Abstract
오픈 보카뷸러리 의미론적 분할(Open-vocabulary semantic segmentation)은 학습 중 보지 못한 텍스트 설명에 따라 이미지를 의미론적 영역으로 나누는 것을 목표로 한다.
최근의 두 단계 접근법은 먼저 클래스에 구애받지 않는 마스크 제안을 생성한 다음, 사전 학습된 비전-언어 모델을 활용하여 마스크된 영역을 분류한다.
이 방식은 성능 병목 현상이 존재하며 마스크된 이미지에서 제대로 작동하지 않기 때문이다.
이를 해결하기 위해, 위 논문은 마스크된 이미지 영역과 이에 대응하는 텍스트 설명을 사용하여 finetuning(미세 조정)하는 방법을 제안한다.
또한, 모델 전체를 미세 조정하는 것 외에도, 우리는 마스크된 이미지의 빈 영역을 활용하는 마스크 프롬프트 튜닝이라는 방법을 제안한다.
이는 가중치를 수정하지 않고도 성능을 크게 향상시키며, 완성히 미세 조정된 모델에서도 추가적인 성능 향상을 제공한다.
1. Introduction
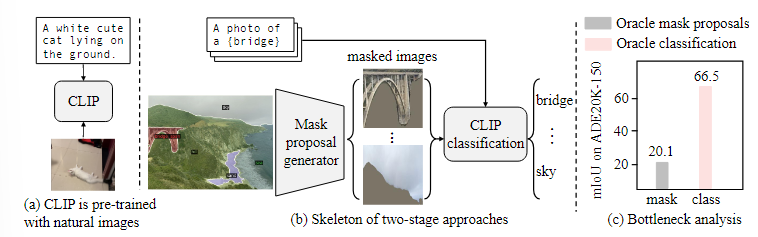
의미론적 분할(Semantic segmentation)은 이미지를 의미 있는 영역으로 그룹화하고 해당 영역에 의미론적 카테고리를 할당하는 것을 목표로 한다.
현대의 의미론적 분할 모델은 주로 사전에 정의된 카테고리로 학습되며, 보지 못한 클래스에 일반화하는 데 실패한다.
반면에 인간은 수천가지의 카테고리를 포함하는 오픈 보카뷸러리 방식으로 장면을 이해한다.
이러한 인간 수준의 인식에 접근하기 위해, 본 논문은 텍스트로 설명된 임의의 카테고리로 이미지를 분할하는 오픈 보카뷸러리 의미론적 분할을 연구한다.
비전-언어 모델(CLIP)은 수식업 규모의 이미지-텍스트 쌍에서 학습되어 풍부한 멀티모달 특징을 학습한다.
이 모델이 탁월한 오픈 보카뷸러리 분류 능력을 보임에 따라 이전 연구들은 사전 학습된 비전-언어 모델을 오픈 보카뷸러리 분할에 활용하는 방법을 제안하였고 이 중, 두 단계 방식은 큰 잠재력을 보여주었다.
이 방식은 클래스에 구애받지 않는 마스크 제안을 생성한 다음, 사전 학습된 비전-언어 모델을 활용하여 오픈 보카뷸러리 분류를 수행
이 방식의 성공은 두 가지 가정에 의존한다.
1. 모델이 클래스에 구애받지 않는 마스크 제안을 생성할 수 있다.
2. 사전 학습된 CLIP이 마스크된 이미지 제안에 대해 분류 성능을 전이할 수 있다.
이 두 가정을 검토하기 위해 분석을 수행하였고, 분석 결과 사전 학습된 CLIP이 마스크된 이미지에서 만족스러운 분류를 수행하지 못하며, 이는 두 단계 오픈 보카뷸러리 분할 모델이 성능 병목 현상이 됨을 보여주었다.
이러한 성능 저하가 마스크된 이미지와 CLIP의 학습 이미지 간의 도메인 차이에 의해 발생한다고 가정한다.
2. Related Work
Pre-trained Vision-Language Models
사전 학습된 비전-언어 모델은 시각적 개념을 텍스트 설명과 연결한다.
CLIP와 같은 사전 학습된 모델은 언어로 설명된 임의의 카테고리를 이미지에서 분류할 수 있는 강력한 오픈 보카뷸러리 분류 성능을 보유하고 있다.
이 논문의 연구는 CLIP을 객체 탐지 작업에 적합하도록 미세 조장한다.
하지만, 다음과 같은 차별점이 존재한다.
- 마스크 이미지를 처리하도록 CLIP을 적응시킨다.
- 마스크 이미지의 빈 영역을 활용하여 CLIP의 가중치를 변경하지 않고도 적응할 수 있는 마스크 프롬프트 튜닝을 제안한다.
Open-Vocabulary Segmentation
오픈 보카뷸러리 세그먼테이션은 텍스트로 설명된 임의의 카테고리를 사용해 이미지를 이해하는 것을 목표로 한다.
최근에는 사전 학습된 CLIP을 활용하는 연구들이 제안되었다.
이 논문의 접근법은 두 단계 방식에 속한다.
- 클래스 비특정 마스크 제안을 생성
- 사전 학습된 CLIP을 활용하여 오픈 보카뷸러리 분류 수행
이 논문은 다른 모델과 다르게 마스크된 이미지 분류 성능을 개선하기 위해 CLIP을 적응시키는 점에서 차별화된다.
Prompt Tuning
프롬프트 튜닝은 대규모 사전 학습 모델을 새로운 작업에 적응시키는 전략이다.
이 연구에서 제안된 마스크 프롬프트 튜닝은 시각적 도메인에서 프롬프트 튜닝과 관련이 있다.
학습 가능한 벡터를 이미지 도메인에 적용한 기존 연구들과 달리, 이 연구는 마스크된 토큰을 학습 가능한 프롬프트로 대체한다.
또한, 마스크 프롬프트 튜닝은 완전 미세 조정 모델에서도 추가적인 성능 향상을 제공한다.
3. Method
이 섹션에서는 두 단계 오픈 보카뷸러리 세그먼테이션 방법을 먼저 살펴본 뒤, 마스크-카테고리 데이터셋을 수집하는 방법과 마스크된 이미지를 처리하기 위해 CLIP을 적응시키는 제안된 마스크 프로므트 튜닝 기법을 설명한다.
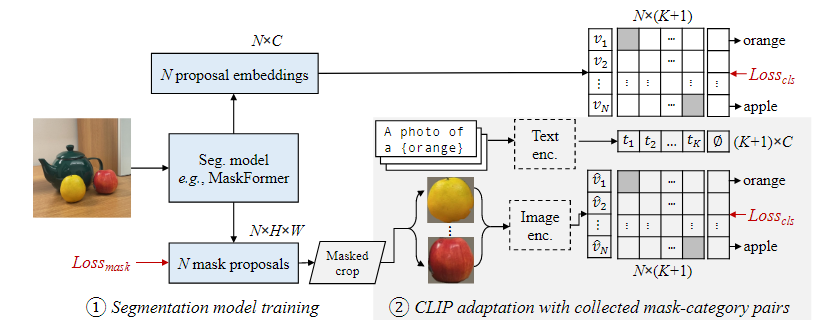
3.1. Two-stage models for open-vocabulary semantic segmentation(두 간계 방식의 오픈 보카뷸러리 의미론적 분할)
이 논문에서 제안하는 두 단계 오픈 보카뷸러리 의미론적 분할 모델은 두 가지 주요 구성 요소로 이루어져 있다.
- 마스크 제안을 생성하는 세그먼테이션 모델
- 오픈 보카뷸러리 분류를 수행하는 모델
세그먼트 생성 모델
우리는 MaskFormer를 세그먼트 생성 모델로 선택했다. MaskFormer는 기존의 픽셀 단위 세그먼테이션 대신, N개의 마스크 제안과 이에 해당하는 클래스 예측을 출력한다.
- 각 마스크는 H x W 크기의 이진 바이너리 행렬로, 대상 객체의 위치를 나타낸다.
- 클래스 예측은 훈련 세트 내 클래스 수 C에 해당하는 차원의 분포를 출력한다.
MaskFormer 수정
각 마스크에서 C-차원의 제안 임베딩을 생성하도록 설계했다.
- 여기서 C는 CLIP모델의 임베딩 차원을 나타낸다.
수정은 MaskFormer가 오픈 보카뷸러리 세그멘테이션을 수행할 수 있도록 만든다.
마스크와 텍스트 임베딩 비교
모델은 특정 클래스 K에 대해 다음과 같은 방식으로 클래스 확률을 예측한다.
-
텍스트 임베딩 생성 : CLIP의 텍스트 인코더를 사용해 각 클래스의 텍스트 임베딩을 생성한다.
-
코사인 유사도 계산 : 각 마스크 임베딩과 텍스트 임베딩 간의 코사인 유사도를 계산한다.
-
클래스 확률 예측
마스크된 이미지에서 CLIP 성능 문제
MaskFormer는 마스크 제안을 생성한다.
각 마스크는 전경 픽셀을 포함하는 바운딩 박스를 선택하여 이미지에서 잘라내고, 배경을 마스크 처리한 뒤, CLIP 입력 해상도로 크기를 조정한다.
그러나, CLIP은 마스크된 이미지에 대해 성능이 저하된다.
CLIP은 자연 이미지를 기반으로 학습되었으나, 마스크된 이미지는 빈 영역이 많아 도메인 차이가 크다.
이러한 차이로 인해 CLIP은 분류 성능을 잘 전이하지 못한다.
이 문제를 해결하기 위해, 우리는 마스크된 이미지를 처리하기 위한 마스크 프롬프트 튜닝 기법을 제안한다.
두 단계 모델 구조
1. 마스크 제안 생성 : 클래스 비특정적인 마스크를 생성하는 단계로 MaskFormer라는 세그멘테이션 모델을 사용하여 픽셀 단위의 세그멘테이션이 아닌, 각 물체 영역을 나타내는 N개의 마스크와 클래스 예측 확률 분포를 출력한다.
- 마스크 분류 : 마스크된 이미지를 CLIP모델에 입력하여 각 마스크가 어떤 클래스인지 분류한다. CLIP의 텍스트 인코더를 사용해 클래스 이름의 텍스트 임베딩을 생성하고, 이를 마스크 임베딩과 비교하여 클래스 확률을 계산한다.
CLIP은 자연 이미지를 기반으로 학습되었기 떄문에 마스크된 이미지에서 성능 저하를 겪는다.
마스크된 이미지는 많은 빈 영역을 포함하기에 도메인 차이가 발생해 분류 성능이 저하됨 => 마스크 프롬프트 튜닝 사용
3.2. Collecting diverse mask-category pairs from captions(캡션에서 다양한 마스크-카테고리 쌍 수집)
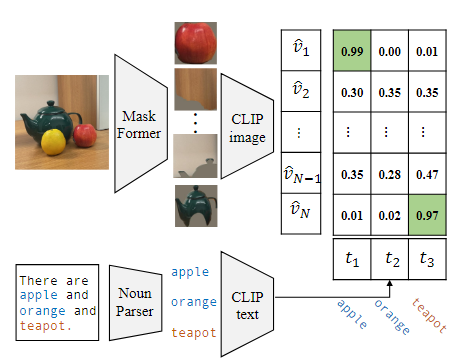
CLIP모델을 마스크된 이미지로 적응시키기 위해, 우리는 기존의 고정된 카테고리 주석 레이블을 사용하는 대신, 캡션에서 명사를 추출하여 더 다양한 마스크-카테고리 쌍을 생성하였다.
기존 접근법의 한계
COCO-Stuff와 같은 데이터셋은 수동으로 주석 처리된 고정된 세그먼트 레이블을 제공한다.
이러한 데이터셋은 정확하지만, 학습 가능한 카테고리 수가 제한적이며, 새로운 카테고리에 대한 일반화 성능이 부족하다.
캡션 기반 데이터 수집의 장점
이미지 캡션은 더 많은 어휘와 다양한 텍스트 표현을 포함하며, 새로운 카테고리를 학습할 기회를 제공한다.
위 그림에 표시된 캡션 "There are apple, orange, and teapot"은 COCO-Stuff에는 없는 "teapot"이라는 카테고리를 제공한다.
따라서 우리는 이미지 캡션에서 명사를 추출하여 새로운 마스크-카테고리 쌍을 생성했다.
데이터 수집 과정
-
마스크 생성 : 사전 학습된 MaskFormer 모델을 사용하여 클래스에 구애받지 않는 마스크 제안을 생성했다. 각 마스크는 이미지에서 물체 영역을 나타낸다.
-
캡션에서 명사 추출 : 오프라인 언어 분석기를 사용해 이미지 캡션에서 모든 명사를 추출. 명사는 이미지에서 나타나는 객체를 나타내며, 마스크와 연결될 수 있다.
-
CLIP 기반 매칭 : CLIP 모델을 사용해 각 마스크 제안과 캡션의 명사 간 유사도를 계산했다. 각 명사에 대해 가장 높은 유사도를 가진 마스크를 선택하여 해당 마스크를 해당 명사와 연결했다.
COCO-Stuff 기반 학습은 약 960,000개의 마스크-카테코리 쌍을 사용하였지만 텍스트 다양성이 부족하여 새로운 클래스에 대한 일반화 성능이 저하되었다.
COCO Captions 기반 학습은 440,000개의 마스크-카테고리 쌍을 사용하였고 더 다양한 텍스트 표현과 카테고리를 포함하며, 성능이 향상되었다.
CLIP을 마스크된 이미지에 적응시키기 위해, 다양한 마스크-카테고리 쌍을 포함하는 데이터 셋을 생성한다.
기존 데이터의 한계
- 기존의 COCO-Stuff와 같은 데이터 셋은 고정된 클래스만 포함하고 있어 새로운 클래스에 일반화하기 어렵다
캡션 기반 데이터셋 생성
1.사전 학습된 MaskFormer를 사용하여 클래스에 구애받지 않는 마스크를 생성한다.
2. COCO Captions와 같은 텍스트 데이터셋에서 이미지 캡션을 사용해 명사를 추출한다.
3. CLIP을 사용해 마스크된 영역과 추출된 명사 간 유사도를 계산하고, 가장 유사한 마스크-카테고리 쌍을 연결한다.
3.3. Mask prompt tuning
마스크된 이미지는 빈 영역을 많이 포함하고 있어 CLIP 분류 성능을 저하시킨다. 이는 CLIP이 자연 이미지에서 학습되었기 때문에 마스크된 이미지에서 도메인 차이가 발생하기 때문이다.
이 섹션에서는 마스크된 이미지를 처리할 수 있도록 CLIP을 적용시키는 새로운 방법인 마스크 프롬프트 튜닝을 제안함
기존 문제점은 마스크된 이미지는 빈 영역이 많아 CLIP의 입력 이미지 분포와 차이를 발생시킨다.
마스킹된 이미지를 CLIP에 공급하면 이미지가 겹치지 않는 패치로 분할된 후 토큰화된다. 그러면 이러한 빈 영역은 0 토큰이 된다.
이러한 토큰은 유용한 정보를 포함하지 않을 뿐만 아니라 모델에 도메인 분포 변화를 가져와(이러한 토큰은 자연 이미지에는 존재하지 않으므로) 성능 저하를 유발한다.
이를 완화하기 위해 마스크 프롬프트 튜닝, 일명 시각적 프롬프트 튜닝이라는 기술을 제안한다.
마스크된 이미지를 CLIP에 입력할 때, 이미지는 텐서로 토큰화된다. 마스크된 이미지는 이진 마스크를 포함하며, 각 요소는 주어진 패치가 유지되었는지 아니면 마스킹되었는지를 나타난다.
오직 패치 내 모든 픽셀이 완전히 마스킹되었을 때만, 해당 패치가 마스크된 토큰으로 간주된다.
이미지 텐서화 : 이미지를 CLIP 모델에 입력하려면, 먼저 이미지를 작은 패치(patch)로 나누고, 이 패치들을 수치 데이터(텐서)로 변환
토큰화 : 각 패치는 하나의 "토큰"으로 간주됩니다. 이 토큰은 패치의 시각적 정보를 CLIP의 임베딩 공간에서 학습 가능한 형식으로 변환한 값
마스크된 이미지는 이진 마스크를 포함한다 : 마스킹 처리를 할 때, 각 패치가 유지되었는지 또는 마스킹되었는지를 나타내는 0과 1로 구성된 이진 마스크를 사용한다.
전체를 완전히 미세 조정하는 방식과 비교하여, 마스크 프롬프트 튜닝은 몇 가지 장점이 있다.
1. 입력 이미지의 일부가 마스킹되는 세그멘테이션 작업에 특별히 설계되었다.
2. 전체 모델을 미세 조정하는 것과 비교하여, 마스크 프롬프트 튜닝에서 학습 가능한 파라미터의 수는 매우 적기 때문에 훈련 효율성이 크게 향상된다.
3. CLIP은 기본적인 모델로서 여러 작업에 동시에 사용될 수 있으며, CLIP의 가중치를 조정하는 것이 허용되지 않을 수도 있다. 마스크 프롬프트 튜닝은 CLIP의 가중치를 변경하지 않아도 되기 때문에 멀티 태크크에 적합
4. 전체 모델 미세 조정과 함께 적용되었을 때, 오픈 보카뷸러리 세그멘테이션 성능을 더욱 향상시킬 수 있다.
마스크된 이미지에서의 문제는 많은 빈 영역을 포함하여 자연 이미지에서 학습된 CLIP모델과의 도메인 차이를 발생시킨다는 것이다.
빈 영역을 단순히 제로 토큰으로 처리하지 않고, 학습 가능한 프롬프트 토큰으로 대체하여 마스크된 이미지의 빈 영역에 학습 가능한 프롬프트 토큰을 추가하여 도메인 차이를 완화한다.
이러한 프롬프트 토큰은 CLIP의 기존 가중치를 변경하지 않으면서 모델의 성능을 향상시킨다.
결론
1. 두 단계 구조 : 마스크 생성과 마스크 분류를 분리하여 효율성 높임
2. 다양한 데이터셋 생성 : 기존 고정 클래스의 한계를 넘어서는 데이터셋 구축
3. 마스크 프롬프트 튜닝 : CLIP의 도메인 차이를 줄이고 성능을 최적화하는 효율적인 기법이 방법들은 모델이 새로운 카테고리에 더 잘 인반화할 수 있도록 돕고, 오픈 보카뷸러리 세그멘테이션의 성능을 향상시킨다.
4. Experiment
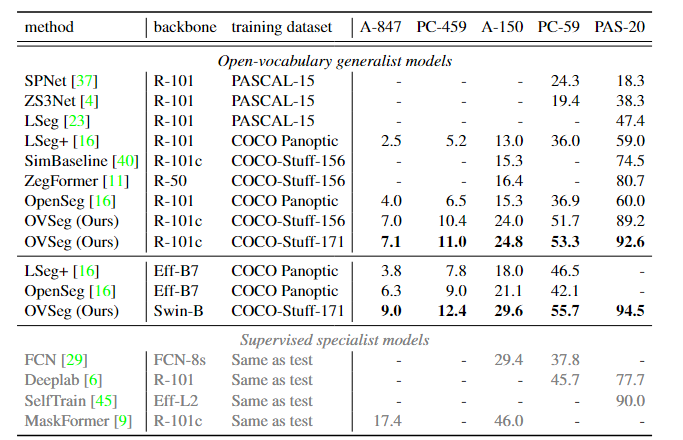
-
ADE-150 (150개의 클래스):
OVSeg는 29.6%의 mIoU를 달성, 기존 최고 모델(OpenSeg)보다 +8.5% 높은 성능을 보임. -
PC-459 (459개의 클래스):
OVSeg는 12.4%의 mIoU를 기록, 기존 최고 성능 대비 +3.4% 개선. -
A-847 (847개의 클래스):
9.0% mIoU를 달성하며, 복잡한 데이터셋에서도 강력한 성능을 입증.
