Abstract
Vision-language model은 다양한 다운스트림 task에서 좋은 성능을 보여주었지만, 모델의 크기 때문에 컴퓨팅 리소스가 제한된 환경(모바일 기기, 엣지 서버)에서는 활용도가 떨어진다.
다운스트림 task?
- Pre-Training된 모델을 활용하여 수행하는 특정한 목적을 가진 작업
언어 모델에서의 다운스트림은 QA, 비전 모델에서는 Object detection, VLM에서는 Image-text retrieval, Image captioning 등...
이를 해결하기 위해 사용할 수 있는 방법으로는
- 더 작은 pre-trained 모델 사용하기
- Magnitude Pruning(크기 기반 가지치기)
하지만, 이 방법들은 유연성이 부족하고 성능이 저하되는 것으로 나타났다.
기존의 VLP(Vision-Language Pre-trained models) 압축을 위해 시도된 두 가지 연구가 있다.
1. 단일 모드 기반 메트릭
- 메트릭
어떤 성능을 수치로 표현할 수 있도록 하는 수치적 기준(예 : 정확도, 정밀도,..등) -> 이 논문에서는 MoPE가 메트릭
단일 modal을 기준으로 pruning을 수행하였다.
즉, 이미지 처리 모델이면 이미지에 대해서만, 텍스트 처리 모델이면 텍스트에 대해서만 중요도를 평가하는 방식으로 기준을 삼아 Pruning 하였다.
하지만, VLM은 이미지와 텍스트를 함께 처리해야 하는 멀티 모달이기 때문에, 단일 모달을 기준으로 Pruning을 사용하면 전체적인 성능이 크게 저하될 수 있다.
2. 마스크 기반 탐색 과정
모델에서 각 모듈이 중요한지 아닌지를 학습하는 Mask기반의 학습을 도입하였다.
즉, 모델이 스스로 "이 모듈은 중요하니까 남겨놔야 해" 또는 "이 모듈은 필요 없으니 제거해도 돼"같은 결정을 내릴 수 있도록 학습하는 방법을 적용하였다.
하지만, 학습가능한 mask를 도입하는 것은 엄청난 연산 비용을 필요로 한다.
- VLM 모델은 크기가 매우 크고 연산량이 많기 때문에, Masking을 위해 모듈에 대해 탐색 과정을 거치는 것이 실용적이지 않다.
이 논문에서는 Module-wise Pruning Error (MoPE) 이라는 방법론을 제안
MoPE는 CLIP 모델의 각 모듈(Attention Layer, FFN,..등)의 중요도를 측정하기 위한 지표이다.
이 메트릭은 특정 모듈을 제거했을 때 Cross modal task에서의 성능 저하를 평가한다.
MoPE를 사용하여 pre-training과 작업별 fine-tuning compression 단계 모두에 적용할 수 있는 통합된 가지치기 프레임워크인 MoPE-CLIP을 소개한다.
1. Introduction
VLP(Vision-Language Pre-trained models) 모델은 강력한 multi-modal representation learning 능력을 보여주었지만 많은 수의 매개변수를 필요로 하기 때문에 리소스가 제한된 디바이스에서는 사용이 제한되었다.
따라서, 실제 애플리케이션에서는 compact한 VLP 모델을 사용하는 것이 필수적이다.
서로 다른 플랫폼에 따라 두 가지 compression 방식을 정의할 수 있다.
-
pre-traning 단계 compression을 정의한다.
edge server는 pre-trained 모델 전체를 처리할 연산 자원이 부족하다.
처음부터 작은 모델을 사전 학습하면 비용이 많이 들므로, 기존의 Pre-trianing된 범용적인 대형 모델을 압축하여 먼저 크기를 줄인 후, 다시 대규모 데이터셋으로 Pre-training하는 방식을 사용한다.
-
fine-tuning 단계 compression을 정의한다.
모바일 기기 같은 환경에서는 하나의 범용 모델보다, 작업별로 최적화된 작은 모델이 필요로 한다.
모바일 기기 등에서 특정 작업(예: 이미지-텍스트 검색)에 맞춰 각각 최적화된 작은 모델을 만드는 방식
ex) 이미지 검색을 위해 vision encoder 압축, text 검색을 위해 text encoder 압축
처음부터 크기가 작은 모델을 사용하는 것도 방법이지만, 각 모델을 개별적으로 Pre-training하는 것은 연산 비용이 너무 크기 때문에 Pruning 방법을 활용한 Compression이 필요하다.
최근 VLP pruning은 크게 두 가지 범주로 나뉜다.
- 첫 번째 방법은 단일 모달에서의 Transformer에 pruning을 적용하는 것이다.
Vision 또는 Language 모델에 사용되는 Transformer에서의 Magnitude기반 pruning과 loss기반 pruning이 효과적이지만, 실험 결과 멀티 모달인 CLIP에 적용했을 때 좋지 않은 성능을 보임
- Magnitude기반 pruning은 뉴런, 레이어의 weight의 크기를 기준으로 weight가 작으면 모델의 출력에 영향을 미치지 않는다고 가정하여 제거한다.
weight 크기만으로 중요도를 판단하기에 실제 미치는 영향을 반영하지 못할 수 있다.
- Loss-aware pruning은 특정 뉴런이나 레이어를 제거했을 때 모델의 loss function값이 얼마나 증가하는지를 측정하여 loss 값 증가가 적은 부분을 제거한다.
- 단일 모달에서는 효과적이지만 멀티 모달에서는 성능 저하가 발생하는 이유?
단일 모달에서의 모듈들은 처리해야 할 데이터 유형이 명확하여 각 모듈이 모델 성능에 기여하는 방식이 단순하기 때문에 중요도가 낮은 부분을 식별하고 제거하는 것이 쉽다.
멀티 모달에서는 두 가지 이상의 데이터 유형을 동시에 처리해야하기 때문에 모델의 성능이 개별 모달의 처리 능력 뿐만 아니라 두 모달 간 상호 작용에 의해 평가된다.
멀티 모달에서는 모달 간 상호작용에 대한 중요도는 평가하지 못한다.
단일 모달 관점에서는 중요하지 않다고 판단된 뉴런이 멀티 모달 성능에서 중요한 역할을 할 수 있다.
- 두 번째 방법은 중요한 모듈을 식별하기 위해 mask기반 pruning이 사용되었다.
모델의 중요한 모듈을 선택하기 위해 mask라는 학습 가능한 파라미터를 사용하여 뉴런, 레이어 등에 얼마나 중요한지를 나타내는 값을 부여하여 값이 낮으면 pruning한다.
마스크를 통해 어떤 모듈이 중요한지 동적으로 학습할 수 있지만 mask학습 자체가 추가적인 계산 비용을 요구한다.
즉, 기존 pruning의 문제점은
-
멀티 모달 모델의 특성을 제대로 반영하지 못해 pruning 후 성능 저하
-
중요한 모듈을 탐색하기 위한 과정이 시간과 계산 비용이 많이 소모됨
=> 현재까지 연구는 VLP 모델의 pre-training 단계와 fine-tuning 단계를 모두 통합하는 pruning 솔루션을 제공하지 못했다.
이를 해결하기 위해, 우리는 pre-traning 및 fine-tuning 단계에서의 compression을 위한 새로운 프레임워크인 MoPE-CLIP을 제안
MoPE는 멀티 모달 task에서 특정 모듈이 pruning될 경우 성능이 얼마나 저하되는지를 측정하는 Metric
MoPE 측정 요소
너비 방향
Transformer에서 FFN, Attention 등의 중요도 평가
깊이 방향
Transformer 레이어의 중요도를 평가
MoPE-CLIP은 MoPE을 활용하여 가지치기를 두 단계에서 수행한다.
- Pre-training 단계
목적 : Zero-shot 성능을 유지하면서 모델의 크기를 줄이는 것
검증 데이터셋에서 제로샷 성능을 측정하여 각 모듈의 MoPE 값을 계산
MoPE값을 기반으로 너비와 깊이를 pruning하고 소규모 데이터로 재학습하여 제로샷 성능을 유지한다.
- Fine-tuning 단계
목적 : 특정 다운스트림 작업(이미지-텍스트 검색)에 최적화된 작은 모델 생성
다운스트림 작업에서 성능 저하를 기준으로 MoPE 값을 계산
너비 방향 pruning를 먼저 수행한 뒤, 깊이 방향 pruning를 진행한다.
- pruning 후 Knowledge Distillation를 통해 pruning 전 교사 모델의 지식을 pruning된 student 모델로 전달
2. Preliminary Study of Downsizing CLIP
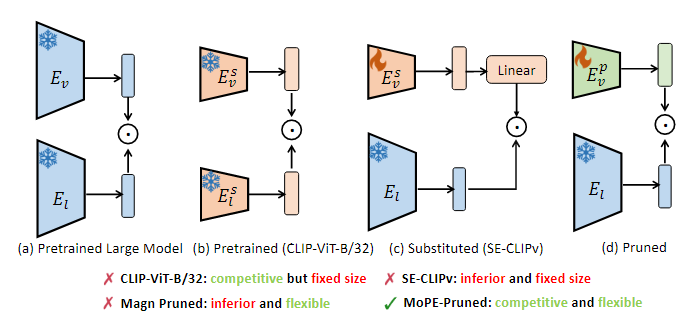
CLIP모델의 크기를 줄이기 위한 다양한 접근법을 설명함
1. 사전 학습된 더 작은 비전 인코더로 대체
2. MagnCLIP: 크기 기반 가지치기
각각의 방법에서 나타난 문제와 한계를 설명. 이를 기반으로 연구팀은 최종적으로 제안된 가지치기 방법(MoPE-Pruning)을 정당화함
compression은
1. pre-training 단계
2. fine-tuning 단계
중에 수행할 수 있다.
더 작은 모델로 대체하는 것은 만족스럽지 못한 결과를 초래함
1. CLIP의 Vision encoder와 Text encoder를 기존 CLIP-ViT-L/14에서 CLIP-ViT-B/32으로 축소시킨 모델
Vision, Laguage encoder 둘 다 Freeze(추가 학습 없음)
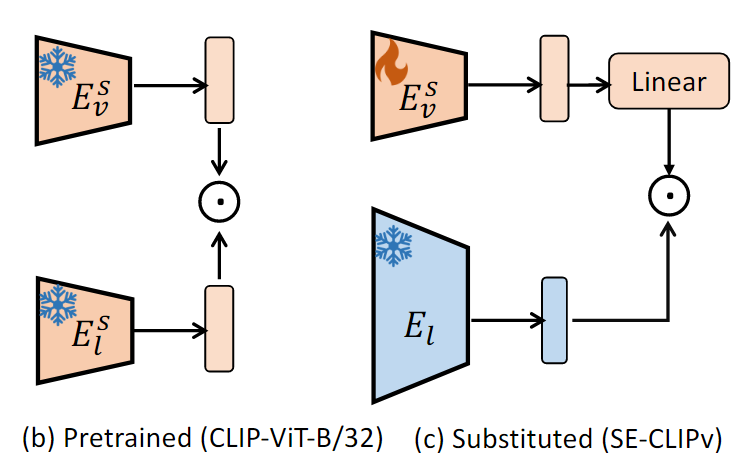
2. CLIP의 원래 Vision Encoder 를 더 작은 사전 학습된 모델인 CLIP-ViT-B/32로 대체하여 모델을 구성한다.
Language Encoder는 고정한(frozen) 상태로 Vision Encoder를 수정함
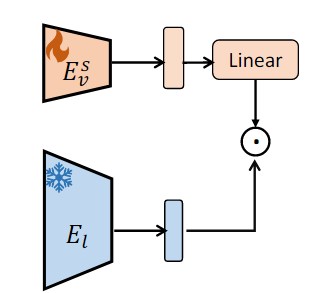
그러나, 수정된(Non-frozen) Vision Encoder와 고정된(Frozen) Language Encoder가 정렬이 잘 맞지 않아 추가적인 학습 필요
- 이에 따라 Linear layer와 Vision encoder를 fine-tuning함
하지만, 는 원래 CLIP과 비교하여 상당한 성능 저하가 발생하였다.
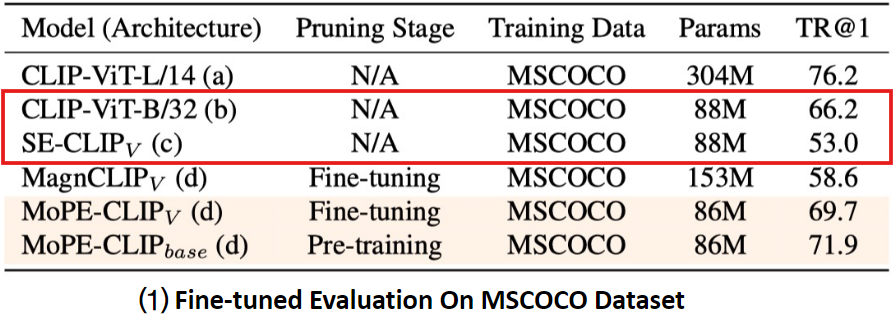
이 성능 저하는 서로 다른 vision-language 모델에서 유래된 분리된 인코더를 정렬하는 데 따르는 어려움에서 발생한 것으로 보인다.
기존 CLIP은 두 인코더가 함께 학습되어 이미지-텍스트 간 상호작용을 잘 이해하도록 최적화되어 있었으나,
새로운 vision encoder는 기존 language 인코더와 함께 학습한 것이 아니라 다른 데이터 분포를 학습하였기 때문에 조화를 이루지 못함
-> Pruning을 사용하는 대안을 탐구하는 데 초점을 맞추기로 함
성공적인 pruning을 위해 추가적인 연구 필요
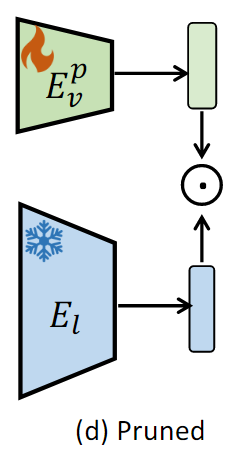
기존 CLIP모델에서 널리 채택된 전략인 Magnitude pruning(크기 기반 가지치기)을 사용한다.
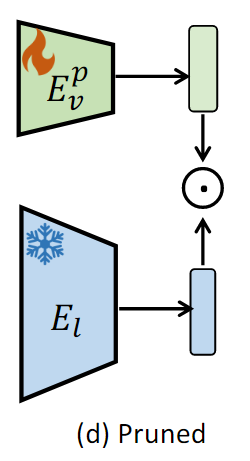
Attention Head와 FFN 뉴런을 매개변수 크기를 기준으로 pruning한다.
특정 매개변수의 크기보다 작은 모듈을 중요하지 않다고 간주하여 제거한다.
- 임계값을 조절하면 pruning된 모델의 크기가 달라진다.
pruning의 강도를 조정하면서 다양한 크기의 모델을 실험한 결과, 모델 매개변수의 최소 50% 이상을 유지해야지만 만족스러운 성능을 보장할 수 있었다.
즉, pruning 강도를 높여 매개변수의 50%이상을 제거하여 모델 크기를 줄이면 성능이 급격하게 저하되는 문제가 발생하였다.
MagnCLIPv는 매개변수의 크기를 기준으로 중요도를 판단한다.
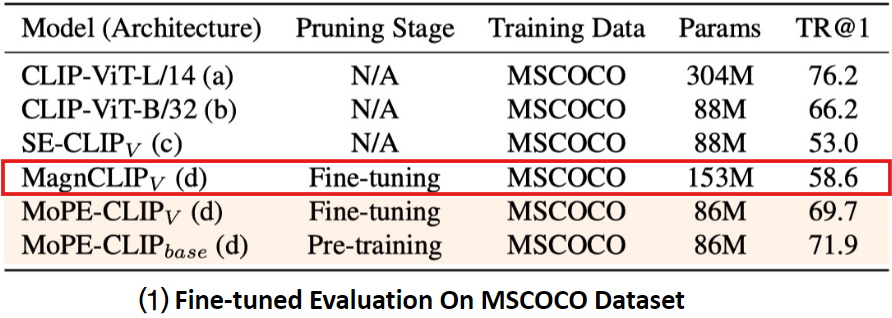
-> 매개변수 크기가 작더라도 모델의 성능에 중요한 역할을 할 수 있는 뉴런이 있는데 단순히 크기만으로 뉴런을 제거하다보니 cross 모달 성능(이미지-텍스트 검색)이 저하됨
모델 크기를 줄이면서도 성능을 유지하기 위해서는 Magnitude pruning외에 더 정교한 방법이 필요하다.
pre-training 및 fine-tuning pruning 모두 고려할 가치가 있음
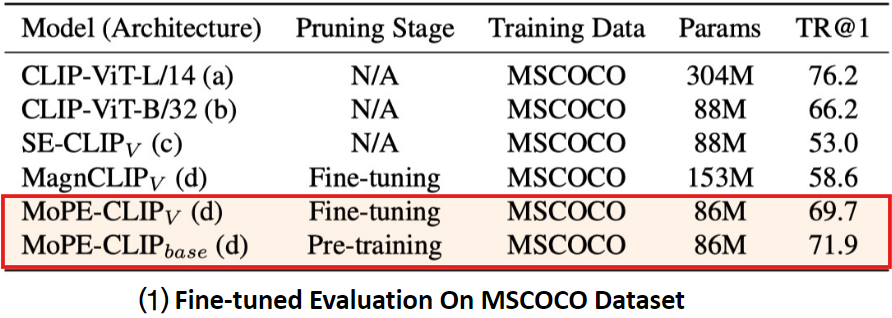
사전 학습(Pre-training) 단계에서의 가지치기와 미세 조정(Fine-tuning) 단계에서의 가지치기를 비교
동일한 크기로 줄어든 모델일 때, 어느 단계에서 pruning을 수행하는 것이 더 좋은 성능인지 확인
두 가지 pruning 방식 비교
- MoPE-CLIP(base)
- pre-training 단계에서 pruning을 수행한 모델
모델의 크기를 줄이는 작업이 pre-trained 데이터를 사용하는 동안 이루어짐
Pre-trained 단계에서 가지치기란?
사전 학습은 CLIP 같은 대규모 비전-언어 모델이 이미지와 텍스트 간의 연관성을 학습하는 과정이다.
학습 중간 단계에서, 특정 모듈을 제거했을 때의 성능 손실을 측정하여 중요도가 낮은 모듈부터 제거한다.
즉, 모델 학습 도중, 중요하지 않은 뉴런, 레이어, 또는 Attention Head를 제거해 모델 크기를 줄이는 작업
- MoPE-CLIPv
- fine-tuning 단계에서 pruning을 수행한 모델(특정 작업에 특화된 pruning)
모델의 크기를 줄이는 작업이 다운스트림 작업에 맞춰 이루어짐
다운스트림 작업에서 가지치기란?
CLIP 모델은 다양한 작업(예: 이미지-텍스트 검색, 텍스트 분류, 이미지 분류)을 수행할 수 있다.
이러한 작업을 다운스트림 작업이라고 한다.
특정 작업에서 중요하지 않다고 판단되는 뉴런, Attention Head, 레이어 등을 제거
중요도는 작업 성능(예: 이미지-텍스트 검색 정확도, 분류 정확도 등)에 기여하는 정도를 기준으로 판단
<pre-training 단계에서의 pruning>
-
장점 : 사전 학습 데이터는 대규모 병렬 데이터셋으로 구성되어 있어, cross 모달 상관관계를 학습하는 데 적합하고, 대규모 병렬 데이터를 사용할 수 있다.
-
단점 : 사전 학습 데이터가 크기 때문에 pruning 후 모델을 재학습하는 데 많은 자원 필요
<fine-tuning 단계에서 pruning>
-
장점 : 다운스트림 데이터는 사전 학습 데이터보다 크기가 작기 때문에 계산 비용이 적게 들고 효율적이다.
-
단점 : 다운스트림 작업에 특화된 데이터만 사용하기 때문에 범용성이 낮다.
3. Method
3.1. Module-wise Pruning Error
cross modal 비전-언어 모델에서 모듈(뉴런, 레이어, Attention head..)의 중요도를 정확히 평가하는 것은 pruning의 주요 과제이다.
중요도를 지표로 pruning을 하기 때문
기존의 pruning 메트릭은 cross modal 성능에 미치는 영향을 고려하지 않아, cross modal 작업에서 성능이 저하되는 주요 원인 중 하나였다.
magnitude pruning은 단순히 가중치 크기 순으로 pruning 했기 때문
이를 해결하기 위해 모듈 단위 가지치기 오류(Module-wise Pruning Error)MoPE라는 새로운 메트릭을 도입한다.
MoPE는 특정 모듈이 제거되었을 때 모델 성능이 저하되는 정도를 정량화하여, 이를 통해 각 모듈의 중요도를 평가한다.
MoPE는 두 가지 pruning 축에서 사용할 수 있다.
1. 너비 방향 : Attention head, FFN (수평적인 구성 요소 제거)
2. 깊이 방향 : Transformer layer (수직적인 구성 요소 제거)
MoPE는 pruning 모든 모듈에 대해 일관되고 정확한 기준을 제공한다.
MoPE 정의 및 계산
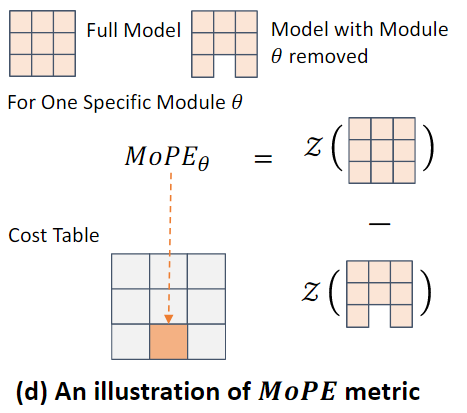
특정 모듈 𝜃의 중요도는 모듈 𝜃가 제거된 CLIP 모델 𝑓𝜑−𝜃와 전체 CLIP 모델 𝑓𝜑 간의 성능 저하로 경험적으로 측정된다.
- : 특정 모듈 𝜃의 pruning 오류(모듈 𝜃가 제거되었을 때 모델 성능에서 발생한 loss)
- 𝑍 : 제로샷 평가 함수(모델이 사전에 학습되지 않은 데이터를 입력 받았을 때 결과를 예측하는 능력을 평가)
- 𝑓𝜑 : 전체 CLIP 모델
- 𝑓𝜑−𝜃 : 모듈 𝜃를 제거한 CLIP 모델
- 𝑍[𝑓𝜑]: 모듈 𝜃가 포함된 전체 모델의 제로샷 평가 결과.
- 𝑍[𝑓𝜑−𝜃]: 모듈 𝜃가 제거된 전체 모델의 제로샷 평가 결과.
두 값의 차이는 검색 작업에서의 평가 지표로, Recall Mean을 사용
- Recall Mean: 모델이 상위 K개의 검색 결과 중 정답을 얼마나 잘 포함했는지 평가하는 지표입니다.
MoPE 값이 높은 모듈 𝜃는 pruning에 더 민감하며, cross modal 작업에서 중요한 역할을 한다는 것을 의미하여 pruning 과정에서 우선적으로 보존해야 한다.

MoPE𝜃를 활용하면 비용 테이블(C𝜃)을 쉽게 생성할 수 있다.
비용 테이블은 각 모듈의 중요도를 평가하고 저장한 데이터 구조이다

- 비용 테이블은 모든 모듈에 대해 MoPE𝜃 값을 저장한 것으로 정의된다.
(n은 모듈의 총 개수)

비용 테이블은 모듈별로 생성됨
- Chead: 모든 Attention Head에 대해 MoPE𝜃 값을 누적한 것
- Cneuron: 뉴런 그룹별 MoPE𝜃 값을 누적한 것
- Clayer: 레이어별 MoPE𝜃 값을 누적한 것
각 비용 테이블은 해당 모듈 범주에서 어떤 요소가 pruning 후 성능에 큰 영향을 미치는지 보여줌
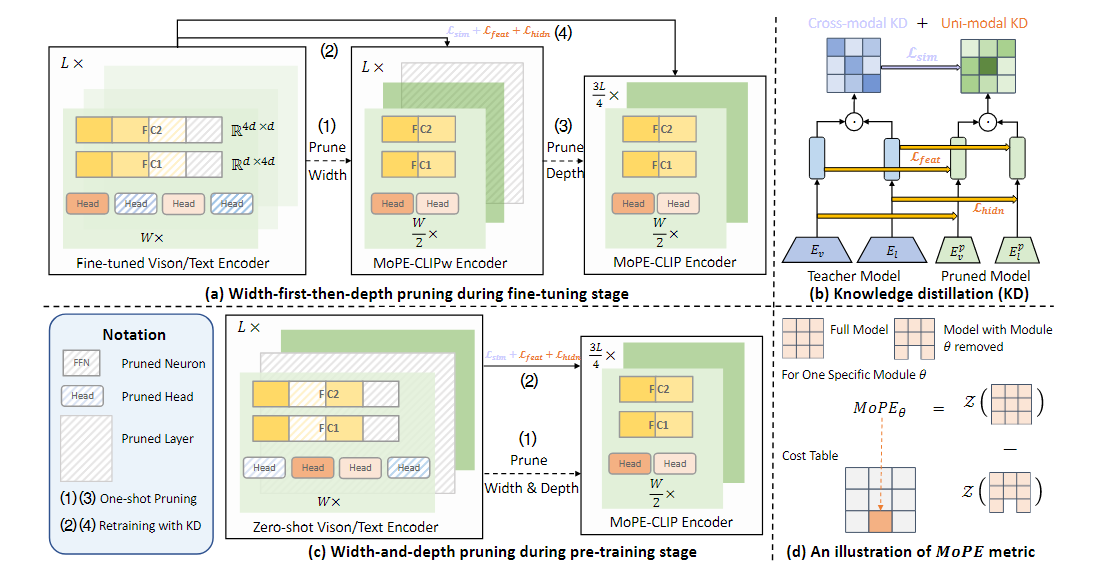
3.2. Unified Pruning Framework Based on MoPE(MoPE 기반 통합 pruning 프레임워크)
이 논문은 MoPE 메트릭을 기반으로 한 통합 pruning 프레임워크를 제안하며, 이 프레임워크는 사전 학습(pre-training) 단계와 미세 조정(fine-tuning) 단계 모두에서 효율적으로 작동한다.
Fine-tuning Stage
fine-tuning 단계에서 주요 과제는 task별 pruning 모델의 성능을 향상시키는 것이다
Fine-tuning 단계에서의 pruning은 다운스트림 작업에 최적화된 경량 모델을 생성하기 위한 과정이다.
분석 결과, 높은 compression 비율을 달성하기 위해서는 너비를 먼저 줄이고, 그다음 깊이를 줄이는 pruning 전력이 가장 효과적(width-first-then-depth strategy)임이 드러남
- 너비 방향 가지치기 (prune Width) : Attention head와 FFN 뉴런을 줄이는 과정
- 깊이 방향 가지치기 (prune Depth) : Transformer 레이어의 수를 줄이는 과정
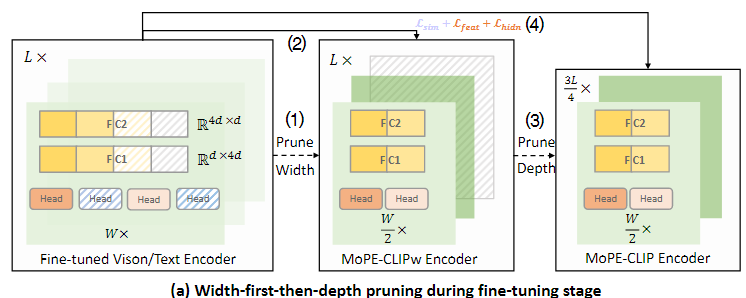
CLIP의 인코더 하나에는 L개의 레이어가 있고, 각 레이어는 multi-head attention블록과 FFN블록으로 구성된다.
너비를 먼저 줄이고, 깊이를 줄이는 pruning을 위해 먼저 fine-tuned된 모델을 너비 방향으로 압축한다.
1. 너비 가지치기
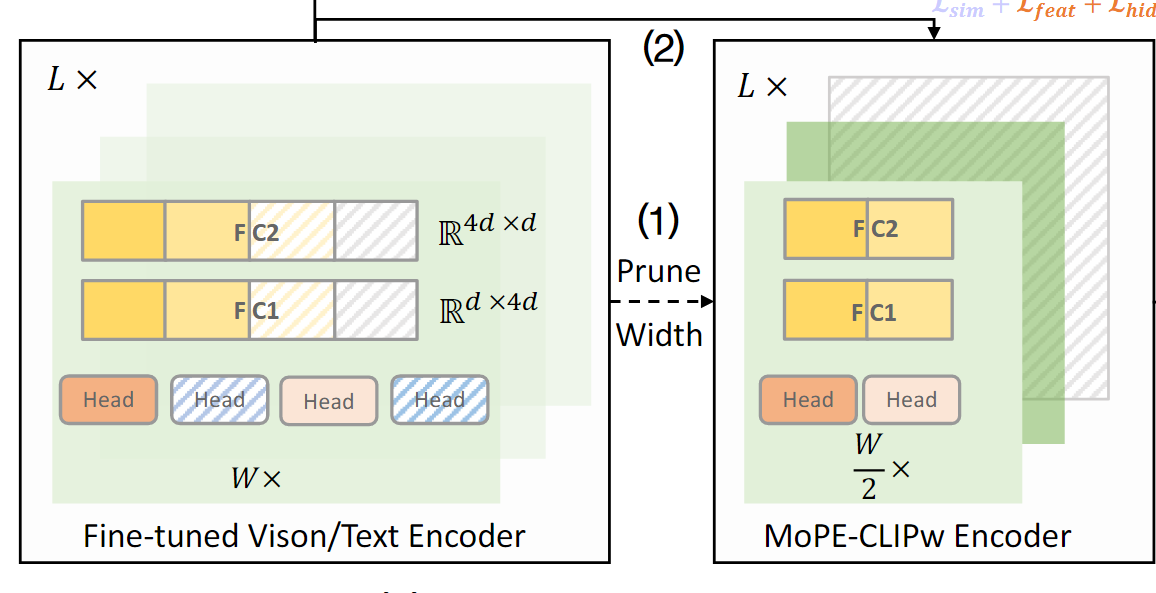
- MHA블록
개의 head를 가진 MHA블록이 L개 레이어만큼 존재할 때, 개의 head를 독립적으로 pruning해야 한다.
각각의 Attention head는 cross 모달 성능(예: 이미지-텍스트 검색)에 기여하는 정도가 다르기 때문에
개의 Attention head 각각에 대해 중요도를 평가해야 한다.
Multi-Head Attention 블록은 여러 개의 Attention Head를 포함하고 있다. Attention Head는 모델이 입력 데이터의 서로 다른 부분을 병렬적으로 주목(attend)할 수 있도록 도와주는 구조
MoPE 메트릭을 계산하여 각 head의 비용 테이블 Chead를 생성한다.
MoPE 메트릭은 특정 head를 제거했을 때 성능 저하를 측정한다. 즉, 각 head가 모델 성능에 얼마나 기여하는지를 평가한다.
MoPE메트릭을 기반으로 각 Attention head의 중요도를 기록한 비용 테이블을 생성한다.
- MoPE값을 기반으로 중요하지 않은 head부터 제거할 수 있도록 비용테이블 생성(비용 테이블은 모듈별로 MoPE 크기 순으로 정렬되어 있다)

- FFN 블록
FFN블록은 업-프로젝션 레이어 W1 ()와 다운-프로젝션 레이어
W2 ()로 구성된다.
업-프로젝션 레이어 W1은 차원 d를 dff로 확장한다. ()
입력 데이터를 더 큰 차원 공간으로 매핑
다운-프로젝션 레이어 W2는 차원 dff를 d로 축소 >
()확장된 데이터를 원래의 차원 공간으로 되돌림
는 중간 뉴런의 개수로 업-프로젝션과 다운-프로젝션 사이에 위치한다.
모든 중간 뉴런 를 열거하는 데 많은 시간이 소요되기 때문에, N개의 그룹으로 나누고 각 그룹의 MoPE를 측정하여 비용 테이블 을 생성한다.
- = 3072이고 N=12라면, 한 그룹에는 3072/12=256개의 뉴런이 포함
그룹별로 제거했을 때의 성능 저하를 평가하여 각 그룹의 MoPE값을 비용테이블에 저장한다.
- 비용 테이블에서 MoPE값이 낮은 그룹 부터 제거
중요하지 않은 head와 뉴런 그룹을 Pruning 후, 성능 손실을 줄이기 위해 고정된 교사 모델로부터 knowledge distillation하여 모델을 생성한다.
교사 모델(가지치기되지 않은 원본 모델)로부터 가지치기된 모델로 지식을 전달하여, 성능을 복구한다.
지식 증류를 통해 성능이 복구된 경량화 모델이 이다
깊이 가지치기
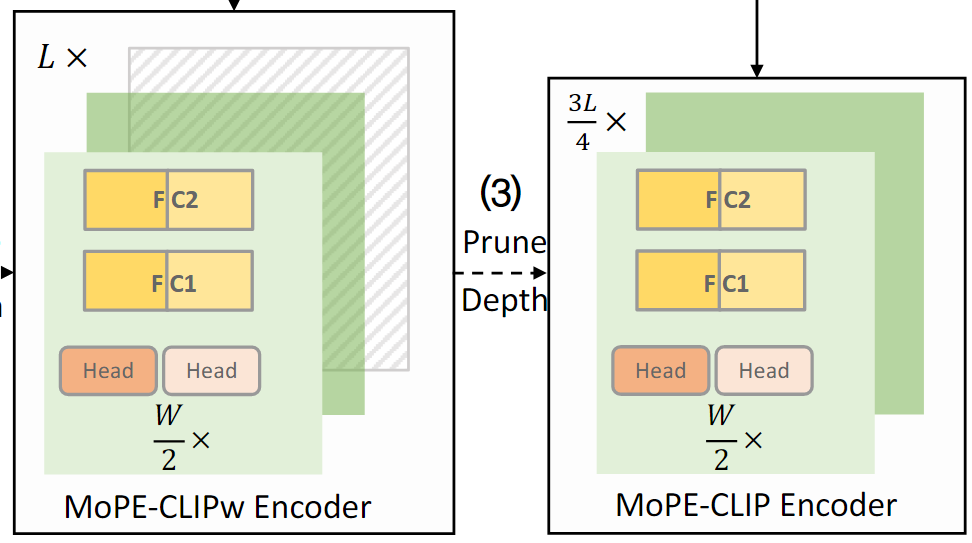
모델을 깊이 방향으로 compression한다.
너비 방향으로는 pruning이 완료된 모델이나 모든 레이어를 포함하고 있어 전체 레이어 중 일부를 제거하여 모델의 연산 깊이를 줄인다.
MoPE 메트릭을 L개의 Transformer 레이어에서 계산하여 비용 테이블 를 생성한다.
를 사용해 중요도가 낮은 레이어를 평가하고 제거한다.
Layer별로 제거했을 때의 성능 저하를 평가하여 각 Layer의 MoPe값을 비용테이블에 저장한다
MoPe값이 낮은 Layer부터 제거
- 최종 MoPE-CLIP모델
최종적으로, 고정된 교사 모델로부터 knowledge distillation하여 최종 MoPE-CLIP모델을 생성한다.
Pre-traning Stage
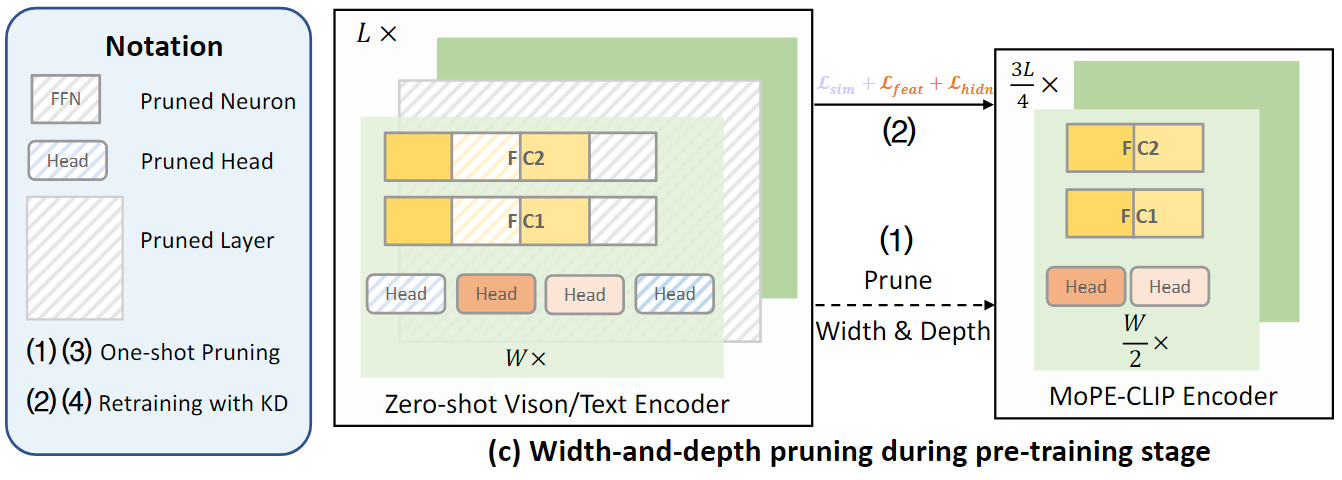
Pre-traning 단계에서 보다 일반적인 소형 모델을 생성하기 위해 대형 모델의 비전 및 텍스트 인코더를 동시에 압축한다
Width-first-then-depth strategy(너비-깊이 순서 가지치기 전략)은 재학습 과정(Distillation)을 포함하며 높은 비용이 발생하고,
Pre-training 동안 이미지-테스트 쌍이 추가되면서 각 재학습 과정마다 습득된 지식이 확장되기 때문에 너비 및 깊이 pruning을 단일 단계로 결합하여 수행한다.
Pre-training 단계에서 모든 모듈을 학습한 후에 pruning을 수행하면 비용이 매우 크기에 너비와 깊이 pruning을 한 번에 병렬적으로 수행한다.
pre-traning 단계에서, 단일 단계로 결합된 pruning을 수행하여 만들어진 경량화된 사전 학습 모델을 기반으로 fine-tuning 단계에서 width-first-then-depth strategy로 pruning을 수행한다.
제로샷 CLIP 모델의 vision 및 text encoder에 대해 head, 뉴런 그룹, layer의 MoPE를 병렬적으로 계산하여 비용 테이블을 생성한 후, pruning을 수행한다.
Vision/Text encoder의 모든 모듈(head, FFN의 뉴런 그룹, transformer layers)에 대해 병렬 처리로 MoPE를 동시에 계산한다.
너비와 깊이를 한 번에 결합하여 pruning한다.
- CLIP 모델
CLIP은 텍스트와 이미지 간의 연관성을 학습하는 대규모 비전-언어 모델이다.대규모 이미지-텍스트 쌍(예: "A cat sitting on a chair")으로 학습되어, 입력된 이미지와 텍스트가 얼마나 잘 매칭되는지 평가
- 제로샷 학습
별도의 fine-tuning 없이 사전 학습된 모델이 새로운 작업에 바로 적용될 수 있는 것을 의미
- 제로샷 CLIP 모델
사전 학습된 데이터만으로도 별도의 fine-tuning없이 다양한 작업(예: 이미지 분류, 이미지-텍스트 검색)을 수행할 수 있는 비전-언어 모델
이후, 소형 이미지-텍스트 pre-training 데이터셋을 이용하여 pruning된 모델을 재학습하여 MoPE-CLIP모델을 얻는다.
만들어진 모델을 fine-tuning 단계에서 사용된다.
Pruning Efficiency
각 모듈에 대해 MoPE 메트릭을 계산하는 데 몇 초밖에 걸리지 않고, 모든 모듈에 대한 MoPE 계산이 병렬적으로 수행할 수 있다
병렬 계산 덕분에 대규모 모델에서도 계산 속도가 매우 빠르다
따라서, 비용테이블을 생성하는 데 걸리는 전체 시간은 완전한 fine-tuning, pre-training과정을 완료하는 데 걸리는 시간보다 훨씬 적다.
Fine-tuning 단계에서 너비와 깊이를 병렬적으로 pruning하지 않는 이유?
Fine-tuning 단계의 주요 목적은 특정 다운스트림 작업(예: 이미지-텍스트 검색, 제로샷 분류 등)에 대해 모델을 최적화하는 것이다.
따라서, pruning는 단순히 모델 크기를 줄이는 것뿐 아니라, 작업에 중요한 정보가 손실되지 않도록 조심스럽게 설계되어야 한다.
1. 너비와 깊이 가지치기가 모델에 미치는 영향이 다르다
너비 가지치기를 통해 모델의 각 layer의 구조를 간소화하면, 미세한 구조적 변화를 일으키고,
깊이 가지치기를 통해 모델의 layer자체를 제거하여 모델의 계층적 처리 능력을 줄이는 변화를 만든다.
먼저 너비를 가지치기하여 성능에 미치는 영향을 최소화하고, 깊이를 가지치기하여 추가적으로 모델을 경량화한다.
2. 병렬 수행이 성능 손실을 증가시킬 가능성이 높다
3. Fine-tuning 단계의 세밀한 최적화 요구
Fine-tuning 단계는 특정 작업에 특화된 모델을 만드는 과정이기 때문에, 세밀한 최적화가 중요하다.
너비 → 깊이 순서로 가지치기하면, 모델의 성능 손실을 점진적으로 평가하고, 필요할 경우 가지치기 전략을 조정할 수 있다.
pre-training에서는 계산 효율성을 극대화하고, 빠르게 모델 크기를 줄이는 것에 중점을 두었기 때문에 성능 손실에 대한 세밀한 조정보다는 효율성이 중요하다.
3.3. Distillation to MoPE-CLIP(MoPE-CLIP으로의 지식 증류)
교사 모델인 CLIP으로부터 pruning된 학생 모델인 MoPE-CLIP으로 cross modal지식과 단일 modal 지식을 전달하기 위한 distillation을 설계
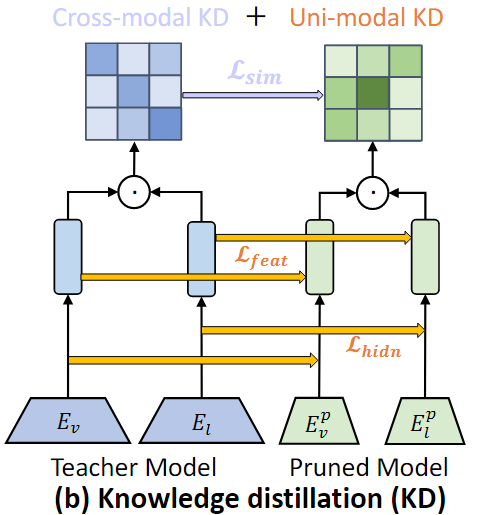
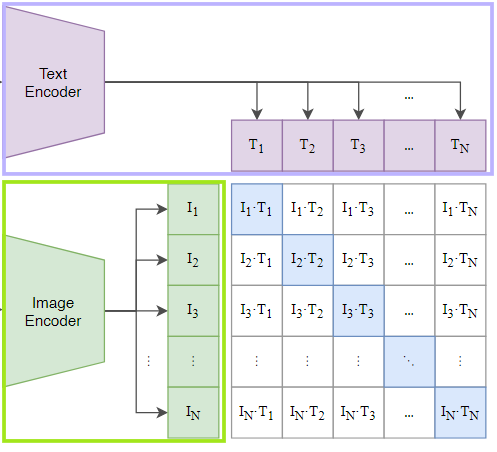
Cross-modal Knowledge
cross modal 지식이란 서로 다른 두 모달리티 간 관계를 학습하여 동일한 임베딩 공간으로 Align하는 것으로 CLIP모델에서는 이미지와 텍스트를 같은 임베딩 공간에 매핑하여 두 데이터의 상호 관계를 모델링한다.
임베딩 공간은 벡터 공간으로, 데이터가 숫자 벡터로 표현되는 장소로 서로 연관된 데이터는 가까운 위치에 매핑되어 내적값이 크다
텍스트와 관련 없는 이미지는 임베딩 고간에서 멀리 떨어진 위치에 매핑된다
즉, 텍스트가 주어졌을 때 관련된 이미지를 검색하거나, 이미지가 주어졌을 때 관련된 텍스트를 예측하는 능력을 학습한다.
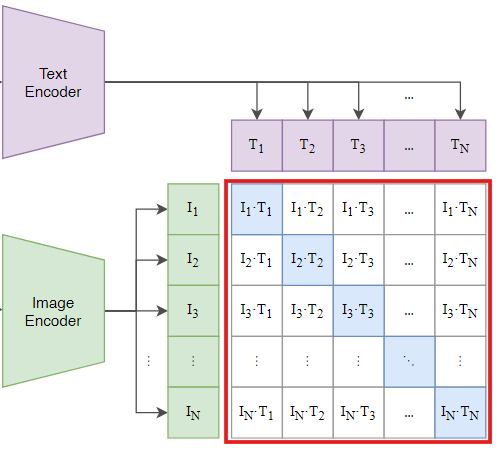
CLIP모델(교사 모델)은 검색 및 분류 작업을 위해 cross modal similarity matrix를 계산한다.
cross modal similarity matrix이란 텍스트와 이미지 쌍 각각의 유사도를 나타내는 행렬 형태의 데이터이다.
similarity matrix의 행은 텍스트, 열은 이미지를 나타내여 행렬의 각 원소는 해당 텍스트와 이미지 간 유사도를 나타낸다.
유사도는 주로 코사인 유사도를 사용하여 구한다.

교사 모델은 텍스트와 이미지 간의 더 밀접하게 정렬된 관계를 학습하여, 높은 품질의 cross modal similarity matrix를 생성하며 이는 pruning된 학생 모델이 학습해야 할 정답 역할을 한다.
학생 모델은 크기가 줄어들어 교사 모델과 동일한 수준의 관계를 학습하기 어렵기에 교사 모델의 cross modal similarity matrix를 학생 모델이 학습하도록 설계한다.
Soft cross entropy loss(SCE)
SCE는 교사 모델의 similarity matrix()와 학생 모델의 similarity matrix() 간 차이를 최소화하는 손실 함수이다.
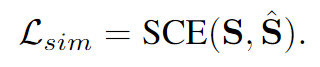
: 학생 모델에서 계산된 유사도 매트릭스
: 교사 모델에서 계산된 유사도 매트릭스
각 Siliarity matrix에 대해 softmax함수를 사용하여 각각 확률 분로 변환시킨 후, Cross-entropy 공식을 사용하여 loss값을 구한다.
두 similarity matrix가 최대한 비슷하게 만들기 위해 SCE값을 최소화하는 것이 목표이다.
Uni-modal Knowledge
교사 모델은 더 우수한 vision encoder와 text encoder를 보유하고 있기 때문에 이러한 더 우수한 encoder에 내재된 지식을 학생 모델로 전달하는 것이 중요하다.
이를 위해 MSE를 사용하여 학생 모델의 feature 표현이 교사 모델의 feature표현과 최대한 유사하도록 보장한다.
또한, Intermediate layer Distillation을 수행하여 교사 모델에서 학생 모델로 hidden state 지식을 전달한다.
각 transformer 레이어의 출력이 이에 해당되며 Depth pruning된 학생 모델은 교사 모델에서 보존된 중간 레이어를 최대한 모방해야 한다.
두 가지 주요 측면에서 교사 모델의 지식을 학생 모델로 전달한다.
1. 최종 출력의 특징 표현 : 이미지 또는 텍스트 인코더의 최종 출력
2. 중간 레이어의 hidden state : 각 transformer 레이어의 출력
최종 출력의 특징 표현
최종 출력의 특징 표현이란 이미지, 텍스트 encoder가 입력 데이터를 처리한 후 생성하는 최종 벡터로 모델이 데이터에 대해 학습한 최종적인 요약 정보를 나타낸다.
모델이 텍스트와 이미지를 같은 임베딩 공간으로 변환하여 이미지와 텍스트 간의 관계를 이해하는 데 핵심적인 역할을 하기 때문에
학생 모델의 최종 출력이(feature representation) 교사 모델처럼 표현할 수 있게 학습
교사 모델의 이미지와 텍스트 출력 벡터와 학생 모델의 이미지와 텍스트 출력 벡터 간 MSE을 계산한다.
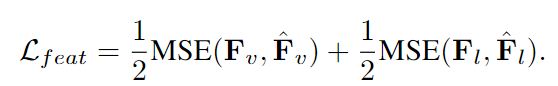
중간 레이어의 hidden state
hidden state는 각 transformer 레이어가 입력데이터를 처리하면서 생성하는 중간 결과로 모델의 hidden layer(은닉층)은 데이터의 점진적인 특성을 학습하기 때문에 중요한 정보를 포함한다.
학생 모델의 각 Transformer 레이어 출력이 교사 모델의 Transformer 레이어 출력과 유사하도록 학습
transformer에서 레이어는 각 레이어는 이전 레이어의 출력을 받아 새로운 출력을 생성하는 형태로 레이어는 Attention와 FFN으로 구성되어 있다.
transformer에서 레이어는 Attention과 FFN의 조합으로 이루어진 메커니즘을 반복적으로 사용하는 단위를 말함
교사 모델과 학생 모델의 두 모달리티에 대해 각각 중간 레이어 출력 간 MSE를 계산한다.
-
vision 지식 손실
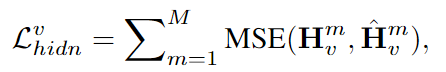
각 레이어 별 출력 값에 대해 MSE를 구한 값을 모두 더하여 계산한다.vision transformer 인코더 내 m번 째 vision 레이어에서의 출력값을 의미
-
text 지식 손실
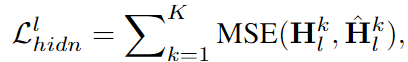
-
총 hidden state 손실
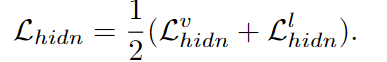
Uni-modal Knowledge는 텍스트 인코더와 비전(이미지) 인코더 각각의 독립적인 출력(Feature)과 중간 계층(hidden state)에 대한 지식 증류
텍스트와 이미지를 독립적으로 처리하여 벡터 생성
Cross-modal Knowledge는 Uni-modal Knowledge에서 나온 텍스트와 이미지 인코더의 최종 출력을 기반으로 텍스트와 이미지 간의 관계를 지식 증류
Uni-modal에서 생성된 벡터를 사용하여 텍스트와 이미지 간 관계 학습
Learning Objective(학습 목표)
학습 목표는 Cross-modal Knowledge와 Uni-modal Knowledge를 결합하고, 여기에 추가로 대조 손실(Contrastive Loss)을 더하여 최종적인 손실 함수로 구성한다.
- Cross-modal KD(Knowledge)
- : 교사 모델과 학생 모델의 유사도 매트릭스 간 손실 (텍스트와 이미지 간 관계 학습)
- Uni-modal KD(Knowledge)
- : 교사 모델과 학생 모델의 인코더의 최종 출력 간 손실 (텍스트 또는 이미지 각각의 정보 학습).
- : 교사 모델과 학생 모델의 인코더의 중간 레이어(hidden states) 간 손실 (텍스트 또는 이미지의 중간 계층 정보 학습).
- Contrastive Loss (𝐿itc)
학생 모델이 텍스트-이미지 유사도를 더 잘 학습하도록 추가적인 제약을 부여하는 손실
최종 Loss Function
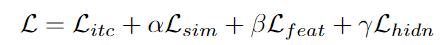
가중치 (𝛼,𝛽,𝛾): 각 손실 항목의 중요도를 조정하기 위한 가중치
- 논문에서는 𝛼=1, 𝛽=, 𝛾=1로 설정함
손실 함수를 이렇게 구성한 이유?
- : 교사 모델의 similarity matrix와 학생 모델의 similarity matrix가 최대한 비슷해지게 만들기 위해
- : 텍스트/이미지 인코더 각각의 출력 벡터가 교사 모델과 유사하게 만들기 위해
- : 텍스트/이미지 인코더의 hidden layer를 교사 모델과 유사하게 만들어 feature를 학습하는 중간에 정보 손실을 최소화하게 하기 위해
- : 올바른 이미지-텍스트 쌍은 가깝게, 잘못된 쌍은 멀리 배치하도록 학습하기 위해
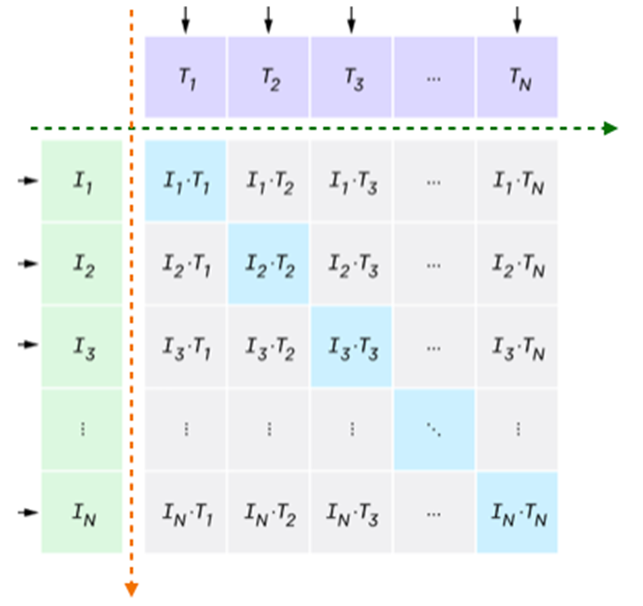
각 이미지에 올바른 텍스트인 n개의 대각선 요소를 정답 레이블로 설정한 후, 정답 레이블의 확률은 높여 손실을 줄이고, 잘못된 쌍의 확률은 낮추도록 학습한다
- 와 차이점
원래 CLIP 모델(교사 모델)은 "고양이가 창가에 앉아 있다"라는 텍스트와 창가에 앉은 고양이 이미지를 유사도가 0.95라고 학습
=>
하지만 Pruning된 학생 모델(MoPE-CLIP)은 같은 쌍을 0.80로 학습할 수도 있음
이때, Cross-modal Similarity Loss가 학생 모델이 교사 모델의 유사도인 0.95로 학습하도록 강제함=>
4. Experiments
다른 Pruning 모델과 비교 실험 결과
Fine-tuning stage compression
Image-to-text retrieval
Vision Encoder의 크기(WIDTH, DEPTH)와 매개변수 개수(PARAMS)를 다르게 설정하여 성능을 비교
MSCOCO 데이터셋(5K test set)에서 검색 성능 평가
- TR@1: 최상위 1개 검색 결과가 정답일 확률
- TR@5: 최상위 5개 검색 결과 중 정답이 포함될 확률
- TR@10: 최상위 10개 검색 결과 중 정답이 포함될 확률
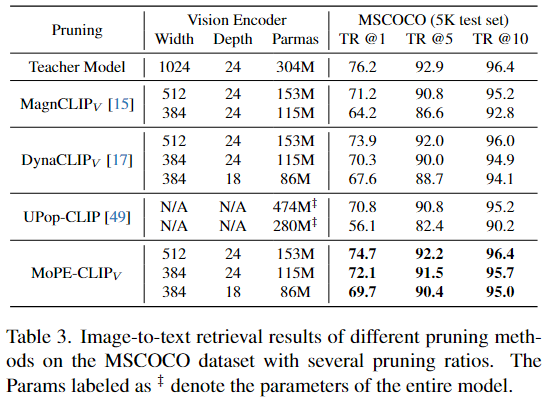
같은 모델 크기에서 MoPE 방식이 더 높은 검색 성능을 제공
Text-to-image retrieval
Text Encoder의 크기(WIDTH, DEPTH)와 매개변수 개수(PARAMS)를 다르게 설정하여 성능 비교
MSCOCO 데이터셋(5K test set)에서 검색 성능 평가
- IR@1: 최상위 1개 검색 결과가 정답일 확률
- IR@5: 최상위 5개 검색 결과 중 정답이 포함될 확률
- IR@10: 최상위 10개 검색 결과 중 정답이 포함될 확률

같은 모델 크기에서 MoPE 방식이 더 높은 검색 성능을 제공
Pre-training stage compression
Zero-shot image-text retrieval
MSCOCO와 Flickr30K 데이터셋을 이용
다양한 Pruning 및 Pre-training 방법을 적용한 모델들의 Zero-shot 이미지-텍스트 검색 성능을 비교
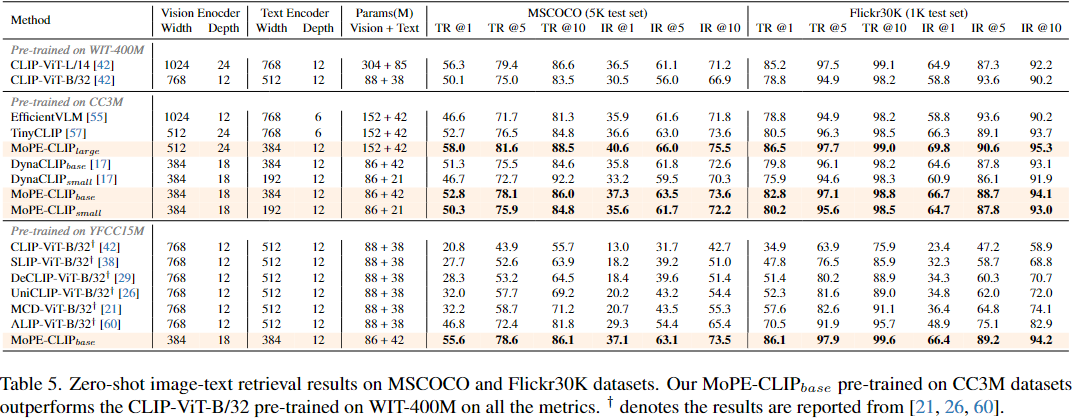
MoPE 방식이 모델을 압축하면서도 성능을 잘 유지하는 효과적인 방법임을 입증
Zero-shot image classification
다양한 데이터셋으로 사전 학습된 모델들의 Zero-shot 이미지 분류 성능(Top-1 정확도 %)을 비교
전체 Sample에 대해 모델이 가장 높은 확률로 예측한 정답이 실제 정답과 정확히 일치하는 비율

기존 모델보다 효율적이며, 더 적은 학습으로 더 좋은 성능을 달성
