Abstract
본 논문은 교차 모달 이해와 생성을 모두 수행할 수 있는 새로운 비전-언어 기반 모델인 mPLUG를 제안한다.
기존 사전 학습된 모델들은 주로 긴 시각적 시퀀스와 교차 모달 정렬로 인해 발생하는 낮은 계산 효율성과 정보 비대칭 문제를 겪는다.
이를 해결하기 위해 mPLUG는 새로운 교차 모달 스킵 연결을 도입한 효과적이고 효율적인 비전-언어 아키텍처를 제안한다.
이 아키텍처는 시각적 측면에서 시간 소모적인 전체 셀프 어텐션을 건너뛰기 위해 특정 레이어를 스킵하는 계층 간의 단축 경로를 생성한다.
mPLUG는 대규모 이미지-텍스트 쌍에서 판별 및 생성 목표를 사용하여 엔드-투-엔드 방식으로 사전 학습되었다.
기존 비전-언어 모델들은 긴 시각적 시퀀스를 처리하거나 모달리티 간 정보 정렬을 수행할 때, 효율성과 성능에서 한계에 부딫힘
교차 모달 스킵 연결을 도입한 비전-언어 기반 모델인 mPLUG를 제안함
특정 레이어에서 완전한 셀프 어텐션 계산을 건너뛰는 방식인 스킵 연결로 계산 효율성을 극대화함
1. Introduction
비전-언어 모델 학습의 가장 큰 도전 과제는 두 모달리티 간의 의미적 간극을 줄이기 위해 적절한 크로스모달 정렬을 찾는 것이다.
기존에 시각적 시퀀스를 모델링하는 방법은 사전 학습된 객체 검출기를 활용하여 이미지에서 중요한 영역을 추출한 뒤 이를 언어적 표현과 정렬하는 방식을 채택했다. 하지만 이러한 아키텍처는 제한 요소가 존재하고 계산 비용이 많이 소모된다.
기존 모델은 사전학습된 객체 검출기를 사용하여 사전에 정의된 특정 시각적 영역을 추출한 뒤, 텍스트 표현과 정렬하여 크로스 모달 학습을 수행했었다.(CNN으로 객체 특징 추출해서 벡터화)
중요한 영역만 추출하여 학습 효율성은 향상되었지만 고해상도 이미지 데이터를 다룰 경우 계산 비용 증가
객체 검출기에 강하게 의존하기 때문에 객체 검출기의 오탐이나 특정 카테고리로 제한된 특징만 학습하기에 예측할 수 없는 시각적 정보를 표현하는 데 한계가 있어서 전체 모델의 성능에 영향을 미침
최근 연구에서는 객체 검출기에 대한 의존성을 줄이고, 이미지와 텍스트 표현 간의 직접적인 정렬을 가능하게 하는 엔드투엔드 접근법을 제안한다.
이 모델들은 긴 시퀀스의 이미지 패치나 격자 형태의 시각적 표현을 사용하여 세부적인 시각적 표현을 추출하고 이해하는 데 중점을 둔다.
객체 검출기를 사용하지 않기 대문에 사전 정의된 시각적 카테고리의 한계를 극복할 수 있고, 시각적 특징 추출과정과 텍스트 정렬 과정이 통합되어 더 강력한 크로스 모달 표현을 학습할 수 있다.(이미지를 패치 단위(patch-based)로 나누고, 이미지 전체를 Transformer와 같은 뉴럴 네트워크로 처리)
이미지 전체를 패치로 나누어 학습하기 때문에 더 세밀한 정보 학습이 가능하지만 처리할 시각적 데이터 시퀀스 길이가 길어져 계산 비용이 증가
하지만, 이미지의 세밀한 정보와 텍스트의 간결한 정보 간 균형을 맞추는 데 어렵기 때문에 텍스트와 이미지를 동일한 방식으로 처리할 경우, 이미지 정보를 충분히 활용하지 못하게 되는 문제가 발생
그러나 긴 시각적 시퀀스를 모델링할 때 두 가지 주요 문제가 발생한다.
-
계산 효율성 문제 : 긴 시각적 시퀀스에 대한 완전한 셀프 어텐션은 텍스트 시퀀스보다 훨씬 많은 계산을 필요로 한다.
-
정보 비대칭 문제 : 이미지-텍스트 사전 학습 데이터의 캡션 텍스트는 보통 짧고 추상적이며, 이미지는 세부적이고 다양한 정보를 제공한다.
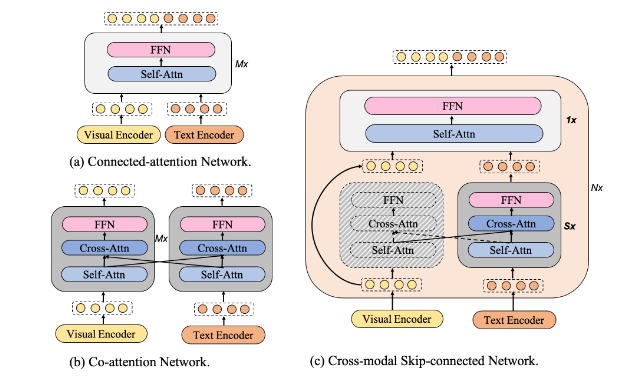
멀티 모달을 융합할 수 있는 방법 중 하나는 "connected-attention network"와 "Co-attention Network"가 있다.
Connected-attention Network은 시각적 특징과 텍스트 특징을 하나의 시퀀스로 결합한 뒤, 하나의 Transformer에 입력하여 처리하는 방식이다.
visual encoder로 이미지 데이터를 패치로 나누어 패치에 대한 벡터로 생성하고 text encoder로 텍스트의 단어 토큰을 임베딩한 뒤 이미지 패치 벡터와 텍스트 임베딩 벡터를 연결시켜 Transformer에 입력하여 셀프 어텐션을 통해 시퀀스 내 모든 요소 간 상호작용을 학습한다.
긴 시각적 시퀀스를 처리할 경우에 Transformer의 셀프 어텐션에서 토큰 간 관계를 계산하는 비용이 길이에 따라 매우 증가하여 계산량이 커지게 되고 이미지 정보와 텍스트 정보의 비대칭성으로 정보가 충분히 반영되지 않는 문제가 발생한다.
Co-attention Network는 이미지와 텍스트 데이터를 별도로 처리하고 크로스 어텐션을 통해 모달리티 간 상호작용을 학습하는 방식이다.
visual encoder로 이미지 데이터를 패치로 나누어 패치에 대한 벡터로 생성하고 text encoder로 텍스트의 단어 토큰을 임베딩한 뒤 이미지와 텍스트는 각각 독립적인 Transformer에서 처리된다.
셀프 어텐션에서 시퀀스 내 요소 간 관계를 학습한다. 이미지 패치 간 공간적 관계나 텍스트 토큰 간의 문맥적 관계를 학습.
크로스 어텐션에서 두 모달리티 간 시퀀스를 입력으로 받는다.
셀프 어텐션과 비슷하지만 쿼리와 키,밸류가 생성되는 모달리티가 다르다.
(이미지 네트워크에서는 Query가 이미지 패치에서 생성되고, Key와 Value는 텍스트 토큰에서 생성된다.)이미지 네트워크에서는 텍스트 정보를 반영한 시각적 특징을 출력하게 되고, 텍스트 네트워크는 이미지 정보를 반영한 언어적 특징을 추출하게 되고, 이후 각각의 네트워크에서 Feed Forward Network를 통해 각 시퀀스의 특징을 강화하여 표현을 각각 생성한다.
독립적으로 학습하기 때문에 두 네트워크가 각각 독립적으로 자원을 소모하게 되어 모델의 파라미터 수가 증가하게 되고 계산 비용이 증가한다.
이를 해결하기 위해, 우리는 새로운 비전-언어 모델인 mPLUG를 제안한다.
mPLUG는 기존 모델과는 다르게, 계산 효율성과 정보 비대칭성을 동시에 해결하기 위해 설계된 교차 모달 스킵 연결을 도입한다.
새로운 교차 모달 스킵 연결을 도입하여 계산 효율성과 정보 비대칭 문제를 동시에 해결한다.
mPLUG는 시각적 표현 학습에서 긴 시각적 시퀀스를 효율적으로 처리하기 위해 다음과 같은 설계 요소를 포함한다.
-
스킵 연결 기반 아키텍처 : mPLUG는 특정 레이어에서 완전한 셀프 어텐션 계산을 건너뛰는 방식으로 설계되어 계산 비용을 줄이면서도 중요한 시각적 정보를 유지한다.
-
효율적인 크로스모달 정렬 : 스킵 연결은 시각적 특징을 언어적 표현과 정렬하기 위해 최적화된 경량화된 아키텍처를 제공한다.
우리는 mPLUG를 대규모 이미지-텍스트 쌍 데이터셋에서 학습하며, 판별 및 생성 학습 목표를 모두 사용한다.
이 논문에서는 mPLUG의 설계와 구현, 그리고 다양한 비전-언어 작업에서의 실험 결과를 제시한다.
2. Related Work
2.1 Vision-Language Pre-training (비전-언어 사전 학습)
서로 다른 모달리티의 정보를 통합하는 방식에 따라 기존의 비전-언어 사전 학습(VLP)는 크게 듀얼 인코더(Co-attention Network)와 퓨전 인코더(connected-attention network) 두 가지로 나뉜다.
듀얼 인코더(Co-attention Network)는 두 개의 단일 모달 인코더를 사용하여 이미지와 텍스트를 개별적으로 인코딩한 다음 내적과 같은 간단한 함수를 사용하여 이미지와 텍스트 간의 상호 작용을 모델링하는 방식이다.
CLIP 및 ALIGN과 같은 모델은 이미지와 텍스트를 사전에 계산하고 캐싱할 수 있어 계산 효율이 높고 검색 작업에 적합하다.
하지만, VQA와 같이 복잡한 추론을 요구하는 비전-언어 이해 작업에서는 성능이 저하될 수 있다.
이미지와 텍스트를 독립적으로 처리하기 때문에 이미지의 특정 부분과 텍스트의 특정 단어 간 관계를 세부적으로 학습하기는 어렵다.
VQA같은 경우 이미지 내 특정 객체의 위치나 관계를 이해하는 것이 중요하기 때문에 위치 정보 학습에 한계가 있다.
퓨전 인코더(connected-attention network)는 이미지와 텍스트를 동시에 인코딩하여 모달리티 간의 복잡한 상호작용을 모델링하는 방식이다.
비전-언어 이해 작업에서 이미지와 텍스트 간의 근본적인 연관성을 더 잘 포착할 수 있다.
하지만, 모든 가능한 이미지-텍스트 쌍을 공동 인코딩해야 하므로 추론 속도가 상대적으로 느리다.
퓨전 인코더는 이미지 벡터와 텍스트 벡터를 하나의 시퀀스로 결합하는데 셀프 어텐션은 시퀀스 길이에 따라 계산 복잡도가 증가하기 때문에 셀프 어텐션의 계산량이 증가하게 되며 속도가 느려진다.
mPLUG는 기존 방식(듀얼 인코더, 융합 인코더)에서 발생하는 계산 비용과 정보 비대칭 문제를 해결하기 위해 크로스-모달 스킵 연결(Cross-Modal Skip Connections)이라는 새로운 모달리티 연결 메커니즘을 도입한다.
2.2 Skip-Connection (스킵 연결)
스킵 연결은 딥 뉴럴 네트워크의 최적화 과정에서 발생할 수 있는 기울기 소실 또는 기울기 폭발 문제를 해결하기 위해 널리 사용되는 기술이다.
ResNet과 Transformer와 같은 컴퓨터 비전 및 자연어 처리 아키텍처에서 폭넓게 사용된다.
최근 몇 년 동안 다양한 스킵 연결 방법이 제안되었다
스킵연결은 이전 레이어의 출력을 다음 레이어로 직접 전달하여, 중간 레이어의 변환 과정에 상관없이 중요한 정보를 유지하도록 하는 것으로 Residual Learning에서 사용된다.
입력 데이터 x를 중간 레이어를 통해 변환한 결과를 F(x)라고 하면 y=F(x)이지만, 스킵 연결에서는 입력 데이터 x를 변환된 결과 F(x)에 직접 더하는 방식으로 y = F(x) + x가 된다.
- 스킵 연결을 통해 입력 정보가 변환 과정을 건너뛰어 출력에 영향을 미치므로, 중요한 정보가 손실되지 않는다.
깊은 네트워크에서도 모델이 안정적으로 학습할 수 있다.
- ResNet : 간단한 아이덴티티 매핑을 사용하여 서로 다른 레이어 간의 합산 지름길 연결을 도입
- Highway Networks : 입력과 변환된 입력의 균형을 제어하기 위해 변환 게이팅 함수를 설계
- DenseNet : 이전 레이어의 모든 중간 표현을 재사용할 수 있도록 연결된 스킵 연결을 설계.
기존 스킵 연결은 신경망에서 정보의 흐름을 개선하고, 기울기 소실 문제를 완화하는 데 사용되었다.(ResNet, DenseNet) 스킵 연결은 네트워크의특정 레이어를 건너뛰거나 정보를 연결하여 계산 비용을 줄이면서도 중요한 정보를 유지한다.
mPLUG는 기존의 스킵 연결을 확장하여 교차 모달 스킵 연결을 도입하여 계산 효율성을 극대화하고 정보 비대칭 문제를 해결하였다.
본 연구에서는 크로스 모달 융합 문제를 해결하기 위해 새로운 크로스 모달 스킵 연결 방법을 제안하고, 서로 다른 모달의 연결된 표현을 모두 처리할지 아니면 각 레이어에서 크로스 모달 상호 작용 부분에만 집중할지 선택하기 위해 연결 스킵 연결과 합산 스킵 연결을 결합한다.
3. mPLUG
이 섹션에서는 먼저 크로스 모달 스킵 연결 네트워크의 핵심 모듈이 포함된 새로운 모델 아키텍처를 소개한 다음, 사전 훈련 목표와 확장 가능한 훈련 인프라에 대해 자세히 설명한다.
3.1 Model Architecture
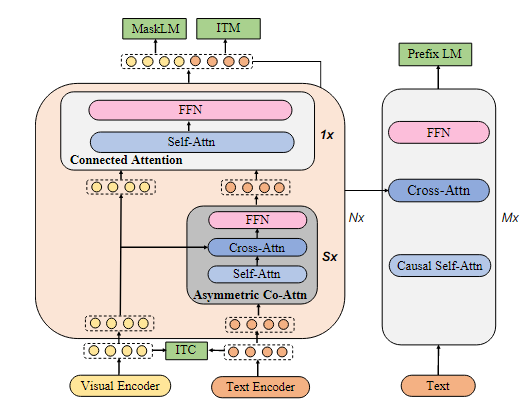
mPLUG는 이미지와 텍스트를 독립적으로 처리하는 두 개의 단일 모달 인코더, 교차 모달 스킵 연결 네트워크, 텍스트 생성을 위한 디코더로 구성된다.
모달리티 별 고유 정보를 더 잘 모델링하기 위해, 우리는 먼저 두 개의 단일 모달 인코더를 사용해 이미지와 텍스트를 별도로 각각 인코딩한다.
이미지 패치에 대해 비주얼 트랜스포머를 시각적 인코더로 사용하며, 이는 사전 학습된 객체 탐지기를 사용하는 것보다 계산 효율이 높다.
시각적 인코더는 입력 이미지를 패치로 나누고 이를 시퀀스 임베딩으로 인코딩한다.
mPLUG에서는 Pre-trained Object Detector를 Encoder로 사용하지 않고 Visual Transformer를 Encoder로 사용하여 이미지를 패치단위로 나누어 각 패치를 토큰으로 간주하여 임베딩한 후 Transformer에 입력으로 전달하여 어텐션 메커니즘을 통해 전체 이미지에 대한 시각적 특징을 생성한다.
객체 탐지기는 CNN 아키텍처를 사용하여 특정 객체 영역의 특징 추출
텍스트 입력은 단어 단위로 나누어 임베딩하여 텍스트 인코더로 전달된다.
참고 문헌에서 An empirical study of training end-to-end vision-and-language transformers. 논문에 따르면 pre trained된 BERT를 텍스트 인코더로 사용했을 것.
명시가 안 되어있는 것을 보아 트랜스포머 기반 모델을 사용하는 것이 암묵적 사실로 간주되었을 것이다.
이후, 패치 단위 임베딩 벡터와 텍스트 입력에 대한 텍스트 임베딩 벡터는 여러 multi skip-connected fusion blocks으로 구성된 modal skip-connected network로 전달된다.
Modal Skip-connected Network는 이미지와 텍스트를 결합하여 처리하는 네트워크이다. 이 네트워크는 여러 개의 Multi Skip-connected Fusion Blocks로 구성되어 있다.(Connected Attention과 Asymmetric Co-Attention 블록)
각 Fusion block은 이미지와 텍스트 간의 정보를 fusion하는 역할을 하거나, skip connection을 통해 중요한 정보를 상위 계층으로 전달하는 역할을 한다.
각 skip connected fusion 블록에서 고정된 stride 값 S를 asymmetric co-attention layers(비대칭 공동 어텐션 레이어)에 적용하여 이미지와 텍스트 간 정보를 결합한다.
Cross-Attention이 이미지와 텍스트 간의 상호작용을 학습하여 연결된 크로스-모달 융합(Connected Cross-modal Fusion)을 수행
- 이미지와 텍스트 간의 시퀀스 길이 차이를 해결하기 위해 비대칭적으로 설계되었음.
S(stride)는 데이터를 처리할 때 건너뛰는 간격을 나타내는 값으로 asymmetric co attention layer에서 긴 시퀀스를 처리할 때 S의 크기만큼 건너뛰어 처리하여 계산량을 줄인다.
이 네트워크의 목표는 connected cross-modal fusion의 효과성과 asymmetric co-attention layers의 효율성을 활용해 강화된 교차 모달 융합을 반복적으로 수행하는 것이다.
마지막으로, 출력된 교차 모달 표현은 시퀀스-투-시퀀스 학습을 위해 트랜스포머 디코더에 전달되어 mPlUG에 이해 및 생성 기능을 모두 제공한다.
- 마지막으로, 이렇게 섞인 정보를 디코더라는 도구에 넘겨준다. 디코더는 이 정보를 바탕으로 텍스트를 생성하거나 질문에 답하는 식으로 결과를 만들어낸다.
=>이미지와 텍스트를 따로 학습한 다음, 서로 연결해서 결과를 만들어낸다.
3.2 Cross-modal Skip-connected Network
교차 모달 스킵 연결 네트워크(Cross-modal Skip-connected Network)는 N개의 스킵 연결 융합 블록으로 구성된다.
각 스킵 연결 융합 블록(Skip-connected Fusion Block)에서, S개의 비대칭 공동 어텐션 레이어(asymmetric co-attention layer)마다 연결된 어텐션 레이어(Connected Attention)를 채택한다.
교차 모델 스킵 연결 네트워크 = N개의 스킵 연결 융합 블록
스킵 연결 융합 블록 = S개의 비대칭 공동 어텐션 레이어 + 1개의 Connected Attention
비대칭 공동 어텐션 레이어
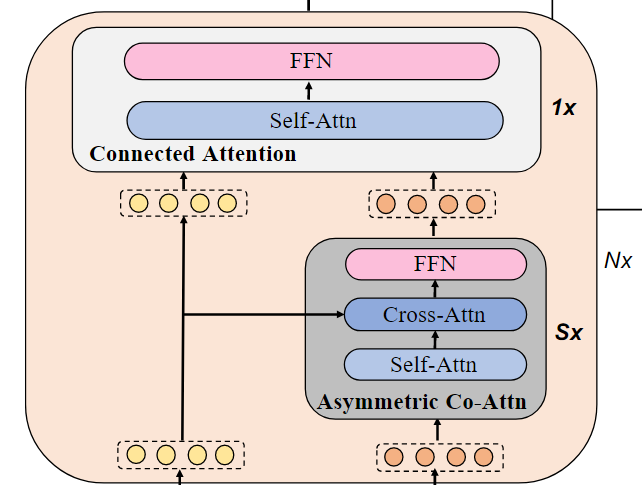
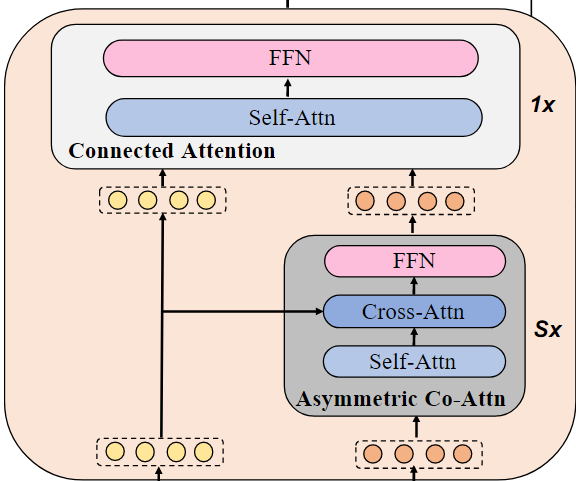
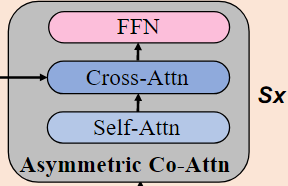

먼저, 단일 모달 인코더에서 나온 텍스트 특징과 이미지 특징을 S개의 비대칭 공동 어텐션 레이어를 통해 처리한 후, 출력된 텍스트 특징과 이미지 특징을 하나의 연결된 어텐션 레이어에 결합한다. 이 스킵 연결 융합 블록은 최종 연결된 이미지와 텍스트 표현을 얻기 위해 N번 반복된다.
asymmetric co-attention layer 내부 과정
asymmetric co-attention layer는 한 번에 복잡한 관계를 학습할 수 없으므로, S번 반복하여 점진적으로 학습한다.
- 셀프 어텐션을 통해 이전 단계의 텍스트 특징 간 관계를 학습
l^n은 이전 단계의 텍스트 특징
- 크로스 어텐션을 통해 이전 단계의 텍스트-이미지 간 관계를 학습
이미지 정보를 반영한 텍스트 특징 출력
- FFN을 통해 텍스트 특징을 비선형 변환
이전 layer에서 학습된 출력 결과가 다음 레이어의 셀프 어텐션으로 순차적으로 전달되며 S번 반복된다.
이미지 특징은 각 Cross Attention 단계(1,2,..S번째)에서 Self Attention을 거친 텍스트 특징과 결합되며, 이미지 특징은 Layer 간 변환되지 않고 동일한 이미지 특징이 각 단계마다 Cross Attention에 입력되고 텍스트 특징만 다음 단계로 변환되며 Self Attention으로 전달됨
전체 네트워크에서 총 N번 반복된다.
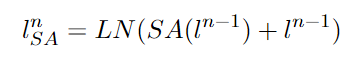
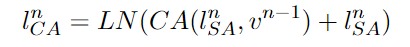
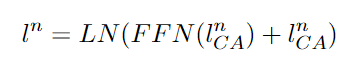
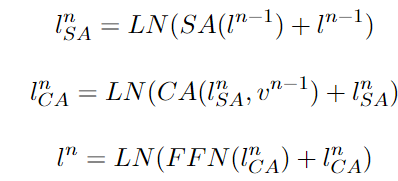
ITC(Image-Text Contrastive Learning)
이미지와 텍스트 간의 연관성을 학습하여, 같은 의미를 가진 텍스트와 이미지 특징 벡터를 임베딩 공간에서 가까운 위치에 배치하는 작업
-
visual encoder와 text encoder에서 각각 이미지와 텍스트의 특징 벡터를 추출한다.
-
텍스트와 이미지의 특징 벡터를 동일한 임베딩 공간으로 매핑한다.
이미지와 텍스트 벡터에서 같은 의미를 가진 텍스트와 이미지의 유사도(내적값)은 커지게, 다른 의미는 작아지게 한다.
connected attention 과정
asymmetric co-attention layer을 S번 거쳐 출력된 텍스트 특징 + 인코더에서 제공된 이미지 특징을 결합하여 최종적으로 하나의 통합된 표현을 생성한다.
Self-Attention단계
이전 단계에서 입력된 텍스트와 이미지 특징을 연결하여 하나의 벡터로 만든 뒤 셀프 어텐션의 입력으로 사용한다.
- 텍스트와 이미지 특징 간 관계를 동시에 학습한다.
- 셀프 어텐션은 특징을 모두 하나로 입력받지만 각 특징의 위치 정보를 보존하기 때문에 이미지 특징과 텍스트 특징을 구분하여 반환한다.
FFN단계
Self-Attention을 통해 출력된 이미지 특징과 텍스트 특징을 입력으로 받아 비선형 변환한다.
- 첫 번째 FC layer -> 비선형 활성화 함수 -> 두 번째 FC layer
FFN을 통해 출력된 이미지 특징과 텍스트 특징은 다음 반복의 Cross-modal Skip-connected Network으로 반복적으로 공급되어 N번 반복한다.
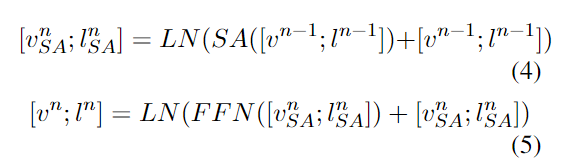
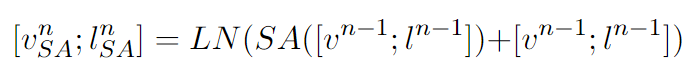
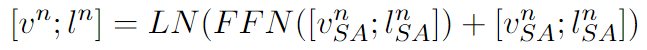
MaskLM
텍스트의 일부를 무작위로 마스킹하고, 이를 복원하도록 학습한다.
- 텍스트에서 일부 단어를 무작위로 마스킹하고, text encoder에 입력한다.
- Connected Attention Block까지 거쳐 마스킹된 텍스트와 이미지의 통합된 표현이 생성되어 MaskLM으로 전달된.
3.통합된 표현에서 마스킹된 위치를 기반으로 단어를 예측한다.각 단어에 대해 확률 분포를 생성하여 가장 높은 확률을 가진 단어를 복원
문맥 정보를 활용해 주변 단어와의 관계 파악, 이미지 정보를 사용하여 관련된 시각적 단서를 보완
- 예측된 단어와 실제 단어간 크로스 엔트로피 로스를 계산하여 학습한다.
_ITM__
텍스트와 이미지가 서로 매칭되는지 여부를 이진 분류한다.
1.통합된 표현을 입력으로 받아. 텍스트-이미지 쌍이 매칭되는지 1, 0으로 판단한다.
연결된 어텐션 레이어는 셀프 어텐션 레이어와 피드 포워드 네트워크로 구성된다.
우리는 이미지 특징과 입력 텍스트 특징을 결합하며, 입력 텍스트 특징은 S개의 비대칭 공동 어텐션 레이어의 출력이다.
연결된 이미지와 텍스트 특징은 셀프 어텐션 레이어와 피드 포워드 네트워크 레이어에 전달된다.


이후, [vn;ln]은 최종 연결된 이미지와 텍스트 표현을 얻기 위해 반복적으로 다음 교차 모달 스킵 연결 네트워크로 전달된다.
디코더
마지막으로, 연결된 출력(N번째 반복 후)은 시퀀스-투-시퀀스 학습을 위한 트랜스포머 디코더에 전달된다.
-
Causal Self-Attention: 이전 텍스트 토큰 간의 관계를 학습.(마스킹을 사용한 attention -> 트랜스포머 디코더에서 사용하는 방법)
각 토큰이 이전에 생성된 단어 토큰에서 주의를 기울일 수 있도록 마스킹하여 self attention을 계산한다.
-
Cross-Attention: Connected Attention Block 출력(이미지+텍스트 통합 표현)과 현재 입력 토큰 간의 관계를 학습.
-
Feed-Forward Network (FFN): 비선형 변환을 통해 다음 출력 토큰 예측.
디코더는 반복적으로 토큰을 생성하며, 각 단계에서 이전 출력 토큰을 새로운 입력으로 사용한다.

3.3 Pre-training Tasks
1. 이미지-텍스트 대조 학습 (Image-Text Contrastive, ITC)
우리는 ITC를 사용하여 단일 모달 인코더에서 출력된 이미지 특징과 텍스트 특징을 정렬한다.
구체적으로, 소프트맥스-정규화된 이미지-텍스트 및 텍스트-이미지 유사도를 계산하며, 두 개의 동적 메모리 큐(텍스트, 이미지)를 사용하여 부정적인 예제의 수를 증가시킨다.
모델이 이미지와 텍스트가 서로 얼마나 잘 어울리는지 판단할 수 있도록 학습한다.
이미지와 텍스트의 특징을 계산한 뒤 이미지-텍스트 사이의 유사도를 계산해 소프트맥스 함수로 정규화한다.
positive pair를 최대화하는 방향, nagative pair를 최소화하는 방향으로 학습학습을 더 잘 시키기 위해 부정적인 이미지-텍스트 쌍을 추가로 학습한다
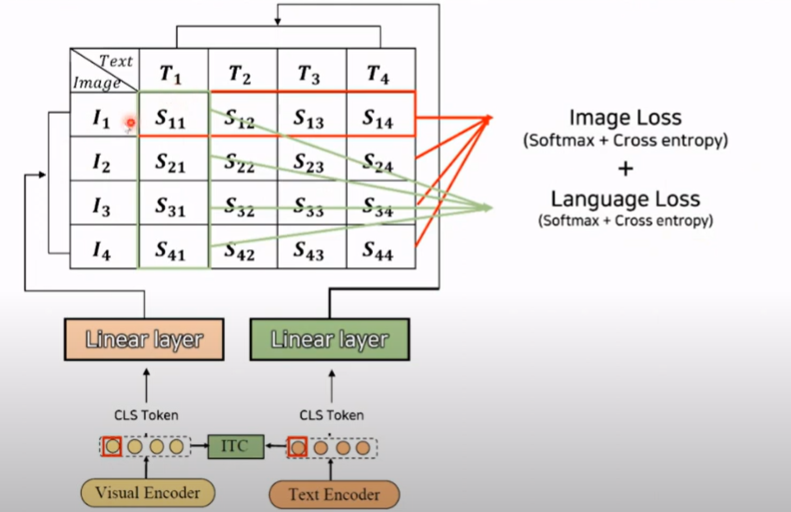
2. 이미지-텍스트 매칭 (Image-Text Matching, ITM)
ITM은 교차 모달 표현에서 이미지로 문장이 서로 일치하는지 여부를 예측하는 것을 목표로 한다.
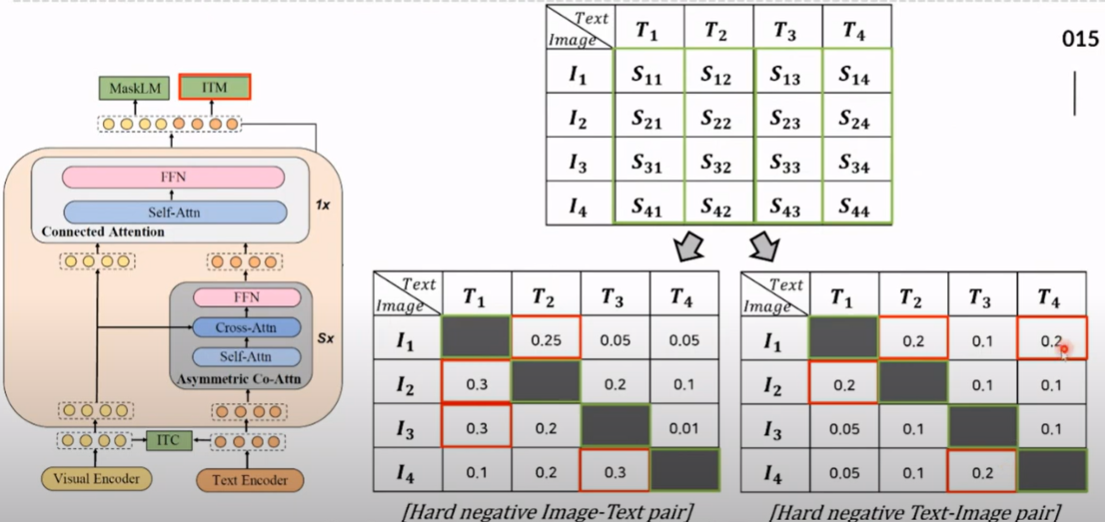
대조적인 텍스트-이미지 유사도를 기반으로 하여 하드 네거티브 이미지-텍스트 쌍을 선택한다.
주어진 이미지와 텍스트가 서로 맞는 쌍인지 판단하는 능력을 학습한다.
교차 모달 표현을 사용하여 이미지와 텍스트의 특징을 섞어서 새로운 표현을 만든다.
이후 모델이 이미지와 텍스트가 맞는지 아닌지를 예측한다.학습을 더 정확하게 하기 위해 아주 비슷하지만 틀린 쌍(하드 네거티브)를 활용한다.
image입장에서 가장 헷갈릴만한, text입장에서 가장 헷갈릴만한 하드 네거티브 pair를 사용Positive Pair의 점수를 1에 가깝게 최적화,Hard Negative Pair의 점수를 0에 가깝게 최적화.
3. 마스크 언어 모델링 (Masked Language Modeling, MLM)
MLM은 텍스트에서 15%의 토큰을 무작위로 마스킹한 후, 교차 모달 표현을 사용하여 이러한 마스킹된 단어를 예측한다.
텍스트의 일부 단어를 가리고, 모델이 가려진 단어를 예측하도록 학습한다.
4. 프리픽스 언어 모델링 (Prefix Language Modeling, PrefixLM)
PrefixLM은 이미지가 주어진 상태에서 캡션을 생성하고, 교차 모달 컨텍스트 이후 텍스트 세그먼트를 예측하는 것을 목표로 한다.
PrefixLM은 크로스 엔트로피 손실을 최적화하여 텍스트의 가능성을 자동 회귀 방식으로 최대화한다.
이미지를 보고 그에 맞는 텍스트(캡션)를 생성하도록 학습한다.
이미지에서 나온 특징을 텍스트 인코더에 넣고, 시작 문구(prefix)를 주어 모델이 나머지 텍스트를 자동으로 생성하게 한다.
ITC: 이미지와 텍스트가 얼마나 어울리는지 학습.
ITM: 이미지와 텍스트가 맞는 쌍인지 판단.
MLM: 문장의 가려진 단어를 예측.
PrefixLM: 이미지를 보고 텍스트(캡션)를 생성.
4 Distributed Learning on a Large Scale
mPLUG와 같은 대규모 모델을 대규모 데이터셋에서 학습하여면 많은 효율성 문제에 직면하게 된다.
우리는 메모리 사용량과 계산 시간을 줄이는 관점에서 처리량을 증가시켜 모델 학습을 가속화한다.
모델 학습 중 메모리 사용량은 두 가지 주요 요소로 구성된다.
1. 정적 메모리 사용량 : 파라미터, 옵티마이저 상태, 그래디언트 등
2. 런타임 메모리 사용량 : 활성화 값과 같은 중간 변수로 인해 발생
정적 메모리를 최적화하는 방법으로 ZeRO기술을 사용하여 파라미터, 옵티마이저 상태, 그래디언트를 데이터 병렬 그룹 전체로 분할한다.
이를 통해 단일 GPU의 정적 메모리 오버헤드를 GPU 카드 개수 N에 비례해 약 1/N으로 줄일 수 있다.
런타임 메모리 최적화하는 방법으로 그래디언트 체크포인팅을 사용한다.
이를 통해 활성화 값을 메모리에 유지하지 않고, 백워드 패스 동안 일부 활성화 값을 다시 계산하여 런타임 메모리 사용량을 크게 줄인다.
계산 시간을 줄이기 위해 우리는 BF16 정밀도 학습을 사용한다.
BF16데이터 타입은 NVIDIA의 새로운 Ampere 아키텍처 GPU에서 지원된다.
이러한 메모리 절약 및 계산 가속 기술을 활용하여, mPLUG의 처리량은 3배 이상 증가하였다.
5. Experiments
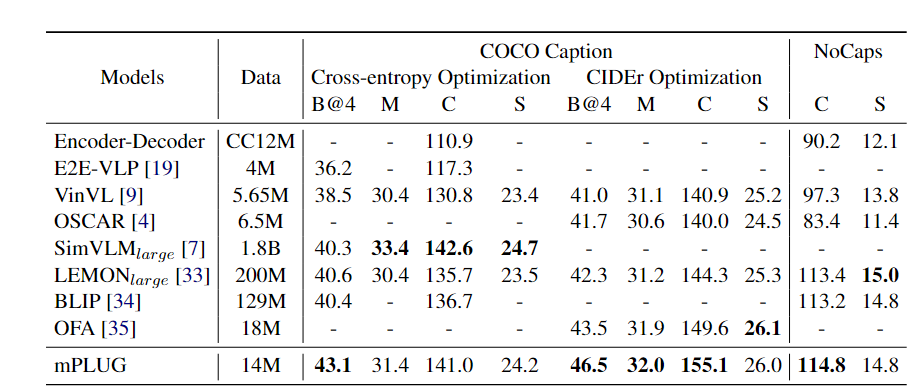
-
Models :테스트된 모델들의 이름
-
Data : 각 모델이 학습에 사용한 데이터의 크기
-
Coco Caption : 이미지 캡션 생성 성능 평가
- Cross-entropy Optimization: 일반적인 캡션 생성 최적화 방식.
- CIDEr Optimization: CIDEr 점수를 높이기 위한 최적화 방식.
-
B@4 (BLEU-4):
생성된 텍스트(캡션)가 정답 텍스트와 얼마나 유사한지를 평가.
단어 순서와 어구의 정확성을 측정. -
M (METEOR):
BLEU보다 더 세밀한 유사도를 평가.
어형 변화와 동의어를 고려하여 문장의 품질을 평가. -
C (CIDEr):
생성된 텍스트와 정답 간의 유사성을 TF-IDF(단어 빈도-역문서 빈도)를 기반으로 평가.
사람이 직접 평가한 점수와 가장 상관관계가 높은 지표. -
S (SPICE):
정답 문장에서 중요한 정보(의미론적 관계, 객체 간 상호작용 등)가 얼>>>마나 잘 반영되었는지를 평가.
-
-
NoCaps : 이미지 캡션 생성 성능을 평가하는 또 다른 데이터셋



전체 내용
Introduction
최근 대규모 사전 학습된 비전-언어 모델은 다양한 작업에서 성공을 거두고 있다. 비전-언어 모델의 핵심 과제는 이미지와 텍스트 간의 의미적 격차를 줄이는 것이다.
기존 접근법은 비효율성과 정보 비대칭성이라는 문제점이 존재한다.
mPLUG는 새로운 교차 모달 스킵 연결 네트워크를 제안하여 비효율성과 정보 비대칭 문제를 해결한다.
Related Work
비전-언어 사전 학습
-
듀얼 인코더 : 이미지와 텍스트를 각각 독립적으로 인코딩한 후, 간단한 연산을 통해 관계를 모델링
-
퓨전 인코더 : 이미지와 텍스트를 깊게 결합하여 복잡한 상호작용을 모델링
스킵 연결
딥러닝 모델에서 사용되는 기술로, 정보 소실을 막고 학습 안정성을 높임
mPLUG는 기존의 스킵 연결 방식을 교차 모달 설정에 맞게 확장
Model Architecture
1. 단일 모달 인코더
- 이미지 인코더 : 이미지 패치를 처리하며, 시각적 특징을 벡터로 변환
- 텍스트 인코더 : 텍스트를 처리하여 각 단어의 임베딩을 생성
2. 교차 모달 스킵 연결 네트워크
이미지와 텍스트의 특징을 연결하고 결합하는 역할
-
비대칭 공동 어텐션 : 텍스트를 중심으로 이미지에서 중요한 부분을 추출하고 텍스트의 특징에 이미지를 반영
-
연결된 어텐션 : 이미지와 텍스트를 결합하여 상호작용을 모델링
-
스킵 연결 : 특정레이어를 건너뛰어 계산 효율성을 높이고, 정보 소실을 방지
3. 디코더
교차 모달 표현을 기반으로 텍스트를 생성
Pre-traning Tasks
mPLUG는 네 가지 사전 학습 과제를 통해 모델의 이해와 생성 능력을 학습한다.
-
이미지-텍스트 대조 학습(ITC): 이미지와 텍스트가 서로 관련 있는지를 학습
-
이미지-텍스트 매칭(ITM): 주어진 이미지와 텍스트가 맞는 쌍인지 예측
-
마스크 언어 모델링(MLM): 텍스트의 일부 단어를 가리고, 이를 예측하도록 학습
-
프리픽스 언어 모델링(PrefixLM): 이미지를 보고 캡션을 생성하거나 텍스트의 나머지 부분을 예측
Distributed Learning on a Large Scale
메모리와 계산 효율성
1. ZeRO 기술 : GPU 메모리를 절약하기 위해 모델의 파라미터를 여러 GPU에 분산
-
그래디언트 체크 포인팅 : 활성화 값을 메모리에 저장하지 않고 필요할 때 다시 계산
-
BF16 정밀도 학습 : 계산 속도는 빠르면서 안정성을 높임
이러한 기술들을 통해 학습 처리량이 기존보다 3배 증가
