Remote Sensing(원격 감지)
물리적 접촉 없이 멀리 떨어진 곳에서 원격으로 정보를 수집하는 기술
직접 가서 눈으로 보거나 만지지 않고, 위성이나 드론, 레이더와 같은 장비를 이용해서 데이터를 모으는 기술
사용 분야
- 환경 : 자연재해 모니터링으로 감지 및 추적
- 도시 : 건물이나 도로 정보, 교통량 분석
- 농업 : 작물이 잘 자라고 있는지 확인
- 기후 변화 : 빙하가 얼마나 녹고 있는지 관찰
전자기파를 기반으로 한 기술로, 주로 빛(가시광선), 적외선, 마이크로파 등이 사용
장점
- Remote sensing을 사용하면 넓은 지역의 데이터를 짧은 시간 내 수집할 수 있다.
- 물리적으로 접근하기 어려운 지역도 분석 가능
- 시간에 따른 변화 탐지 가능
Abstract
Remote sensing 이미지는 지속 가능한 개발 목표를 정하고 기후 변화 문제를 해결하는 데 활용될 수 있다.
하지만, VLM 개발에 필요한 대규모 및 의미론적으로 다양한 image-text 데이터셋이 remote sensing 이미지 분야에는 아직 존재하지 않는다.
VLM은 대규모 image-text 데이터셋이 필수적인데 Natural이미지는 대규모 데이터 수집이 쉽지만, Remote sensing 이미지는 text설명이 붙어 있는 대규모 데이터셋을 구할 수 없다.
이러한 이유로 remote sensing 데이터를 학습할 VLM 모델을 개발하기가 어렵다.
데이터셋이 없으면 모델 학습 자체가 불가능하거나, 성능이 낮을 수밖에 없다
본 연구에서는 이 문제를 해결하기 위해 SkyScript라는 데이터셋을 만들었다.
remote sensing 이미지와 OpenStreetMap(OSM)에 포함된 풍부한 의미를 자동으로 연결하기 위해 지리 좌표를 사용하는 새로운 방법을 제시
Introduction
Remote sensing 이미지는 achieving Sustainable Development Goals(SDGs - 지속 가능한 개발 목표)를 달성하고 기후 변화 문제를 해결하는 데 중요한 역할을 한다.
Remote sensing 이미지를 활용한 computer vision은 농작물 수확량 예측, 산림 벌채 탐지, 재생 가능한 에너지 자원 매핑..등 다양한 응용 분야에서 자동화를 가능하게 한다.
기후 변화로 인한 위기에 대응하기 위해 remote sensing 이미지와 이를 분석하는 vision 모델은 지구 표면 관찰, 취약한 인프라 및 인구 식별 등 다양한 방식으로 위기를 완화하는 데 기여할 수 있다.
remote sensing 이미지를 활용하는 supervised learning(지도학습) 모델은 특정 task를 수행할 수 있도록 많이 개발되었지만, CLIP과 같은 task-agnostic한 VLM은 아직 활용되지 못하고 있다.
remote sensing 이미지를 활용하는 task-agnostic한 VLM은 개발이 아직 미흡하다.
CLIP과 같은 VLM은 다양한 task에서 일반화할 수 있는 능력이 있지만, 대규모이면서 의미적으로 다양한 이미지-텍스트 데이터셋에 의존적이다.
하지만, Remote sensing 이미지는 이러한 대규모 데이터셋이 부족하기 때문에 VLM에서는 아직 활용되지 못하고 있다.
<Remote sensing 이미지 데이터셋이 부족한 이유>
- Remote sensing 이미지는 주로 정부 기관, 국제 기구의 소유
- Remote sensing 이미지는 비용을 지불해야 제공받을 수 있고 인터넷에서 크롤링 할 수 없다.
- Remote sensing 이미지를 얻을 수 있더라도, Natural 이미지처럼 semantic한 텍스트가 엮여있지 않다.
remote sensing 이미지를 주석 처리하려면 해당 분야에 대해 친숙함이 필요한데, 사람이 직접 주석을 달며 대규모 및 semantic이 다양한 데이터를 얻는 것도 어려운 과제이다.
이 연구에서는 SkyScript라는 대규모이면서 의미적으로 다양한 이미지-텍스트 데이터셋을 구축하여 이러한 한계를 극복한다.
1. 지리 좌표와 OpenStreetMap 활용
- Google Earth Engine에서 얻은 텍스트 정보가 없는 remote sensing 이미지와 OpenStreetMap 데이터베이스의 semantic한 텍스트 정보를 지리적 좌표를 통해 연결하여 데이터 셋을 만듦
2. 데이터셋 규모
- 260만 개의 이미지-텍스트 쌍
- 29,000개의 다양한 semantic 설명
SkyScript를 사용하여 VLM을 지속적으로 pre-training하여 CLIP모델의 성능을 향상 시켰고 뛰어난 성과를 보임
1. Zero-shot scene classfication(제로샷 장면 분류)
2. fined-grained attribute classification(세부 속성 분류)
3. Cross modal retrieval(크로스 모달 검색)
Related Work
Vision-language model(VLM)
이미지를 텍스트 설명과 연결하는 것이 vision representation을 학습하는 effective한 approach임이 입증되었다.
CLIP과 그 후속 연구들은 대규모 image-text 데이터셋으로 학습할 때 VLM이 다양한 task에서 일반화가 잘되고 안정적임을 보여주었다.
특히 CLIP은 contrastive learning으로 이미지와 텍스트 표현을 align하여 학습한 표현을 다양한 computer vision task에 제로샷 방식으로 transfer할 수 있게 했다.
하지만, remote sensing 이미지를 위한 VLM은 대규모 remote sensing 이미지-텍스트 데이터셋이 없어 충분히 탐구되지 않았다.
Foundation models for remote sensing(원격 감지용 기초 모델)
최근의 self-supervised learning의 발전을 따라가, remote sensing의 기초모델을 개발하는 연구가 2가지 방향으로 탐구되었다.
-
같은 장소를 서로 다른 시간, 각도, 조건에서 촬용한 다른 이미지들 사이의 유사성을 학습하는 방법
같은 장소를 다양한 관점에서 일관되게 이해하는 능력을 키울 수 있다.
remote sensing 이미지에서는 동일한 지역이 조건에 따라 다르게 모일 수 있기 때문
-
이미지의 패치를 masking하고, masking된 부분을 주변 픽셀과 같은 다른 정보를 사용해 복원하도록 학습하는 방법
remote sensing 이미지에서는 구름으로 인해 덮인 장소와 같이 가려진 정보나 누락된 데이터를 추론해야 할 때가 많기 때문
두 방법으로 학습된 모델은 remote sensing 이미지 데이터만을 사용하기 때문에, 다양한 task에 적용시키기 위해서는 추가적인 fine-tuning이 필요하므로 비효율적이다.
최근에 Remote sensing을 위한 CLIP 연구가 있었는데, 데이터의 부족으로 인해 좋은 성능을 내지 못했다.
그래서 SkyScript 같은 대규모이면서 의미적으로 다양한 데이터셋이 필요하다.
Remote sensing dataset
remote sensing 이미지는 전문 지식을 필요로 하기 때문에 대규모이면서 의미적으로도 다양한 데이터셋을 구하는 것이 어렵다.
100만개 이상의 이미지를 포함한 데이터셋은 드물며, 이 데이터셋들은 semantic 클래스 수도 150개 이하로 적다.
기존의 remote sensing 이미지-텍스트 데이터셋은 작은 규모로 몇백에서 몇만 개의 이미지만 포함한다.
최근 연구는 기존 remote sensing 데이터셋을 집계하고 caption을 자동으로 생성하여 약 17만개의 remote sensing 이미지-텍스트 데이터셋을 구축했지만, 이미지에 포함된 클래스 수가 의미적으로 다양하지 못해 제한되었다.
Dataset
Data collection approach(데이터 수집 접근법)
SkyScript 데이터셋은 대규모로 수집된 remote sensing 이미지 데이터를 OSM(OpenStreetMap)의 지리적 텍스트가 포함된 의미 정보와 연결하여 생성되었음
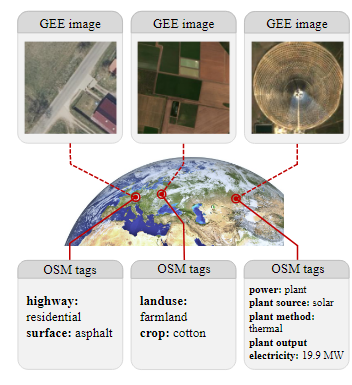
- image 수집, semantic 수집
- 2단계 태그 분류 접근법
- 데이터셋에 포함할 object 선택
- object를 시각적으로 표현할 수 있는 image 선택
- 태그를 사용하여 image에 맞는 캡션 생성
Source of images(이미지 소스)
open remote sensing image-text 데이터셋에 포함된 데이터는 연구 목적으로 사용하기 위해 license 제약이 없어야 한다. 이를 위해 Google Earth Engine(GEE)를 사용하여 대규모 remote sensing 이미지를 다양한 소스에서 수집함
GEE는 대규모 remote sensing 이미지 컬렉션에 대한 public한 접근을 제공하고, 데이터의 공유와 재배포를 허용함
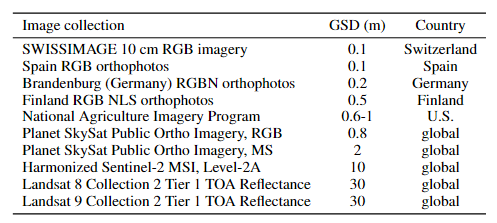
SkyScript에서 사용된 이미지 컬렉션과 해상도를 나열
다중 source 및 다중 resolution의 이미지 풀로 구성되어 있고, GSD가 0.1m/픽셀에서 30m까지 다양하다.
Source of semantics(의미 정보 소스)
VLM의 일반화를 가능하게 하기 위해, 데이터셋에 포함된 semantic 정보는 단순히 다양한 object 카테고리 뿐만아니라, 세부적인 하위 카테고리도 포함해야 한다.
Remote sensing 이미지의 이러한 격차를 해결하기 위해 OSM(OpenStreetMap)에 포함된 풍부한 semantic 정보를 활용했다.
OSM은 사람들이 직접 데이터를 입력하는 crowdsourced geographic database이다.
OSM에서 지도 상의 각 object는 하나 이상의 태그로 설명된다.
각 태그는 자유 형식의 두 가지 텍스트 필드로 구성
- 키(key) : 주제, 카테고리, 특징 유형 설명(예 : 표면)
- 값(value) : 키에 따라 특정 특징, 속성, 하위 카테고리 설명(예 : 아스팔트)
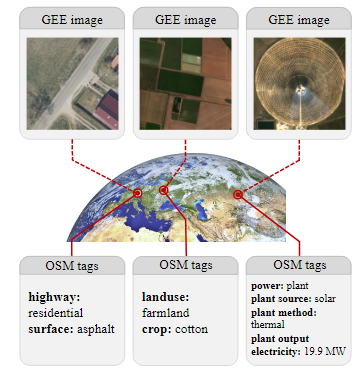
이전에는 OSM의 풍부한 semantic 정보는 supervised learning을 위한 remote sensing 데이터셋 구축에서 제대로 활용되지 못했다.
OSM 데이터의 검증되지 않은 특성때문에 신뢰도가 낮을 수 있다는 우려가 존재했기 때문이다.
하지만, 웹 크롤링을 기반으로 한 contrastive image-text pre-training을 통해서 정제되지 않은 데이터셋도 semantically diverse한(의미적으로 다양한) 이미지-텍스트 데이터셋을 생성할 수 있는 능력을 보여주었다.
이러한 intuition(직관)을 기반으로 OSM의 검증되지 않았지만, 의미적으로 풍부한 데이터를 활용하여 데이터셋을 구축하였다.
OSM은 사람들이 직접 데이터를 입력하는 crowdsourced geographic database이기 때문에 검증되지 않은 오류가 있을 수 있다.
하지만, 노이즈가 많아도, 데이터가 의미적으로 다양하면 유용한 데이터셋을 만들 수 있다고 판단
Connect images with appropriate semantics(이미지와 적절한 의미 정보 연결하기)
OSM에서 일부 태그는 remote sensing 이미지에서 시각적으로 설명될 수 있지만, 일부 태그는 시각적으로 설명되지 않을 수 있다.
또한, 특정 해상도(GSD)에서 충분히 큰 객채(예 : 해안선)은 시각적으로 설명될 수 있지만, 작은 객체(예 : 전봇대)는 설명되지 않을 수 있다..
- 태그가 나타내는 객체가 remote sensing 이미지에서 눈에 보이는 경우 시각적으로 확인 가능하다고 말한다.
- GSD가 작을 수록 고해상도로 더 작은 객체를 확인할 수 있다.
객체 크기가 크면 해상도가 낮아도 시각적으로 쉽게 확인 가능
이미지를 설명하기 위해 어떤 태그를 포함시켜야 할지를 결정하기 위해 두 단계의 태그 분류 접근법을 개발하였다
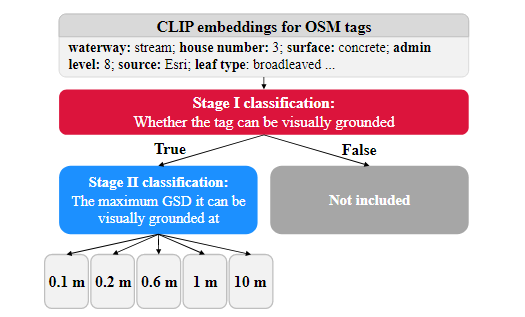
CLIP 임베딩을 사용하여 태그(키+값)을 입력으로 제공
- CLIP 임베딩은 이미지-텍스트 pre-training을 통해 태그의 시각적 정보를 이미 인코딩했기 때문에 사용됨
CLIP은 이미지와 텍스트를 같이 학습했기 때문에 텍스트 태그가 어떤 시각적 이미지와 관련이 있는지를 이미 학습한 상태이다.
따라서, CLIP 임베딩을 사용하면 텍스트 태그가 시각적으로 어떤 이미지와 연관이 있는지 빠르게 파악할 수 있다.CLIP의 임베딩을 사용하면, 이미지 없이도 태그가 이미지에서 가지는 시각적 특성을 로지스틱 회귀 모델이 이해할 수 있도록 도와주는 역할을 한다.
1단계
binary logistic regression 모델을 사용하여 태그가 시각적으로 확인 가능한지를 예측한다.(yes/no)
OSM에서 제공하는 태그는 매우 많고 다양한데 이 중 일부 태그가 나타내는 객체가 remote sensing 이미지에서 시각적으로 확인되지 않거나 유용하지 않을 수 있기 때문에 유용한 태그와 그렇지 않은 태그를 구분한다.
- CLIP 임베딩 벡터를 입력으로 사용한다.
로지스틱 회귀 모델 작동 원리
1. 입력 데이터를 가중치와 곱한 뒤 더한다.
2. 시그모이드 함수에 통과시켜 확률 값 계산
3. 계산된 확률 값을 임계값을 기준으로 yes/no를 결정
1단계를 위한 모델을 학습하기 위해
준비된 태그 데이터에 대한 정답 값을 준비하고, 모델이 예측한 값과 정답을 비교하여 loss를 계산하고 가중치를 조정하며 데이터를 학습한다.
학습은 5-fold cross validation을 사용하여 데이터의 일반화 성능을 측정한다.
데이터를 5개 묶음으로 나누어 5번의 학습-평가 과정 진행
- 각 단계에서 4개 폴드를 학습 데이터로, 1개 폴드를 테스트 데이터로 사용하여 5번 반복하며 모든 폴드가 한 번씩 테스트 데이터로 사용됨
5-fold cross validation을 수행하면서 로지스틱 회귀 모델의 하이퍼파라미터를 조합해보며 최적의 하이퍼파라미터를 선택한다.
최적의 하이퍼파라미터를 가진 모델로 최종 학습 후, 시각적으로 확인 가능한 것으로 예측 되면, 다음 단계 진행
2단계
1단계에서 확인 가능(yes)로 분류된 태그만 2단계로 넘어온다.
multi-class logistic regression 모델을 사용하여 태그가 시각적으로 확인 가능한 최대 GSD를 예측한다.
어떤 객체는 고해상도에서만 확인이 가능하고, 어떤 객체는 저해상도에서도 확인이 가능하기 때문에, 태그가 나타내는 객체가 어떤 해상도에서 확인 가능한지를 모델이 예측해야 한다.
multi-cliss logistic regression이란
여러 범주(class) 중 하나를 선택하는 분류 모델
- 여기서는 GSD의 5가지 범주(0.1m, 0.2m, 0.6m, 1m, 10m) 중 하나를 예측
- 예측값은 0.1, 0.2, 0.6, 1, 10(m)중 하나로 선택된다.
0.1m -> 매우 높은 해상도로 작은 객체도 확인 가능
10m -> 낮은 해상도로 큰 객체만 확인 가능
2단계 모델도 CLIP 임베딩을 입력 데이터로 사용하여 출력된 클래스들의 확률 값에서 가장 높은 확률을 가진 GSD를 예측값으로 출력한다.
CLIP 임베딩의 차원이 높아 overfitting의 위험이 있기 때문에, 입력 데이터를 PCA를 통해 차원을 축소했다.
CLIP 임베딩의 차원이 높으면 overfitting의 위험이 있는 이유?
차원이 증가하게 되면 모델이 학습 가능한 패턴의 수가 크게 증가하는데 이로 인해 모델이 실제로 필요한 패턴뿐 아니라 데이터의 불필요한 노이즈까지 학습하게 된다.
PCA?
PCA는 고차원 데이터를 저차원으로 변환하면서, 원래 데이터의 가장 중요한 정보를 유지하는 방법이다.
5-fold cross validation을 사용하여 모델의 최적의 하이퍼파라미터를 찾고 일반화 성능을 높여 학습시킨다.
- 이미지에서 시각적으로 확인 가능한 태그만 포함하여 데이터셋의 신뢰성을 높이고 GSD 정보를 추가하여 태그가 특정 해상도에서만 활용되도록 제한한다.
remote sensing 이미지는 단순히 픽셀로 구성된 데이터이기 때문에 태그는 이미지를 설명하는 텍스트 역할을 한다.
- 태그가 데이터셋에 포함되어 있으면, 특정 객체를 포함하는 이미지를 쉽게 검색할 수 있다.
Data selection
전 세계 OSM 데이터를 효율적으로 샘플링하고, 각 객체에 적합한 이미지를 선택하는 것이 Data selection의 목표
data selection은 object selection과 image selection 두 단계로 구성된다.
Object selection
Object selection은 데이터셋에 포함할 OSM 객체를 결정하는 과정이다.
semantic diversity를 보장하기 위해, OSM 기반으로 2단계로 수행한다.
1단계 : random object selection
-
지구 전체를 위도/경도 간격이 0.01° × 0.01°으로 구성한 격자에서 무작위로 40만개의 격자를 선택한다.
-
그런 다음, 선택된 격자 내에 위치한 object를 OSM 데이터베이스에서 쿼리하여 추출한다.
도로, 주거지, 강과 같은 공통 태그를 가진 전 세계적으로 일반적인 object들이 포함됨
2단계 : targeted object selection
random object selection에서 포함되지 않은 희귀 태그를 대상으로 OSM 데이터베이스에서 관련 object들을 "직접" 쿼리한다.
이를 통해 데이터셋에 sparse한 semantic 정보를 포함할 수 있다.
두 단계 모두 OSM 데이터베이스를 쿼리하기 위해 OverPass API를 사용한다.
Image selection
Object selection을 통해 데이터셋에 포함할 OSM 객체를 결정한 후, 해당 객체와 연결될 이미지를 선택하는 과정이다
OSM object에 적합한 이미지를 찾는 것을 목표로 GEE에서 제공하는 여러 이미지 컬렉션 중에서 object를 시각적으로 표현할 수 있는 이미지를 선택한다.
<이미지 컬렉션 선택>
OSM 데이터에서 특정 객체가 있으면, 해당 객체를 시각적으로 잘 보여줄 수 있는 이미지 컬렉션을 선택한다.
<객체 유형에 따라 적합한 이미지를 고른다>
1. 점 또는 선 object인 경우
- 2단계 태그 분류 모델에서 예측된 최대 허용 GSD를 기준으로 더 작은 GSD의 적합한 이미지 컬렉션을 결정한다.

2. 다각형 object의 경우
- 다각형 객체는 점이나 선과 달리 넓이와 경계를 갖고 있는 면적을 나타내는 객체이다.
- 다각형 object가 포함된 이미지의 가로/세로 픽셀크기는 75~1000픽셀 사이 안에 있어야 한다.
객체에 대해 적합한 이미지 컬렉션이 여러 개 있을 때는, 무작위로 하나 선택
<이미지 경계 선택>
선택한 이미지 컬렉션에서 해당 객체를 중심으로 이미지를 자르고, 경계를 설정한다.
<객체 유형에 따라 경계를 설정한다>
-
점 객체 : 점을 이미지의 정중앙에 놓고 이미지가 224 x 224 픽셀 크기가 되도록 경계를 설정한다.
-
polyline 객체 : polyline 노드 중 하나를 무작위로 선택하여 이미지 중심에 배치한 후, 이미지가 224 x 224 픽셀 크기가 되도록 경계를 설정한다.
-
다각형 객체 : 다각형 경계 상자를 이미지 경계로 설정한다.
다각형 object를 둘러싸는 최소 직사각형 영역을 계산하여 이 영역을 이미지의 경계 상자로 사용한다.
왜 경계 상자를 사용?
다각형 object는 형태가 복잡할 수 있기 때문에 다각형 전체를 포함하는 경계 상자를 기준으로 이미지 타일을 선택하면 object가 온전하게 표현되어 잘려 보이지 않고 object 분석에 필요한 모든 정보를 포함할 수 있다.
<이미지 경계 무작위 조정>
데이터를 다양화하기 위해 이미지의 경계를 약간 조정한다.
1. 점 또는 선 object인 경우
- 이미지 중심을 약간 이동시켜 중심에서 벗어나지만 여전히 이미지의 중앙 1/3 영역 안에 위치하도록 한다.
- 이미지 높이와 너비는 168~300픽셀 사이에서 무작위로 다시 선택한다.
2. 다각형 object의 경우
- 이미지 높이와 너비는 150~1500픽셀 범위에서 무작위로 다시 선택한다
- 이미지의 가로 세로 비율은 0.5~2 사이로 설정된다.
<이미지 다운로드>
위에서 설정한 이미지 컬렉션과 경계를 GEE에 전달하여 이미지를 다운로드 한다.
Image selection의 목적?
1. 객체와 관련성이 높은 이미지만 선택해 데이터셋의 품질을 높임
2. 데이터셋의 다양성을 확보해 모델이 더 일반화된 패턴을 학습하도록 유도
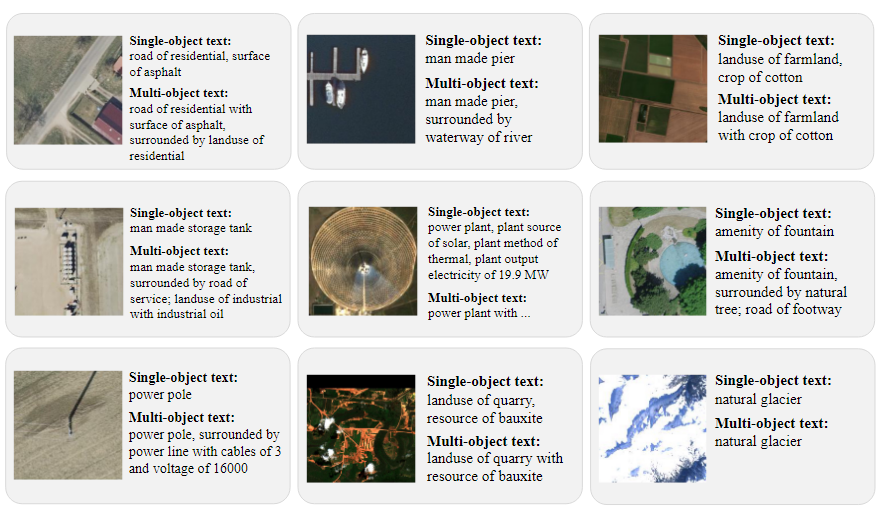
Assembling Caption(캡션 조합)
OSM 태그 데이터를 기반으로 object를 설명하는 텍스트를 생성하는 과정
각 객체는 여러 태그를 가질 수 있고, 각 태그는 key와 value로 구성된다.
태그를 연결 단어("of", "is")를 사용하여 key와 value를 연결한 후, 여러 태그들을 ","또는 "and"로 연결하여 캡션으로 변환한다.
캡션 조합 단계
1단계 : 태그 이름 변경
태그 이름이나 값을 더 직관적이고 일반적인 텍스트로 변경한다.
- highway -> road
- aeroway -> airport
변경된 이름은 데이터셋의 텍스트 표현을 더 읽기 쉽게 만든다.
__2단계 : 키와 값을 연결
태그의 키와 값을 연결하여 의미 있는 텍스트 구문을 생성
-
형용사 형태의 키는 키와 value을 공백으로 연결
{"natural", "water"} → "natural water"
-
key가 특정 속성일 경우 "is"를 사용하여 value와 연결
- {"smoothness", "good"} → "smoothness is good"
-
그 외의 경우 "of"를 기본 연결로 사용
- {"lanes", "2"} → "lanes of 2"
3단계 : 여러 태그 연결
single object 또는 multi object에 대한 캡션 생성
-
single object는 여러 태그를 쉼표로 연결
"power": "pole" → "power pole"
-
다중 object는 중심 object의 설명과 주변 object의 설명을 "with"로 연결한 뒤, 각 객체들을 "and"로 연결한다
-
중심 객체의 설명은 "surrounded by"로 사용
- 중심 객체: "power": "pole".
- 주변 객체: {"power": "minor line"}, {"cables": "3"}, {"voltage": "16000"}.
- 다중 객체 캡션: "power pole, surrounded by power minor line with cables of 3 and voltage of 16000"
Filtering out uncorrelated image-text pairs(상관없는 이미지-텍스트 쌍 필터링)
wild한 상태의 검증되지 않은 데이터셋에서 노이즈 데이터를 줄이기 위해, 이미지와 해당 캡션 간의 관련성이 충분하지 않은 이미지-텍스트 데이터 쌍을 필터링한다.
태그로부터 캡션이 조합된 후, CLIP모델을 사용하여 각 이미지-캡션 쌍에 대한 임베딩을 생성하고, 코사인 유사도를 계산하여 유사도가 낮은 노이즈 데이터를 찾아 상위 유사도 값을 가진 이미지-캡션 쌍만 유지한다.
실험에서는 상위 20%, 30%, 50%를 선택했다.
Data analysis
Dataset overview(데이터셋 개요)
위에서 사용한 데이터 수집 방법을 사용하여, 총 520만개의 필터링되지 않은 remote sensing 이미지-텍스트 쌍을 얻었으며, 44,000개의 고유한 태그를 포함한다.
필터링을 통해 유사도 값 상위 50%의 이미지-텍스트 쌍만 유지하여, 총 260만개의 이미지-텍스트 쌍을 얻었으며, 29,000개의 고유한 태그를 포함한다.
이 태그는 10만 개의 고유한 단일 객체 캡션과 120만개의 고유한 다중 객체 캡션 형성한다.
이미지 GSD는 0.1에서 30m 범위 사이에 분포한다.
분류 성능을 검증하기 위해 70개의 클래스를 포함하는 classification dataset을 추가적으로 수집하였고, 이 데이터셋에 포함된 object들은 주 데이터셋에는 포함되지 않는다.
이 데이터셋은 "SkyScript-classification"으로 명명
SkyScript Classification Dataset
remote sensing 이미지에서 classification을 테스트하기 위한 데이터셋으로 SkyScript 데이터셋과는 별개로 설계되었다.
- 70개의 클래스로 구성되었고, 다양한 지형, 자연 경관 등이 포함된다.
- 각 클래스에는 100개의 이미지가 포함되고 희귀 클래스는 예외적으로 더 적은 이미지를 포함
Geographic coverage(지리적 범위)
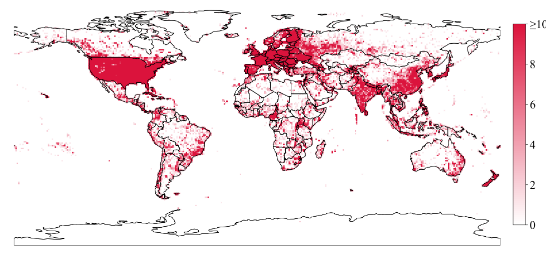
위 그림처럼 SkyScript는 남극을 제외한 모든 대륙에 대한 지리적 범위를 갖고 있다.
미국과 유럽은 고해상도 이미지 데이터가 풍부하기 때문에, 작은 객체도 데이터셋에 더 많이 포함된다.
이러한 고해상도 이미지를 필요로 하는 작은 object가 미국과 유럽에 더 많이 포함되어 있다.
세계의 다른 지역에는 인구 밀도가 높은 지역(인도, 중국)은 인구 밀도가 높기 때문에 건물, 도로 등 큰 규모의 object가 밀집된 지역이다.
인구 밀도가 높기 때문에 많은 object를 포함하는 경향이 있고, OSM(OpenStreetMap) 데이터가 더 잘 작성되어 있어, 태그가 잘 정리되어 있다.
- 미국, 유럽 : 고해상도 이미지의 작은 object
- 중국, 인도 : 크고 많은 양의 object
Semantic diversity(의미적 다양성)
SkyScript는 의미적으로 다양하다.
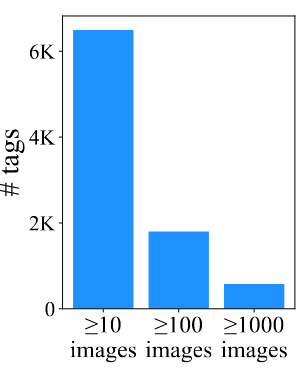
580개의 태그는 1000개 이상의 이미지를 포함하고 있고, 1,800개 이상의 태그는 100개 이상의 이미지를 데이터셋에 포함하고 있다.
많은 태그가 충분히 많은 데이터를 갖고 있어, 데이터셋이 단순히 몇몇 태그에 집중된 것이 아닌 다양한 태그를 고르게 포함하고 있음을 보여줌
t-SNE를 사용하여 SkyScript에 포함된 태그의 CLIP 임베딩과 다른 데이터셋의 semantic 클래스를 2D 공간으로 투영한 결과, SkyScript는 기존 데이터셋에 포함된 태그와 의미를 모두 포함하면서도, 더 많은 정보를 제공한다.
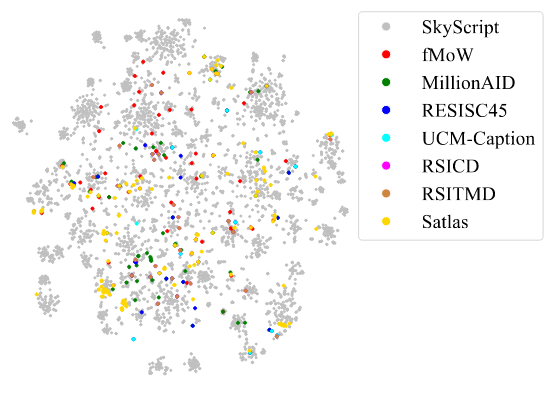
t-SNE이란?
고차원 공간에서 데이터 간의 유사성을 저차원 공간에서도 유지하면서 데이터를 표현
- 데이터를 클러스터를 통해 나타내어 군집 간 유사성과 차이를 시각적으로 확인할 수 있다.
다음 그림에 나타난 것처럼, SkyScript는 단순한 object classification을 넘어서 세부적인 object의 속성까지 포함한다.
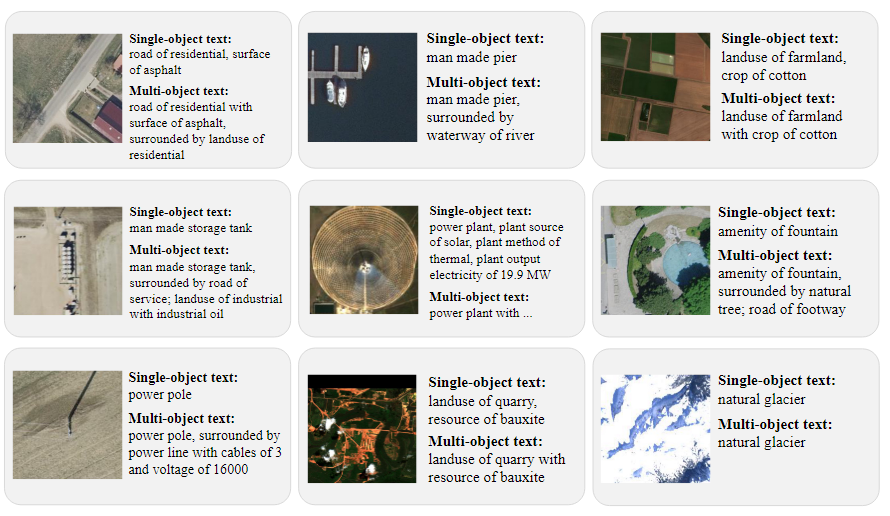
-
농지(farmland):
단순히 "농지"라고 분류하지 않고, "작물 유형(crop type)"까지 정보를 제공 -
도로(road):
단순히 "도로"라고 분류하지 않고, "도로 표면(road surface)"의 재질(아스팔트, 자갈 등)도 포함
이러한 세부 정보는 데이터셋이 단순히 객체의 이름만 아는 것이 아니라, 객체의 속성과 context까지 이해할 수 있도록 돕는다
SkyScript 데이터셋은 단순히 광범위한 객체 정보를 제공하는 것을 넘어서, 객체의 속성과 세부적인 의미까지 포함하여 모델에게 의미적으로 더 다양한 정보를 제공하여 object를 더 잘 이해하고 예측할 수 있도록 한다.
Comparison with the remote sensing subset in LAION
LAION-2B는 웹 크롤링을 통해 얻은 23억 개의 이미지와 영어 캡션으로 구성된 거대한 텍스트-이미지 데이터셋이다
LAION-2B에서 remote sensing 이미지 서브셋을 추출하여, remote sensing 분야에서 더 나은 VLM을 만들 수 있는지 테스트한다.
구체적으로, CLIP/ViT-L-14의 이미지 인코더에서 출력된 이미지 임베딩을 입력 특징으로 사용하여, 주어진 이미지가 원격 감지 이미지인지 아닌지를 예측하는 로지스틱 회귀 모델을 학습하였다.
- 데이터셋 준비
LAION-2B에서 2,000개의 remote sensing 이미지와 50,000개의 non remote sensing 이미지를 수집.
- 이를 기반으로 학습(90%) 및 테스트(10%) 세트를 구성하여 학습
- 테스트 결과
테스트 세트에서 정확도는 99.96%로, CLIP 임베딩이 remote sensing 이미지와 non remote sensing 이미지를 구별하는 데 효과적임을 보여줌
- LAION-RS 생성
학습된 로지스틱 회귀 모델을 LAION-2B의 전체 데이터셋에 적용해, 원격 감지 이미지-텍스트 쌍을 필터링
- 결과적으로, 총 726,000개의 원격 감지 이미지-텍스트 쌍(LAION-RS)을 생성.
LAION-2B에서 원격 감지 데이터를 추출해 LAION-RS라는 서브셋을 생성하였지만, 전체 23억개의 샘플 중, remote sensing 이미지-텍스트 쌍은 726,000로 전체 데이터 셋의 0.03%에 불과했다.
웹 크롤링 기반 데이터 수집의 한계로, SkyScript와 같은 데이터셋의 필요성을 강조
Applications and Limitations(응용 및 한계)
Applications
SkyScript는 remote sensing 분야에서 다양한 task 모델을 개발하는 데 사용될 수 있다.
- Open-vocabulary classification
- Cross modal retrieval
- Image captioning
SkyScript는 지속 가능한 개발 응용 분야에서 잠재력이 있다.
SkyScript만으로도 remote sensing에 특화된 VLM을 개발할 수 있고, 이를 위해 지속적인 pre-training을 활용할 수 있다.
또, 다른 이미지-텍스트 데이터셋과 결합하여 일반 목적의 VLM을 처음부터 pre-training할 수도 있다.
Limitations
SkyScript는 몇 가지 내재된 편향이 있을 수 있다.
-
고해상도 이미지의 제한된 지역적 분포
현재 SkyScript는 라이선스 제한이 없은 remote sensing 이미지만 고려하고 있는데, 고해상도 이미지는 주로 미국과 유럽에 집중되어 있어, 다른 지역은 데이터셋에서 상대적으로 적게 표현된다. -
OSM 주석의 불완전성
개발도상국에서는 OSM주석이 덜 완전하고, 이로 인해 해당 지역에서의 샘플 데이터가 부족하다.정부 기관과 협력하여, 더 넓은 범위를 포괄하는 고해상도 이미지를 확보해야 한다.
-
단순한 규칙 기반 접근법의 한계
현재 SkyScript는 태그로부터 캡션을 자동으로 조합하기 위해 단순한 규칙 기반 접근법만 사용하는데 LLM을 사용하여 태그로부터 더 자연스럽고 의미 있는 캡션을 생성하는 방법에 대한 연구가 필요하다.
Experiments
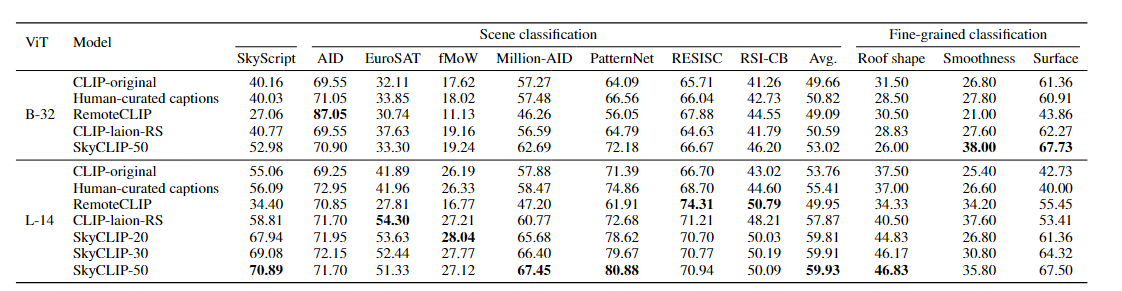
-
ViT (Vision Transformer)
B-32: BERT-32기반의 모델
L-14: BERT-14기반의 모델 -
Model
SkyCLIP: SkyScript 데이터셋으로 학습된 CLIP 모델- SkyCLIP-20: SkyScript 데이터셋 중 상위 20% 데이터만 사용.
- SkyCLIP-30: SkyScript 데이터셋 중 상위 30% 데이터만 사용.
- SkyCLIP-50: SkyScript 데이터셋 중 상위 50% 데이터만 사용.
-
Scene classification
remote sensing 이미지에서 다양한 장면을 분류dataset : SkyScript, AID, EuroSAT, fMoW, Million-AID, PatternNet, RESISC, RS1-CB
- Avg는 모든 데이터셋에서의 평균 성능
-
Fine-grained classification
remote sensing 이미지 내에서 세부 속성에 대한 분류dateset : SkyScript
Roof shape: 지붕 형태
Smoothness: 표면의 매끄러움
Surface: 표면의 유형 -
평가 지표
Top-1 정확도(%) : 모델이 가장 높은 확률로 예측한 클래스가 실제 클래스와 일치한 비율
결과
Scene classification
-
B-32 모델:
SkyCLIP-50는 대부분의 데이터셋에서 높은 성능을 발휘했으며, 평균 성능(Avg)에서도 52.98로 가장 뛰어남.
RemoteCLIP은 EuroSAT(87.05)에서 높은 성능을 보였으나 다른 데이터셋에서는 상대적으로 낮은 성능을 보임. -
L-14 모델:
SkyCLIP-50은 대부분의 데이터셋에서 최고 성능을 기록하며, 평균 성능(Avg)은 59.93로 가장 높다.
특히, PatternNet(80.88), Million-AID(67.45)에서 매우 뛰어난 성능을 보임.
Fine-grained classification
-
B-32 모델:
SkyCLIP-50이 Surface(67.73)에서 최고 성능을 보이며, 다른 속성에서도 경쟁력 있는 결과를 보임. -
L-14 모델:
SkyCLIP-50이 모든 세부 속성에서 가장 높은 성능을 보임
SkyScript 데이터셋을 활용한 SkyCLIP 모델은 장면 분류와 세부 분류 작업에서 우수한 성능을 발휘한다.
특히, L-14 모델을 사용할 경우 성능이 더 뛰어나며, SkyCLIP-50은 거의 모든 작업에서 최고 성능을 기록
