Abstract
LLM의 규모가 커짐에 따라 성능을 유지하면서 크기는 줄이는 pruning이 방법으로 떠오르고 있다.
그러나, 기존 pruning들은 수십억개의 파라미터를 가진 LLM에는 거의 적합하지 않는 retrain을 하거나, 2차 gradient에 의존하는 등의 계산 비용이 크다는 문제가 있다.
본 논문에서는 pre-train된 LLM에서 sparsity를 유도하도록 설계된 효과적인 pruning방법인 Wanda를 소개한다.
이 접근 방식은 Input activation에 가중치를 곱하여 중요도를 측정해 pruning한다.
Wanda는 retrain이나 weight update가 필요하지 않으며, pruning된 LLM을 그대로 사용할 수 있다.
1. Introduction
LLM은 NLP분야에서 놀라운 성능을 보여주고 있지만, 수식억 개의 파라미터가 포함되기 때문에 상당한 리소스를 필요로 한다.
LLM의 대중화를 위해 높은 계산 비용을 완화하고자 하는 노력이 지금까지 있어왔지만, 지금까지 주목할만한 대부분의 방법은 Quantization에 집중되어 왔다.
Pruning은 모델 내 특정 가중치를 제거하여 모델의 크기를 줄이는 것으로 Model compression에 있어서 상대적으로 덜 주목되어 왔다.
기존의 pruning방법을 살펴보면 그 이유를 알 수 있다.
- Pruning 후 retrain
- Iterative한 과정
- Randomly한 초기화
이러한 방법들은 엄청난 양의 리소스를 요구하며 비효율적이다.
본 논문에서는 Wanda(Weight and Activation)라는 간단하고 효과적인 접근 방식을 도입하여 이 문제를 해결한다.
이 기법은 가중치를 update할 필요없이 LLM높은 수준의 spasity를 갖게 한다.
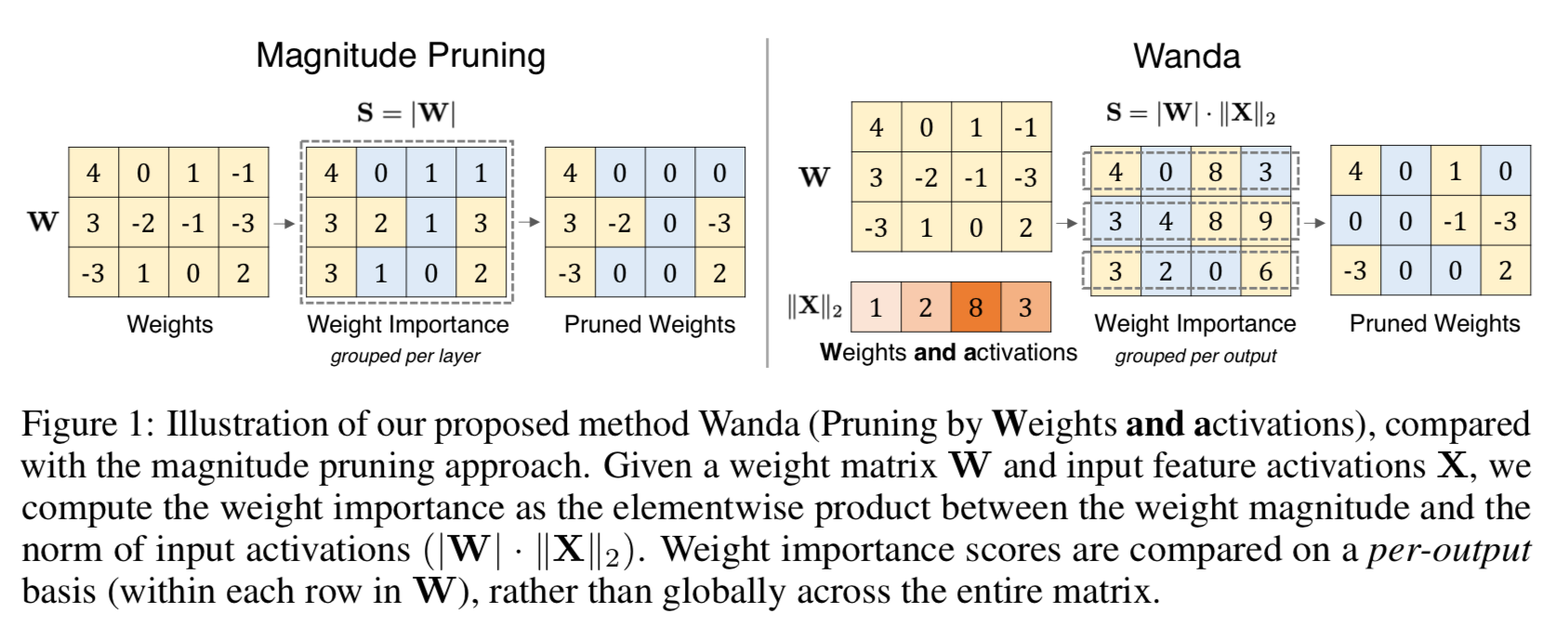
Input activation으로 기존의 Weight magnitude 기반의 pruning metric을 보강하는 것이 가중치의 importance를 평가하는 데 매우 효과적임을 발견하였다.
2. Preliminaries
Magnitude pruning
신경망의 sparsity를 유도하기 위한 표준 pruning기법으로, 개별 weight의 크기에 따라 제거하며, 특정 임계값 이하의 weight를 가진 weight는 제거된다.
이 임계값은 local(layer-wise)로 비교되거나 global하게 비교되어 결정된다.
매우 단순한 method임에도 높은 sparsity를 갖게 하기 위해 사용되어 왔으며, 현재도 pruning의 강력한 기준 접근법으로 사용되고 있다.
Emergent Large Magnitude Features
Transformer 기반의 LLM에서 큰 규모의 특징이 관찰되었다.
LLM이 특정 규모(약 6B)에 도달하면 일부 hidden state의 일부 feature들만 유난히 큰 magnitude의 특징들이 나타난다는 것이다.
- 이는 단순한 outlier가 아닌, 모델의 언어 예측 성능에 매우 중요한 역할을 하는 핵심 특징들임이 밝혀졌다.
3. Wanda : Pruning by Weights And Activations
A Motivating Example
-
2개의 Input과 weight가 있는 뉴런이 있다고 가정
-
이제 출력의 변화를 최소화하면서 제거할 weight를 하나만 선택하는 것을 목표라 가정
Input feature인 과 의 크기가 비슷한 경우 magnitude pruning에 따라 을 제거하는 것이 좋은 전략이 될 수 있다
하지만, LLM에서 관찰된 바와 같이, 두 Input feature의 크기가 매우 다를 수 있다.
이 경우 가중치 을 제거하는 것보다 가중치 를 제거해야 한다.
이 예시는 뉴런의 output을 결정하는 데 가중치 크기만큼이나 중요한 역할을 할 수 있는 Input activation을 고려하지 않는다는 weight magnitude pruning의 한계를 보여준다.
따라서, LLM을 pruning할 때, 내부에서 새롭게 발견되는 큰 크기의 feature들을 고려할 때, Weight magnitude의 단순성을 유지하면서 이러한 한계를 처리할 수 있도록 설계된 pruning metric을 제안한다.
Pruning metric
가중치 W의 모양()을 가진 linear layer를 생각해본다.
LLM의 경우, 이 linear layer는 () 형태의 Input activation 를 받으며, 은 각각 batch, sequence 차원을 의미한다.
각 개별 weight에 대해 weight의 크기와 해당 Input activation의 곱으로 importance를 평가할 것을 제안한다.
