MCU란?
유튜브 참고 자료 : https://youtu.be/dcNk0urQsQM?si=6-rqgMvH7yPFEKrC
IBM 블로그 자료 : https://www.ibm.com/kr-ko/think/topics/microcontroller
MCU(Micro Controller Unit)
하나의 칩 안에 CPU + 메모리 + 주변 장치가 모두 들어있는 소형 컴퓨터
이미지 출처 : https://datacapturecontrol.com/articles/io-devices/microcontrollers/overview
- 작은 컴퓨터를 하나의 칩으로 만든 것으로 생각하면 직관적
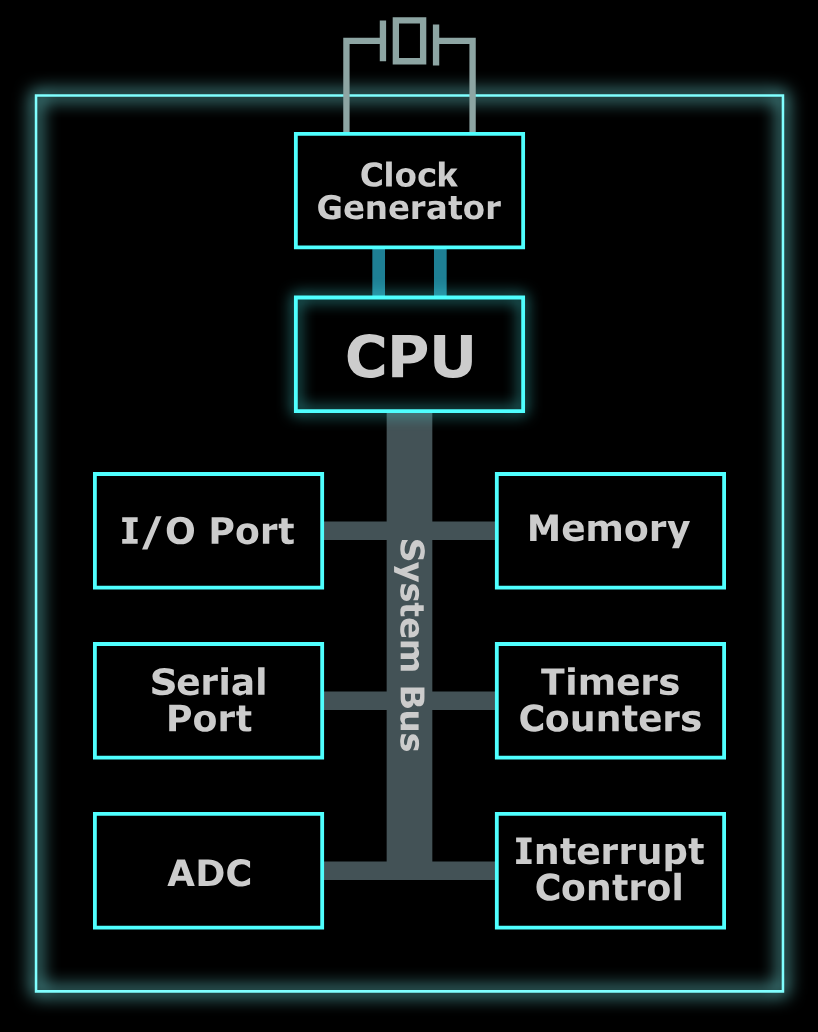
MCU 구성 요소
-
CPU (중앙처리장치)
- 컴퓨터의 두뇌라고도 불리며, 명령을 실행하고 작업을 제어하는 핵심 구성 요소
-
메모리
- 프로그램 메모리와 달리 시스템 전원이 끊기면 손실될 수 있는 임시 데이터를 저장하는 휘발성 메모리(RAM)
(RAM : 프로그램이 실행될 때 쓰는 작업공간)- SRAM : 작지만 빨라야 하는 Cache
- DRAM : 크게 많이 필요한 메인 메모리
- 전원이 꺼져도 유지되는 프로그램 코드를 저장하는 비휘발성 Flash 메모리가 포함되어 있음
- 프로그램 메모리와 달리 시스템 전원이 끊기면 손실될 수 있는 임시 데이터를 저장하는 휘발성 메모리(RAM)
-
주변 장치
- 사용 목적에 따라 타이머/카운터(시간 측정, PWM 생성), ADC(아날로그 -> 디지털 변환 센서), I/O 인터페이스, 통신 프로토콜(UART) 등 포함될 수 있음
Micro Controller vs Micro Processor
-
MCU : CPU + 메모리 + 주변 장치가 한 칩에 다 들어있는 완성형 제어용 컴퓨터
칩 하나만 있으면 동작 가능 (All-in-one)
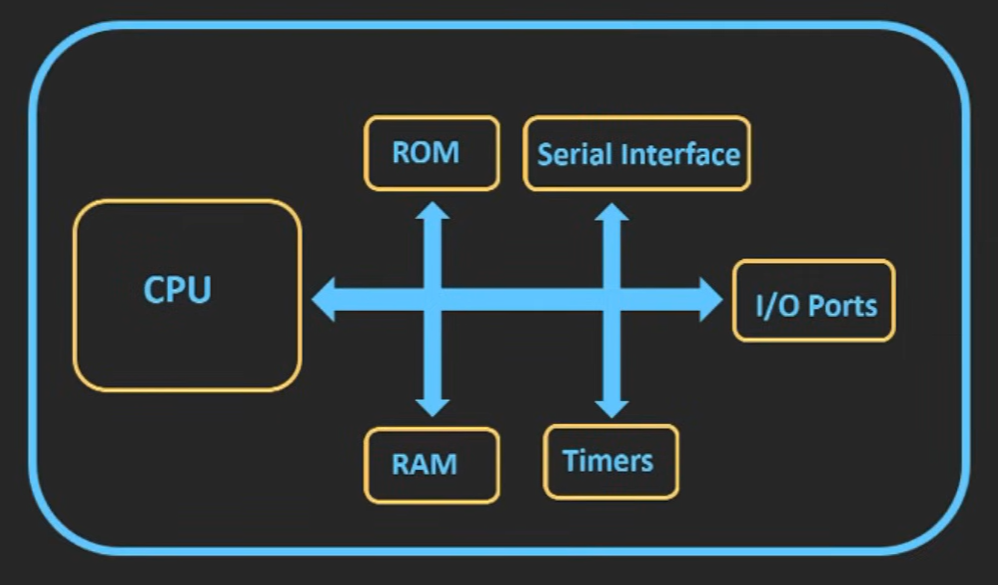
사진 출처 : https://www.youtube.com/watch?v=dcNk0urQsQM -
MPU : 연산만 담당하는 CPU 칩 (메모리, 주변 장치는 외부에 따로 필요)
시스템 동작에 필요한 장치들은 전부 외부에 있어 보드 전체가 필요(CPU-only)
사진 출처 : https://www.youtube.com/watch?v=dcNk0urQsQM
적용 분야 차이
-
MCU : "특정하게 정해진 일"을 안정적으로 반복하는 임베디드 시스템의 핵심
디지털 카메라, 세탁기, 리모컨 등 수행될 작업이 미리 정의되어 있는 장치에서 사용

MCU는 입력값을 바탕으로 몇 가지 처리를 수행하고 그 결과를 출력함
여기서 입력은 사용자 입력일 수도 있고, 센서에서 오는 입력일 수도 있음
- 예를 들어, 전자레인지의 경우 출력과 시간을 설정하면 음식이 조리된 상태로 나옴
-
MPU : PC나 노트북과 같이 "범용적인 컴퓨팅" 중심으로 사용
게임, 웹, 사진 편집, 문서 작업 등 MPU는 기본적으로 작업이 미리 정의되지 않은 복잡한 응용 분야에서 사용
MCU의 병목 현상
MCU에서의 memory bottleneck은 CPU는 일할 준비가 됐는데, 메모리(Flash/SRAM)에서 데이터, 코드를 가져오거나 저장하는 속도/대역폭이 부족해서 CPU가 기다리는 현상을 말함
주요 원인
1. Flash 메모리에서 실행할 때 느림
- Clock이란 MCU 내부 회로가 한 번 동작하는 박자로, CPU는 클럭에 맞춰 명령어를 한 단계씩 실행하고, 주변 장치도 클럭 기준으로 동작
- MCU에서 코드는 보통 Flash 메모리에 있고, CPU는 Flash에서 명령어를 가져오며 실행하는데, Flash 메모리는 SRAM보다 느리다.
CPU가 100MHz로 동작한다고 치면, 1사이클이 10ns인데, Flash가 명령어를 내주는데 30ns만큼 걸린다면, CPU는 10ns마다 명령어를 읽고 쓰려는데, Flash에서 30ns가 걸려서 CPU에서 Flash에 접근하기 위해 wait state가 발생하며 CPU가 기다리게 됨
2. SRAM 용량/대역폭 부족
- Buffer란 데이터를 잠깐 저장해두는 임시 공간인데, CPU에서 데이터를 처리하는 속도와 데이터가 들어오는 속도가 완벽하게 같지 않기 때문에, 중간에 잠깐 쌓아둘 통이 필요한데, 이 통이 Buffer이다.
MCU의 SRAM은 일반적인 PC에서 사용되는 SRAM보다 용량이 더 작은데, CPU가 다른 작업을 하는 동안 데이터가 계속 들어오면 buffer가 금방 차버려, 데이터가 유실될 수 있음
작은 buffer로 인해, 데이터를 쪼개서 자주 처리해야 해서, 오버헤드가 늘어남
3. CPU가 I/O 복사를 하느라 바쁨
- 주변(입출력 장치 I/O) 장치로부터 CPU가 처리해야 할 데이터들이 계속 들어오게 되는데, 그 데이터를 RAM에 쌓아야 한다.(MCU에서 말하는 RAM은 주로 SRAM)
들어오는 데이터를 RAM에 운반하는 일을 CPU하게 하게 되면, CPU가 할당하는 시간의 대부분이 운반에 사용되어서 CPU가 해야할 계산 작업을 못함
그래서 등장한 게 DMA이다. 현대 MCU에는 DMA를 지원(너무 작은 MCU는 없을 수도)
- DMA는 주변장치와 RAM 사이에서 데이터를 운반하는 일을 CPU대신 해주는 하드웨어
4. 버스/주변 장치가 메모리를 공유해서 충돌
- MCU 내부에는 데이터가 다니는 길인 버스가 있는데, CPU가 RAM을 읽고 쓰는 것도 이 버스를 쓰고, DMA가 데이터를 RAM으로 옮기는 것이 이 버스를 사용한다.
CPU가 RAM에서 배열을 읽고 쓰는 중에 DMA가 데이터를 RAM에 쓰려고 하면 둘이 같은 버스를 놓고 경쟁하며 한 쪽은 기다려야 하는 상황 발생
Abstract
MCU에서 초소형 딥러닝을 구현하는 것은 제한된 메모리 크기로 인해 어려운 과제이다.
메모리 병목 현상은 CNN 설계의 불균형한 메모리 분포로 인해 발생하는데,
CNN은 초반 layer에서 feature map의 HxW가 아직 크기 때문에 초반 몇 블록은 activation이 매우 커 메모리 사용량이 폭증한다.
- CNN에서는 Conv 출력 feature map 자체를 activation이라고 부름
CNN의 activation 메모리 :
- 초반 몇 개의 block의 peak memory가 나머지 블록보다 크다
초반 메모리가 더 큰 이유
- CNN의 activation() 텐서에서 layer가 깊어질수록 와 의 크기가 감소하는 정도가 가 늘어나는 정도보다 크기 때문에 activation memory가 점점 줄어듦
- 예를 들어 를 2배 줄이면 는 4배 감소하지만, C를 2배 늘리면 최종적으로 는 2배 감소하게 된다.
이 문제를 해결하기 위해 이 논문에서는 feature map의 작은 공간 영역에서만 작동하고 peak memory를 크게 줄이는 일반적인 패치별 추론 스케줄링을 제안한다.
하지만, 이 방법을 사용하면 패치와 계산 오버헤드가 겹치게 되어, receptive field와 FLOP을 후반 단계로 이동하고 계산 오버헤드를 줄이기 위해 receptive field 재분배를 추가로 제안한다.
Introduction
MCU와 같은 초소형 하드웨어에 기반한 IoT 디바이스는 어디에나 사용되고 있다.
이러한 초소형 하드웨어에 딥러닝 모델을 배포하면 인공지능의 대중화를 실현할 수 있으나, 초소형 하드웨어는 모바일 딥러닝과 다르게 메모리의 한계가 존재한다.
일반적인 MCU는 512KB보다 작은 SRAM을 갖고 있어, 대부분의 딥러닝 모델을 배포하기에 너무 작다.
Pruning이나 Quantization과 같은 model compression은 모델의 매개변수 수와 FLOP을 줄이는 데 초점을 맞출 뿐, 메모리 병목 현상을 해결하지는 못한다.
하드웨어적인 경량화까진 해결X
메모리 용량이 부족하면 CNN에서 feature map의 크기가 제한되어 작은 이미지밖에 처리할 수 없다.
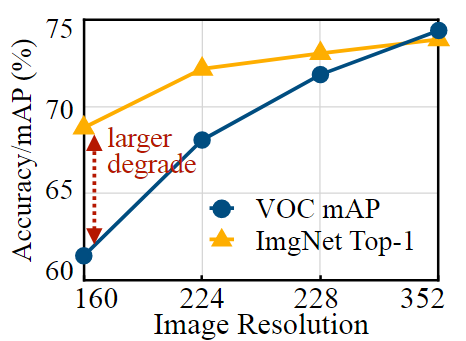
이는 image classification과 같은 단순 작업에는 적합할 수 있으나, Object detection과 같은 밀도 높은 reasoning task에는 적합하지 않다.
Image classification보다 Object detection에서 이미지의 해상도가 accuracy에 매우 민감함을 보여주는 그래프
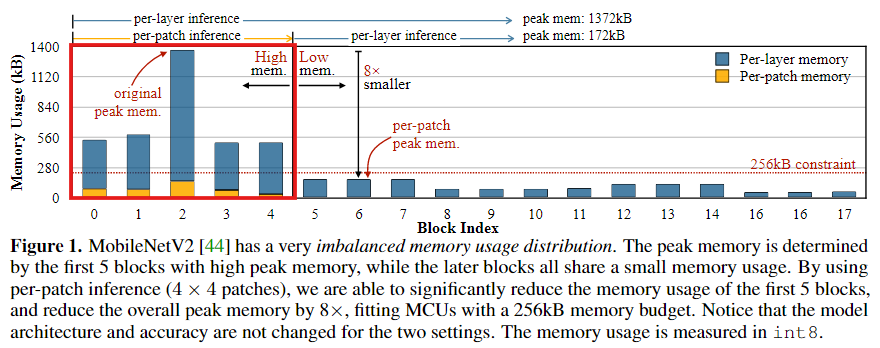
효율적인 딥러닝 모델 설계를 위해 각 block에서의 메모리 사용량을 분석한 결과, 메모리 사용량 분포가 매우 불균형함을 발견하였다.
MobileNetV2에서 처음 5개의 block에서만 높은 peak memory(450KB 이상)을 사용하여 전체 네트워크의 메모리 병목 현상이 발생함을 발견하였다.
- Int 8 양자화 후 측정
나머지 13개의 block에서는 메모리 사용량이 적어 256KB의 MCU 메모리에 쉽게 맞출 수 있었다.
초기 5개 block에서의 메모리 사용량이 나머지 block보다 8배 이상 더 높다.
- 이 문제를 해결하면 전체 peak memory를 8배까지 줄일 수 있는 최적화에서의 큰 가능성 존재
본 논문에서는 이러한 문제를 해결하기 위해 MCUNetV2를 제안한다.
먼저 메모리를 많이 사용하는 CNN의 초기 Block에 patch별 실행 순서를 제안한다.
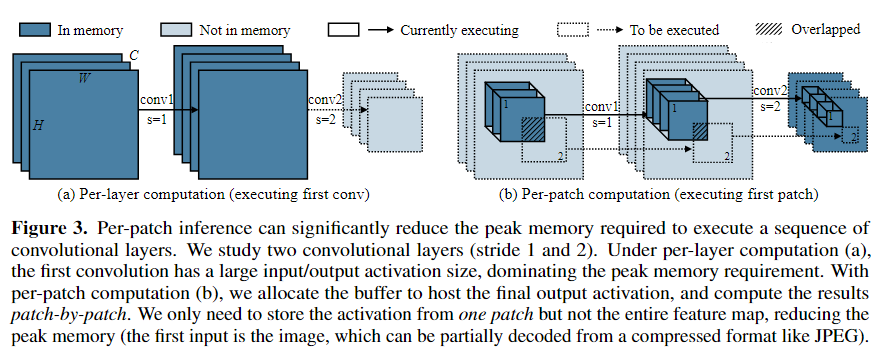
기존의 전체 feature map를 처리하던 방법과 달리 feature map의 작은 공간 영역에서 한 번에 작동한다.
- 작은 patch의 feature만 저장하면 되므로 peak memory를 크게 줄일 수 있어, 더 큰 해상도의 image를 처리할 수 있다.
하지만, peak memory가 줄어들면 계산 오버헤드가 발생하는데, 겹치지 않는 output patch를 계산하려면 입력 image patch를 겹쳐야 하므로 계산이 반복적으로 이루어지게 된다.
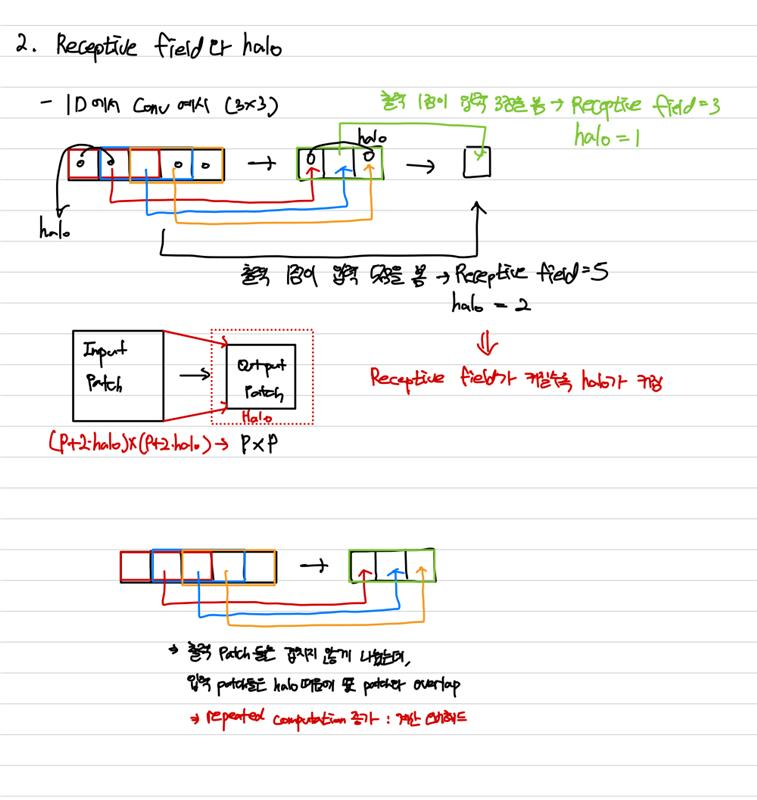
오버헤드는 초기 block에서 receptive field의 크기와 관계가 있다.
Receptive field의 크기가 클수록 입력 patch가 더 커져 더 많은 overlap이 발생한다.
그래서 계산 오버헤드를 줄이기 위해 receptive field의 재분배를 제안한다.
이렇게 하면 성능에 영향을 주지 않으면서 overlap으로 인한 계산 오버헤드를 줄일 수 있다.
Contribution
1. CNN의 메모리 사용 패턴을 분석하여 불균형한 메모리 분포로 인한 최적화의 가능성을 발견
2. Patch기반 추론 스케줄링을 제안하여 CNN모델 실행에 필요한 peak memory를 줄이고 계산 오버헤드를 최소화하기 위한 receptive field의 재분배를 함께 제안
2. Understanding the Memory Bottleneck of Tiny Deep Learning
CNN 모델의 메모리 병목 현상을 체계적으로 분석
Imbalanced memory distribution
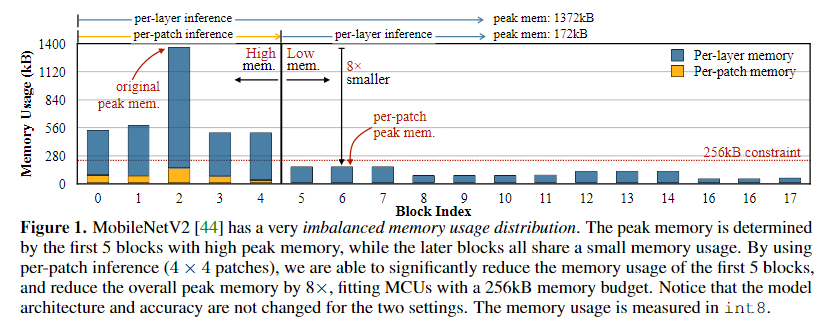
위 Figure는 MoblieNetV2의 Block당 peak memory 사용량을 제공한다.
Figure에서 볼 수 있듯이 불균형한 메모리 사용량 분포의 명확한 패턴을 관찰할 수 있다.
- 처음 5개 block은 peak memory가 커서 MCU의 메모리 제약 조건을 초과하는 반면, 나머지 13개 block은 256KB 메모리 제약 조건에 쉽게 맞는다.
- 세 번째 block은 나머지 block들보다 메모리 사용량이 8배 이상 더 커서 메모리 병목 현상이 발생한다.
이러한 현상이 여러 CNN 백본에서 공통적으로 나타나는 것을 확인하였다.
초반 메모리가 더 큰 이유
- CNN의 activation() 텐서에서 layer가 깊어질수록 와 의 크기가 감소하는 정도가 가 늘어나는 정도보다 크기 때문에 activation memory가 점점 줄어듦
- 예를 들어 를 2배 줄이면 는 4배 감소하지만, C를 2배 늘리면 최종적으로 는 2배 감소하게 된다.
Challenges and opportunities
불균형한 메모리 사용 분포는 MCU에서 실행할 수 있는 모델 성능과 이미지 해상도를 크게 제한한다.
초기 메모리의 병목현상으로 인해, 대부분의 block에서 이미 적은 메모리를 사용하고 있음에도 불구하고 전체 모델의 크기를 축소해야한다.
또한, 고해상도 입력으로 인해 초기 peak memory가 커지기 때문에 해상도에 민감한 task(예 : Object detection)을 수행하기 어렵다.
- Input channel : 3
- Output channel : 32
- Stride : 2
MoblieNetV2의 첫 번째 Conv layer를 224 224의 이미지에서 실행하려면 int8로 quantization하더라도 의 메모리가 필요하므로 MCU에 장착할 수 없다.
초기 메모리가 병목되는 부분을 우회할 수 있는 방법을 찾을 수 있다면 전체 모델의 peak memory를 크게 줄일 수 있는 최적화에 대한 가능성을 남길 수 있다.
3. MCUNetV2: Memory-Efficient Patch-based Inference
3.1 Breaking the Memory Bottleneck with Patch-based Inference
Patch 기반의 inference로 초기 layer의 메모리 병목 현상 해결을 제안한다.
기존의 딥러닝 inference 프레임워크는 layer-by-layer 실행을 사용한다.
각 Conv layer에 대해 inference 라이브러리는 먼저 SRAM에
- input activation(입력하는 feature map의 메모리)
- output activation(출력되는 feature map의 메모리)의 버퍼를 할당하고,
전체 layer 계산이 완료된 후 input activation에 대한 버퍼를 해제한다.다음 layer에서 출력된 activation은 input이 됨
하지만, CNN의 초기 block에서 MCU의 SRAM에 layer마다 input과 output에 대한 activation 크기만큼의 버퍼를 할당하는 것은 너무 크다.
patch 기반 inference는 메모리 병목이 일어나는 초기 단계를 patch단위로 실행한다. 이는 전체 feature map의 영역보다 훨씬 작은 영역에서만 모델을 실행하기 때문에 메모리 사용량을 효과적으로 줄일 수 있다.
특정 병목 단계 이후부터는 다시 layer-by-layer 방식으로 실행된다.
Layer-by-layer 방식
첫 번째 Conv layer에 대해 input activation과 output activation의 크기가 커서 memory peak가 높다.
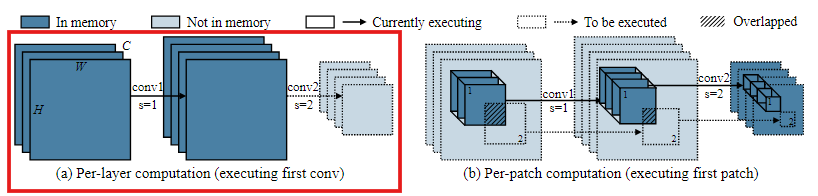
Patch-by-patch 방식
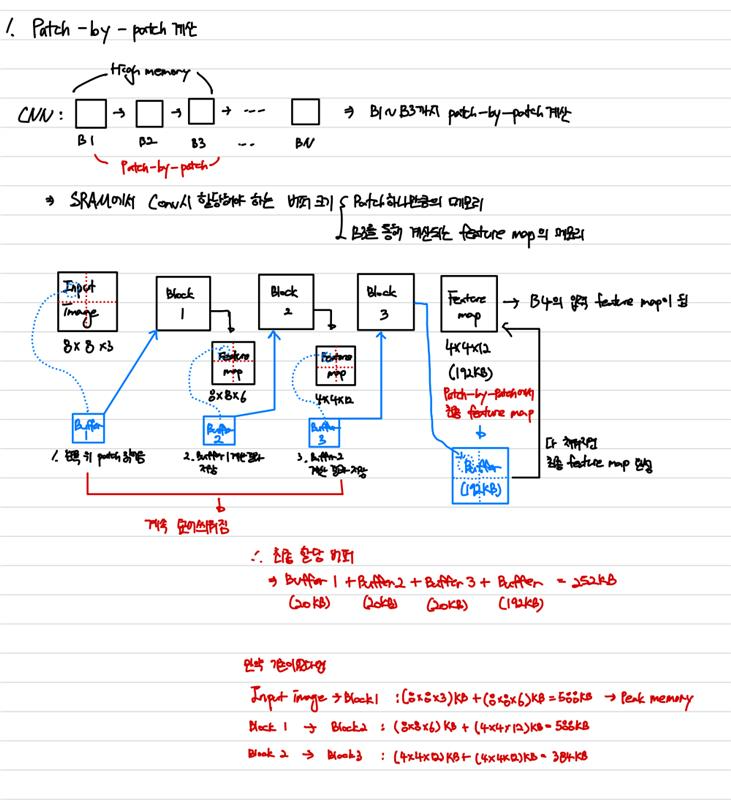
최종 output activation에 대한 버퍼를 할당하고, 이전까지는 전부 patch별로 값을 계산하여, 전체 activation에 대한 memory대신 하나의 patch에서의 activation값만 저장하면 된다.어떻게 patch의 메모리를 알고 미리 할당?
- MCU inference엔진인 TinyEngine은 모델 구조가 정해지면 각 layer내 텐서의 크기를 사전에 미리 계산할 수 있다.
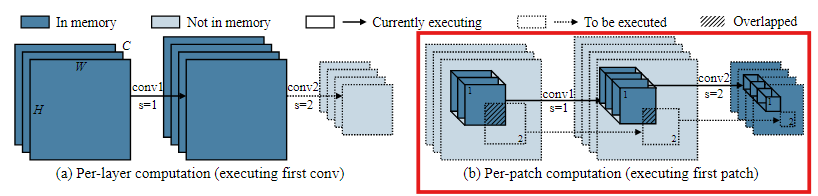
Computation overhead
상당한 메모리 절약은 계산 오버헤드를 대가로 한다.
Layer-by-layer와 동일한 output을 얻기 위해, Output activation에서 patch를 overlap되지 않게 나누지만, 각 output patch에 대응되는 입력 patch에서는 overlap되는 영역이 생긴다.
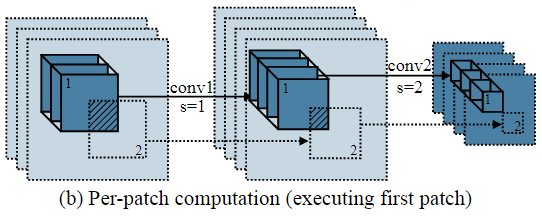
이는 kernel size가 1을 초과하는 conv filter가 receptive field를 증가시키는 데 기여하기 때문이다.
이러한 반복 계산은 최적의 하이퍼 파라미터를 선택하더라도, 10~17%의 계산 오버헤드를 증가시킬 수 있으며, 이는 저전력 엣지 디바이스에서 적절하지 않다.
3.2 Reducing Computation Overhead by Redistributing the Receptive Field
계산 오버헤드는 patch-by-patch에서 receptive field와 관련있다.
Receptive field가 클수록 output patch를 계산하기 위해 실제로 읽어야 하는 input patch의 크기가 커지기 때문에 input patch간 겹치는 영역이 커지고 계산이 반복된다.

계산 오버헤드를 줄이기 위해 CNN의 receptive field를 재분배하는 것을 제안한다.
- Patch-by-patch 단계의 receptive field 크기를 줄이고
- 후반 단계의 receptive field 크기를 늘리는 것이다.
초반의 receptive field를 줄이면 각 input patch의 크기와 반복 계산을 줄이는 데 도움이 된다.
하지만, 전체 receptive field가 작아지면 일부 task의 성능이 저하될 수 있다.
이에 대한 해결 방안으로 기존 MoblieNetV2를 기반으로 하여 아키텍처를 수정하였다.
- MB 1 커널을 넣어서 채널수는 유지하면서도 주변 픽셀값을 보지 않아 공간적으로 RF를 키우지 않음
- MB1 1x1에서 1은 블록 내부에서 채널 C를 1 x C로 유지하여 1x1 conv를 수행한다는 뜻
- MB6 3×3은 채널 C를 6 x C로 확장하여 3x3 conv를 수행한다는 뜻
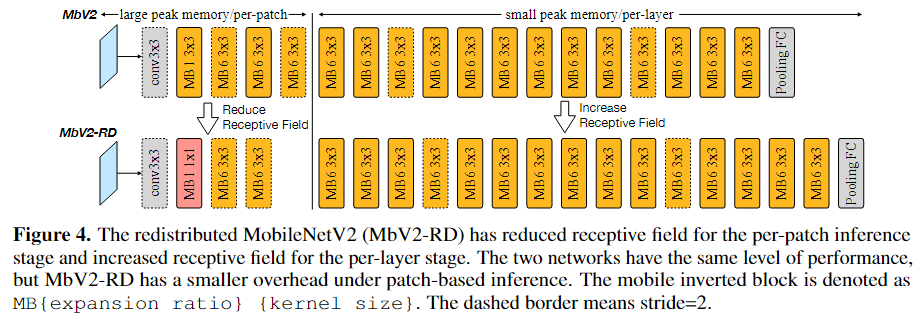
Patch-by-patch단계에서 더 작은 kernel과 더 적은 block수를 사용하고, 이후 layer-by-layer 단계에서 block수를 늘리며 아키텍처를 수정하였다.

두 아키텍처의 성능을 비교해보았을 때
- 둘 다 Patch-by-patch로 수행했기 때문에 SRAM peak memory을 8배까지 줄이지만,
- Patch-by-patch만 적용한 MoblieNetV2 설계는 Patch-by-patch에서 중복 계산으로 인해 patch-by-patch 단계에서 42%, 전체에서 10%의 계산 오버헤드를 가진다.
- MACs(곱셈 + 누적 덧셈 수)에서는 Patch-by-patch만 적용한 MoblieNetV2보다 patch-by-patch 단계에서 연산량이 73M까지 줄어들었다.
- Classification accuracy는 거의 동일하며 VOC mAP(객체 검출 벤치마크)는 소폭 상승하였다.
Receptive field를 재분배하면 output feature map이 224x224일 때, 4등분 하여 한 patch size가 56x56인데, receptive field의 크기를 줄여 기존 input patch size를 75에서 63까지 줄이면서도 image classification 및 object detection 성능은 동일한 수준으로 유지할 수 있다.
Input patch size가 75에서 63까지 줄었다는 의미는 Overlap되는 영역의 크기가 줄었다는 의미 : 중복 계산이 줄어듦
Receptive field 재분배 후 계산 오버헤드는 3%에 불과하며, 메모리 감소의 이점을 고려하면 무시할 수 있는 수준이다.
3.3 Joint Neural Architecture and Inference Scheduling Search
Receptive field를 재분배하면 최소한의 오버헤드로 메모리 감소의 이점을 누릴 수 있지만, 백본에 따라 전략이 달라질 수 있다.
또한, peak memory가 감소하면 더 큰 입력 해상도를 사용하는 등의 자유를 누릴 수 있다.
하지만, 이러한 선택지가 너무 커지기 때문에 아키텍처와 스케줄링(patch/layer로 어떻게 실행할지)을 자동화된 방식으로 함게 최적화하는 것을 제안한다.
특정 데이터셋과 하드웨어 제약 조건이 주어지면서 최고의 정확도를 달성하는 것이 목표이다.
최적화 목록
1. Backbone optimization
2. Inference scheduling optimization
3. Joint search
Backbone optimization
NAS
사람이 직접 네트워크 구조를 설계하는 대신, 미리 정해둔 탐색 공간 안에서 여러 구조를 자동으로 평가해서 목표를 가장 잘 만족하는 아키텍처를 찾는 방법
이 논문에서의 탐색 공간
1. Kernel size (커널 크기) : 3/5/7
3x3 / 5x5 / 7x7 커널 중에서 고름
2. Expansion ratio (확장비) : 3/4/6
한 블록 내부에서 채널을 중간에 몇 배로 늘릴지
3이면 C x 3으로 늘어남
3. Number of blocks (블록 개수) : 2/3/4
해상도가 동일한 블록의 개수
- 224xx224가 한 블록에서 112x112로 줄고, 또 어느 지점에서 56x56으로 줄 때, 이 같은 해상도가 동일하게 유지되는 블록의 개수를 의미
4. Per-block width multiplier (블록별 너비 배수) : 0.5/0.75/1.0
블록마다 입/출력 채널 수를 다르게 하기 위해 스케일링하는 값
- 0.75면 해당 채널의 입력/출력의 채널 수를 0.75배함

5. Input resolution (입력 해상도) : 96~256
입력 이미지를 96x96 ~ 256x256 사이의 해상도로 넣음
이러한 탐색 공간의 구성은 최종 NAS 성능에 결정적인 영향을 미친다.
Inference scheduling optimization
모델과 하드웨어 제약조건이 주어졌을 때, 그 모델을 MCU에서 어떻게 실행할지 최적의 inference scheduling을 찾아야 한다.
같은 모델이라도 Layer-by-layer와 Patch-by-patch가 어떻게 스케줄링 되어있는지에 따라 메모리와 오버헤드가 달라지기 때문이다.
이 논문에서는 TinyEngine 기반으로 이를 확장하였으며, 제약 조건 내에서 가장 좋은 스케줄링을 탐색한다.
TinyEngine은 MCU에서 모델을 실행할 때, conv, FC, pooling같은 연산을 처리하도록 하는 프레임워크
기존 TinyEngine은 Layer-by-layer로만 지원
1. 패치 개수
Patch-by-patch의 최종 출력 feature map을 x로 쪼개어 채운다.
- 가 커질수록 peak memory는 더 줄어들지만, 오버헤드가 증가할 수 있다.
2. 앞에서 몇 개의 블록을 patch-by-patch로 실행할지
이 커지면 patch로 처리하는 구간이 길어져 메모리를 더 줄일 수 있지만, 그만큼 오버헤드 역시 컺빌 수 있다.
이 두 변수를 제약 조건을 만족하면서 최적인 값으로 정해야 한다.
Joint search
NAS를 통해 최적 아키텍처를 최적화하는 것과 inference scheduling을 통해 최적의 실행 방식을 찾는 것을 따로 실행하면 최적의 결과를 놓칠 수 있으니,
둘을 한 번에 탐색하여 최적화 해야 한다.
앞에서 말했던
1. Backbone 탐색 공간
: 커널 크기(3/5/7)
: 확장비(3/4/6)
: 스테이지별 블록 수(깊이)
: 블록별 너비 스케일
: 입력 해상도
2. Scheduling 변수
: 패치 분할 개수
: 앞에서부터 몇 블록을 patch-by-patch로 실행할지
이 전체를 한 세트로 제약을 만족시키는 조합을 찾는다.
여기서는 Evolutionary search(진화적 탐색)라는 NAS 방법을 사용
- Backbone탐색 공간에서 아키텍처 랜덤 샘플링
- 그 아키텍처에 대해 scheduling 변수에서 제약 조건 내 가능한 모든 조합을 전부 탐색
- 그중에서 가장 최적을 성능을 보이는 scheduling 변수 선택
이 샘플링에서의 최적인 값들, 평가 결과를 하나의 점수로 나타냄
- 1~3 과정을 계속 반복하면서 가장 높은 점수인 샘플링 조합을 업데이트해감
4 . Experiments
Experiments에서 저자들이 증명하려는 핵심은 3가지
-
기존 네트워크도 patch-based inference로 피크 메모리(SRAM)를 크게 줄일 수 있다
-
(NAS로) 모델+스케줄을 같이 설계하면, MCU에서 정확도 SOTA를 갱신할 수 있다 (분류/탐지)
-
patch 기반의 설계/하이퍼파라미터(p, n)가 메모리·오버헤드·정확도에 어떻게 영향을 주는지 분석한다
실험 세팅
1. Analytic profiling : 아키텍처만 보고 계산한 메모리
레이어가 요구하는 메모리를 입력 activation + 출력 activation 합으로 계산
순수 구조 비교용
2. On-device profiling : 실제로 MCU에서 돌렸을 때 측정된 SRAM/Flash
실제로 MCU에서 실행했을 때는 버퍼 할당과 같은 부가적인 메모리로 인해 analytic과 다름
현실적인 배포 가능성 확인용
실험 데이터셋 & 배포 환경
데이터셋
- ImageNet: 표준 분류 벤치마크
- Visual Wake Words(VWW): TinyML 현실 앱(사람/존재 감지 등)을 반영
- Pascal VOC, WIDER FACE: 해상도에 민감한 detection task에서, patch 기반이 해상도 제약을 풀어주는지 확인
환경
- int8 양자화로 배포
- TinyEngine 기반으로 patch inference 지원하도록 확장
- 서로 SRAM/Flash가 다른 3개 MCU(STM32F412/F746/H743)에서 측정
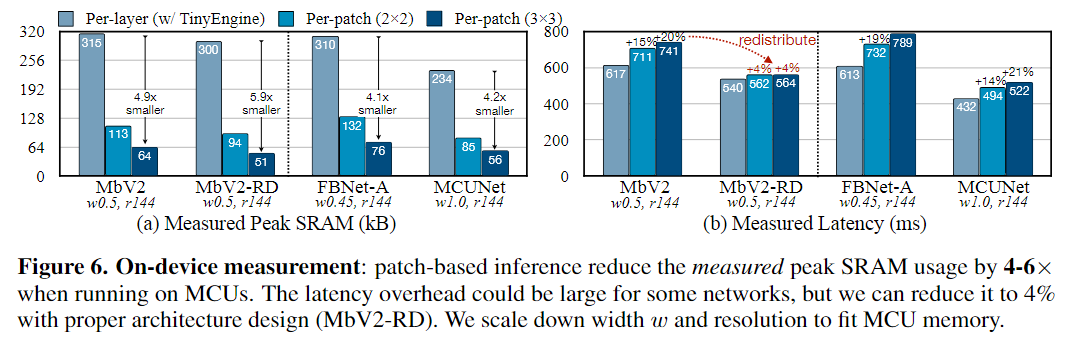
4.1 Reducing Peak Memory of Existing Networks
기존에 존재하는 모델을 대상으로 patch-by-patch 방식이 메모리/오버헤드를 얼마나 줄이는지 확인
Analytic profiling 결과
- 입력 224×224, patch는 4×4
- 피크 메모리 3.7× ~ 8.0× 감소
- 대신 연산량 오버헤드 8% ~ 17% 증가

On-device 측정 결과
- STM32F746(320kB SRAM/1MB Flash)에서,
- per-layer vs per-patch(2×2 또는 3×3) 비교
- MCU 메모리 한계 때문에 width(w)와 resolution(r)을 줄여서 실험
- 실측 피크 SRAM이 4~6× 감소
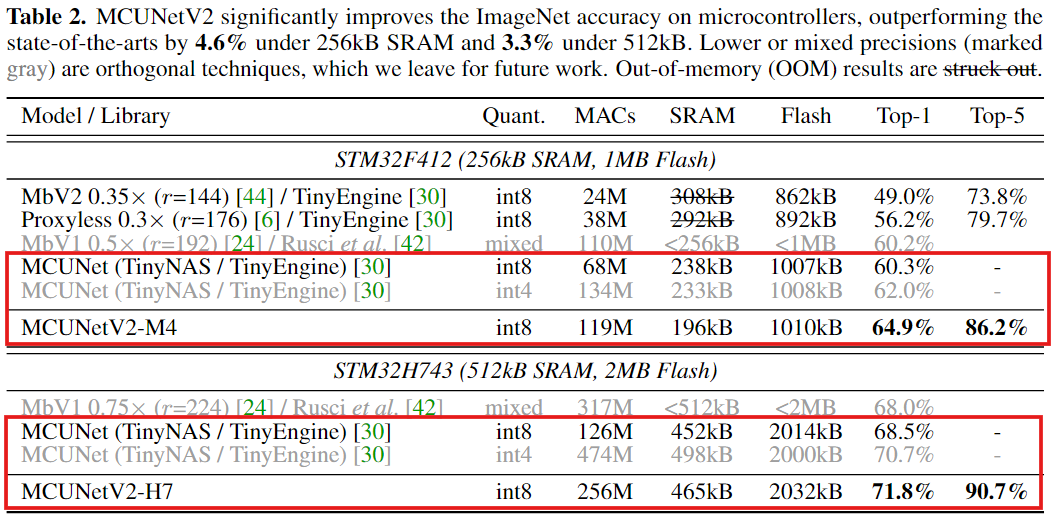
4.2 MCUNetV2 for Tiny Image Classification
NAS로 모델+스케줄을 같이 찾았을 때 MCU에서의 성능 확인
ImageNet on MCU
실험 환경
- STM32F412: 256kB SRAM / 1MB Flash (Cortex-M4급)
- STM32H743: 512kB SRAM / 2MB Flash (Cortex-M7급)
- 256kB/1MB 조건에서 기존 SOTA(MCUNet) 대비 +4.6% Top-1 개선, 피크 SRAM도 더 낮다
- 512kB/2MB 조건에서 Top-1 71.8%로 SOTA 성능
4.3 MCUNetV2 for Tiny Object Detection
Detection은 해상도에 민감한데, patch inference가 해상도 제약을 풀어 mAP를 크게 올림을 증명
Pascal VOC detection
- H743(512kB)에서 MCUNetV2-H7 mAP 68.3%, 기존(MCUNet 51.4%) 대비 +16.9%p
- F412(256kB)로도 줄여서 mAP 64.6%, +13.2%p 개선
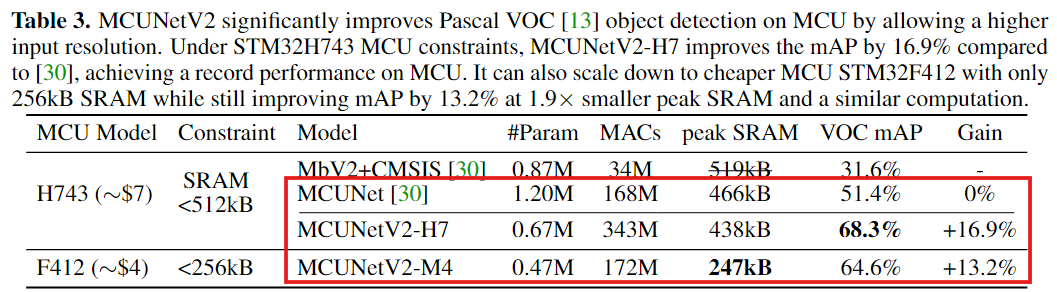
- 계산량(MACs)은 비슷하거나(256kB 쪽은 172M vs 168M) 큰 차이가 없는데도 mAP가 크게 오르는 이유
patch 기반이 더 큰 입력 해상도 + 더 작은 모델 같은 새로운 조합을 허용해서 탐지에 유리한 구성을 찾을 수 있기 때문
