Abstract
Foundation model의 general한 활용은 인공지능 개발에서 중요한 돌파구를 제공하였다.
Foundation model?
다양한 task에서 general하게 활용할 수 있도록 대규모 데이터와 자원을 기반으로 학습된 모델
- 텍스트 기반 모델 : GPT, BERT
- 이미지 기반 모델 : SimCLR, MAE
- 비전-언어 기반 모델 : CLIP, DALL-E
Remote sensing 분야에서도 Self-supervised learning(SSL), 특히 Masked image modeling(MIM)기술을 활용해 foundation model을 개발하고 있지만 한계가 존재한다.
-
low-level feature에만 focus를 맞추고, high-level semantics를 학습하지 못한다.
Remote sensing foundation model의 학습 방법은 이미지의 세부적인 feature를 학습하는 데 효과적이지만 이미지가 나타내는 맥락적 의미와 같은 추상적인 의미는 학습하는 데 한계가 있다.
-
언어 이해 능력 부족으로 인해 zero-shot task나 text-image retrival과 같은 multimodal 응용에 적합하지 않다.
기존 remote sensing foundation model은 비전 전용 모델을 중심으로 설계되어, object detection, segmentation, classification등 이미지에서 경계 정보를 학습하는 데 초점을 맞추고, 언어 데이터를 학습하거나, 텍스트와 이미지를 연관시키는 과정을 포함하지 않았음
Remote sensing 데이터는 텍스트와 이미지의 align된 dataset이 거의 없다.
-
주석 데이터를 활용한 fine-tuning이 필요하여 데이터 effciency가 낮다.
Remote sensing model은 natural 이미지와 다르게 도메인 특화된 데이터(위성 이미지)에서 학습해야 하는 경우가 많은데, remote sensing 데이터셋은 크기가 작고, 도메인 특화 작업을 처리하기 위해 추가적인 주석 데이터가 필요함
이러한 한계를 극복하기 위해, 최초의 remote sensing을 위한 VLM인 RemoteCLIP을 제안
-
Vision-language 통합 학습
이미지를 vision representation으로 변환하고, 텍스트 임베딩과 align하여 학습 -
Data 확장
Remote sensing에서 사용할 수 있는 데이터가 제한적이라는 문제를 해결하기 위해, Box-to-Caption, Mask-to-Box라는 변환 방식을 도입
Introduction
인공지능 분야에서 foundation model의 중요성이 점점 커지고 있다.
특정 task나 domain에 맞춰 설계된 모델과 비교했을 때, general한 활용이 가능한 foundation model은 다양한 task에서 뛰어난 성능과 generalization 성능을 보여주었다.
- 텍스트 기반 모델 : GPT, BERT
- 이미지 기반 모델 : SimCLR, MAE
- 비전-언어 기반 모델 : CLIP, Flamingo
Remote sensing 분야에서도 위성 이미지 분석으로 위한 foundation model 개발에 힘쓰고 있다.
현재까지의 주요 접근 방식은 Computer vision에서 성공을 거둔 Self-supervised learning(SSL)으로, 특히 Masked image modeling(MIM)방법에서 영감을 받았다.
Self-Supervised Learning : 레이블이 없는 데이터로 학습
Masked Image Modeling : 이미지를 일부 가리고 이를 복원하는 방식
하지만, MIM 기반의 remote sensing foundation model에는 두 가지 주요 한계가 있다.
-
Occlusion invariance(가려짐 불변성)
MIM은 이미지의 가려진 부분을 복원하는 데 중점을 두는 방법으로 Natural image에서 중요한 특성인데, 위성 이미지에서는 시야가 가려질 일이 적어 필요성이 낮다.
-
Low-level feature 중심 학습
MIM은 주로 이미지의 Low-level feature(엣지, 텍스처 등 작고 세부적인 특징)을 학습한다.
이는 High-level semantics(맥락, 관계)를 이해하는 데 한계가 있다.
Object detection와 같은 단순 작업에는 적합하지만, 의미적인 추론이 필요한 Zero-shot 작업에는 부적합하다.
또한, 모든 Foundation 모델은 다운스트림 작업에 적응하기 위해 주석이 달린 데이터와 추가적인 fine-tuning이 필요하다.
그러나, 기존의 Foundation 모델은 Language와 Vision을 정렬하는 능력이 부족하여 CLIP과 같은 Zero-shot 학습이나 Text-image retrival과 같은 Multimodel응용에 적합하지 않다.
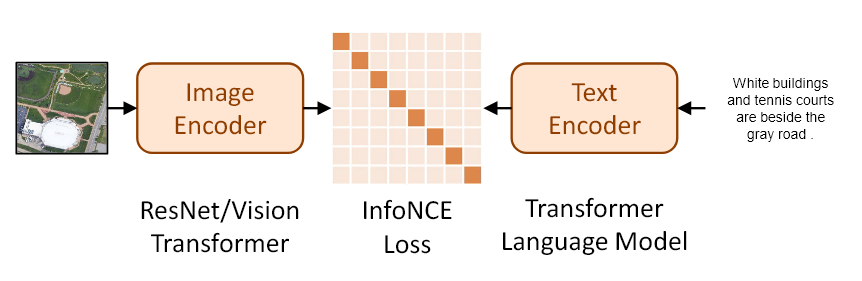
이 논문에서는 Remote sensing을 위한 Vision-language 기반 Foundation model을 개발하였다.
<목표>
1. 위성 이미지의 시각적 개념에 대해 풍부한 semantics를 담은 강력한 vision representation을 학습
-
이 vision representation과 align된 text embedding을 학습
-
이를 통해 다양한 Downstream task에 활용
Remote sensing 데이터를 다루는 모델 개발에서 가장 큰 문제는 대규모 pre-training data의 부족이다.
Remote sensing 데이터는 Text-Image가 align된 대규모 데이터셋이 부족하고, 주석 데이터를 활용한 fine-tuning 없이는 task에 잘 적응하지 못한다.
제한된 데이터로는 대규모 Vision-language 모델을 학습할 때 Overfitting 문제가 발생한다.
이를 해결하기 위해 기존 데이터셋보다 12배 큰 traning data를 생성하는 방법을 도입하였다.
- Mask-to-Box(M2C), Box-to-Caption(B2C) 변환
- 다양한 주석 데이터를 통합하여 Image-Caption 데이터 형식으로 변환
- Object detection 데이터의 경계 상자와 semantic segmantation map을 자연어 text로 변환하여 Vision-language 학습에 활용
- 무인 항공기(UAV) 이미지 활용
- UAV 데이터를 추가해 traning 데이터의 diversity를 강화
- InfoNCE loss function 최적화
- 이미지와 텍스트 간의 상호 정보를 정렬하기 위해 InfoNCE loss function을 사용하여 학습한다.
- 이 loss function은 이미지와 텍스트 pair를 서로 가까이 align 하는 것을 목표로 한다.
요약
1. Remote sensing 도메인을 위한 대규모 데이터셋
2. Remote sensing을 위한 새로운 Vision-language foundation model
Related work
Remote sensing 분야에서 기존 연구의 주요 접근 방식
Self-supervised Foundation Models for Remote Sensing
Remote sensing 데이터를 이용해 학습하는 자기 지도 학습의 두 가지 주요 접근 방식(대조 학습, 생성적 학습)을 설명
Foundation 모델은 대규모 pre-training을 통해 여러 downstream task를 처리할 수 있는 능력을 갖추고 있으며, 최근 인공지능 연구에서 중요한 초점으로 부각되었다.
Remote sensing 분야는 GeoAI(지리 공간 AI)를 위한 foundation 모델 구축을 추진하고 있다.
SSL은 라벨이 없는 데이터를 활용해 vision representation을 학습하는 방법으로, 최근 Remote sensing 모델 개발의 핵심적인 접근 방식으로 자리잡았다.
SSL 접근 방식은 크게 두 가지로 나뉜다.
1. Contrastive learning : 데이터를 pair로 비교하여 유사성을 학습
2. Generative learning : 데이터를 부분적으로 가려서 이를 복원하는 방식으로 학습
Contrastive learning
Contrastive learning은 Remote sensing 데이터에서 데이터를 비교하고 유사성을 학습하는 방식이다.
연구자들은 Natural image 학습에서 사용되던 방법을 Remote sensing에 맞게 확장하였다.
동일한 이미지에서 증강된 두 View를 비교하는 방식으로, 데이터 간 유사성을 학습
<Remote sensing 이미지를 대상으로 SSL방법을 적응시키기 위한 방법>
-
공간적 이웃(Spatial neighbors)활용
위성이미지의 공간적 관계를 활용하여 이웃한 이미지 간의 관계를 학습하면 공간적 연속성을 유지하는 강력한 임베딩을 생성할 수 있다.위성 이미지에서 공간적으로 가까운 영역은 유사한 패턴을 가질 가능성이 높다
- 이러한 이웃 데이터를 증강 데이터로 활용한다.
-
랜덤 회전(Random rotations)
Remote sensing 이미지의 90, 180, 270도 회전을 통해 회전된 이미지와 원본을 positive pair로 설정하여, 모델이 방향 변화에 강건한 표현을 학습동일한 이미지에 대해 다양한 회전 각도를 적용하여 증강 데이터 생성
-
지리적 식생 정보 증류(Distilled vegetation features)
Remote sensing 이미지에서 식생에 관련된 특징만을 추출하여 대조 학습(contrastive learning)에 활용위성 이미지에서 식생(초목, 숲, 농경지)은 중요한 지리적 특징 중 하나이다. 따라서, 식생 정보를 활용하여 모델이 지리적 특징을 학습하도록 합니다
-
다중 뷰 코딩(Contrastive multiview coding)
동일한 지역의 다른 시점에서 촬영된 데이터를 사용해 학습하여 모델이 같은 지역의 다양한 표현을 이해하도록 학습 -
초고해상도 작업(Super-resolution enhancement)
Remote sensing 이미지의 초고해상도 복원에 활용하였다.
저해상도 이미지와 고해상도 이미지를 연결하여, 모델이 더 세부적인 표현을 학습한다.
Generative learning
Generative learning은 Remote sensing에서 MIM 방식을 사용하여 학습한다.
생성 학습은 모델이 입력 데이터의 일부를 복원하거나 생성하는 작업을 통해 데이터의 특징을 학습하는 방법
이미지의 일부를 가리고 이를 복원하도록 모델을 훈련시키는 방식으로, MIM방법을 기반으로 하는 여러 Remote sensing 모델은 기존 MIM 프레임워크게 새로운 속성을 통합하는데 초점을 맞춘다.
연구자들은 MIM을 Remote sensing에 적합하도록 다양한 속성을 추가했다.
-
스케일 불변성(Scale-invariance) : 이미지 크기에 영향을 받지 않는 표현 학습
Remote sensing 이미지에서는 동일한 object라도 다른 scale로 나타날 수 있다.
- 모델이 다양한 스케일에서 객체를 동일하게 인식하도록 만든다.
스케일 불변성을 학습하면 다양한 해상도의 이미지에서 일관된 성능을 보일 수 있다.
- 모델이 다양한 스케일에서 객체를 동일하게 인식하도록 만든다.
-
시간적 정보(Temporal information) : 시간에 따른 이미지 변화를 학습
위성 이미지는 시간의 흐름에 따라 수집된다.
특정 지역에서 계절이나 시간이 변하면서 발생하는 변화를 학습하는 것이 중요시간적 정보를 학습하면 모델이 이미지 간 시간 의존성을 이해할 수 있다.
-
시간적 불변성(Temporal invariance)
시간이 변해도 동일한 객체를 일관되게 인식할 수 있도록 모델을 학습하는 방식
Self-supervised Foundation Models for Remote Sensing은 Contrastive learning과 Generative learning의 조합을 통해 데이터를 학습한다.
Vision Language Models for Remote Sensing
Remote sensing 데이터를 위한 비전-언어 모델이 어떻게 발전했는지
Image와 text의 통합은 인공지능 연구의 핵심 과제였으며, Vision-language 모델은 이미지를 텍스트를 연결하거나, 텍스트를 기반으로 이미지를 검색하는 작업에서 활용된다.
특히 Remote sensing 분야에서 복잡한 위성 이미지와 이에 연관된 의미를 해석하는 것이 중요하다.
Image-text retrieval models
Remote sensing retreieval의 초기 연구는 CNN을 통해 이미지를 인코딩하고, LSTM을 사용하여 텍스트 caption을 인코딩하였다.
이후 연구
-
이 모델에 위성 이미지를 전역/지역적으로 이해할 수 있는 능력을 부여하기 위해 dynamic fusion module을 활용하는 프레임워크를 도입하였다.
-
다양한 언어의 remote sensing semantics를 적응하기 위해 다중 언어를 이해할 수 있는 다중 언어 프레임워크를 제안하였다.
이러한 모델들은 이미지-텍스트 retrieval 통해 지식을 습득하는 데 초점을 맞추었지만, retrieval을 넘어서 다운스트림 task에서 이러한 비전 언어 모델의 효율성이 검증되지 않았다.
CLIP-based models
CLIP은 이미지와 텍스트를 연결하는 대규모 멀티모달 모델로, remote sensing 데이터를 vision-language 모델에 적용하기 위한 중요한 기반이 된다.
CLIP은 natural 이미지에 대해서 이미지와 텍스트를 정렬하여 embedding하는 뛰어난 성능을 보였지만 remote sensing에서의 연구는 아직 초기 단계로 아직 제한적이다.
Relate work
- 원격 감지 데이터를 처리하기 위한 기존 SSL 및 비전-언어 모델이 어떻게 발전했는지 설명.
- 기존 연구가 제공하지 못한 한계와 공백을 강조.
- 이 논문(RemoteCLIP)이 제안하는 비전-언어 기반 Foundation 모델이 이러한 한계를 어떻게 해결할 수 있을지 논리적 연결을 제공
RemoteCLIP
Contrastive language image pretraining
CLIP 전략으로 학습된 vision-language 모델은 다양한 task에서 놀라운 generalization 능력을 보여주었다.
대규모 이미지-텍스트 쌍에서 추출한 cross-modal supervision을 통해 의미적으로 유사한 샘플들의 표현을 align하고, 유사하지 않는 샘플들은 멀어지도록 학습한다.
CLIP 모델은 InfoNCE loss function을 최적화한다.
학습 방식
CLIP은 M개의 image-text 샘플 쌍으로 구성된 대규모 데이터셋
을 사용해 학습한다.
Image encoder () : 이미지 샘플 를 잠재 표현 로 인코딩
Text encdoer () : 텍스트 샘플 를 잠재 표현 로 인코딩
학습 중, CLIP은 InfoNCE 손실 함수를 사용하여 이미지를 텍스트와, 텍스트를 이미지와 정렬하도록 학습한다.
-
이미지-텍스트 정렬 : 주어진 이미지에 대한 올바른 텍스트와 높은 유사도를 가지도록 학습
-
텍스트-이미지 정렬 : 주어진 텍스트에 대한 올바른 이미지를 높은 유사도로 정렬
InfoNCE loss function
동일 배치에 있는 데이터 간 유사도를 비교하여 정렬 학습
positive pair는 유사도 점수(내적)가 높아야 하고, negative pair는 낮아야 함
이미지와 텍스트 간의 유사성을 최대화하고, 다른 이미지-텍스트 쌍 간의 유사성을 최소화하는 방식으로 작동
- CLIP은 이미지를 보고 텍스트를 찾거나, 텍스트를 보고 이미지를 찾을 수 있는 모델이기 때문에 두 가지 방향 모두 학습하는 방식이 필요하다
- 분자 : i번째 이미지와 해당하는 텍스트의 유사도를 지수 함수로 변환
- 분모 : i번째 이미지/텍스트와 전체 텍스트/이미지 간의 유사도들의 softmax 분포
- : Batch size
- : learnable temperature parameter(softmax 스케일링 조정)
CLIP 모델이 InfoNCE loss function를 통해 두 가지 중요한 성질을 학습한다.
- 표현 정렬(Representation alignment)
의미적으로 유사한 데이터는 같이 위치에 align된다.
- 쌍을 이루는 image-text 샘플 간에는 높은 유사도 를 생성
- 표현 그룹화(Representation grouping)
유사한 데이터끼리 그룹화된다.
대규모 CLIP 모델은 Remote sensing task에서도 강력한 모델이다.
CLIP은 대규모 image-text pair로 학습된 vision-language 모델로 다운스트림 작업에서 일반적으로 뛰어난 성능을 발휘한다.
Remote sensing 데이터에 대해 특별히 설계되지 않았지만, remote sensing 벤치마크에서 다양한 성능을 보여주고 있다.
<OpenAI의 Zero-shot 성능 평가>
EuroSAT과 RESISC45 데이터셋(대표적인 remote sensing 데이터)에서 CLIP의 Scene recognition의 zero-shot 성능을 평가
가장 큰 CLIP 모델인 ViT-Large 14-336의 성능
- EuroSAT : 59.6%
- RESISC45 : 71.7%
이는 remote sensing 특화 모델과 비교했을 때 낮은 성능이다.
SATIN 데이터셋에서도 유사한 실험이 이루어졌으나, CLIP 계열 모델의 zero-shot 성능이 만족스럽지 않았다.
CLIP 모델이 pre-training에서 일반적 의미 정렬에는 뛰어나지만, remote sensing에서는 적합하지 않음을 나타낸다.
<선형 평가(Linear probing)결과>
Linear probing을 통해 CLIP 모델이 훨씬 더 뛰어난 성능을 보였다.
- EuroSAT: 98.1%
- RESISC45: 94.9%
다른 Foundation 모델을 모두 능가하였다.
이는 CLIP의 contrastive learning이 remote sensing 데이터에 적합한 시각적 표현을 학습할 수 있지만, cross-modal alignment는 부족함을 보여준다.
추가 학습을 통해 강력한 성능을 낼 수 있음을 의미한다
<Remote sensing 이미지 검색에서의 CLIP 평가>
연구진은 CLIP 모델의 zero-shot retrieval 성능을 RSITMD, RSICD, UCM같은 대표적인 Remote sensing 데이터셋에서 테스트 하였다.
모델 크기는 ResNet-50(38M 파라미터)부터 ViT-G-14(1.8B 파라미터)까지 다양하게 실험하였다.
- ALBEF, BLIP 같은 다른 VLM 모델과도 비교
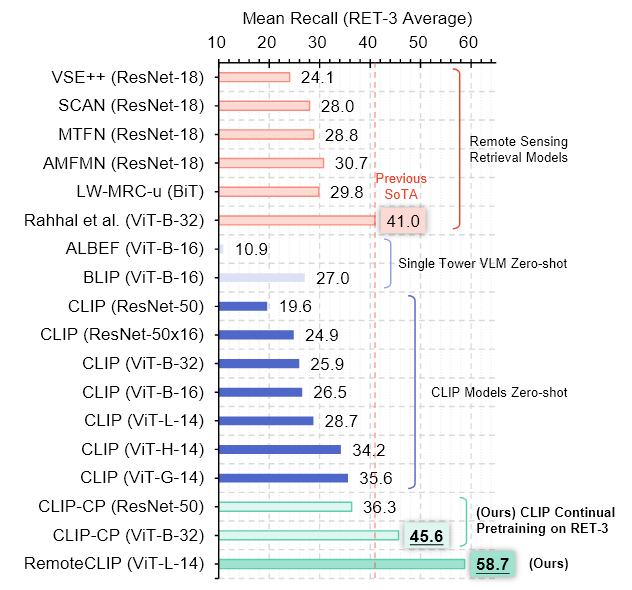
<평가 결과> - CLIP 모델의 크기가 커질수록 성능이 향상되었다.
- 대규모 모델과 대규모 pre-training이 복잡한 네트워크 구조나 다중 손실 함수 사용보다 더 효과적임을 보여준다.
소형 CLIP 모델에 대한 지속적 사전 학습은 성능을 더욱 향상시킨다
대형 CLIP 모델이 Remote sensing 작업에서 강력한 성능을 보여주는 것을 고려했을 때, 도메인 내 항공 이미지 데이터를 사용하여 성능을 더욱 향상시킬 수 있는지에 대한 질문이 제기된다.
Continual pretraining은 이러한 목표를 달성하기 위한 방법론이다.
<초기 실험>
ResNet-50과 ViT-B-32모델을 대상으로 기존의 세 가지 remote sensing 데이터셋에 대해 지속적으로 추가 학습을 시킨다.
- 결과적으로 얻은 모델은 CLIP-CP로 표기하며, 이 모델은 강력한 성능을 보여주었다.
<실험 결과>
CLIP-CP 모델은 가장 큰 CLIP 모델(ViT-G-14)의 zero-shot 결과를 단 2%의 매개변수(38M 파라미터)로 능가하며, 좋은 성능을 달성하였다.
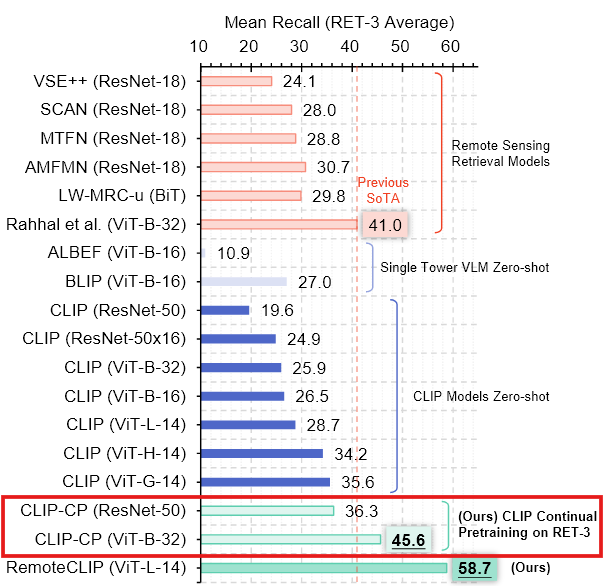
이는 지속적 사전 학습이 모델의 성능을 크게 향상시킬 수 있음을 보여준다.
또한, 여러 데이터셋을 모아서 기초 모델을 조정하는 것이 유리하다는 것이 분명하다
<과적합 문제와 데이터 스케일링의 필요성>
간단한 지속적 사전 학습 전력은 좋은 결과를 보여주지만, 완벽하지는 않다.
모델의 크기를 확장하려고 할 때, 심각한 overfitting 현상이 나타난다.
Continual pretraining이 작은 CLIP 모델에서는 효과적이지만, 대형 CLIP 모델로 확장하려하면 Overfitting 발생
그 이유는, Continual pretraining에 사용된 dataset이 대형 CLIP에 비해 너무 작다.
연구진이 대형 CLIP 모델의 모델 용량과 복잡성에 맞추기 위해 데이터 스케일링을 수행하였다.
데이터 크기를 모델 크기에 맞게 확장하는 데이터 스케일링 기법 도입
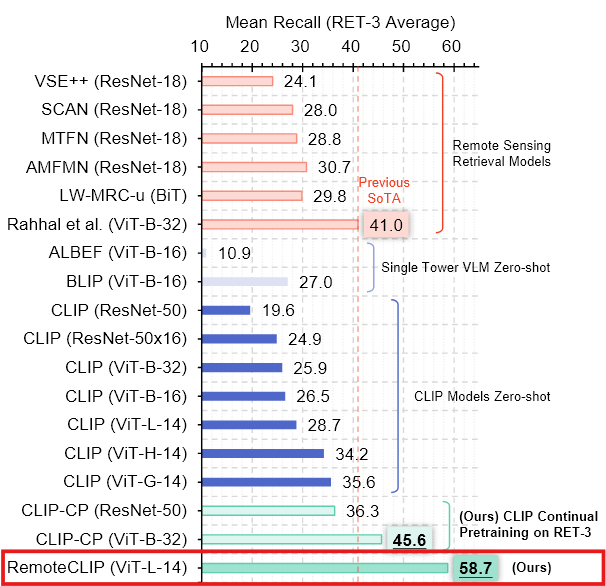
규모가 큰 CLIP 모델을 대상으로 데이터 스케일링하여 Continual pretraining한 결과 규모가 작은 CLIP모델인 CLIP-CP보다 더 좋은 결과를 보여주었다.
- Continual pretraining이 Remote sensing 도메인에서 CLIP 모델의 성능을 크게 향상시킬 수 있다.
- 그러나, 모델의 크기가 커질수록 데이터 규모가 성능 향상의 주요 병목 현상이 되므로, 데이터 스케일링이 필수적이다.
Data Scaling via Annotation Unification
CLIP 모델은 대규모 image-text 쌍으로 학습되지만, remote sensing 도메인에서는 이러한 데이터셋이 부족하다.
이는 성능을 제한하는 주요 병목 현상임을 확인하였고 데이터셋 규모를 확장하여 Continual pretraining을 수행해야 한다.
- 간단한 방법은 크라우드소싱을 기반으로 더 많은 Caption을 추가하는 것이지만, 이는 비용이 매우 높고 확장성을 크게 저하시키며, 주석의 품질과 다양성을 보장하기도 어렵다.
이 문제를 해결하고 CLIP 모델의 잠재력을 극대화하기 위해, 주석 통합을 통해 데이터셋을 확장하는 방법을 제안한다.
Remote sensing 데이터에는 object bounding box와 클래스 이름으로 주석이 달려있는 데이터가 많은데, 이 주석은 자연어 caption에 대해 학습한 CLIP의 텍스트 인코더로는 직접 이해할 수 없다.
- Box-to-Caption(B2C) 변환 방식 제안
- bounding box 주석을 자연어 caption 집합으로 변환하는 방식
- Mask-to-Box(M2B) 변환 방식 제안
- Segmentation 데이터셋의 주석을 bounding box 주석으로 변환한다.
Box-to-Caption (B2C) Generation
B2C 생성 방식은 Object detection 데이터셋에서 제공되는 경계 상자 주석과 레이블을 기반으로 자연어 캡션을 생성할 수 있게 한다.
이 방법은 rule-based 방식을 사용하여 이미지 내 Object를 설명하는 5개의 고유한 Caption을 생성한다.

<첫 번째와 두 번재 캡션>
경계 상자의 중심 지점을 기준으로 생성된다.
- 첫 번째 Caption은 이미지 중심에 있는 Object를 설명한다.
- 두 번째 Caption은 중심에 위치하지 않은 Object를 설명한다.
이러한 구분은 이미지 내 Object의 공간적 분포에 대한 추가적인 맥락과 정보를 제공
<나머지 세 개의 캡션>
이미지 내 다양한 object 카테고리의 수를 고려하여 생성된다.
- 경계 상자 주석 목록에서 랜덤으로 object를 선택하고, 이에 따라 캡션 생성
- Object의 출현 횟수가 10회를 초과하는 경우, 정확한 숫자 대신 "many", "a lot of"와 같은 일반적인 용어를 사용하여 캡션의 가독성과 다양성을 높인다.
- 하나의 이미지에 대해 여러 개의 캡션을 생성함으로써, 데이터의 다양성을 높인다.
- 객체의 위치를 설명하는 캡션을 통해 모델이 객체의 공간적 배치를 이해할 수 있다.
Mask-to-Box (M2B) Conversion
Segmentation 데이터를 CLIP 모델이 이해할 수 있는 경계 상자 주석으로 변환하는 과정이다.
Segmentation 주석은 픽셀 단위로 제공되므로, Object의 위치와 크기를 모델이 처리할 수 있는 형식으로 바꿀 필요가 있다.
이렇게 변환된 데이터를 기반으로 B2C 과정으로 통해 자연어 캡션을 생성할 수 있다.
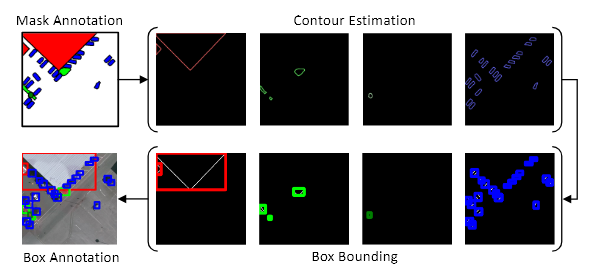
1. 클래스별 mask 처리
Segmentation mask는 각 픽셀에 클래스 레이블이 할당되어 있다.
먼저, 각 클래스 별로 해당하는 픽셀만 추출하여 binary mask로 변환한다.
2. Contour(윤곽점) 추출
각 클래스의 mask에서 객체의 윤곽선을 추출한다.
동일한 클래스를 가진 연결된 영역을 찾아야 함
윤곽선은 객체의 외부 경계를 나타내는 점들의 집합이다.
Suzuki의 경계 추적 알고리즘을 사용하여 binary 이미지에서 외부 경계와 내부 경계를 정의하여 각 연결된 영역의 윤곽점을 추출하여 해당 영역의 경계를 정의한다.
- Outer boundary와 Hole boundary 정의
- 이미지를 왼쪽에서 오른쪽으로 스캔하면서 시작 시점 찾기
- 주변 픽셀을 탐색하여 경계를 따라 이동하면서 윤곽선 정보 추출
- 계층적 관계를 유지하면서 object의 구조를 파악
binary image에서 작동하므로 세그멘테이션 mask를 카테고리 별로 변환하여 특정 카테고리를 foreground로, 나머지는 background로 처리한다
3. 경계 상자 생성
추출된 윤곽점을 기반으로 각 연결된 영역의 경계 상자를 생성한다.
윤곽점의 수평 및 수직 좌표를 정렬하여 최소 및 최대 값을 찾는다.
- 최소값 : ()
- 최대값 : ()
이 좌표가 각 object의 경계 상자를 형성하며, 각 연결된 객체 영역에 대한 위치와 크기를 나타낸다.
ex) "건물" 클래스 처리:
"건물" 클래스에 해당하는 픽셀을 추출한다.
"건물" 클래스의 연결된 영역을 식별하고, 각 영역의 윤곽점을 추출한다.
윤곽점을 기반으로 각 "건물" 영역의 경계 상자를 생성한다.
이렇게 생성된 경계 상자는 Box-to-Caption 생성 과정을 통해 자연어 텍스트 설명으로 변환된다.

Sample De-duplication
데이터셋에서 중복된 이미지를 제거하는 과정이다.
중복된 이미지가 있으면 모델이 동일한 데이터를 반복해서 학습하게 되어 Overfitting이 발생할 수 있고, 테스트셋 오염이 발생할 수 있다.
학습 데이터와 테스트 데이터 간에 중복된 이미지가 있으면, 모델이 테스트 데이터를 이미 본 상태가 되어 공정한 평가가 어려워진다.
p-Hash 기반의 블록 단위 로컬 탐지를 사용하여 중복 이미지를 식별하고 제거하였다.
p-Hash는 이미지의 시각적 특징을 기반으로 고유한 해시 값을 생성하는 방법으로 이미지의 픽셀 값이 조금 달라도 유사한 해시 값을 생성할 수 있어서, 중복 이미지를 효과적으로 탐지할 수 있다.
1. p-Hash값 생성
데이터셋의 모든 이미지에 대해 p-Hash 값을 생성한다.
p-Hash는 이미지를 고정 길이의 해시 값으로 변환하여 이미지의 시각적 특징을 나타낸다.
2. 해시 값 분할
생성된 p-Hash 값을 N개의 세그먼트로 분할한다.
각 세그먼트는 해시 값의 일부분을 나타낸다.
3. Dictionary 생성
각 세그먼트에 대해 dictionary를 생성한다.
dictionary의 키는 세그먼트 인덱스이고, value는 해당 세그먼트에 속하는 모든 이미지의 p-Hash값이다.
4. 중복 이미지 탐지
모든 dictionary를 탐색하면서 pair-wise 이미지의 p-Hash값 간의 hamming distance를 계산한다.
Hamming distance는 두 해시 값이 얼마나 다른지를 나타내는 지표이다.
두 이미지의 hamming distance가 특정 임계값 미만인 경우, 두 이미지는 중복으로 간주된다.
5. 중복 이미지 제거
중복으로 판별된 이미지 중 하나를 제거한다.
ex)



Data analysis
데이터 확장을 위해 사용된 각 소스 데이터셋
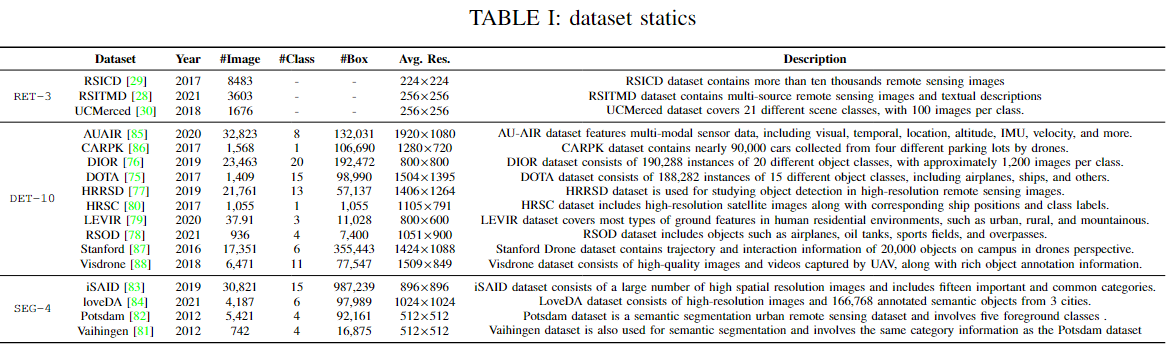
이는 세 그룹으로 나눌 수 있다.
1. 검색 데이터 (RET-3)
Remote sensing을 위한 세 가지 주요 이미지-텍스트 데이터셋을 직접 채택
- RSICD, RSITMD, UCM 세 가지 데이터셋으로 구성
이러한 데이터셋의 Caption은 인간이 주석을 달았기 때문에 캡션 품질이 높지만 데이터셋 크기는 작다.
인간이 주석을 단 고품질의 작은 이미지-텍스트 데이터셋
2. 탐지 데이터 (DET-10)
탐지 데이터셋은 데이터셋 확장의 주요 소스이다.
이러한 데이터셋은 RET-3 데이터셋보다 훨씬 높은 해상도를 가지고 있다.
이 그룹의 데이터셋은 위성 이미지와 UAV 이미지를 모두 포함하여 높은 도메인 다양성을 보여준다.
객체 탐지 주석이 있는 고해상도 및 고다양성 데이터셋
3. 세분화 데이터 (SEG-4)
4개의 인기 있는 remote sensing 세분화 데이터셋을 채택하고 M2B를 통해 변환한 후 B2C를 수행했다.
이러한 데이터셋도 높은 이미지 해상도와 도메인 다양성을 가지고 있다.
세분화 주석이 있는 고해상도 및 고다양성 데이터셋
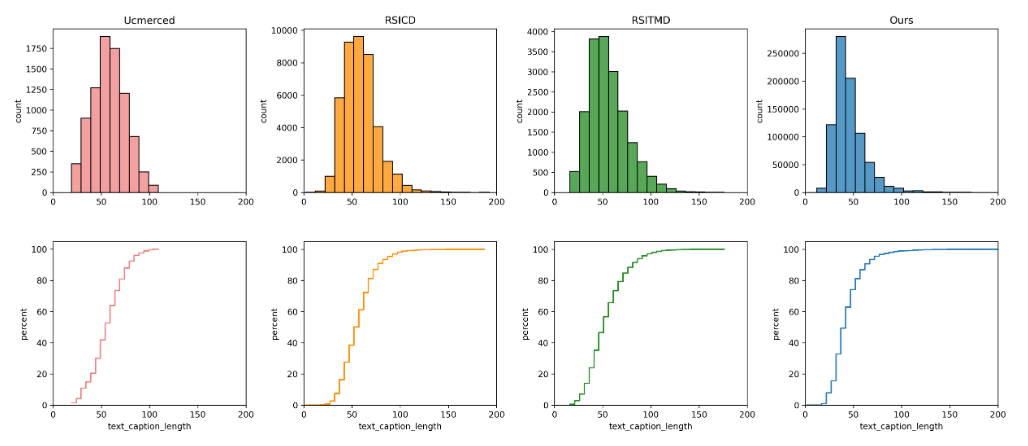
RET-3 데이터와 B2C+M2B로 변환된 (DET-10, SEG-4)데이터의 캡션 길이 분포를 시각화하였다.
- DET-10 -> B2C변환 : 기존 bounding box와 클래스 라벨만 존재했던 데이터를 자연어 Caption으로 변환
- SEG-4 -> M2B변환 -> B2C변환
B2C와 M2B 접근 방식은 RET-3 데이터의 캡션 분포와 매우 유사한 캡션 분포를 생성한다.
B2C + M2B를 통해 변환하는 방식이 자연스러운 캡션을 생성하는 데 효과정임을 보여줌
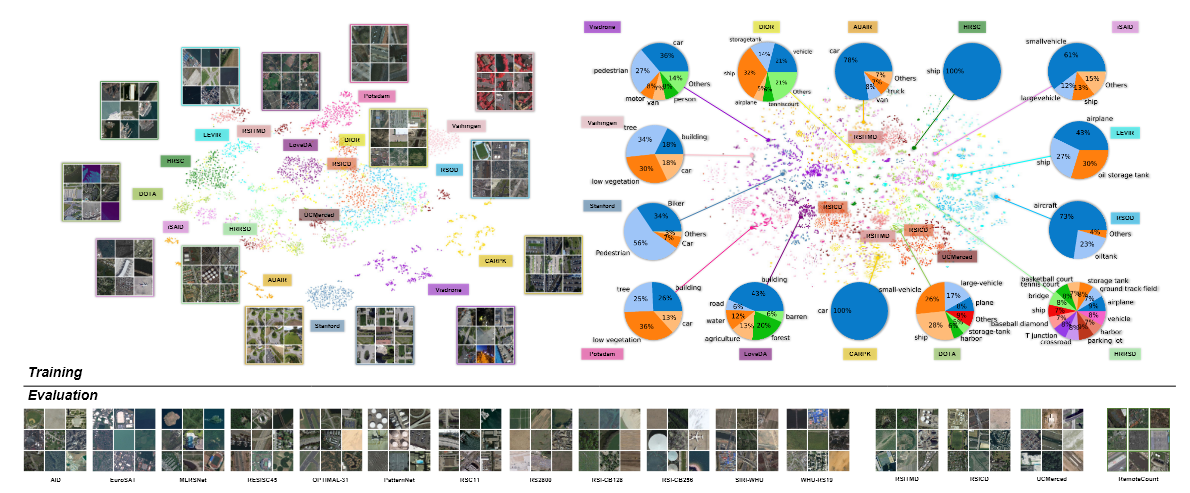
최종 데이터(DET-10+SEG-4+RET-3)의 T-SNE 시각화를 생성했다.
최종 데이터의 각 하위 집합에서 2k개의 샘플을 선택하여 시각화 수행
기존 데이터 (RET-3) + 새롭게 변환된 데이터 (DET-10 & SEG-4)
- DET-10 (객체 탐지 데이터) → B2C(Box-to-Caption) 변환을 적용하여 image-text 데이터로 변환
- SEG-4 (세그멘테이션 데이터) → M2B(Mask-to-Box) 변환 → B2C 변환을 적용하여 image-text 데이터로 변환
Experiments
벤치 마킹
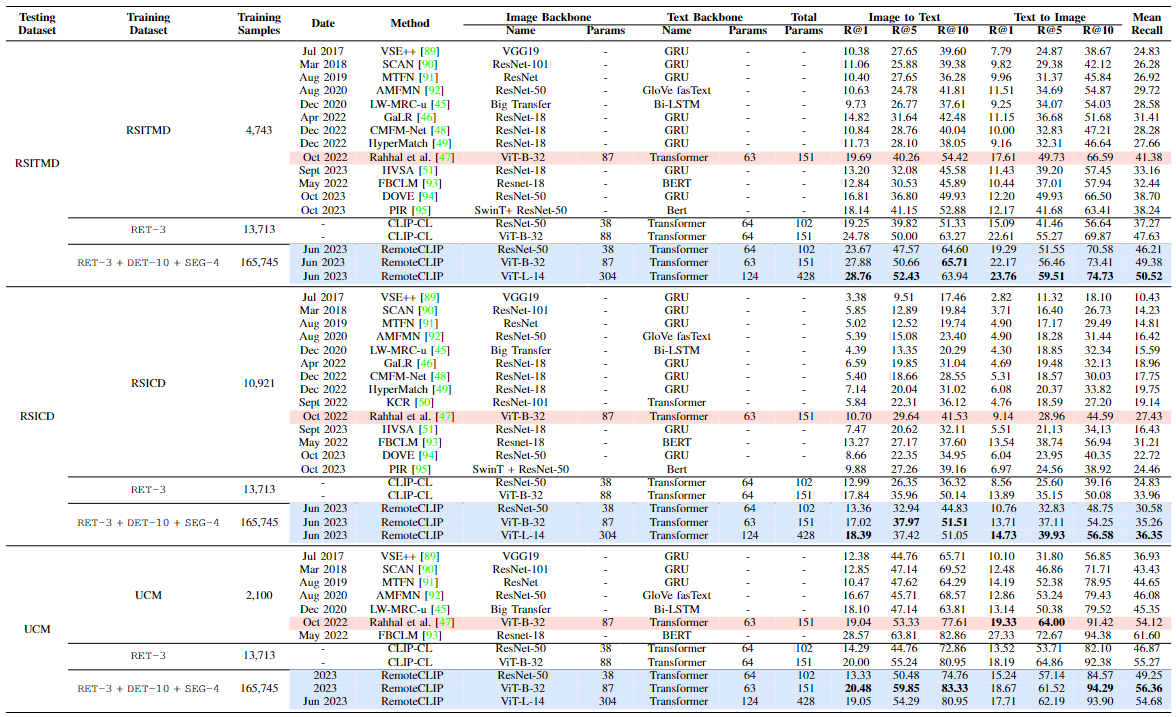
Cross-modal retrieval
- RemoteCLIP은 세 가지 원격 감지 이미지-텍스트 검색 벤치마크(RSITMD, RSICD, UCM)에서 평가됨
- 평가 지표는 Top-1, Top-5, Top-10 리콜(Recall) 및 평균 리콜(Mean Recall)
객체 계수 (Object Counting)
- 새로운 원격 감지 객체 계수 벤치마크인 RemoteCount를 도입
- 이 데이터셋은 DOTA 데이터셋의 검증 세트에서 선택된 947개의 이미지-텍스트 쌍으로 구성
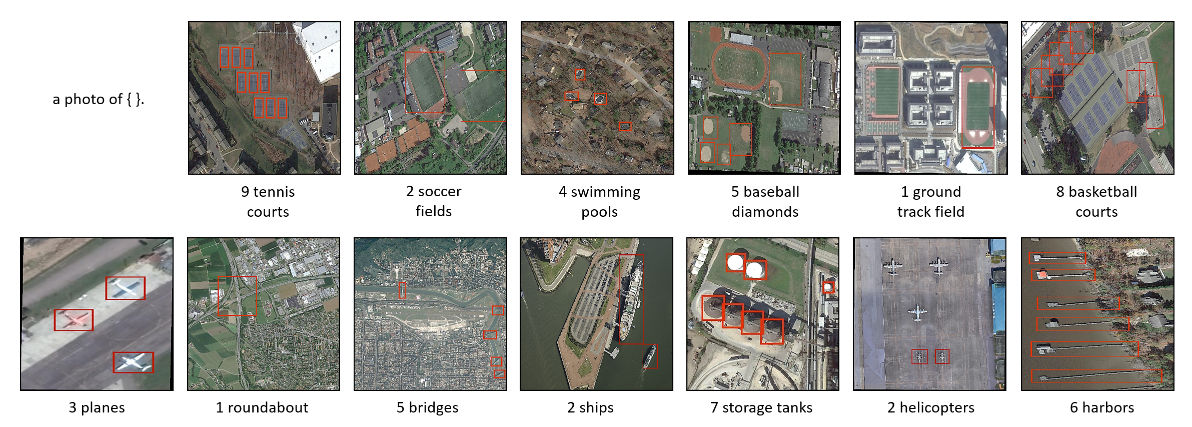
RemoteCLIP은 CLIP 대비 더 정확한 객체 계수 능력을 보여주었으며, 특히 숫자를 텍스트로 표현할 때 더 강력한 성능을 보였습니다.
제로샷 이미지 분류 (Zero-shot Image Classification)
- 12개의 원격 감지 이미지 분류 데이터셋에서 RemoteCLIP의 제로샷 분류 성능을 평가
- RemoteCLIP은 CLIP 대비 평균 정확도에서 2.85%(ResNet-50), 6.39%(ViT-Base-32), 5.63%(ViT-Large-14)의 성능 향상을 보임
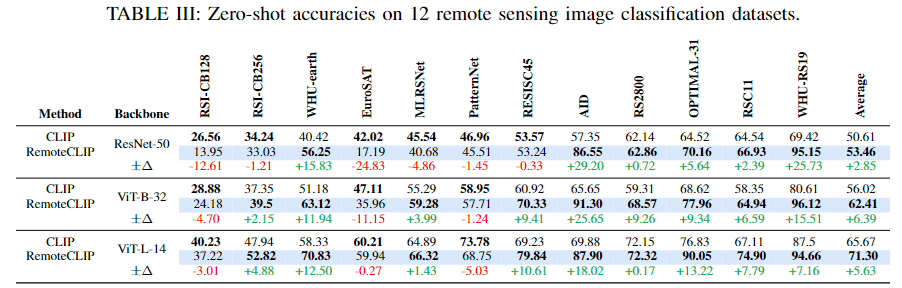
특히, ViT-Large-14 기반 RemoteCLIP은 12개 데이터셋 중 9개에서 CLIP을 능가함
Few-shot 분류 (Few-shot Classification)
- Few-shot 학습 설정에서 RemoteCLIP의 성능을 평가
- 1-shot, 4-shot, 8-shot, 16-shot, 32-shot 설정에서 모델을 평가
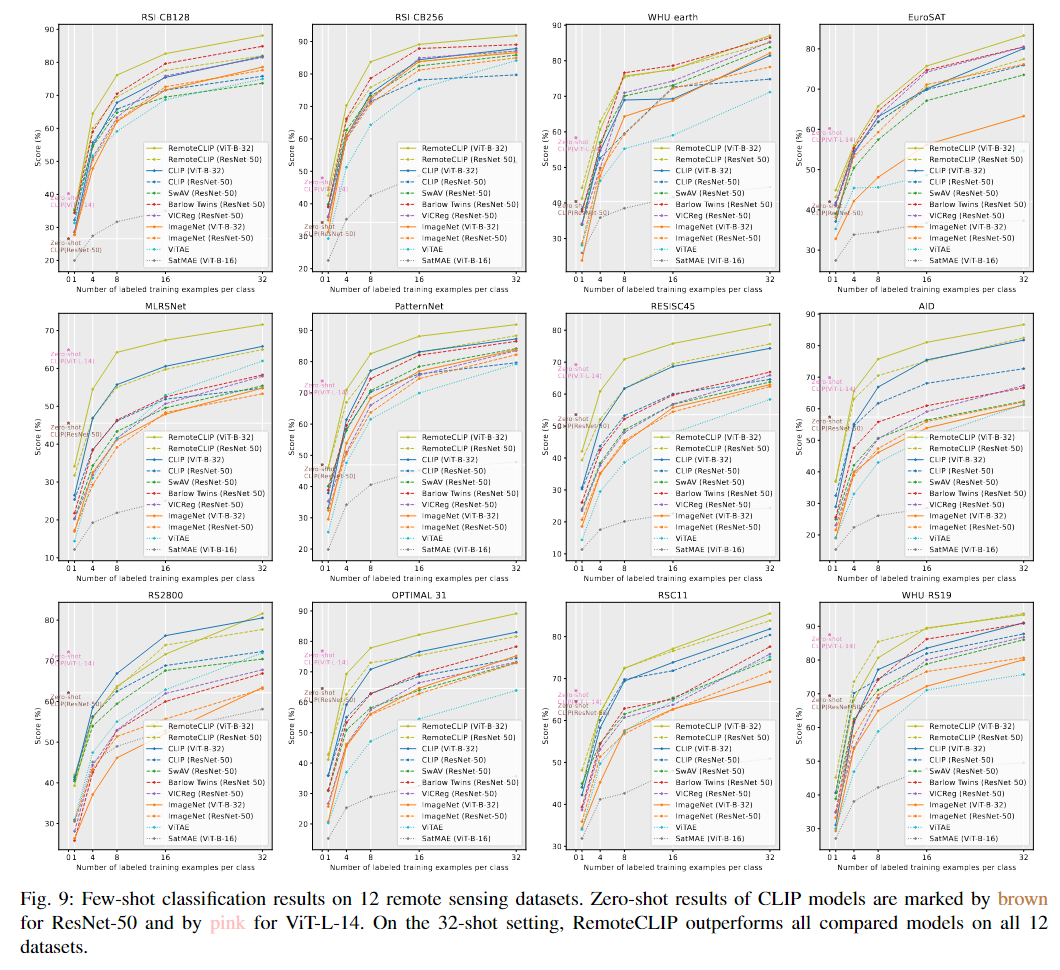
RemoteCLIP은 Few-shot 학습에서도 우수한 성능을 보였으며, 32-shot 설정에서는 모든 비교 모델을 능가했습니다.
풀샷 선형 탐색 및 k-NN 분류 (Full-shot Linear Probing and k-NN Classification)
- 12개의 원격 감지 이미지 분류 데이터셋에서 선형 탐색(Linear Probing) 및 k-NN 분류 성능을 평가

RemoteCLIP은 CLIP 및 기존 자기 지도 학습 모델보다 우수한 성능을 보임

비밀 댓글입니다...