Abstract
CLIP은 Vision, Language를 연결하는 멀티 모달의 이해 능력을 크게 발전시켰지만, 부정적인 의미를 파악하지 못한다는 문제점이 존재한다.
이러한 문제의 원인을 파악한 결과, 부정적인 내용의 데이터의 부족으로 training된 것이 원인으로 추정된다.
이를 해결하기 위해 LLM을 이용하여 부정적인 내용을 포함하는 data generation파이프 라인을 도입하여 CLIP을 fine-tuning하는 NegationCLIP을 개발하였다.
또한 부정적인 표현의 이해에 대한 평가를 위한 벤치마크인 NegRefCOCOg를 제안한다.
1. Introduction
최근 VLM의 발전은 멀티모달 task에서 주목할 만한 성능을 달성하였다.
특히, CLIP은 영향력있는 모델로 떠오르며 CLIP을 base로 하는 후속 모델들의 기반이 되었다.
그러나, 이러한 후속 모델들은 CLIP encoder의 기능에 제약을 받기 때문에 CLIP의 robustness가 더욱 강조된다.
하지만, CLIP에는 부정적인 의미를 이해하지 못한다는 내재적인 한계가 존재하였으며 이를 정확하게 처리하려는 연구가 진행되었지만, 여전히 해결되지 못했다.
따라서, CLIP이 안정적으로 동작하기 위해서는 부정 표현에 대한 정확한 이해가 필수적이다.
본 논문의 실험에서는 CLIP이 부정적인 내용의 프롬프트의 이미를 이해하지 못하는 경우가 많다는 사실을 발견하였다.
CLIP의 pre-training data에 부정적인 내용이 포함된 caption이 제대로 표현되지 않았거나, Image와 Caption이 제대로 align되어 있지 않고 존재하여 모델의 부정표현 이해 능력을 저해하는 것으로 나타났다.
이러한 data의 한계를 완화하기 위해 LLM과 MLLM을 활용하여 부정적인 의미의 Caption 생성하고 Image와 정확하게 align되도록 두 가지 data generation 파이프라인을 제안한다.
- 문맥과 관련된 object의 부재에 따라 부정 표현을 생성
- Object의 존재 여부에 따라 부정 표현의 다양성을 확장
Contribution
- CLIP의 부정 표현 이해 능력의 한계가 pre-training data의 한계에서 비롯되었음을 찾아내었다.
- LLM과 MLLM을 활용하여 Image 속 맥락에 맞는 부정 표현을 generate하는 파이프라인을 개발하여 training data의 품질을 개선하였다.
- VLM의 부정 표현 이해 능력을 측정하기 위한 벤치마크인 NegRefCOCOg를 제안
- NegationCLIP이라는 이름의 부정 인식이 개선된 CLIP은 VLM의 task 전반에서 탁월한 성능을 발휘한다.
2. Negation : A Critical Challenge for CLIP
CLIP이 부정 표현 이해에 한계가 있음을 실험을 통해 입증하고, 이러한 한계의 원인을 파악한다.
2.1 Case Study : Exposing the Negation Issue
CLIP의 부정 표현 처리 능력을 평가하기 위해 얼굴 Image에 대한 40개의 binary속성이 포함된 CelebA dataset을 이용하여 이진 분류 실험을 수행하였다.
예를 들어, ‘안경’ 속성의 경우 안경을 쓴 사람의 사진과 안경을 쓰지 않은 사람의 사진과 같은 프롬프트를 생성하여 이미지가 주어졌을 때, 두 가지 중 올바른 프롬프트를 이미지와 일치시키는 정확도를 측정한다.
- 실험 결과
무작위로 추측해도 50%는 나오는 이진 분류 작업임에도 60.8%라는 정확도를 얻었으며, 이는 상당히 낮은 수치이다.
실험 결과를 통해 부정 표현 이해에서 CLIP의 Robustness를 강화하기 위한 개선의 필요성을 강조
2.2 Root Cause : Limited Negation in Training Data
이러한 문제의 원인을 CLIP의 pre-training data의 관점에서 접근하였다.
부정 표현의 존재 여부와 품질을 조사하기 위해 OpenCLIP과 같은 공개 CLIP모델에 널리 사용되는 dataset인 LAION-400M을 분석하였다.
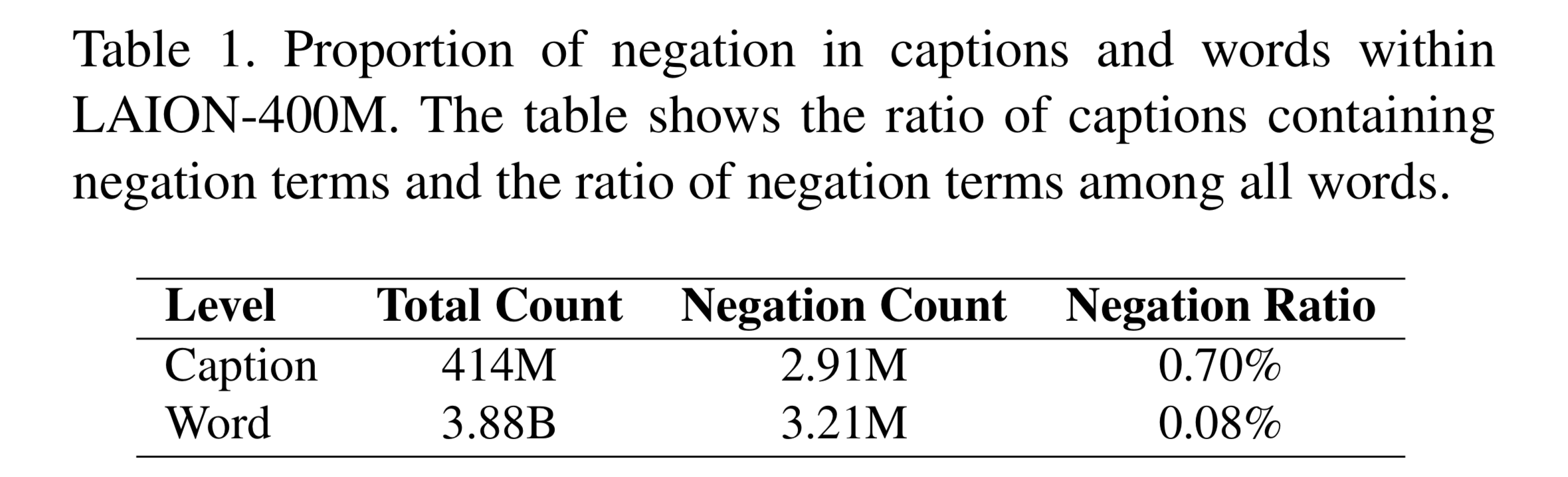
연구 결과에 따르면 LAION-400M의 caption중 약 0.704%만이 부정 표현 용어를 포함하고 있는 것으로 나타났으며, 전체 단어 수에서 차지하는 비율은 0.083%에 불과하다는 결과를 얻었다.

또한, Caption의 부정 표현이 있더라도 Image의 시각적인 맥락과 일치하지 않는 경우가 많아 학습할 수 있는 의미있는 정보를 제공하지 못한다.
이는 VLM의 training에 사용되는 Image-Text pair 데이터의 특성때문일 수 있다.
Image에 대한 caption은 자연스럽게 Image의 내용을 설명하는 데 초점을 맞추는 데 , 없는 것을 명시하기 보단 보이는 것을 설명하는 데 초점을 맞추기 때문에 부정 표현에 대한 노출이 적을 수밖에 없다.
3. Negation-Inclusive Data Generation
LLM과 MLLM을 사용하는 2가지의 Date generation 파이프라인을 설명한 다음 NegRefCOCOg 벤치마크를 제안한다.
3.1 Generating Negation from Object Absence
기존의 잘 align된 Image-Caption dataset을 활용하여 새로운 주석을 추가할 필요 없이 활용도를 극대화한다.
Object가 Image에 존재할 것 같지만 실제로는 존재하지 않는 그럴듯한 Object를 기반으로 부정 표현을 자연스럽게 통합시켜 기존의 Caption을 보강한다.
Object가 Image에 존재 여부는 MLLM을 통해 정확하게 판단할 수 있다.
이 파이프라인의 접근 방식은
- LLM을 사용하여 그럴듯한 Object를 식별하고 해당 Image의 caption을 제공한 뒤에
- MLLM을 이용하여 Image에 그럴듯한 object가 없는지 확인한다.
- Object가 없음이 확인된 경우, LLM을 사용하여 Caption을 보강하며 부정 표현이 없었던 경우 자연스럽게 부정 표현을 통합함으로써 training data를 보강한다.
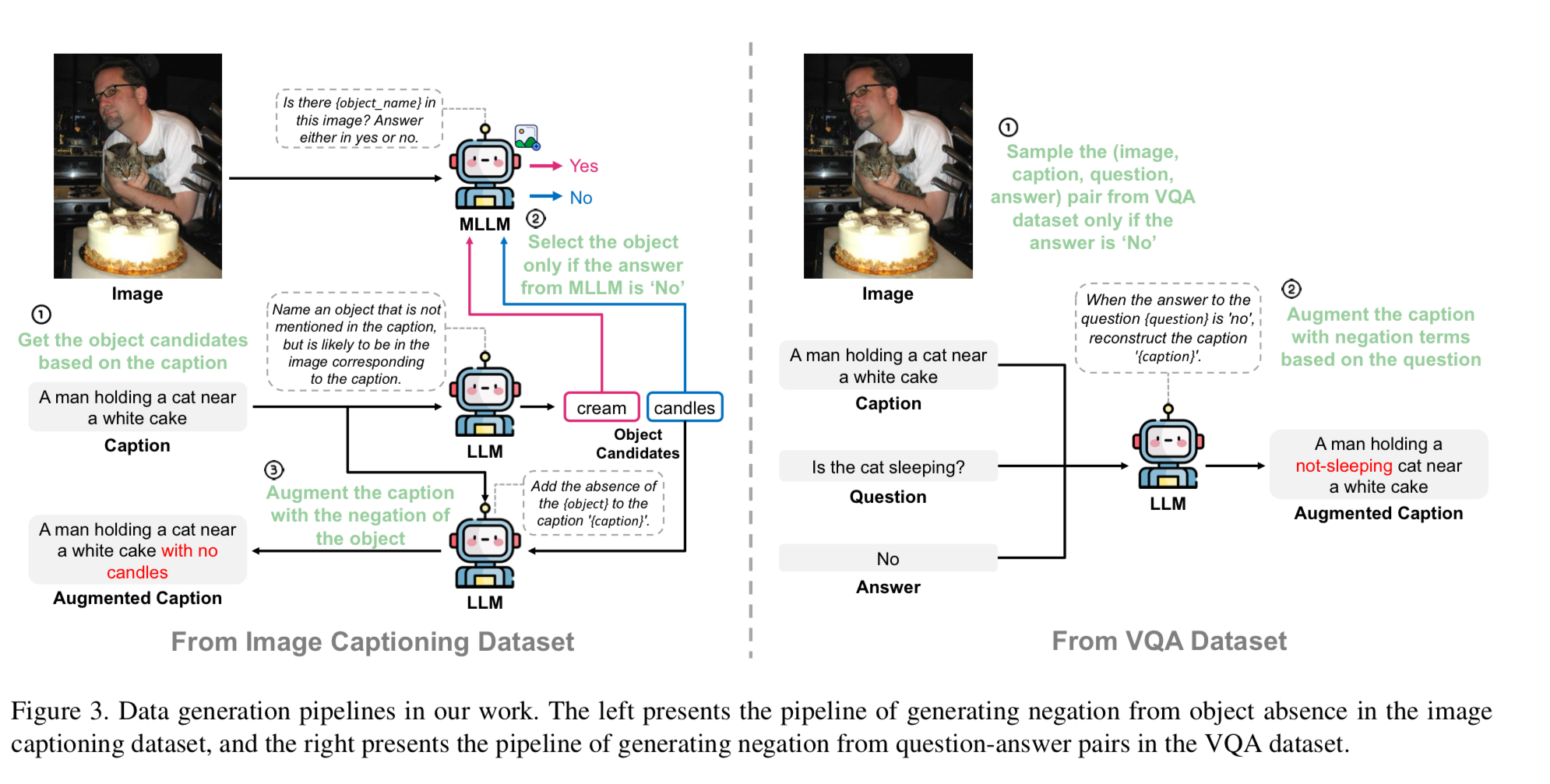
1. Caption에서 그럴듯한 object추출하기
각각의 Image-caption pair data에 대해, 먼저 Caption만 LLM에 제공하여 caption에 언급되지는 않았지만 Image에 존재할 가능성이 있는 그럴듯한 object를 식별한다.
2. MLLM으로 object의 존재 여부 확인
1번 과정은 Image를 고려하지 않기 때문에 식별한 그럴듯한 object가 실제로 Image에 존재할 가능성이 있다.
이러한 object의 존재 여부를 확인하기 위해 MLLM에 Image를 제공하고 식별된 object의 존재 여부를 묻는다.
3. 부정 표현으로 caption 보강
MLLM이 없다고 판단한 object의 경우, LLM을 사용하여 누락된 object에 대한 정보를 부정 표현으로 추가하여 기존의 caption을 보강한다.
3.2 Expanding Diversity of Negation
위의 파이프라인은 효과적이지만 object와 관련된 부정표현으로만 제한된다.
Data를 더욱 풍부하게 하기 위해 VQA(Visual Question Answering) dataset에서 가져온 data를 활용하는 보조 파이프라인을 사용한다.
다양한 Question-Answer pair를 활용하여 부정 표현의 다양성을 도입한다.
이러한 pair는 object의 존재뿐만 아니라 수행 중인 task 및 object가 가진 속성과 같은 측면을 포함하므로, 더 광범위한 Image에 부정 표현을 통합할 수 있다.
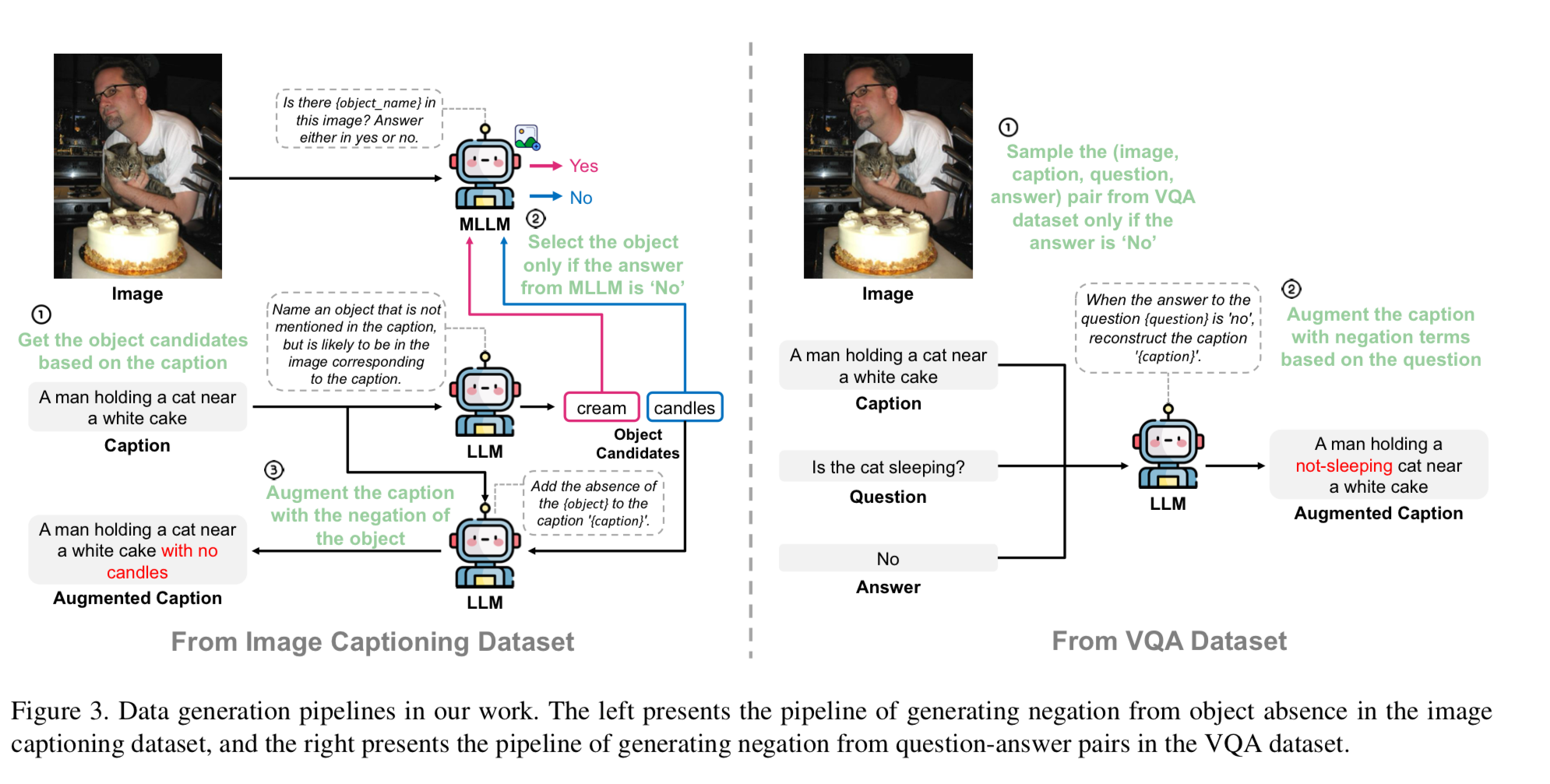
1. “No” data 선택
VQA dataset에서 답변이 ”No”인 Image-Question-Answer를 식별한다.
2. 부정 표현으로 caption 보강
선택한 각 Image와 원본 caption에 대해 LLM을 사용하여 question과 해당 answer에 따라 부정 표현으로 caption을 보강한다.
3.3 NegRefCOCOg Benchmark Proposal
기존의 부정 표현을 위한 벤치마크인 VALSE는 “No”만을 유일한 부정 표현으로 삼고 object의 존재 여부에만 초점을 맞추고 있기 때문에 NegRefCOCOg를 제안하여 이러한 한계를 해결한다.
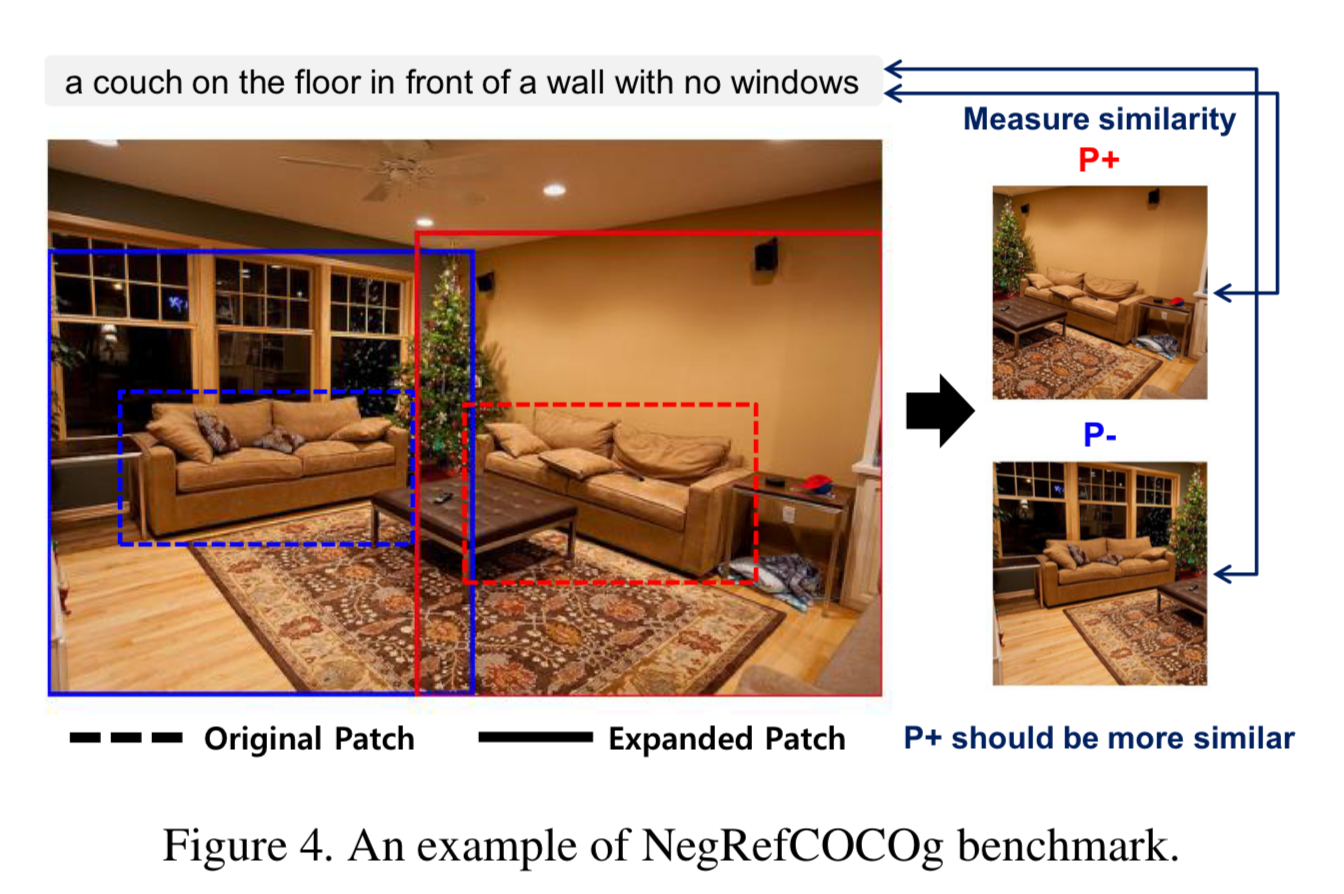
“No”, “Not”, “Without”과 같은 다양한 부정 표현을 포함하고 있으며, object의 존재 외에도 동작과 속성을 포함하고 있다.
