Open Vocabulary Semantic Segmentation with Patch Aligned Contrastive Learning (CVPR 2023)
논문
Abstract
이 논문은 Open Vocabulary Semantic Segmentation을 수행하는 새로운 방법론을 제안한다.
Open Vocabulary Semantic Segmentation
훈련 시 특정 데이터셋이 없어도 텍스트에 해당하는 이미지 내 영역을 식별하는 것
제안된 방법은 Patch Aligned Contrastive Learning(PACL)로 기존의 CLIP 모델에 새로운 정렬 방식을 도입한 방식이다.
CLIP모델은 대규모 이미지-텍스트 쌍 데이터로 학습된 모델로, 이미지와 텍스트를 연관 짓는 작업 수행
PACL은 CLIP의 vision encoder에서 패치 토큰(이미지의 작은 조각)과 text encoder의 CLS 토큰(전체 텍스트를 요약한 표현)을 정렬시키는 학습 방식을 도입하여 모델이 텍스트 입력과 관련된 이미지의 특정 영역을 더 잘 식별할 수 있게 한다.
기존의 CLIP은 CLS 토큰 간 정렬을 기반으로 전체 이미지 수준에서만 텍스트와의 연관성을 학습했으나 PACL은 패치 수준의 정렬을 가능하게 하여 이미지의 각 세부 영역과 텍스트 간 연관성을 강화한다.
토큰 간 정렬한다는 말은 토큰 간 유사도를 학습시킨다는 말
CLIP
CLIP은 대규모 이미지-텍스트 데이터를 사용하여 이미지를 표현하는 vision encoder와 text encoder를 학습하며 두 인코더가 이미지 전체와 텍스트 전체를 매칭하도록 설계됨
CLIP의 vision encoder는 이미지 전체를 하나의 벡터(CLS토큰)로 요약하고 text encoder는 문장 전체를 CLS토큰으로 요약하여 CLIP의 대조학습(Contrasitive Learning)은 이미지의 CLS토큰과 텍스트의 CLS토큰 간 연관성을 학습한다.
대조 학습은 서로 관련 있는 쌍은 내적값 커지게, 관련 없는 쌍은 내적값 작게 하는 방식으로 모델 학습 하는 방법
CLIP에서는 이미지 전체를 요약한 벡터(CLS토큰)과 텍스트 전체를 요약한 벡터 간 대조학습으로 이미지와 텍스트 간 연관성을 학습시킨다.
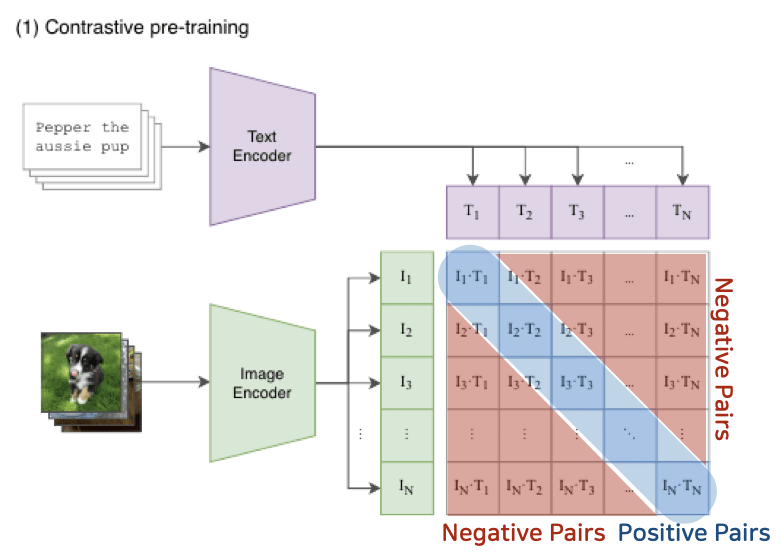
이렇게 학습하면 이미지 전체 수준에서 텍스트와 연관성을 찾는 데는 강점이 있지만, 이미지 내부의 세부 영역에 대한 정밀한 연관성은 학습할 수 없다.
그래서 Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP (CVPR 2023) 논문에서는 Masking을 사용하여 세부 영역에 집중할 수 있도록 하는 방법 제시했었다.
이 논문에서는 이미지 전체가 아닌 패치 단위로 연관성을 학습시키는 방법을 제안하고 있다.
Introduction
이미지 분류, 객체 탐지, Semantic Segmenatation과 같은 다양한 예측 문제들은 컴퓨터 비전에서 중요한 문제이다.
이미지 분류는 하나의 이미지에 대한 하나의 주석만 필요하지만 Semantic Segmentation은 픽셀 단위로 주석을 제공해야 하기 때문에 더 많은 노력이 필요하다.
이미지 분류는 이미지 전체를 하나의 카테고리로만 분류하면 되지만 Semantic Segmentation은 이미지의 각 픽셀마다 구분해 카테고리를 지정해야함
주석 데이터란?
모델이 학습하기 위해 데이터에 대해 사전 정의된 주석이 필요한데
Semantic segmantation이 이미지의 모든 픽셀에 해당하는 클래스 정보가 포함된 정답 데이터가 필요로 하기 때문에 모델이 이미지의 특정 패턴과 클래스 간 관계를 학습하기 위해 필수적이다
이러한 문제를 해결하기 위해서 unsupervised(비지도) 방식의 접근법이 제안되었다.
하지만, unsupervised learning은 주석 데이터를 사용하지 않기 때문에 비용이 적게 들지만 기존의 supervised learning 방식보다 성능이 떨어지는 것을 확인할 수 있었다.
비지도 학습은 학습 데이터에 정답이 주어지지 않은 상태에서 데이터를 학습하는데 주석이 필요없기 때문에 비용을 절약할 수 있지만 데이터를 보고 스스로 패턴과 특징을 찾아야 하므로 정답이 주어지는 지도 학습에 비해 성능이 떨어진다.(비용과 성능의 trade-off)
잘 학습되었는지에 대한 정답 기준이 없기 때문에 성능이 떨어짐
주석 데이터를 사용하지 않는다는 말은 이미지와 텍스트를 매핑하고 픽셀 별로 loss를 계산할 정답 기준이 없음
최근 multi-modal 기초 모델이 발전하면서 인터넷에서 수집된 대규모 데이터셋으로 학습이 가능해졌다. CLIP같은 모델은 인터넷의 이미지-텍스트 데이터를 활용해 학습되었다.
이러한 모델들은 자연어 기반의 표현을 학습하기 때문에 텍스트로 정의할 수 있는 open vocabulary 예측 작업에서 유용하다.
멀티 모달을 이용해 이미지와 텍스트 간의 연관성을 학습하여 텍스트로 정의된 개념에 해당하는 이미지를 찾을 수 있다.
open vocabulary 예측이란 모델이 학습 데이터에서 보지 못한 새로운 개념도 텍스트로 정의된 내용을 바탕으로 처리하는 능력으로 CLIP같은 모델의 자연어 기반으로 학습능력은 해당 작업에 적합하다.CLIP은 이미지오 텍스트 간의 관계를 학습했기 때문에 텍스트로 정의된 작업인 Open Vocabulary에서 유용하다
그래서 multi-modal 모델이 semantic segmentation에서 적용될 수 있는지에 대한 의문이 제기되었다.
이전 연구에서 GroupViT모델은 이미지-텍스트 데이터만으로 Open Vocabulary Semantic Segmentation을 수행했지만 새로운 아키텍처 설계로 인해 처음부터 끝까지 학습이 필요하며, pre-trained된 vision encoder를 사용할 수 없다는 단점이 존재했다.
GroupViT는 Open Vocabulary를 사용하여 미지 정의되지 않은 새로운 클래스에서도 텍스트 데이터를 통해 이미지와 텍스트 간 연관성을 학습할 수 있는 모델이다.
하지만, GroupViT는 Vision Transformer를 자체적으로 수정하여 기존에 학습된 Vision encoder와 호환되지 않아 처음부터 끝까지 새로운 데이터로 학습을 다시 수행해야 한다.
CLIP의 vision encoder처럼 미리 학습된 모델을 가져와 사용하는 것이 아니라 처음부터 새로운 아키텍처로 모델을 설계한 것
이 연구에서는 이미지-텍스트 데이터만으로 학습되는 모델로, Segmentation 주석이나 mask를 사용하지 않고 Open Vocabulary Semantic Segmentation문제를 해결하려고 한다.
CLIP은 이미지 전체와 텍스트 간 관계를 학습할 수 있지만, 이미지 내 세부 영역(패치)와 텍스트의 관계를 학습하지 못한다는 한계가 존재한다.
vision encoder의 패치 토큰과 text encoder의 CLS 토큰 간의 정렬을 학습하기 위한 새로운 학습 방식인 PACL을 정의한다.
PACL은 텍스트와 관련된 패치 간의 관계를 학습하며, 이를 기반으로 Segmentation주석 없이도 제로샷 Semantic Segmentation을 가능하게 한다.
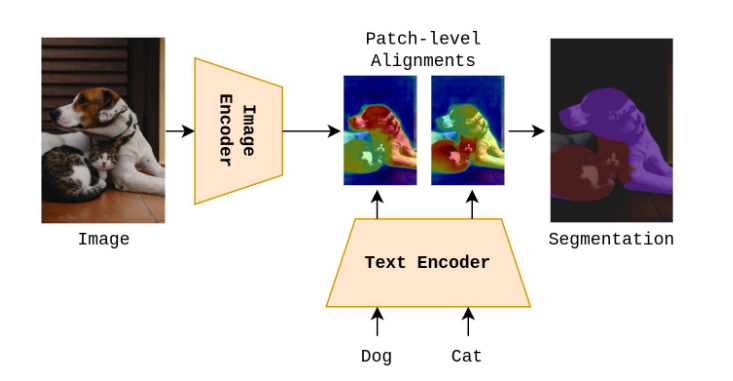
PACL은 기존 GroupViT와 달리 pre-trained된 ViT인코더를 사용할 수 있고, 모든 데이터셋에서 PACL은 Segmentation주석이나 mask없이도 일관된 성능 향상을 보여주었다.
요약하면, 본 연구의 기여는 다음과 같다.
1. PACL을 제안한다.
vision encoder의 패치 표현과 text encoder의 CLS 텍스트 표현 간 정렬을 학습하기 위해 Contrasitive loss(대조 손실)을 수정한 새로운 호환성 함수이다.
이 정렬이 이미지 내 특정 텍스트 입력과 관련된 영역을 찾는 데 사용할 수 있음을 보여주어, Open Vocabulary Semantic Segmentation아ㅡ로 제로샷 전이를 수행하는 데 활용될 수 있다.
2. Pre-trained된 CLIP 인코더를 사용한 PACL이 제로샷 semantic segmentation작업에서 좋은 성능을 달성
3. PACL이 CLIP의 백본과 함께 사용되었을 때 분류 작업에서도 좋은 성능을 보임
2. Related Work
Supervised Semantic Sementation(지도 학습 기반 Semantic Sementation)
주어진 이미지에서 Semantic Sementation작업은 이미지를 픽셀 단위로 고정된 카테고리 집합 중 하나로 분류하는 것을 말한다.
지도 학습 기반 Semantic Sementation 데이터셋은 각각의 픽셀에 주석이 포함된 이미지를 제공한다.
픽셀 단위의 주석 작업은 많은 비용을 필요로하기 때문에 데이터셋에 포함된 클래스 수가 제한적이다.
unsupervised Semantic Sementation(비지도 학습 기반 Semantic Sementation)
픽셀 단위 주석 없이 이미지 데이터를 학습하여 의미적으로 유사한 영역을 클러스터링한다.
주석 데이터 없이 Self-Supervised 방식을 사용하여 이미지 속 feature를 학습하려 시도했다.
Self-Supervised는 주석 데이터를 제공하지 않아도 모델이 데이터를 보고 스스로 특징을 학습하는 방법으로 이미지 내 픽셀의 특징을 비교하여 유사한 픽셀끼리 클러스터링하여 픽셀 간 유사성을 학습한다.
주석 데이터 없이도, 이미지를 패치로 나눈 뒤, 패치 간 관계와 유사성을 기반으로 Segmentation을 수행한다.
본 논문에서는 CLIP과 같은 멀티 모달에서 Self-Supervised 방식을 확장하여 활용하려함
Natural Language Supervision(자연어 감독)
최근 인터넷에서 수집된 대규모 이미지-텍스트 쌍 데이터셋의 가용성 덕분에, 대규모 멀티 모달 모델을 학습하는 것이 가능해졌다.
자연어 감독은 이미지-텍스트 쌍 데이터셋을 사용하여 학습하는 멀티모달 모델의 학습 방식으로 자연어 텍스트를 학습 데이터로 사용하여 모델을 학습시키는 기법
이러한 모델들은 다양한 다운스트림 작업에서 활용된다.(이미지-텍스트 검색, VQA비주얼 질문 응답, 제로샷 이미지 분류, 객체 탐지..)
주석 데이터를 만들 필요 없이, 자연어를 기반으로 모델이 스스로 개념을 이해할 수 있다는 장점이 있다.
Natural language supervision for zero-shot segmentation
Semantic Sementation 작업에서 대규모 멀티 모달 모델을 사용하는 방향으로 몇 가지 연구가 이루어졌다.
기존 연구들은 완전 지도학습이나 클래스 비종속 주석을 필요로 했으나 본 연구는 CLIP 모델의 대조 학습 방법을 약간 수정하여 ViT 기반 비전 인코더의 패치 토큰과 텍스트 인코더의 CLS토큰 간 정렬을 학습하여 Segmentation 주석 없이도 Semantic Sementation을 수행한다.
기존 Semantic Sementation은 주석을 필요로 하나 본 연구는 텍스트와 이미지의 특정 패치를 연결하여, 주석 없이 Semantic Sementation을 수행
학습 데이터에 없는 새로운 클래스도 텍스트 설명만으로 작업할 수 있게 하며, 텍스트의 의미에 따라 이미지의 패치들을 분류하고 이를 통해 픽셀 수준의 Segmentation을 가능하게 한다.
3. Patch Level Alignment in CLIP(CLIP에서 패치 수준 정렬)
CLIP의 대조 학습(contrastive training)은 Transformer 기반 vision 및 text 인코더에서 생성된 CLS 토큰이 유사한 이미지-텍스트 쌍에 대해 정렬되도록 보장한다.
하지만, 이러한 학습 방식은 이미지와 텍스트 간의 전체적인 연관성만 학습하기에 패치 수준에서의 정렬은 학습되지 않을 수 있다.
CLIP에서 패치 수준 정렬을 평가하기 위해 이미지를 여러 패치로 나누고 각 패치를 기존 CLIP의 제로샷 분류 방법을 사용하여 고정된 클래스 중 하나로 분류한다.
패치 수준의 분류 정확도는 CLIP모델에서 비전과 텍스트가 얼마나 잘 정렬되었는지를 보여준다.
수식 정의
1. 데이터셋 정의

- x : 입력 이미지
- y : 각 픽셀에 해당하는 클래스(주석 데이터)
여기서는 전체 이미지 수준의 제로샷 분류를 다루기 때문에 y를 사용하지 않음
제로샷 모델은 텍스트와 이미지 간의 관계를 학습함으로써 사전에 정의되지 않은 클래스도 분류함
2. CLIP의 비전 및 텍스트 인코더

- 비전 인코더 : 이미지를 받아서 임베딩 벡터로 변환
- 텍스트 인코더 : 텍스트를 임베딩 벡터로 변환하여 이미지와 비교
3. 공통 임베딩 공간

- 공통 임베딩 공간 : 비전 인코더와 텍스트 인코더는 서로 다른 임베딩 차원을 사용하기 때문에 선형 변환을 통해 동일한 차원으로 매핑한다.
동일한 차원의 공간에서 유사성을 비교한다
4. 제로샷 분류

비전 임베딩과 텍스트 임베딩 간의 코사인 similarity를 계산하여 이미지와 텍스트가 얼마나 관련이 있는지 측정한다.
이를 바탕으로 확률 분포를 계산한다.
5. 패치 수준으로 확장

기존의 CLIP은 이미지 전체를 하나의 벡터로 변환했지만, 여기서는 이미지를 패치 단위로 나눈다.
T개의 패치 벡터가 생기면 각각의 패치 벡터와 텍스트 벡터 간에 모두 코사인 유사도를 계산하여 제로샷 분류를 수행한다.
성능 평가
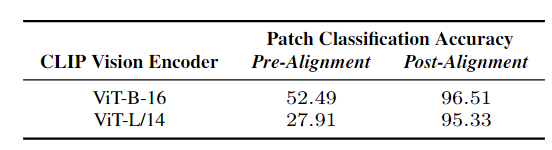
Table1에서 CLIP 모델 두 가지에 대한 패치 분류 정확도를 보았을 때, 패치 수준에서의 정확도가 매우 낮은 것을 알 수 있으며(Pre-Alignment), 전체 이미지 수준에서의 예측 정확도 보다 패치 수준에서의 성능이 더 좋지 않았다.
사전 학습된 CLIP모델은 Open Vocabulary Semantic Segmenatation에 적합하지 않다.
4. Semantic Coherence in Vision Encoders
위에서 봤을 때, CLIP에서 이미지와 텍스트 인코더 간의 패치 수준 정렬이 성능이 안 좋기 때문에, CLIP에서 그러한 정렬을 학습할 수 있는지를 다룬다.
이를 위해서는 pre-trained된 CLIP 비전 인코더가 semantic coherence(의미적으로 일관성)을 가져야 한다.
이미지에서 의미적으로 유사한 영역은 비전 인코더에서 유사한 패치 표현을 생성해야 한다.(유사한 임베딩값을 생성해야 한다.)
의미적 일관성이 없으면, 비전 인코더가 이미지의 유사한 영역을 잘 표현하지 못해 텍스트와의 정렬 성능이 낮아진다.
CLIP의 비전 인코더의 semantic coherence를 정렬화하기 위해 유사한 테스트를 사용한다.
CLIP 비전 인코더가 패치 수준 정렬을 학습할 수 있는지 여부를 판단하기 위해 수행
CLIP의 비전 인코더가 의미적 일관성을 갖추고 있다면 패치 수준 정렬을 바로 학습할 가능성이 있다.
- CLIP모델이 PACL로 확장될 가능성을 평가하기 위한 테스트
테스트 과정
1. 패치 표현 수집
데이터셋의 각 이미지를 CLIP 비전 인코더에 입력하여 각 패치의 벡터를 추출한다.

2. 코사인 유사도 계산
두 패치의 벡터 표현 간 코사인 유사도를 계산한다.
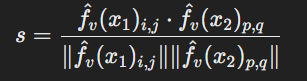
코사인 유사도 값이 클수록 두 패치가 같은 클래스를 가질 가능성이 높다
두 패치 간의 코사인 유사도를 계산하여 CLIP비전 인코더가 두 패치를 얼마나 유사하게 표현했는지 확인한다.
클래스 레이블 간 비교를 통해 정답을 설정하고, 코사인 유사도를 이용해 의미적 일관성을 잘 학습했는지 확인
3. Segmentation 레이블 수집
각 패치에 대해 해당 패치의 레이블을 결정
각 패치에 대해 l(x1)i,j라는 Segmentation 레이블이 할당된다.
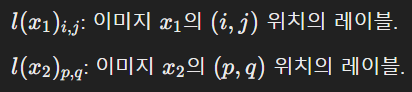
각 이미지에는 Segmentation 레이블 맵 y가 있다
이미지의 각 픽셀에 해당하는 클래스 레이블이 존재
Segmentation 레이블은 각 패치에 대해 어떤 클래스에 속하는지를 나타낸다.
4. 이진 분류 수행
각 패치의 클래스 레이블을 비교하여, 두 패치가 같은 클래스인지 아닌지 확인한다
두 레이블을 비교하여 같은 클래스이면 1, 다른 클래스이면 0으로 두 패치가 같은 클래스에 속하는지 여부를 이진 레이블로 변환한다.
의미적으로 유사한 레이블을 가진 패치가 높은 코사인 유사도를 가져야 함
패치 표현이 같은 레이블을 가지는 패치 간에 높은 코사인 유사도를 가지며, 의미적 일관성이 높음
이진 분류기의 성능은 CLIP의 비전 인코더가 의미적 일관성이 높은지 낮은지를 나타낸다.
5. Patch Aligned Contrastive Learning (PACL)
CLIP의 대조 학습 손실을 수정하여 비전 인코더의 패치 표현과 텍스트 인코더의 CLS 토큰 간의 정렬을 학습하는 방법을 제안
A modified compatibility function for contrastive loss
CLIP 학습에서 변경할 유일한 부분은 대조 학습 손실의 (compatibility function)호환성 함수이다.
기존의 CLIP은 이미지-텍스트 쌍에 대해 비전 임베딩과 텍스트 임베딩을 생성하여 두 표현을 공통된 차원으로 임베딩하였다.
기존의 compatibility function은 CLS 토큰(비전 임베딩, 텍스트 임베딩) 간의 코사인 유사도를 계산한다.
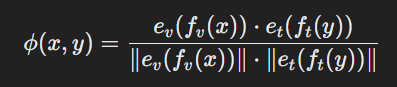
기존의 CLIP은 위의 compatibility function을 이용하여 대조학습 손실을 계산하였다.
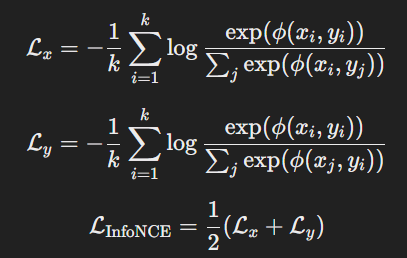
그러나 이 손실 함수는 CLS 토큰 수준에서 정렬을 보장할 뿐, 패치 수준에서의 정렬은 보장하지 못했다.
수정된 접근 방식 : PACL
-
비전 인코더를 수정하여 이미지를 패치 수준으로 나누어 모든 패치 임베딩을 출력한다.
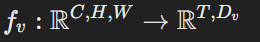
-
이후 모든 패치 임베딩과 텍스트 임베딩 간 코사인 유사도를 계산한다.
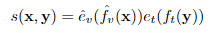
결과적으로, 각 패치에 대해 텍스트와의 유사도가 계산된다.s(x,y)는 패치 개수 𝑇만큼의 값을 가지며, 𝑠(𝑥,𝑦)∈𝑅^𝑇이다
-
계산된 유사도를 소프트맥스 함수를 사용하여 0~1 범위로 정규화한다.

각 패치가 텍스트와 얼마나 중요한지 나타낸다s(x,y)는 텍스트와 각 패치 간의 상대적 중요도를 나타내는데, 정규화되지 않아서 해석이 어렵고, 다른 패치들과 비교하기 어렵기 때문에 소프트맥스를 이용하여 정규화한다.
모든 패치에 대해 텍스트와의 유사도를 비율로 변환하여 어떤 패치가 가장 텍스트와 강한 연관성을 가지는지 비교할 수 있다.
- a(x, y)의 모든 원소의 합은 1이 되어 각 패치의 상대적 중요도를 나타내는 가중치가 된다
-
이후 패치 간 가중 평균을 계산하여 최종 패치 표현을 생성한다.
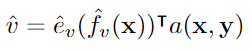
각 패치 𝑖는 고유한 벡터 표현 𝑒𝑣(𝑓𝑣(𝑥))𝑖를 가진다.

텍스트와 관련성이 높은 패치에 더 많은 가중치를 부여하기 위해, 소프트맥스에서 구한 가중치 a(x,y)를 사용한다. -
수정된 CLIP의 호환성 함수는 다음과 같이 정의된다.
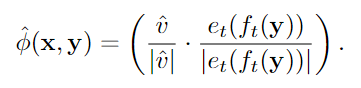
InfoNCE 손실 함수에 이 새로운 호환성 함수를 적용하여 학습을 수행하며, 이를 Patch Aligned Contrastive Learning (PACL)이라고 부른다.
작동 방식 시각화
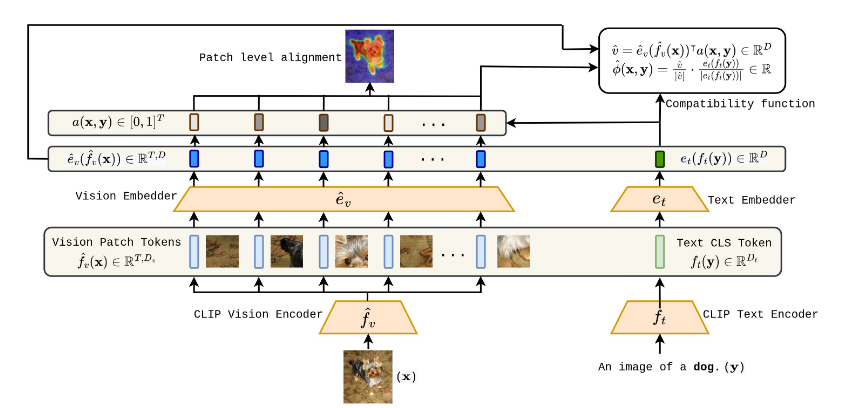
1. 입력
이미지 x : 개 이미지가 입력으로 사용
텍스트 y : 텍스트 입력은 "A dog"문장
2. CLIP 비전 인코더 (fv)
이미지 𝑥는 CLIP의 비전 인코더에 의해 처리된다.
비전 인코더는 이미지를 여러 패치 토큰 fv(x)로 나눈다.
- 각 패치는 T개의 독립적인 벡터로 표현되며, 그림에서는 "개의 머리", "몸통", "다리" 등 각 패치가 개별적인 이미지 조각으로 표현된다.
3. CLIP 텍스트 인코더 (ft)
텍스트 입력 𝑦는 CLIP의 텍스트 인코더에 의해 처리된다.
텍스트 인코더는 텍스트의 CLS 토큰 ff(y)를 생성한다.
- CLS 토큰은 텍스트 전체를 요약한 벡터 표현이다.
4. Vision Embedder (𝑒𝑣)
CLIP 비전 인코더에서 생성된 패치 표현 𝑓𝑣(𝑥)는 Vision Embedder(𝑒𝑣)에 의해 패치 표현을 공통 차원으로 변환된다.
=>ev(fv(x))
5. Text Embedder (𝑒𝑡)
텍스트 CLS 토큰 𝑓𝑡(𝑦)는 Text Embedder (𝑒𝑡)에 의해 텍스트 표현이 공통 차원으로 변환된다.
=>et(ft(y))
6. 패치 수준 유사도 계산 (𝑠(𝑥,𝑦))
각 패치 표현 ev(fv(x))와 텍스트 CLS 표현 et(ft(y))간의 코사인 유사도를 계산한다. s(x,y)
- s(x,y) => T개의 패치 각각과 텍스트 간의 유사도를 나타낸다
7. 소프트맥스 정규화 (𝑎(𝑥,𝑦))
패치 유사도 𝑠(𝑥,𝑦)를 소프트맥스를 통해 정규화하여 각 패치의 가중치𝑎(𝑥,𝑦)를 계산한다.
- 𝑎(𝑥,𝑦) : 각 패치가 텍스트와 얼마나 관련 있는지 나타내는 확률 분포
8. 가중 평균 패치 표현 생성 (𝑣^)
각 패치의 표현 ev(fv(x))i에 가중치 𝑎(𝑥,𝑦)i를 곱하여 가중 평균 패치 표현 𝑣^를 생성한다.
- 𝑣^ : 텍스트와 강하게 연관된 이미지ㅡ이 패치 정보를 요약한 벡터이다.
9. 수정된 호환성 함수 (𝜙^(𝑥,𝑦))
생성된 가중 평균 패치 표현 𝑣^와 텍스트 표현 et(ft(y)) 간의 코사인 유사도를 계산하여 최종 호환성 함수 𝜙^(𝑥,𝑦)를 정의한다.
- 𝜙^(𝑥,𝑦) : 이미지와 텍스트 간의 정렬 정도를 나타낸다.
10. Patch Level Alignment(패치 수준 정렬)
최종적으로, 가중치 𝑎(𝑥,𝑦)를 시각화하여 이미지에서 텍스트와 관련된 영역을 강조한다.
- "A dog." 텍스트와 연관된 패치들이 시각적으로 강조된다
Grounded in Mutual Information
호환성 함수가 어떻게 작동하는지를 이해하기 위해 InfoNCE 손실과 mutual information(MI)의 관계를 알아본다.
MI는 x와 y가 서로 얼마나 정보를 공유하는지를 측정하는 값으로 CLIP에서는 이미지의 특정 패치와 텍스트가 얼마나 서로 관련있는지를 보여준다
MI가 크면 두 변수는 강하게 연결되어 있고, 작으면 거의 무관하다.
InfoNCE는 CLIP학습에서 사용되는 손실로 InfoNCE 손실을 최소화하면 x와 y 간의 MI를 극대화할 수 있다.
즉, InfoNCE는 MI의 하한을 제공한다
x, y를 결합 확률 분포를 가진 두 개의 다변량 랜덤 변수라고 가정할 때 x와 y간의 MI는 다음과 같이 계산된다.
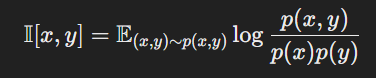
이것은 x와 y 간에 공유되는 정보의 양을 나타낸다.
하지만, MI는 계산이 복잡하여 근사치를 통해 추정하는데 InfoNCE 손실
𝐿InfoNCE(𝜃)는 모델 매개변수 𝜃를 사용하여 MI의 하한(lower bounded)를 제공하며, 다음과 같이 정의한다.
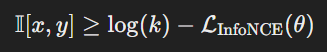
여기서 k는 InfoNCE 손실에서 한 배치에 포함된 샘플 개수로, k-1개의 음성 샘플이 포함된다. 따라서, InfoNCE 손실을 최소화하면 MI의 하한을 극대화하게 된다.
PACL의 패치 수준 정렬 테스트
3장에서 설명한 패치 수준 분류 테스트를 다시 수행한다.
각 패치에 대해 코사인 유사도를 계산하고, 가장 높은 유사도를 가지는 클래스를 예측한다.
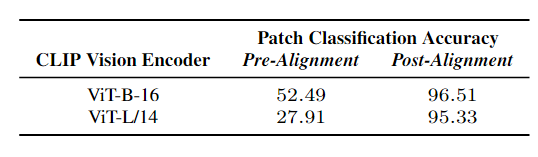
PACL을 적용한 후, 패치 수준 분류 정확도가 크게 향상됨을 알 수 있다.
6. Experiments

- Method : 평가된 방법들
- CLIP + PACL: PACL을 적용한 CLIP 모델(우리의 방법)
- Encoder : 각 모델에서 사용된 인코더(비전 모델)와 그 사전 학습 여부
- PACL은 사전 학습된 CLIP ViT-B/16을 사용
-
External Training Set : 학습에 사용된 외부 데이터셋
-
Constraints : 학습 중 사용된 주석 및 마스크의 여부
- PACL은 어떠한 주석(Annotation)이나 마스크(Mask)도 사용하지 않음
- mIoU : 모델의 성능을 나타내는 지표로, 높을수록 성능이 좋다.
분석 결과
기존 CLIP 모델은 의미 세분화에서 매우 낮은 mIoU를 기록했다
- PV-20에서 8.4 : 이는 기본 CLIP이 패치 수준 정렬을 학습하지 못했음을 보여준다
PACL을 적용한 CLIP은 기존 CLIP에 비해 성능이 크게 향상되었다.
- PV-20: 8.4 → 72.3
- PC-59: 2.3 → 50.1
- CS-171: 2.6 → 38.8
- A-150: 1.3 → 31.4
PACL은 기본 CLIP 모델의 한계를 극복하며, 다양한 Semantic Segmentation 데이터셋에서 높은 성능을 보여준다
