논문
1.BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
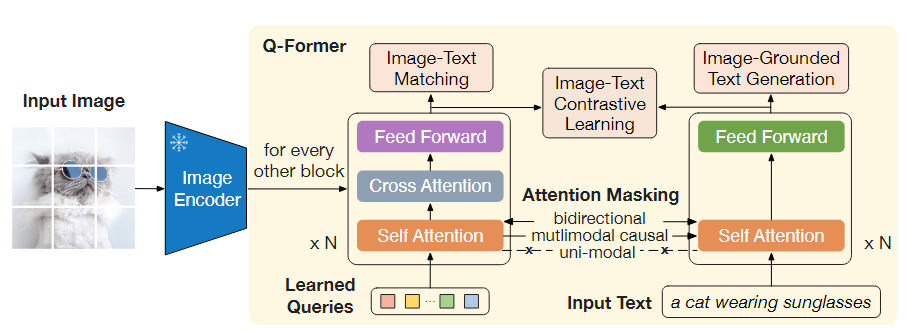
BLIP-2는 대규모 모델의 종단 간 학습으로 인해 비전-언어 사전 학습 비용이 증가하는 문제를 해결하기 위해 고안된 효율적인 사전 학습 전략이다.BLIP-2는 미리 학습된 이미지 인코더와 대형 언어 모델(LLM)을 고정한 채로 활용하고, 가벼운 쿼리 변환기(Query
2.mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
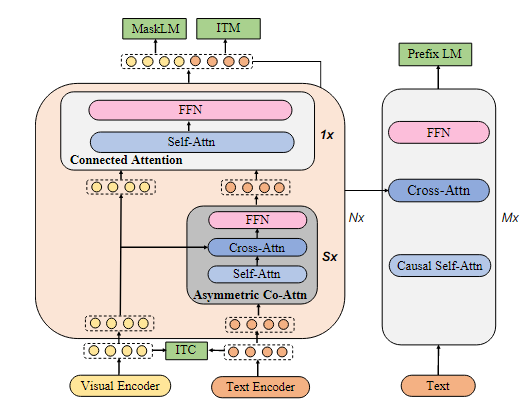
Abstract 본 논문은 교차 모달 이해와 생성을 모두 수행할 수 있는 새로운 비전-언어 기반 모델인 mPLUG를 제안한다. 기존 사전 학습된 모델들은 주로 긴 시각적 시퀀스와 교차 모달 정렬로 인해 발생하는 낮은 계산 효율성과 정보 비대칭 문제를 겪는다. 이를 해결
3.Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
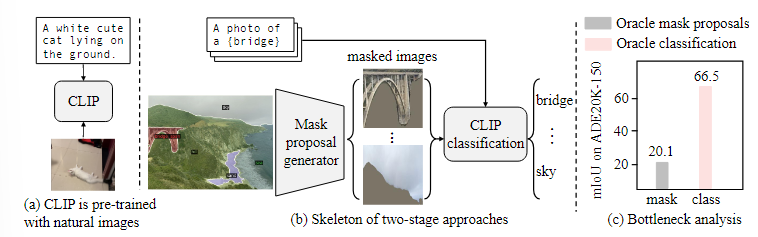
오픈 보카뷸러리 의미론적 분할(Open-vocabulary semantic segmentation)은 학습 중 보지 못한 텍스트 설명에 따라 이미지를 의미론적 영역으로 나누는 것을 목표로 한다.최근의 두 단계 접근법은 먼저 클래스에 구애받지 않는 마스크 제안을 생성한
4.Dynamically Pruning Segformer for Efficient Semantic Segmentation (ICASSP 2022)

Abstract 컴퓨터 비전 작업에서 Transformer 기반의 모델 중 하나인 SegFormer는 semantic Segmentation에서 우수한 성능을 보여주었지만, 높은 계산 비용으로 인해 엣지 디바이스에 SegFormer를 배포하는 데 어려움을 겪고 있다.
5.MoPE-CLIP: Structured Pruning for Efficient Vision-Language Models with Module-wise Pruning Error Metric
Abstract Vision-language model은 다양한 다운스트림 task에서 좋은 성능을 보여주었지만, 모델의 크기 때문에 컴퓨팅 리소스가 제한된 환경(모바일 기기, 엣지 서버)에서는 활용도가 떨어진다. >다운스트림 task? >- Pre-Training된
6.Open Vocabulary Semantic Segmentation with Patch Aligned Contrastive Learning (CVPR 2023)
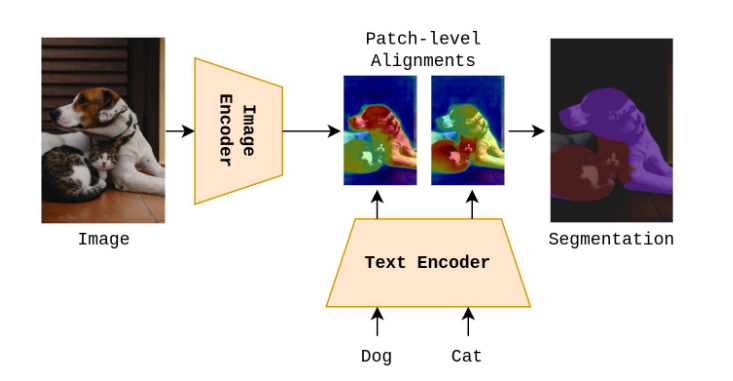
이 논문은 Open Vocabulary Semantic Segmentation을 수행하는 새로운 방법론을 제안한다.Open Vocabulary Semantic Segmentation훈련 시 특정 데이터셋이 없어도 텍스트에 해당하는 이미지 내 영역을 식별하는 것제안된 방
7.MULTIFLOW: Shifting Towards Task-Agnostic Vision-Language Pruning

Abstract 비전-언어 모델은 다양한 작업에서 좋은 성과를 보인다. 하지만, 비전-언어 모델은 대규모 매개변수로 인해 높은 계산 비용이 요구된다. 이러한 문제를 해결하기 위해 모델 pruning은 실질적인 해결책으로 떠오르고 있다. 그러나, 기존의 pruning
8.SkyScript: A Large and Semantically Diverse Vision-Language Dataset for Remote Sensing

Remote Sensing(원격 감지) 물리적 접촉 없이 멀리 떨어진 곳에서 원격으로 정보를 수집하는 기술 직접 가서 눈으로 보거나 만지지 않고, 위성이나 드론, 레이더와 같은 장비를 이용해서 데이터를 모으는 기술 사용 분야 환경 : 자연재해 모니터링으로 감지 및
9.RemoteCLIP: A Vision Language Foundation Model for Remote Sensing
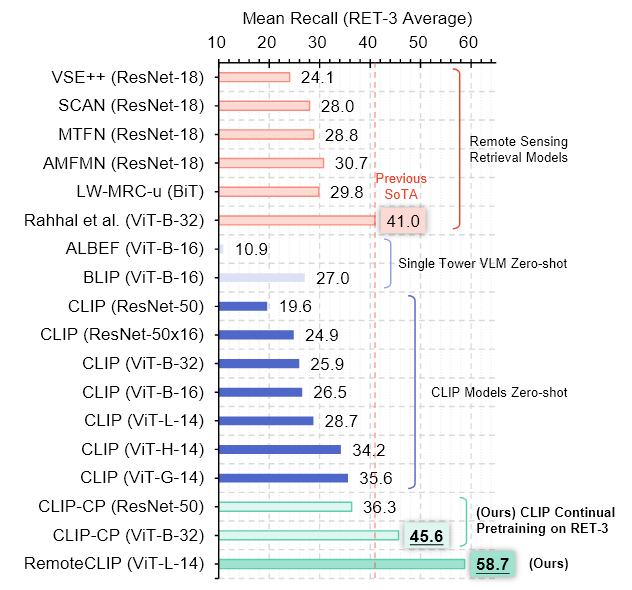
Foundation model의 general한 활용은 인공지능 개발에서 중요한 돌파구를 제공하였다.Foundation model?다양한 task에서 general하게 활용할 수 있도록 대규모 데이터와 자원을 기반으로 학습된 모델텍스트 기반 모델 : GPT, BERT이
10.A Prior Instruction Representation Framework for Remote Sensing Image-text Retrieval
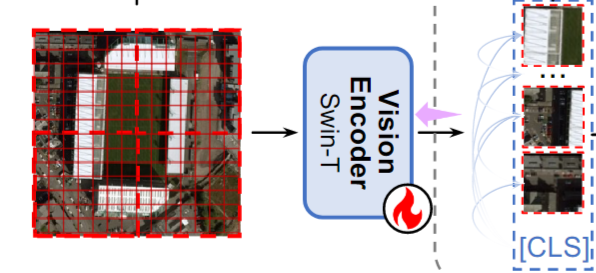
Abstract 이 논문은 Remote sensing 데이터에서 image와 text 간의 연관성을 더 정확하게 찾아내기 위한 새로운 방법을 제안한다.(Remote Sensing Image-Text Retrieval) 기존의 Remote Sensing Image-Te
11.PIR: Remote Sensing Image-Text Retrieval with Prior Instruction Representation Learning
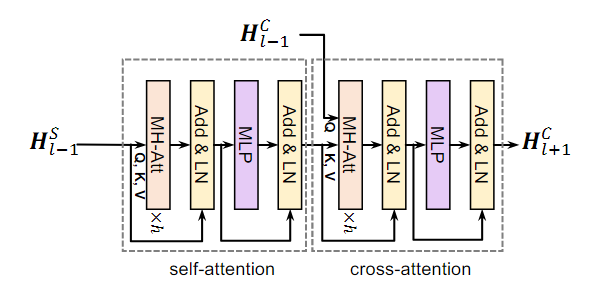
Abstract Remote sensing image-text retrieval은 Remote sensing 해석 작업의 중요한 요소로, 시각적 및 언어적 표현을 Align하는 역할을 한다. 본 논문에서는 Prior Instruction Representation(P
12.REMOTE SENSING VISION-LANGUAGE FOUNDATION MODELS WITHOUT ANNOTATIONS VIA GROUND REMOTE ALIGNMENT

Abstract >이 논문에서는 text 주석 없이 Remote sensing 이미지를 위한 VLM을 training하는 새로운 방법을 제안함 기존에는 image-text pair쌍이 있어야 training이 가능했지만, Remote sensing 이미지는 text
13.ECoFLaP: EFFICIENT COARSE-TO-FINE LAYER-WISE PRUNING FOR VISION-LANGUAGE MODELS
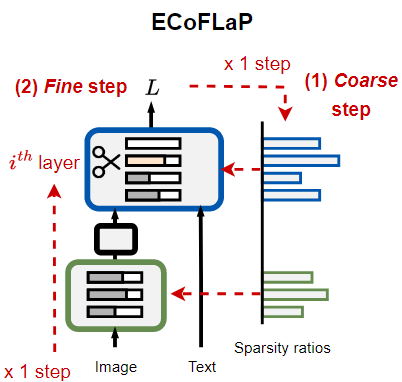
Abstract 대규모 비전-언어 모델(LVLM)은 image와 text의 풍부한 정보를 통합하여 종합적으로 이해할 수 있고, 이를 통해 multi-modal 다운스트림 작업에서 주목할 만한 발전을 이루어냈다. 하지만, LVLM은 크기가 매우 크고 연산량이 많아서,
14.A Survey on Deep Neural Network Pruning: Taxonomy, Comparison, Analysis, and Recommendations
Abstract 최근의 LLM은 막대한 모델 크기를 가지며, 이로 인해 상당한 계산 비용과 저장 공간을 필요로 한다. 모델을 리소스가 제한된 환경에서 배포하고 추론 속도를 높이기 위해 Model compression의 한 방법으로서 Pruning 기법을 탐구하였다.
15.Everybody Prune Now: Structured Pruning of LLMs with Only Forward Passes
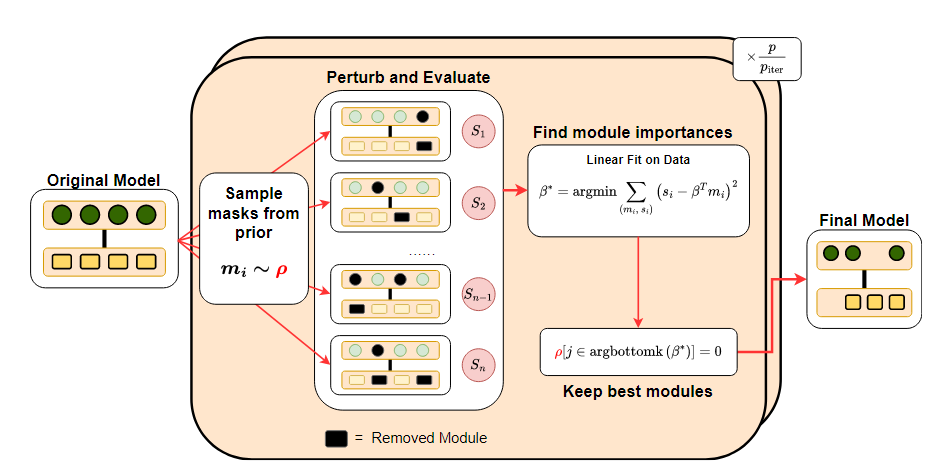
Abstract Structured pruning은 더 작고 빠른 LLM을 만들기 위한 경량화 방법이다. 기존 Pruning 방법들은 대부분 Backpropagation을 필요로 하기 때문에, Backpropagation을 위해 gradient 계산 비용과 메모리 사
16.LoRA 논문 리뷰
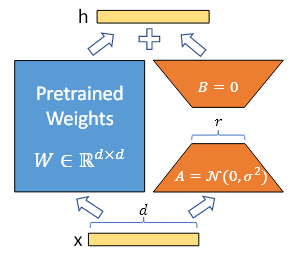
1. Lora: Low-rank adaptation of large language models - Introduction 자연어 처리에서 많은 Task들은 하나의 대규모로 pre-trained 된 언어 모델을 여러 downstream task에 적용시키는 데 의존한
17.A Survey of Quantization Methods for Efficient Neural Network Inference
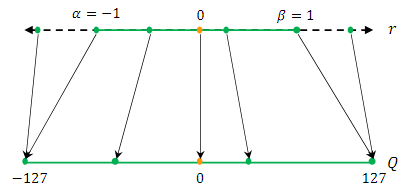
Abstract
18.Rethinking Pruning for Vision-Language Models: Strategies for Effective Sparsity and Performance Restoration
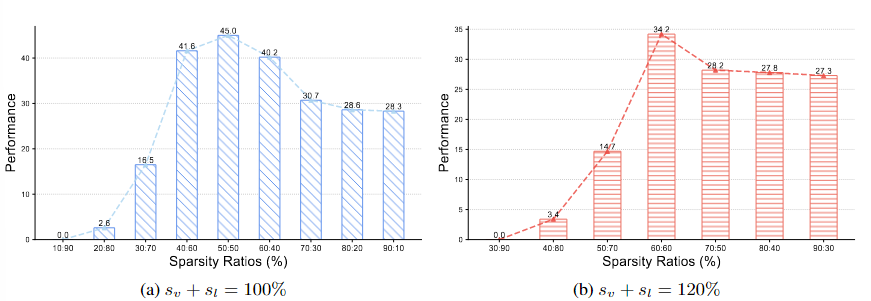
VLM은 여러 모달리티의 정보를 통합하여 다양한 과제에서 좋은 성능을 보여주었지만, 대규모 VLM을 리소스가 제한된 환경에 배포하는 것은 어려운 과제이다.Pruning 후 Fine-tuning을 하는 것이 잠재적인 해결책이 될 수 있지만, VLM과 같은 멀티 모달에 대
19.Sparse High Rank Adapters
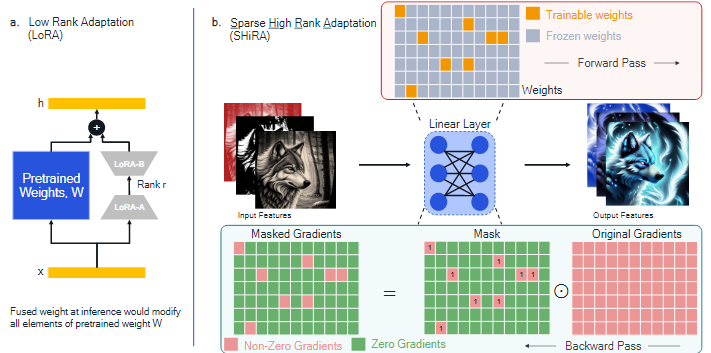
생성형 AI research에서 LoRA 기법이 크게 주목받고 있다.LoRA의 주요 장점은 pre-training된 모델과 결합할 수 있어서 inference 오버헤드는 피할 수 있다.하지만,adaptor를 빠르게 교체하기 어렵고Base 가중치와 결합하지 않을 경우,
20.Filter Images First, Generate Instructions Later: Pre-Instruction Data Selection for Visual Instruction Tuning

Abstract
21.CLIPLoss and Norm-Based Data Selection Methods for Multimodal Contrastive Learning

Abstract
22.Know “No” Better: A Data-Driven Approach for Enhancing Negation Awareness in CLIP
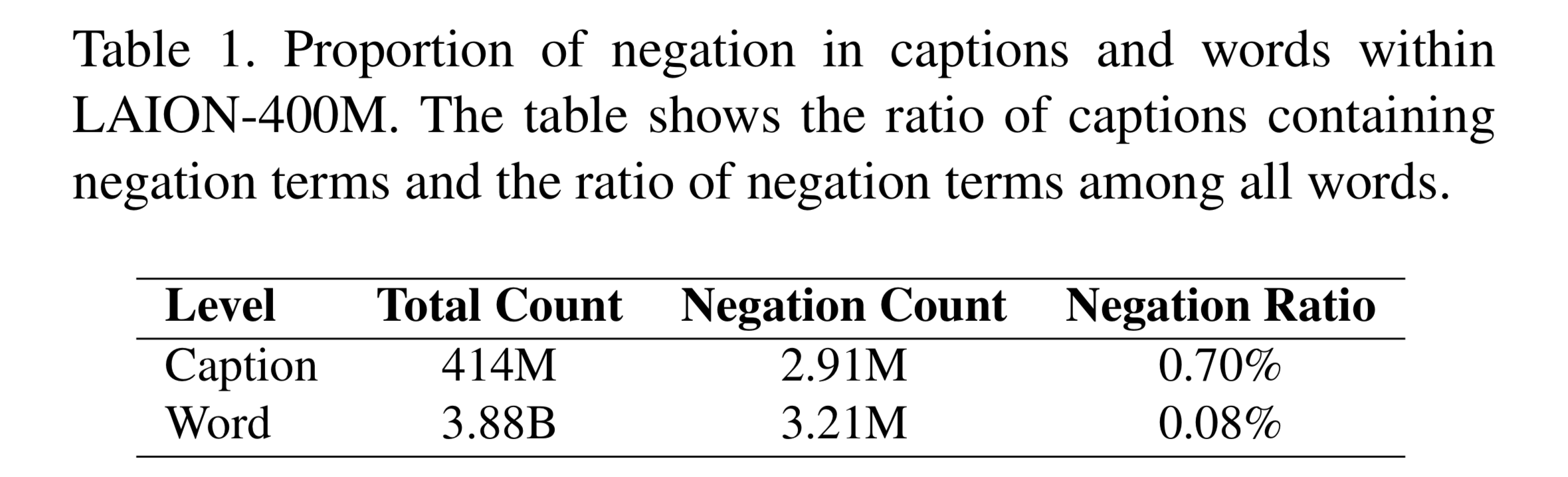
Abstract
23.A Simple and Effective Pruning Approach for Large Language Models
Abstract LLM의 규모가 커짐에 따라 성능을 유지하면서 크기는 줄이는 pruning이 방법으로 떠오르고 있다. 그러나, 기존 pruning들은 수십억개의 파라미터를 가진 LLM에는 거의 적합하지 않는 retrain을 하거나, 2차 gradient에 의존하는 등의
24.Variance-Based Pruning for Accelerating and Compressing Trained Networks
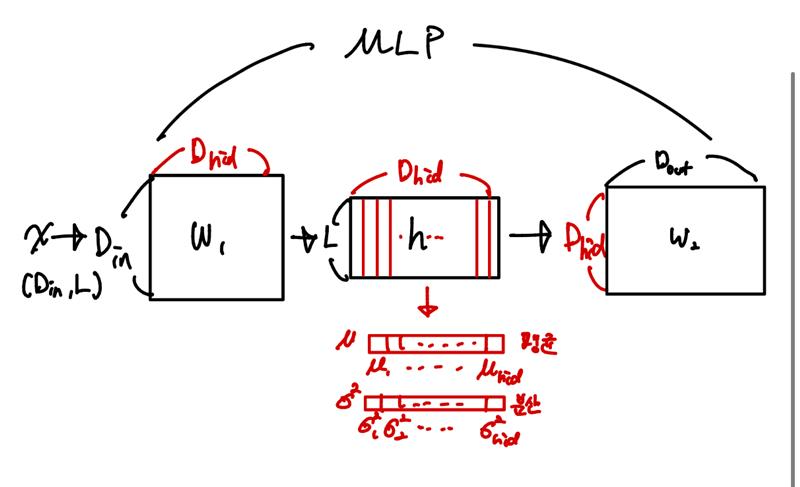
Structured pruning은 계산 비용 및 메모리 사용을 줄일 수 있지만, structured하게 잘라내어졌기 때문에 Retrain이 필요하여 cost가 많이 드는 경우가 많다.이를 해결하기 위해, One-shot structured pruning 방법인 var
25.DLP: Dynamic Layerwise Pruning in Large Language Models
주요 Pruning 기법들은 uniform layer-wise pruning에 의존하는데, 이는 높은 sparsity에서 심각한 성능 저하를 일으킨다.최근에는 다양한 layer의 기여도를 인식하여 non-uniform-layer-wise pruning을 연구하는데, 이
26.MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning
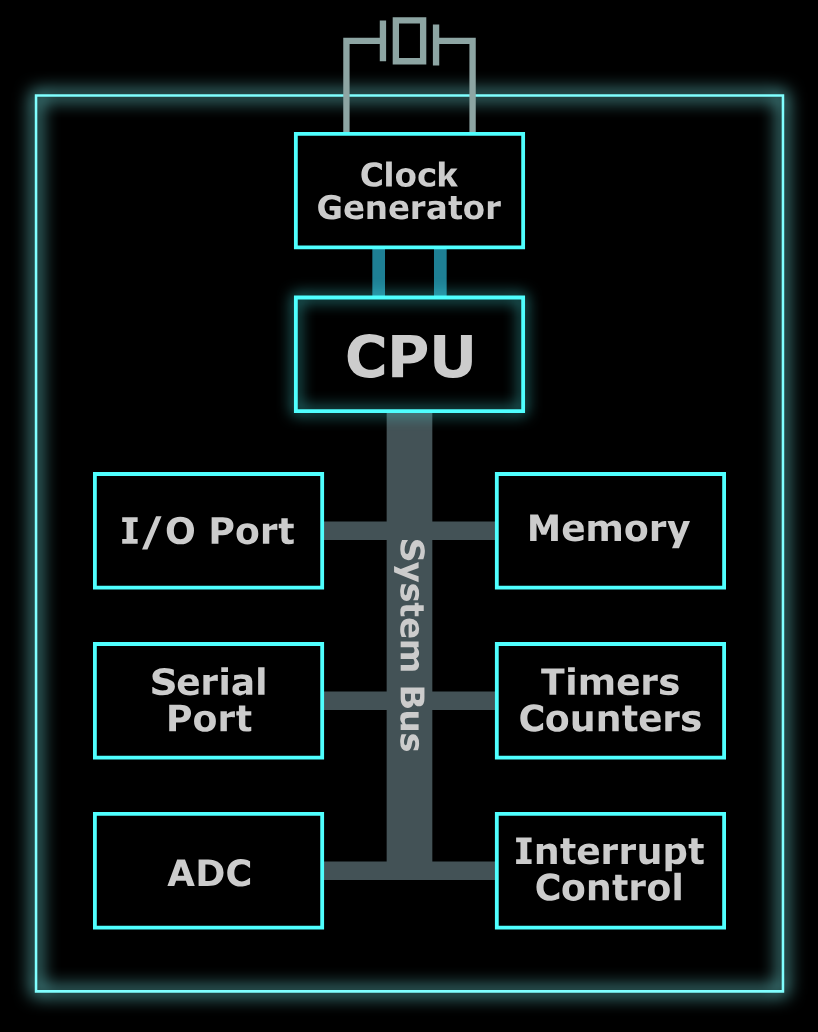
유튜브 참고 자료 : https://youtu.be/dcNk0urQsQM?si=6-rqgMvH7yPFEKrCIBM 블로그 자료 : https://www.ibm.com/kr-ko/think/topics/microcontrollerMCU(Micro Con
27.Designing Object Detection Models for TinyML: Foundations, Comparative Analysis, Challenges, and Emerging Solutions

최근 NAS의 발전으로 엄격한 하드웨어 기준의 제약 조건도 충족하도록 설계된 Hardware-aware NAS가 등장주로 task 성능 향상에 초점을 맞춘 기존의 NAS와 다르게 HNAS는 배포 제약 조건을 NAS의 탐색 프로세스에 통합하여 성능과 효율성을 기반으로 최