 수 있어, 직접적으로 많은 샘플을 뽑을 필요가 적다.
먼저 전체 VIT dataset 에서 무작위로(전체 5%) 소량만 선택한 작은 집합 으로 LVLM을 1epoch 만큼만 fine-tuning하여 기본적인 instruction을 따를 수 있는 능력만을 갖추도록 한다.
이 fine-tuning된 모델을 reference model이라 부른다.
이 reference model이 에서 내는 loss를 활용하여, task에 샘플을 배분하기 위한 중요도 측정 점수인 Instruction Relevance Score를 정의한다.
IRS 정의

위 그림처럼 내 각 VIT에는 (I,Q,R)의 삼중항으로 표현된다.
- I : Image
- Q : 사람이 만든 텍스트 질문
- R : GPT가 생성한 응답
IRS는 reference model의 다음 token에 대한 예측 손실(CE Loss)를 비교하여 계산된다.
1. I와 Q만을 이용하여 R을 예측할 때의 Loss
- : GPT가 생성한 응답 R을 tokenization한 것
- : 토큰 개수
- : Referenece모델이 j번째(현재) 전까지 예측한 답변 토큰
- : GPT가 생성한 j번째 정답 응답
: 모델이 예측한 j번째 토큰과 GPT가 생성한 j번째 정답 토큰 간 CELoss계산
즉, 이미지와 질문을 조건으로 줄 때, 모델이 GPT가 만든 정답 응답을 얼마나 잘 재현했는가를 나타내는 값이다.
2. Q없이 I만을 이용하여 R을 예측할 때의 Loss
3. IRS 정의
높은 IRS : Q를 추가해도 R을 생성하는 데 도움이 되지 않는다
=> 질문 Q의 필요성이 낮음낮은 IRS : 모델이 Q가 있을 때 R을 훨씬 잘 생성한다.
=> 질문 Q가 중요한 역할을 한다.: IRS는 특정 task가 얼마나 instruction에 의존하는지를 보여준다.
과제 중요도 계산
각 task 의 IRS 평균은 다음과 같이 정의한다.
- : i번째 task
- : 중 task 에 속하는 샘플 모음
- : 중 task 에 속하는 샘플의 개수
- : Image와 Y(Q,R쌍)에서 Y가 얼마나 중요한지에 대한 score
: Task 에 속한 샘플들의 IRS를 전부 평균낸 값이 이다
낮은 : 해당 task가 중요하다
높은 : 해당 task가 덜 중요하다
최종적으로 각 task의 상대적 비율은 softmax 형태로 정하여 이를 기반으로 task별 샘플링 예산을 배정한다.
- : 최종적으로 task 가 전체 샘플에서 차지하는 비율(샘플링 예산)


3.2. Task-wise Cluster-based Selection
를 통해 task별 상대적 비율을 정했으니, 이제 각 task 내부에서 instruction 생성을 위한 정보량이 높은 label이 없는 image들을 선택하는 단계에 집중한다.
과제 에 속한 label이 없는 image들에 대해서, pre-trained된 경량 vision encoder(DINOv2)를 이용하여 visual feature를 추출한다.
입력 이미지에 대해, transformer 층의 [CLS]토큰에서 feature vector 를 얻는다.
이렇게 얻은 의 feature vector 들을 k-mean 알고리즘으로 개의 cluster 로 묶는다.
으로 설정
Cluster별 샘플 수 결정
Task 의 번째 cluster에서 샘플을 선택할 때는, cluster의 상대적 크기 와 task의 중요도 가중치 를 모두 고려한다.
구체적으로, 다음과 같이 선택할 샘플의 수 를 정한다.
- : task 의 번째 cluster에서 선택할 샘플의 개수
- : task 의 중요도
- : 에서 번째 cluster에 속한 image의 수
- : task 의 전체 image 수
- : 최종적으로 뽑을 전체 샘플의 수
: 중요한 task는 전체에서 더 많이 샘플링되고, 그 안에서도 클러스터의 크기 비율에 맞게 뽑혀서 다양성 유지
Cluster 내부 선택
각 cluster의 내부에서는, Neighbor Centrality(NC) 점수를 기준으로 가장 대표적인 개의 image를 고른다.
- : Image I의 feature space에서 k개의 최근접 이웃
- : Cosine similarity
: 즉, 가 높다는 것은 해당 iamge가 주변 이웃들과 매우 유사하다는 뜻이고, 이는 그 이미지가 대표적 샘플일 가능성이 높음을 의미한다.
최종적으로 모든 task에서 선택된 image를 모아 최종적인 를 구성한다.
이 에 대해서만 instruction을 생성하고, 이를 사용해 LVLM을 fine-tuning한다
4. Experiments
실험은 LLaVA-1.5-7B모델을 대상으로 수행되었음
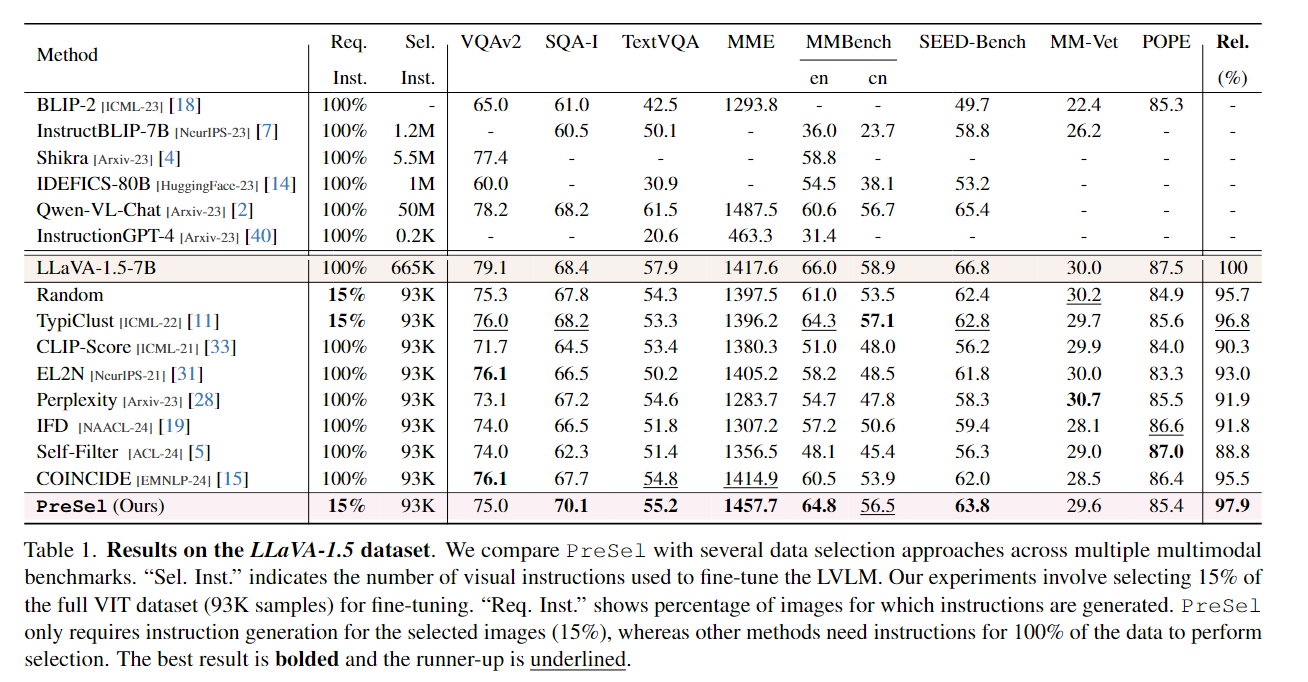
- Dataset : LLaVA-1.5 dataset
- Method: 비교하는 모델/방법
- Req. Inst. (Required Instructions): 각 방법이 지시문을 생성해야 하는 데이터 비율
- 100% → 전체 데이터에 대해 지시문 필요
- 15% → 데이터의 15%만 지시문 생성
- Sel. Inst. (Selected Instructions): 실제 지시문 개수 (샘플 수)
<다른 기법>
공통적으로 Sel. Inst. = 93K (전체의 15%)만 사용함
하지만, 지시문을 생성하는 비율은 전체 (100%)에 대해 생성함
< PreSel >
데이터의 15%만 지시문 생성하면서도, 다른 selection 방법보다 consistently 더 높은 점수 기록
- 비용 절감(지시문 생성량 85%↓) + 성능 유지/개선
PreSel is robust across varying task diversities
-
LLaVA-1.5 데이터셋은 약 10개의 과제(task)만 포함 → 과제 수가 비교적 적음.
-
Vision-Flan 데이터셋은 무려 191개 시각 과제를 포함 → 훨씬 더 다양하고 복잡한 태스크 구성을 가짐.
따라서 연구팀은 LLaVA-1.5-7B모델에서 Vision-Flan에서도 실험해 PreSel이 과제 다양성이 커져도 잘 작동하는지 검증함.
<실험 결과>
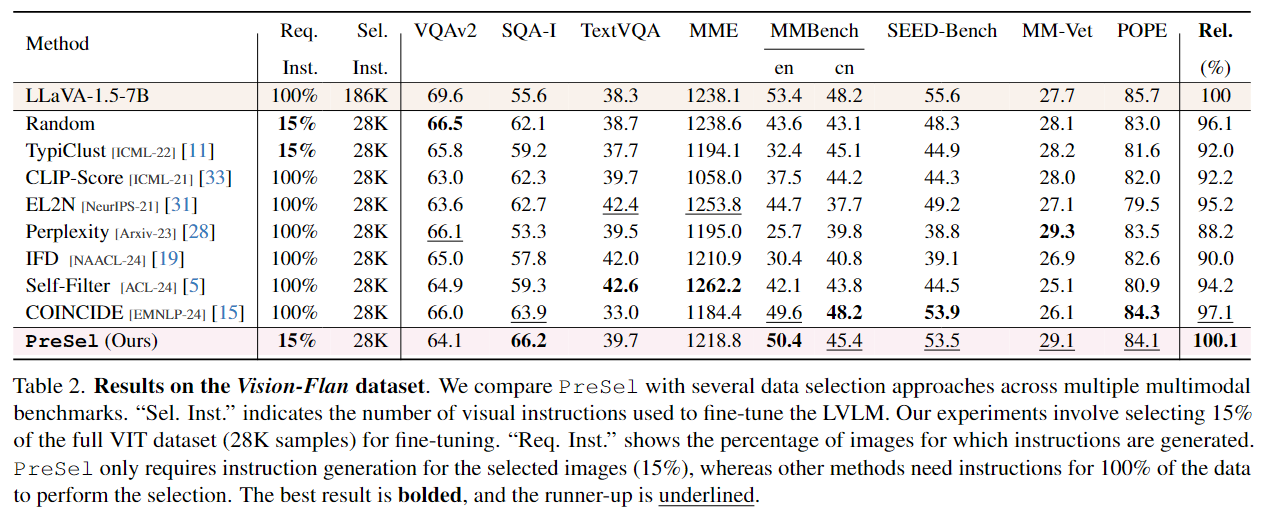
PreSel은 Vision-Flan 실험에서 전체 데이터(100%)를 사용한 LLaVA 모델보다 성능이 약간 더 높음.
이때 PreSel은 전체 데이터 중 15%만 지시문을 생성했음에도 불구하고 성능 손실이 없고, 오히려 더 나음.
따라서 PreSel은 과제 수가 적든 많든(VQA·OCR·캡셔닝 몇 개 수준부터 191개까지), 성능 저하 없이 적용 가능하다는 게 확인됨
- PreSel은 과제 다양성이 큰 데이터셋에서도 강건하게 작동
