

이미지/사운드 데이터들을 매칭시키는 해커톤 아이디어 부문 지원 프로젝트입니다.
- 해커톤이미지/사운드 매칭프로젝트 (1) 글에 이은 음성 분류 모델 코드리뷰 글입니다.🐤🐤🐤
음성데이터 분류 모델 코드 리뷰
- 생활/가전 카테고리
1.원본 음성 데이터 Dataframe화
import librosa
import pandas as pd
import numpy as np
def separate_features(audio, sample_rate, file_name):
wnd_size = 2048
wnd_stride = 512
hop_length = 2048
chroma_stft = librosa.feature.chroma_stft(
y=audio, sr=sample_rate,
n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_size
).flatten()
rmse = librosa.feature.rms(
y=audio, frame_length=wnd_size, hop_length=wnd_size
).flatten()
spec_cent = librosa.feature.spectral_centroid(
y=audio, sr=sample_rate, n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_stride
).flatten()
spec_bw = librosa.feature.spectral_bandwidth(
y=audio, sr=sample_rate, n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_stride
).flatten()
rolloff = librosa.feature.spectral_rolloff(
y=audio + 0.01, sr=sample_rate,n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_stride
).flatten()
zcr = librosa.feature.zero_crossing_rate(
y=audio, frame_length=wnd_size, hop_length=wnd_stride
).flatten()
harmony = librosa.feature.tempogram(
y=audio, win_length=wnd_size, hop_length=wnd_stride
).flatten()
mfcc = librosa.feature.mfcc(
y=audio, sr=sample_rate, win_length=2,
hop_length=hop_length
)
df_one_sample = pd.DataFrame({'chroma_stft.mean':np.mean(chroma_stft, axis=0),
'chroma_stft.var':np.var(chroma_stft, axis=0),
'rmse.mean':np.mean(rmse, axis=0),
'rmse.var':np.var(spec_cent, axis=0),
'spec_cent.mean':np.mean(spec_cent, axis=0),
'spec_cent.var':np.var(spec_cent, axis=0),
'spec_bw.mean':np.mean(spec_bw, axis=0),
'spec_bw.var':np.var(spec_bw, axis=0),
'rolloff.mean':np.mean(rolloff, axis=0),
'rolloff.var':np.var(rolloff, axis=0),
'zcr.mean':np.mean(zcr, axis=0),
'zcr.var':np.var(zcr, axis=0),
'harmony.mean':np.mean(harmony, axis=0),
'harmony.var':np.var(harmony, axis=0)},index=[file_name])
for i in range(len(np.mean(mfcc.T, axis=0))):
df_one_sample['mfcc.mean'+str(i+1)] = np.mean(mfcc.T, axis=0)[i]
df_one_sample['mfcc.var'+str(i+1)] = np.var(mfcc.T, axis=0)[i]
df_one_sample['label'] = file_name.split('_')[0]+'_'+file_name.split('_')[1]
return df_one_sampleimport glob
import os
life_home_appliances = ['냉장고 사용', '드라이어 사용', '선풍기 사용', '안마하기', '안마하기(전동)', '압력밥솥 사용', '에어컨 사용',
'전자레인지 사용', '주전자 사용', '청소하기', '캐리어 사용', '키보드 치기','믹서기 갈기', '커피 내리기', '커피콩 갈기',
'커피콩 볶기', '면도하기(전동)', '면도하기', '이발하기', '세탁기']
for i in range(len(life_home_appliances)):
directory_name = '해커톤/사운드/원천데이터/'+life_home_appliances[i]+'/*.wav'
file_lists = [f for f in glob.glob(directory_name)]
# print(file_lists)
result = []
for file_path in file_lists:
audio, sample_rate = librosa.load(file_path)
file_name = os.path.basename(file_path)
print(file_name)
result.append(separate_features(audio, sample_rate, file_name))
test = pd.concat(result)# result = [df1,df2,df3.....]
test.to_csv(life_home_appliances[i]+'.csv',mode='w',encoding='cp949')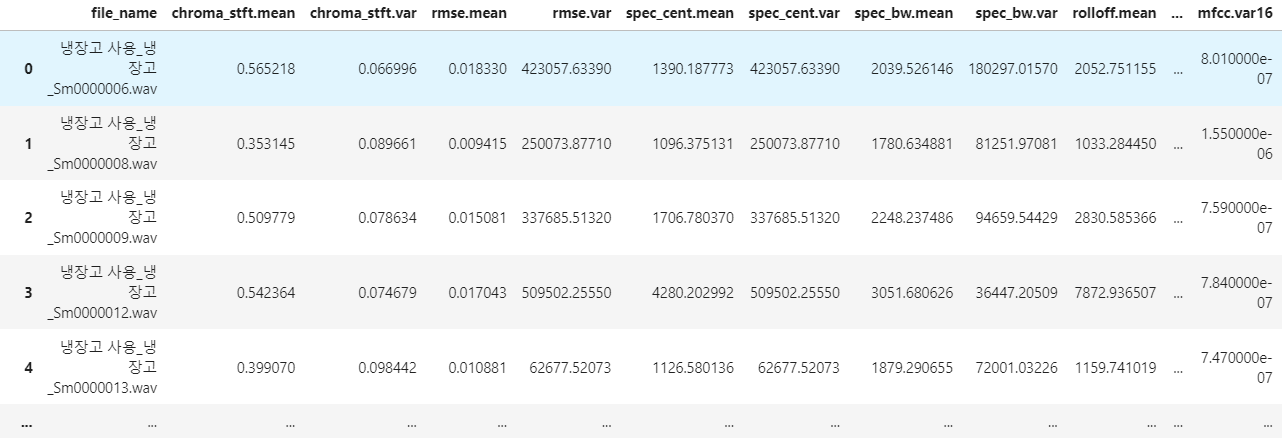
- 3가지 머신러닝 학습/저장
# 폴더명으로 클래스 통합한 df (클래스 세분화 X)
import pandas as pd
df = pd.read_csv('Life_Appliances_Folder_Classes.csv',encoding='cp949')
df
import dataframe_image as dfi
df_sample = df.sample(5)
df_sample_5 = df_sample[['file_name','label']]
dfi.export(df_sample_5,'df_sample_5_hangul.jpg')
df_sample_5
df['label'].value_counts()
# 레이블 인코딩
def get_preprocessing_df(df):
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
df_file_name = df['file_name'] # 파일명 따로 저장
df = df.drop(columns='file_name') # 파일명 제거
df_old = df
df_new = df
# 레이블 인코딩
encoder = LabelEncoder()
items = df_old['label']
encoder.fit(items)
labels_endcoded = encoder.transform(items)
df_labels_encoded = pd.DataFrame(data=labels_endcoded,columns=['label'])
df_new['label'] = df_labels_encoded
# 스케일러 생략
# 정규화스케일링
# 원본데이터가 균등하면 MinmaxScaler
# 원본데이터가 균등하지않으면 StandardScaler
# columns_list = list(df_old.columns)
# columns_list.remove('label')
# scaler = StandardScaler()
# items = df_old.drop(columns='label')
# scaler.fit(items)
# features_scaled = scaler.transform(items)
# df_features_scaled = pd.DataFrame(data=features_scaled,columns=columns_list)
# df_new_label = pd.DataFrame(df_new['label'])
# df_new = pd.concat([df_features_scaled,df_new_label],axis=1)
return df_new
df = get_preprocessing_df(df)# Encoding 적용된 df
df_sample_5 = df.loc[[215,24,12,201,578]]
df_sample_5 = df_sample_5[['chroma_stft.mean','label']]
dfi.export(df_sample_5,'df_sample_5_hangul_encoding.jpg')
df_sample_5[['chroma_stft.mean','label']]
# 데이터 split
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import plot_importance
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
def get_dataset_df(df_voice):
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=156,stratify=y)
return X_train,X_test,y_train,y_test
X_train,X_test,y_train,y_test = get_dataset_df(df)
X_test.to_csv('original_X_test.csv')
# 3가지 머신러닝 모델 정의
def get_clf_models():
# 가장 성능 좋은 파라미터 3가지 선택
list_models = []
xgb_wrapper = XGBClassifier(n_estimators=100,learning_rate=0.3)
list_models.append(xgb_wrapper)
lgbm_wrapper = LGBMClassifier(n_estimators=300,colsample_bytree=0.75,max_depth=4,min_child_weight=1,learning_rate=0.1)
list_models.append(lgbm_wrapper)
rf_clf = RandomForestClassifier(n_estimators=1200,random_state=156,n_jobs=-1)
list_models.append(rf_clf)
return list_models
list_models = get_clf_models()# 모델 학습
def get_clf_predict(list_models):
list_pred = []
list_pred_proba = []
for i in range(len(list_models)):
print(f"{list_models[i].__class__}")
list_models[i].fit(X_train,y_train)
pred= list_models[i].predict(X_test)
list_pred.append(pred)
pred_proba = list_models[i].predict_proba(X_test)[:,:20] # 클래스 20개 , 0~19
list_pred_proba.append(pred_proba)
return list_pred,list_pred_proba
list_pred,list_pred_proba = get_clf_predict(list_models)# 모델 평가
def get_clf_eval(y_test,list_pred,list_pred_proba,list_models):
from sklearn.metrics import accuracy_score,precision_score
from sklearn.metrics import recall_score,confusion_matrix
from sklearn.metrics import f1_score,roc_auc_score
import time
list_confusion = []
list_accuray = []
list_precision = []
list_recall = []
list_f1 = []
list_roc_auc = []
df_evaluation = pd.DataFrame(columns=['accuracy','precision','recall','f1_score']) # ,'ROC_AUC'
for i in range(len(list_pred)):
print(f"{str(list_models[i]).split('(')[0]}")
start = time.time()
# 혼동행렬(오차행렬),정확도, 정밀도, 재현율,f1 (roc_auc 제외)
confusion = confusion_matrix(y_test,list_pred[i]) # 혼동행렬
list_confusion.append(confusion)
accuracy = accuracy_score(y_test,list_pred[i]) # 정확도
list_accuray.append(accuracy)
precision = precision_score(y_test,list_pred[i], average='micro') # 이진분류시 => 정밀도 ,pos_label=1
list_precision.append(precision)
recall = recall_score(y_test,list_pred[i], average='micro') # 이진분류시 => 재현율 ,pos_label=1
f1 = f1_score(y_test,list_pred[i],average='micro')# 이진분류시 => pos_label=1
list_f1.append(f1)
end = time.time()
df_evaluation = df_evaluation.append({'accuracy':accuracy,'precision':precision,'recall':recall,'f1_score':f1},ignore_index=True) #'ROC_AUC':roc_auc},
print(f"{list_models[i].__class__}")
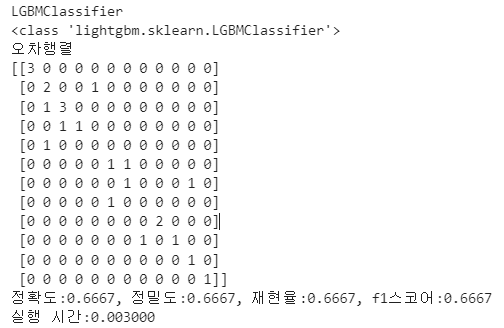
print('오차행렬')
print(confusion)
print(f'정확도:{accuracy:.4f}, 정밀도:{precision:.4f}, 재현율:{recall:.4f}, f1스코어:{f1:.4f}') # :.4f 소수 4자리까지 , roc_auc:{roc_auc:.4f}'
print(f'실행 시간:{end-start:.6f}')
print("\n")
df_evaluation = df_evaluation.set_axis([str(list_models[i]).split('(')[0] for i in range(len(list_models))], axis='index')
return df_evaluation
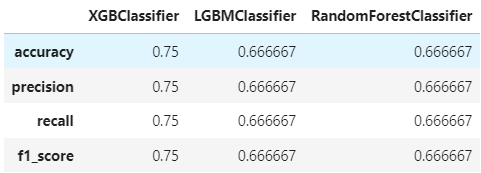
df_evaluation = get_clf_eval(y_test,list_pred,list_pred_proba,list_models)
df_evaluation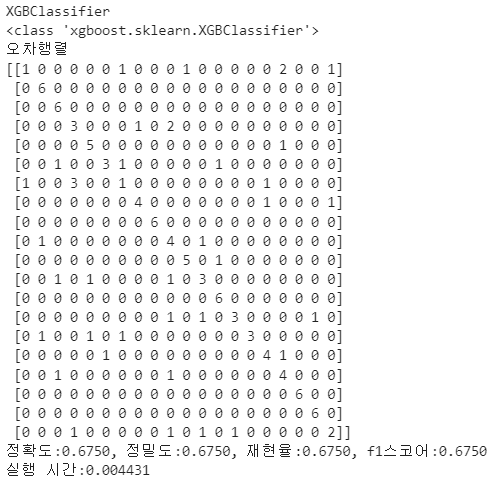



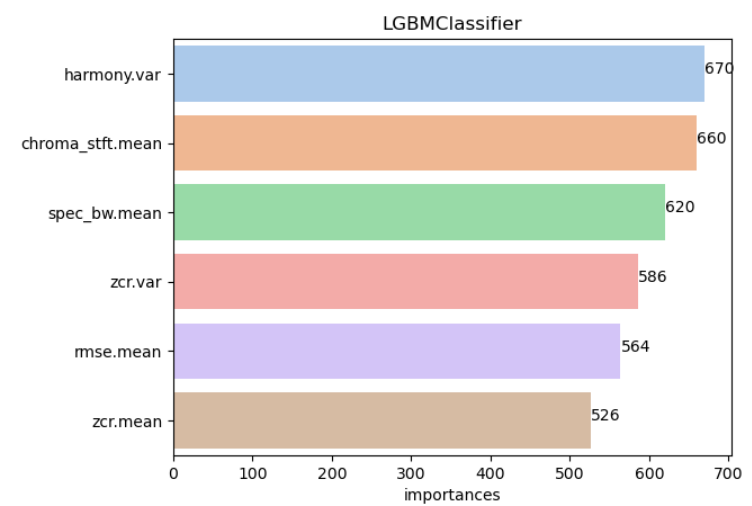
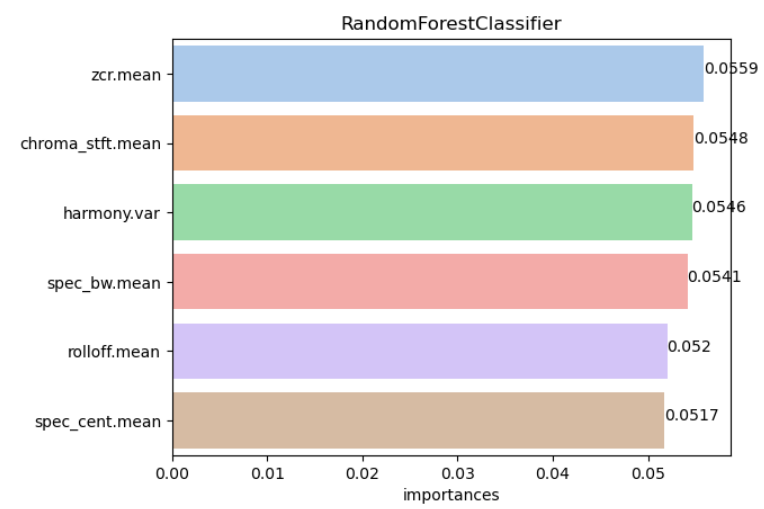
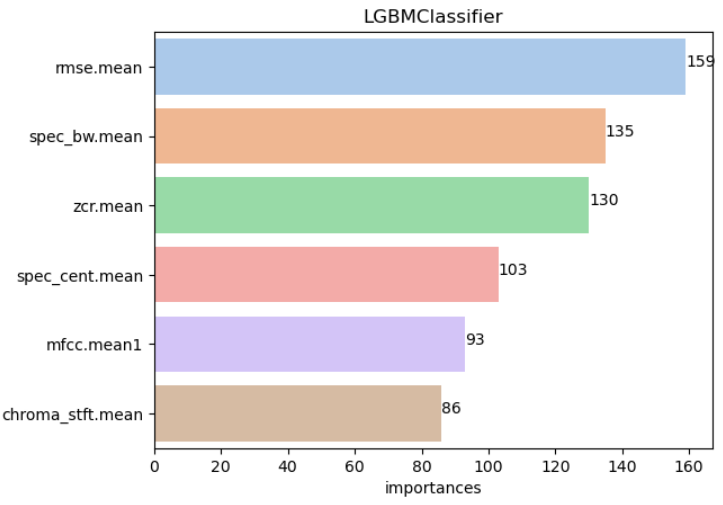
# 모델별 Feature_Importances 시각화
def get_feature_importances(list_models,X_train):
import matplotlib.pyplot as plt
import seaborn as sns
for i in range(len(list_models)):
features_importance_values = list_models[i].feature_importances_
features_importance_df = pd.DataFrame(features_importance_values,index=X_train.columns)
features_importance_df = features_importance_df.rename(columns={0:'importances'})
features_importance_df = features_importance_df.sort_values('importances',ascending=False)
sns.set_palette("pastel")
g = sns.barplot(x=features_importance_df['importances'][:6],y=features_importance_df.index[:6],ci=None)
g.set_title(str(list_models[i]).split('(')[0])
for i in range(len(features_importance_df.index[:6])):
g.text(x = np.round(features_importance_df['importances'][:6].values[i],4), y=i,s=np.round(features_importance_df['importances'][:6].values[i],4))
plt.show()
get_feature_importances(list_models,X_train) # 모델별로 importances 표현방식이 다르다
# 모델 저장하기
import pickle
for model in list_models:
with open('models_pickle_life_appliances/'+str(model).split('(')[0]+'.pickle','wb') as fw:
print(model)
pickle.dump(model, fw)# 모델 검증 결과
for i in range(len(list_models)):
correct_cnt = 0
for j in range(len(list_pred[0])):
if list_pred[i][j] == ans[j]:
correct_cnt +=1
print(f"{str(list_models[i]).split('(')[0]}는 {correct_cnt}/120개를 맞추었습니다.")
- 음성데이터 => 이미지데이터 매칭 (input : 랜덤 20개 음성데이터 )
import pandas as pd
df = pd.read_csv('Life_Appliances_Folder_Classes.csv',encoding='cp949')
life_appliances = list(set(df['label'].values))
print(len(life_appliances))
life_appliances
# 학습된 모델 불러오기
import pickle
list_models = ['XGBClassifier','LGBMClassifier','RandomForestClassifier']
# for i in range(len(list_models)):
# with open('models_pickle/'+list_models[i]+'.pickle', 'rb') as f:
# model = pickle.load(f)
# list_models[i] = model
for idx,i in enumerate(list_models):
name = 'models_pickle_life_appliances/'+i+'.pickle' # name = 'models_pickle/'+i+'.pickle'
print(name)
with open(name, 'rb') as f:
model = pickle.load(f)
list_models[idx] = model
import pandas as pd
df = pd.read_csv('Life_Appliances_Folder_Classes.csv',encoding='cp949')
# df_original = df.copy()
# df_original
for model in list_models:
print(model)
# 20개의 랜덤 음성데이터 선택
def get_test_sound():
# 생활/가전 랜덤 음성 출력
# 음성 클래스 분류
# 클래스에 맞는 이미지 출력
import random
import glob
list_test_sound_file = []
for i in range(len(life_appliances)):
rand_foler_num = random.randint(0,len(life_appliances)-1)
rand_pic_num = random.randint(0,29)
file_name = ''
print(f"rand_foler_num: {rand_foler_num}")
print(f"rand_pic_num: {rand_pic_num}")
directory_name = '해커톤/사운드/원천데이터/'+life_appliances[rand_foler_num]+'/*.wav'
file_lists = [f for f in glob.glob(directory_name)]
file_name = file_lists[rand_pic_num]
list_test_sound_file.append(file_name)
return list_test_sound_file
list_test_sound_file = get_test_sound()# 선택된 20개의 음성데이터 dataframe화
def get_test_sound_file_to_data(test_sound_file):
import librosa
import numpy as np
X_test = pd.DataFrame()
y_test = pd.DataFrame()
for test_sound_file in list_test_sound_file:
audio, sample_rate = librosa.load(test_sound_file)
wnd_size = 2048
wnd_stride = 512
hop_length = 2048
chroma_stft = librosa.feature.chroma_stft(
y=audio, sr=sample_rate,
n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_size
).flatten()
rmse = librosa.feature.rms(
y=audio, frame_length=wnd_size, hop_length=wnd_size
).flatten()
spec_cent = librosa.feature.spectral_centroid(
y=audio, sr=sample_rate, n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_stride
).flatten()
spec_bw = librosa.feature.spectral_bandwidth(
y=audio, sr=sample_rate, n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_stride
).flatten()
rolloff = librosa.feature.spectral_rolloff(
y=audio + 0.01, sr=sample_rate,n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_stride
).flatten()
zcr = librosa.feature.zero_crossing_rate(
y=audio, frame_length=wnd_size, hop_length=wnd_stride
).flatten()
harmony = librosa.feature.tempogram(
y=audio, win_length=wnd_size, hop_length=wnd_stride
).flatten()
mfcc = librosa.feature.mfcc(
y=audio, sr=sample_rate, win_length=2,
hop_length=hop_length
)
df_test = pd.DataFrame({'chroma_stft.mean':np.mean(chroma_stft, axis=0),
'chroma_stft.var':np.var(chroma_stft, axis=0),
'rmse.mean':np.mean(rmse, axis=0),
'rmse.var':np.var(spec_cent, axis=0),
'spec_cent.mean':np.mean(spec_cent, axis=0),
'spec_cent.var':np.var(spec_cent, axis=0),
'spec_bw.mean':np.mean(spec_bw, axis=0),
'spec_bw.var':np.var(spec_bw, axis=0),
'rolloff.mean':np.mean(rolloff, axis=0),
'rolloff.var':np.var(rolloff, axis=0),
'zcr.mean':np.mean(zcr, axis=0),
'zcr.var':np.var(zcr, axis=0),
'harmony.mean':np.mean(harmony, axis=0),
'harmony.var':np.var(harmony, axis=0)},index=[test_sound_file])
for i in range(len(np.mean(mfcc.T, axis=0))):
df_test['mfcc.mean'+str(i+1)] = np.mean(mfcc.T, axis=0)[i]
df_test['mfcc.var'+str(i+1)] = np.var(mfcc.T, axis=0)[i]
df_test['label'] = test_sound_file.split('/')[3] # 폴더명으로 통합
df_test = df_test.reset_index()
df_test = df_test.drop(columns=['index'])
X_one_test = df_test.iloc[:,:-1]
y_one_test = df_test['label']
encoding_dict ={'냉장고 사용': 0,
'드라이어 사용': 1,
'면도하기': 2,
'면도하기(전동)': 3,
'믹서기 갈기': 4,
'선풍기 사용': 5,
'세탁기': 6,
'안마하기': 7,
'안마하기(전동)': 8,
'압력밥솥 사용': 9,
'에어컨 사용': 10,
'이발하기': 11,
'전자레인지 사용': 12,
'주전자 사용': 13,
'청소하기': 14,
'캐리어 사용': 15,
'커피 내리기': 16,
'커피콩 갈기': 17,
'커피콩 볶기': 18,
'키보드 치기': 19}
y_one_test.values[0] = y_one_test.values[0].split('\\')[0]
print(y_one_test.values[0])
for i in range(len(encoding_dict)):
if list(encoding_dict.keys())[i] == y_one_test.values[0]:
y_one_test.values[0] = str(encoding_dict[list(encoding_dict.keys())[i]])
y_one_test = y_one_test.astype(int)
X_test = X_test.append(X_one_test)
y_test = y_test.append(y_one_test)
return X_test,y_test
# test_sound_file = '해커톤/사운드/원천데이터/선풍기 사용\선풍기 사용_공업용 선풍기_Sm0000047.wav' # 직업 음성파일 선택하기
X_test,y_test = get_test_sound_file_to_data(list_test_sound_file)
X_test
# 모델에 넣어 검증
def get_clf_predict(list_models):
list_pred = []
list_pred_proba = []
for i in range(len(list_models)):
print(f"{list_models[i].__class__}")
pred= list_models[i].predict(X_test)
list_pred.append(pred)
pred_proba = list_models[i].predict_proba(X_test)[:,:21]
list_pred_proba.append(pred_proba)
return list_pred,list_pred_proba
list_pred,list_pred_proba = get_clf_predict(list_models) # 평가
def get_clf_eval(y_test,list_pred,list_pred_proba,list_models):
from sklearn.metrics import accuracy_score,precision_score
from sklearn.metrics import recall_score,confusion_matrix
from sklearn.metrics import f1_score,roc_auc_score
import time
list_confusion = []
list_accuray = []
list_precision = []
list_recall = []
list_f1 = []
list_roc_auc = []
df_evaluation = pd.DataFrame(columns=['accuracy','precision','recall','f1_score']) # ,'ROC_AUC'
for i in range(len(list_pred)):
print(f"{str(list_models[i]).split('(')[0]}")
start = time.time()
# 혼동행렬(오차행렬),정확도, 정밀도, 재현율,f1,roc_auc
confusion = confusion_matrix(y_test,list_pred[i]) # 혼동행렬
list_confusion.append(confusion)
accuracy = accuracy_score(y_test,list_pred[i]) # 정확도
list_accuray.append(accuracy)
precision = precision_score(y_test,list_pred[i], average='micro') # 이진분류시 => 정밀도 ,pos_label=1
list_precision.append(precision)
recall = recall_score(y_test,list_pred[i], average='micro') # 이진분류시 => 재현율 ,pos_label=1
list_recall.append(recall)
f1 = f1_score(y_test,list_pred[i],average='micro')# 이진분류시 => pos_label=1
list_f1.append(f1)
# roc_auc = roc_auc_score(y_test,list_pred_proba[i],multi_class='ovr',average="macro") # 다항분류 시 => multi_class='ovr'
# list_roc_auc.append(roc_auc)
end = time.time()
df_evaluation = df_evaluation.append({'accuracy':accuracy,'precision':precision,'recall':recall,'f1_score':f1},ignore_index=True) #'ROC_AUC':roc_auc},
print(f"{list_models[i].__class__}")
print('오차행렬')
print(confusion)
print(f'정확도:{accuracy:.4f}, 정밀도:{precision:.4f}, 재현율:{recall:.4f}, f1스코어:{f1:.4f}') # :.4f 소수 4자리까지 , roc_auc:{roc_auc:.4f}'
print(f'실행 시간:{end-start:.6f}')
print("\n")
df_evaluation = df_evaluation.set_axis([str(list_models[i]).split('(')[0] for i in range(len(list_models))], axis='index')
return df_evaluation
df_evaluation = get_clf_eval(y_test,list_pred,list_pred_proba,list_models)


# 검증 결과 정확도 그래프 시각화
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
df_evaluation = df_evaluation.rename(index={'XGBClassifier':'XGB','LGBMClassifier':'LGBM','RandomForestClassifier':'RandomForest'})
plt.figure(figsize=(4,4))
plt.ylim(0.0,1.0)
# plt.xticks(rotation=45)
sns.set_palette("pastel")
g = sns.barplot(x=df_evaluation.index,y=df_evaluation['accuracy'],ci=None,errwidth=50)
for i in range(len(df_evaluation.index)):
print(i)
g.text(x = i, y=np.round(df_evaluation['accuracy'].values[i],4),s=np.round(df_evaluation['accuracy'].values[i],4),ha='center')
plt.savefig('Life_Appliances_Try_Matching_20_samples_Accuaracy.png')
plt.show()
# 모델이 예측한 클래스와 매칭되는 이미지 출력
def get_pred_pics(class_name):
import glob
import matplotlib.pyplot as plt
import random
directory_name = '해커톤/이미지/원천데이터/'+class_name+'/*.jpg'
file_lists = [f for f in glob.glob(directory_name)]
rand_pic_num = random.randint(0,len(file_lists)-1)
file_name = file_lists[rand_pic_num]
image = plt.imread(file_name)
plt.imshow(image)
plt.show()
import numpy as np
reverse_encoding_dict ={ 0: '냉장고 사용',
1: '드라이어 사용',
2: '면도하기',
3: '면도하기(전동)',
4: '믹서기 갈기',
5: '선풍기 사용',
6: '세탁기',
7: '안마하기',
8: '안마하기(전동)',
9: '압력밥솥 사용',
10: '에어컨 사용',
11: '이발하기',
12: '전자레인지 사용',
13: '주전자 사용',
14: '청소하기',
15: '캐리어 사용',
16: '커피 내리기',
17: '커피콩 갈기',
18: '커피콩 볶기',
19: '키보드 치기'}
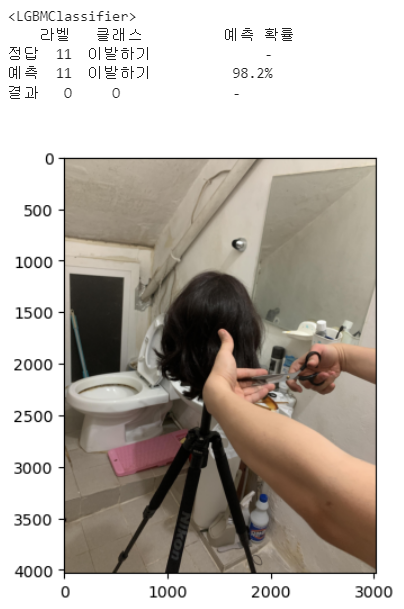
for i in range(len(list_test_sound_file)):
print(f'<{i+1}번째 문제>')
# print(f"정답 : Label = {y_test.values[i]},{reverse_encoding_dict[y_test.values[i][0]]}\n")
for j in range(len(list_models)):
print(f'<{list_models[j].__class__.__name__}>')
# print(np.round(list_pred_proba[j][i],3))
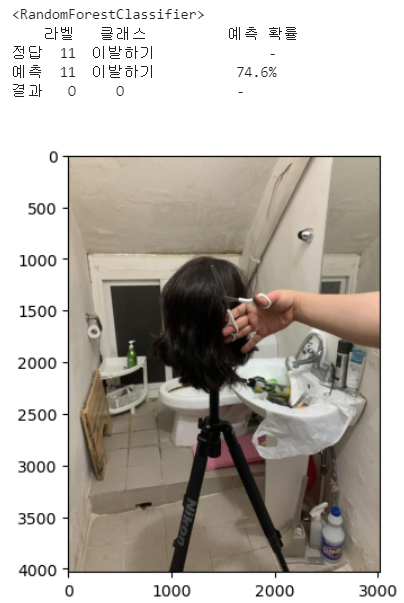
df_result = pd.DataFrame(columns=['라벨','클래스',' 예측 확률'],index=['정답','예측','결과'])
maxproba = np.round(list_pred_proba[j][i],3).max()
answer = np.where(np.round(list_pred_proba[j][i],3)==maxproba)
is_correct = ''
if y_test.values[i] == answer[0]:
is_correct = 'O'
else:
is_correct = 'X'
# print(f"{str(list_models[j].__class__.__name__)}이(가) 예측한 답: {answer[0]},{reverse_encoding_dict[answer[0][0]]},{is_correct}")
# maxproba = np.round(list_pred_proba[j][i],3).max()
# print(maxproba)
df_result.loc['정답','라벨'] = int(y_test.values[i][0])
df_result.loc['정답','클래스'] = reverse_encoding_dict[y_test.values[i][0]]
df_result.loc['정답',' 예측 확률'] = '-'
df_result.loc['예측','라벨'] = answer[0][0]
df_result.loc['예측','클래스'] = reverse_encoding_dict[answer[0][0]]
df_result.loc['예측',' 예측 확률'] = str(np.round(maxproba*100,3))+'%'
df_result.loc['결과','라벨'] = is_correct
df_result.loc['결과','클래스'] = is_correct
df_result.loc['결과',' 예측 확률'] = ' -'
print(df_result)
print('\n')
get_pred_pics(reverse_encoding_dict[answer[0][0]])



- 교통 카테고리
- 원본 음성 데이터 Dataframe화 (클래스 세분화)
# 차량 이상 감지 시스템이라는 주제에 맞게 차종별로 클래스 세분화
import librosa
import pandas as pd
import numpy as np
def separate_features(audio, sample_rate, file_name):
wnd_size = 2048
wnd_stride = 512
hop_length = 2048
chroma_stft = librosa.feature.chroma_stft(
y=audio, sr=sample_rate,
n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_size
).flatten()
rmse = librosa.feature.rms(
y=audio, frame_length=wnd_size, hop_length=wnd_size
).flatten()
spec_cent = librosa.feature.spectral_centroid(
y=audio, sr=sample_rate, n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_stride
).flatten()
spec_bw = librosa.feature.spectral_bandwidth(
y=audio, sr=sample_rate, n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_stride
).flatten()
rolloff = librosa.feature.spectral_rolloff(
y=audio + 0.01, sr=sample_rate,n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_stride
).flatten()
zcr = librosa.feature.zero_crossing_rate(
y=audio, frame_length=wnd_size, hop_length=wnd_stride
).flatten()
harmony = librosa.feature.tempogram(
y=audio, win_length=wnd_size, hop_length=wnd_stride
).flatten()
mfcc = librosa.feature.mfcc(
y=audio, sr=sample_rate, win_length=2,
hop_length=hop_length
)
df_one_sample = pd.DataFrame({'chroma_stft.mean':np.mean(chroma_stft, axis=0),
'chroma_stft.var':np.var(chroma_stft, axis=0),
'rmse.mean':np.mean(rmse, axis=0),
'rmse.var':np.var(spec_cent, axis=0),
'spec_cent.mean':np.mean(spec_cent, axis=0),
'spec_cent.var':np.var(spec_cent, axis=0),
'spec_bw.mean':np.mean(spec_bw, axis=0),
'spec_bw.var':np.var(spec_bw, axis=0),
'rolloff.mean':np.mean(rolloff, axis=0),
'rolloff.var':np.var(rolloff, axis=0),
'zcr.mean':np.mean(zcr, axis=0),
'zcr.var':np.var(zcr, axis=0),
'harmony.mean':np.mean(harmony, axis=0),
'harmony.var':np.var(harmony, axis=0)},index=[file_name])
for i in range(len(np.mean(mfcc.T, axis=0))):
df_one_sample['mfcc.mean'+str(i+1)] = np.mean(mfcc.T, axis=0)[i]
df_one_sample['mfcc.var'+str(i+1)] = np.var(mfcc.T, axis=0)[i]
df_one_sample['label'] = file_name.split('_')[0]+'_'+file_name.split('_')[1]
return df_one_sampleimport glob
import os
traffic = ['차량 공회전','차량 주행','선박 운항','경고음']
for i in range(len(traffic)):
directory_name = '해커톤/사운드/원천데이터/'+traffic[i]+'/*.wav'
file_lists = [f for f in glob.glob(directory_name)]
# print(file_lists)
result = []
for file_path in file_lists:
audio, sample_rate = librosa.load(file_path)
file_name = os.path.basename(file_path)
print(file_name)
result.append(separate_features(audio, sample_rate, file_name))
test = pd.concat(result)# result = [df1,df2,df3.....]
test.to_csv(traffic[i]+'.csv',mode='w',encoding='cp949')
# 클래스 세분화된 dataframe
traffic = ['차량 공회전','차량 주행','선박 운항','경고음']
df_cat_rotation = pd.read_csv('차량 공회전.csv',encoding='cp949')
print(df_cat_rotation.index)
df_cat_run = pd.read_csv('차량 주행.csv',encoding='cp949')
df_cat_rotation = df_cat_rotation.append(df_cat_run)
print(df_cat_rotation.index)
df_ship_run = pd.read_csv('선박 운항.csv',encoding='cp949')
df_cat_rotation = df_cat_rotation.append(df_ship_run)
print(df_cat_rotation.index)
df_siren = pd.read_csv('경고음.csv',encoding='cp949')
df_cat_rotation = df_cat_rotation.append(df_siren)
print(df_cat_rotation.index)
df_cat_rotation = df_cat_rotation.reset_index()
df_cat_rotation = df_cat_rotation.rename(columns={'Unnamed: 0':'file_name'})
df_cat_rotation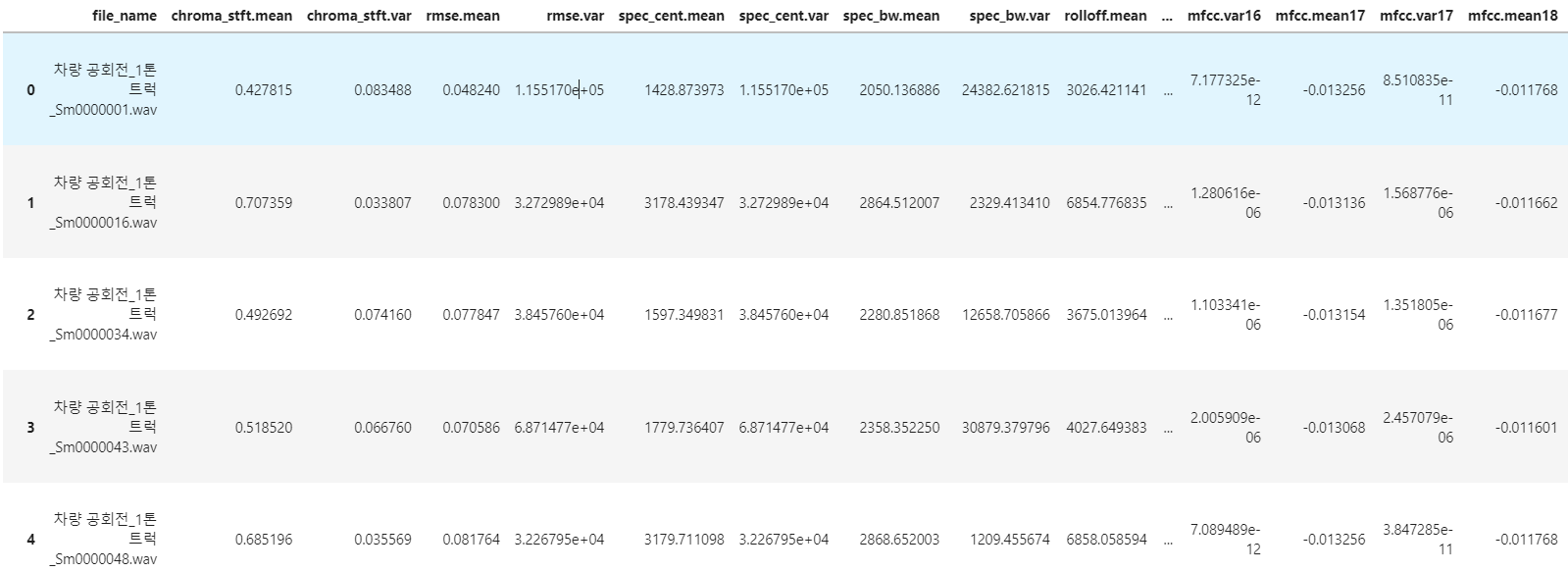
# 학습할 데이터 저장
df_cat_rotation.to_csv('Traffic_Detailed_Classes.csv',encoding='cp949')- 3가지 머신러닝 학습/저장
# 클래스 세분화한 df
import pandas as pd
df = pd.read_csv('Traffic_Detailed_Classes.csv',encoding='cp949')
df
df['label'].value_counts()
# 레이블 인코딩
def get_preprocessing_df(df):
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
df_file_name = df['file_name'] # 파일명 따로 저장
df = df.drop(columns='file_name') # 파일명 제거
df_old = df
df_new = df
# 레이블 인코딩
encoder = LabelEncoder()
items = df_old['label']
encoder.fit(items)
labels_endcoded = encoder.transform(items)
df_labels_encoded = pd.DataFrame(data=labels_endcoded,columns=['label'])
df_new['label'] = df_labels_encoded
# 스케일러 생략
# 정규화스케일링
# 원본데이터가 균등하면 MinmaxScaler
# 원본데이터가 균등하지않으면 StandardScaler
# columns_list = list(df_old.columns)
# columns_list.remove('label')
# scaler = StandardScaler()
# items = df_old.drop(columns='label')
# scaler.fit(items)
# features_scaled = scaler.transform(items)
# df_features_scaled = pd.DataFrame(data=features_scaled,columns=columns_list)
# df_new_label = pd.DataFrame(df_new['label'])
# df_new = pd.concat([df_features_scaled,df_new_label],axis=1)
return df_new
df = get_preprocessing_df(df)
df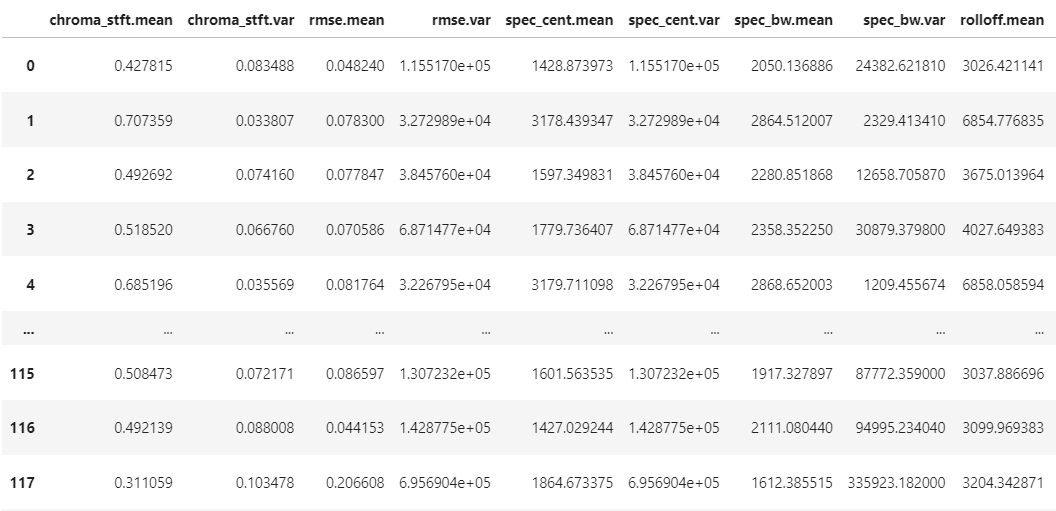
# 데이터 split
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import plot_importance
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
def get_dataset_df(df_voice):
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=156,stratify=y)
return X_train,X_test,y_train,y_test
X_train,X_test,y_train,y_test = get_dataset_df(df)
X_test.to_csv('original_X_test.csv')# 3가지 머신러닝 모델 정의
def get_clf_models():
# 가장 성능 좋은 파라미터 3가지 선택
list_models = []
xgb_wrapper = XGBClassifier(n_estimators=100,colsample_bytree=0.25,max_depth=3,min_child_weight=1,learning_rate=0.3)
list_models.append(xgb_wrapper)
lgbm_wrapper = LGBMClassifier(n_estimators=300,colsample_bytree=0.25,max_depth=2,min_child_weight=1,learning_rate=0.1)
list_models.append(lgbm_wrapper)
rf_clf = RandomForestClassifier(n_estimators=1000,
max_depth=8,
min_samples_leaf=1,
min_samples_split=2,
random_state=156,n_jobs=-1)
list_models.append(rf_clf)
return list_models
list_models = get_clf_models()# 모델 학습
def get_clf_predict(list_models):
list_pred = []
list_pred_proba = []
for i in range(len(list_models)):
print(f"{list_models[i].__class__}")
list_models[i].fit(X_train,y_train)
pred= list_models[i].predict(X_test)
list_pred.append(pred)
pred_proba = list_models[i].predict_proba(X_test)[:,:20] # 클래스 20개 , 0~19
list_pred_proba.append(pred_proba)
return list_pred,list_pred_proba
list_pred,list_pred_proba = get_clf_predict(list_models)# 모델 평가
def get_clf_eval(y_test,list_pred,list_pred_proba,list_models):
from sklearn.metrics import accuracy_score,precision_score
from sklearn.metrics import recall_score,confusion_matrix
from sklearn.metrics import f1_score,roc_auc_score
import time
df_evaluation = get_clf_eval(y_test,list_pred,list_pred_proba,list_models)
list_confusion = []
list_accuray = []
list_precision = []
list_recall = []
list_f1 = []
list_roc_auc = []
df_evaluation = pd.DataFrame(columns=['accuracy','precision','recall','f1_score']) # ,'ROC_AUC'
for i in range(len(list_pred)):
print(f"{str(list_models[i]).split('(')[0]}")
start = time.time()
# 혼동행렬(오차행렬),정확도, 정밀도, 재현율,f1,roc_auc
confusion = confusion_matrix(y_test,list_pred[i]) # 혼동행렬
list_confusion.append(confusion)
accuracy = accuracy_score(y_test,list_pred[i]) # 정확도
list_accuray.append(accuracy)
precision = precision_score(y_test,list_pred[i], average='micro') # 이진분류시 => 정밀도 ,pos_label=1
list_precision.append(precision)
recall = recall_score(y_test,list_pred[i], average='micro') # 이진분류시 => 재현율 ,pos_label=1
f1 = f1_score(y_test,list_pred[i],average='micro')# 이진분류시 => pos_label=1
list_f1.append(f1)
# roc_auc = roc_auc_score(y_test,list_pred_proba[i],multi_class='ovr') # 다항분류 시 => multi_class='ovr'
# list_roc_auc.append(roc_auc)
end = time.time()
df_evaluation = df_evaluation.append({'accuracy':accuracy,'precision':precision,'recall':recall,'f1_score':f1},ignore_index=True) #'ROC_AUC':roc_auc},
print(f"{list_models[i].__class__}")
print('오차행렬')
print(confusion)
print(f'정확도:{accuracy:.4f}, 정밀도:{precision:.4f}, 재현율:{recall:.4f}, f1스코어:{f1:.4f}') # :.4f 소수 4자리까지 , roc_auc:{roc_auc:.4f}'
print(f'실행 시간:{end-start:.6f}')
print("\n")
df_evaluation = df_evaluation.set_axis([str(list_models[i]).split('(')[0] for i in range(len(list_models))], axis='index')
return df_evaluation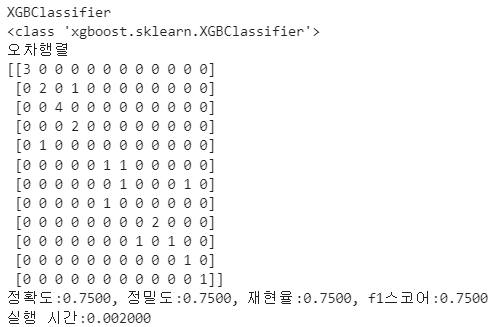

# 모델별 Features_Importances 시각화
def get_feature_importances(list_models,X_train):
import matplotlib.pyplot as plt
import seaborn as sns
for i in range(len(list_models)):
features_importance_values = list_models[i].feature_importances_
features_importance_df = pd.DataFrame(features_importance_values,index=X_train.columns)
features_importance_df = features_importance_df.rename(columns={0:'importances'})
features_importance_df = features_importance_df.sort_values('importances',ascending=False)
sns.set_palette("pastel")
g = sns.barplot(x=features_importance_df['importances'][:6],y=features_importance_df.index[:6],ci=None)
g.set_title(str(list_models[i]).split('(')[0])
for i in range(len(features_importance_df.index[:6])):
g.text(x = np.round(features_importance_df['importances'][:6].values[i],4), y=i,s=np.round(features_importance_df['importances'][:6].values[i],4))
plt.show()
get_feature_importances(list_models,X_train) # 모델별로 importances 표현방식이 다르다(?)

# 모델 저장하기
import pickle
for model in list_models:
with open('models_pickle_traffic/'+str(model).split('(')[0]+'.pickle','wb') as fw:
pickle.dump(model, fw)# 모델 검증 결과
for i in range(len(list_models)):
correct_cnt = 0
for j in range(len(list_pred[0])):
if list_pred[i][j] == ans[j]:
correct_cnt +=1
print(f"{str(list_models[i]).split('(')[0]}는 {correct_cnt}/24개를 맞추었습니다.")
- 음성데이터 => 이미지데이터 매칭 (input : 랜덤 20개 음성데이터 )
import pandas as pd
df = pd.read_csv('Traffic_Detailed_Classes.csv',encoding='cp949')
traffic_detail_classes = list(set(df['label'].values))
print(len(traffic_detail_classes))
traffic_detail_classes
traffic_folder_classes = []
for traffic_detail_class in traffic_detail_classes:
traffic_folder_classes.append(traffic_detail_class.split('_')[0])
traffic_folder_classes = set(traffic_folder_classes)
traffic_folder_classes = list(traffic_folder_classes)
traffic_folder_classes
# 학습된 모델 불러오기
import pickle
list_models = ['XGBClassifier','LGBMClassifier','RandomForestClassifier']
# for i in range(len(list_models)):
# with open('models_pickle/'+list_models[i]+'.pickle', 'rb') as f:
# model = pickle.load(f)
# list_models[i] = model
for idx,i in enumerate(list_models):
name = 'models_pickle_traffic/'+i+'.pickle' # name = 'models_pickle/'+i+'.pickle'
print(name)
with open(name, 'rb') as f:
model = pickle.load(f)
list_models[idx] = model
import pandas as pd
df = pd.read_csv('Traffic_Detailed_Classes.csv',encoding='cp949')
# df_original = df.copy()
# df_original
for model in list_models:
print(model)
# 랜덤 20개의 음성데이터 선택
def get_test_sound():
# 생활/가전 랜덤 음성 출력
# 음성 클래스 분류
# 클래스에 맞는 이미지 출력
import random
import glob
# traffic_folder_classes
# traffic_detail_classes
list_test_sound_file = []
for i in range(20):
rand_foler_num = random.randint(0,len(traffic_folder_classes)-1)
rand_pic_num = random.randint(0,29)
file_name = ''
print(f"rand_foler_num: {rand_foler_num}")
print(f"rand_pic_num: {rand_pic_num}")
directory_name = '해커톤/사운드/원천데이터/'+traffic_folder_classes[rand_foler_num]+'/*.wav'
file_lists = [f for f in glob.glob(directory_name)]
file_name = file_lists[rand_pic_num]
list_test_sound_file.append(file_name)
return list_test_sound_file
list_test_sound_file = get_test_sound()# 랜덤 20개의 음성데이터 dataframe화
def get_test_sound_file_to_data(test_sound_file):
import librosa
import numpy as np
X_test = pd.DataFrame()
y_test = pd.DataFrame()
for test_sound_file in list_test_sound_file:
audio, sample_rate = librosa.load(test_sound_file)
wnd_size = 2048
wnd_stride = 512
hop_length = 2048
chroma_stft = librosa.feature.chroma_stft(
y=audio, sr=sample_rate,
n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_size
).flatten()
rmse = librosa.feature.rms(
y=audio, frame_length=wnd_size, hop_length=wnd_size
).flatten()
spec_cent = librosa.feature.spectral_centroid(
y=audio, sr=sample_rate, n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_stride
).flatten()
spec_bw = librosa.feature.spectral_bandwidth(
y=audio, sr=sample_rate, n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_stride
).flatten()
rolloff = librosa.feature.spectral_rolloff(
y=audio + 0.01, sr=sample_rate,n_fft=wnd_size,
win_length=wnd_size, hop_length=wnd_stride
).flatten()
zcr = librosa.feature.zero_crossing_rate(
y=audio, frame_length=wnd_size, hop_length=wnd_stride
).flatten()
harmony = librosa.feature.tempogram(
y=audio, win_length=wnd_size, hop_length=wnd_stride
).flatten()
mfcc = librosa.feature.mfcc(
y=audio, sr=sample_rate, win_length=2,
hop_length=hop_length
)
df_test = pd.DataFrame({'chroma_stft.mean':np.mean(chroma_stft, axis=0),
'chroma_stft.var':np.var(chroma_stft, axis=0),
'rmse.mean':np.mean(rmse, axis=0),
'rmse.var':np.var(spec_cent, axis=0),
'spec_cent.mean':np.mean(spec_cent, axis=0),
'spec_cent.var':np.var(spec_cent, axis=0),
'spec_bw.mean':np.mean(spec_bw, axis=0),
'spec_bw.var':np.var(spec_bw, axis=0),
'rolloff.mean':np.mean(rolloff, axis=0),
'rolloff.var':np.var(rolloff, axis=0),
'zcr.mean':np.mean(zcr, axis=0),
'zcr.var':np.var(zcr, axis=0),
'harmony.mean':np.mean(harmony, axis=0),
'harmony.var':np.var(harmony, axis=0)},index=[test_sound_file])
for i in range(len(np.mean(mfcc.T, axis=0))):
df_test['mfcc.mean'+str(i+1)] = np.mean(mfcc.T, axis=0)[i]
df_test['mfcc.var'+str(i+1)] = np.var(mfcc.T, axis=0)[i]
print('---------------')
print(test_sound_file.split('\\')[1].split('_')[0]+'_'+test_sound_file.split('\\')[1].split('_')[1])
df_test['label'] = test_sound_file.split('\\')[1].split('_')[0]+'_'+test_sound_file.split('\\')[1].split('_')[1] # @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 폴더명으로 통합
df_test = df_test.reset_index()
df_test = df_test.drop(columns=['index'])
X_one_test = df_test.iloc[:,:-1]
y_one_test = df_test['label']
encoding_dict ={'선박 운항_어선':2,
'경고음_구급차':0,
'경고음_철길 건널목':1,
'차량 공회전_SUV':5,
'차량 주행_1톤 트럭':8,
'선박 운항_여객선':3,
'차량 주행_SUV':9,
'차량 공회전_버스':6,
'차량 공회전_1톤 트럭':4,
'차량 공회전_승용차':7,
'차량 주행_버스':10,
'차량 주행_승용차':11}
y_one_test.values[0] = y_one_test.values[0].split('\\')[0]
print(y_one_test.values[0])
for i in range(len(encoding_dict)):
if list(encoding_dict.keys())[i] == y_one_test.values[0]:
y_one_test.values[0] = str(encoding_dict[list(encoding_dict.keys())[i]])
print(y_one_test)
y_one_test = y_one_test.astype(int)
X_test = X_test.append(X_one_test)
y_test = y_test.append(y_one_test)
return X_test,y_test
# test_sound_file = '해커톤/사운드/원천데이터/선풍기 사용\선풍기 사용_공업용 선풍기_Sm0000047.wav' # 직업 음성파일 선택하기
X_test,y_test = get_test_sound_file_to_data(list_test_sound_file)
# 모델 평가
def get_clf_eval(y_test,list_pred,list_pred_proba,list_models):
from sklearn.metrics import accuracy_score,precision_score
from sklearn.metrics import recall_score,confusion_matrix
from sklearn.metrics import f1_score,roc_auc_score
import time
list_confusion = []
list_accuray = []
list_precision = []
list_recall = []
list_f1 = []
list_roc_auc = []
df_evaluation = pd.DataFrame(columns=['accuracy','precision','recall','f1_score']) # ,'ROC_AUC'
for i in range(len(list_pred)):
print(f"{str(list_models[i]).split('(')[0]}")
start = time.time()
# 혼동행렬(오차행렬),정확도, 정밀도, 재현율,f1,roc_auc
confusion = confusion_matrix(y_test,list_pred[i]) # 혼동행렬
list_confusion.append(confusion)
accuracy = accuracy_score(y_test,list_pred[i]) # 정확도
list_accuray.append(accuracy)
precision = precision_score(y_test,list_pred[i], average='micro') # 이진분류시 => 정밀도 ,pos_label=1
list_precision.append(precision)
recall = recall_score(y_test,list_pred[i], average='micro') # 이진분류시 => 재현율 ,pos_label=1
list_recall.append(recall)
f1 = f1_score(y_test,list_pred[i],average='micro')# 이진분류시 => pos_label=1
list_f1.append(f1)
# roc_auc = roc_auc_score(y_test,list_pred_proba[i],multi_class='ovr',average="macro") # 다항분류 시 => multi_class='ovr'
# list_roc_auc.append(roc_auc)
end = time.time()
df_evaluation = df_evaluation.append({'accuracy':accuracy,'precision':precision,'recall':recall,'f1_score':f1},ignore_index=True) #'ROC_AUC':roc_auc},
print(f"{list_models[i].__class__}")
print('오차행렬')
print(confusion)
print(f'정확도:{accuracy:.4f}, 정밀도:{precision:.4f}, 재현율:{recall:.4f}, f1스코어:{f1:.4f}') # :.4f 소수 4자리까지 , roc_auc:{roc_auc:.4f}'
print(f'실행 시간:{end-start:.6f}')
print("\n")
df_evaluation = df_evaluation.set_axis([str(list_models[i]).split('(')[0] for i in range(len(list_models))], axis='index')
return df_evaluation
df_evaluation = get_clf_eval(y_test,list_pred,list_pred_proba,list_models)
# import dataframe_image as dfi
# dfi.export(df_evaluation,'Traffic_Try_Matching_20_samples.jpg')
df_evaluation


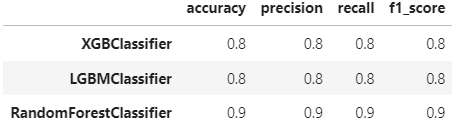
# 검증 결과 정확도 그래프 시각화
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
df_evaluation = df_evaluation.rename(index={'XGBClassifier':'XGB','LGBMClassifier':'LGBM','RandomForestClassifier':'RandomForest'})
plt.figure(figsize=(4,4))
plt.ylim(0.0,1.0)
# plt.xticks(rotation=45)
sns.set_palette("pastel")
g = sns.barplot(x=df_evaluation.index,y=df_evaluation['accuracy'],ci=None,errwidth=50)
for i in range(len(df_evaluation.index)):
print(i)
g.text(x = i, y=np.round(df_evaluation['accuracy'].values[i],4),s=np.round(df_evaluation['accuracy'].values[i],4),ha='center')
plt.savefig('Traffic_Try_Matching_20_samples_Accuaracy.png')
plt.show()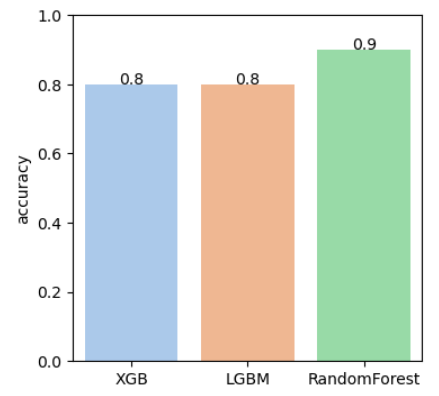
import numpy as np
reverse_encoding_dict_detail ={ 2: '선박 운항_어선',
0: '경고음_구급차',
1: '경고음_철길 건널목',
5: '차량 공회전_SUV',
8: '차량 주행_1톤 트럭',
3: '선박 운항_여객선',
9: '차량 주행_SUV',
6: '차량 공회전_버스',
4: '차량 공회전_1톤 트럭',
7: '차량 공회전_승용차',
10: '차량 주행_버스',
11: '차량 주행_승용차'}
reverse_encoding_dict_folder ={ 2: '선박 운항',
0: '경고음',
1: '경고음',
5: '차량 공회전',
8: '차량 주행',
3: '선박 운항',
9: '차량 주행',
6: '차량 공회전',
4: '차량 공회전',
7: '차량 공회전',
10: '차량 주행',
11: '차량 주행'}
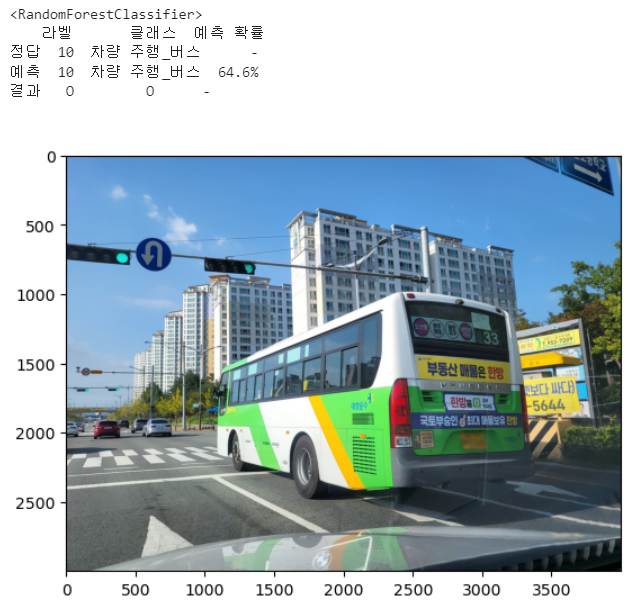
for i in range(len(list_test_sound_file)):
print(f'<{i+1}번째 문제>')
# print(f"정답 : Label = {y_test.values[i]},{reverse_encoding_dict[y_test.values[i][0]]}\n")
for j in range(len(list_models)):
print(f'<{list_models[j].__class__.__name__}>')
# print(np.round(list_pred_proba[j][i],3))
df_result = pd.DataFrame(columns=['라벨','클래스','예측 확률'],index=['정답','예측','결과'])
maxproba = np.round(list_pred_proba[j][i],3).max()
answer = np.where(np.round(list_pred_proba[j][i],3)==maxproba)
is_correct = ''
if y_test.values[i] == answer[0]:
is_correct = 'O'
else:
is_correct = 'X'
# print(f"{str(list_models[j].__class__.__name__)}이(가) 예측한 답: {answer[0]},{reverse_encoding_dict[answer[0][0]]},{is_correct}")
# maxproba = np.round(list_pred_proba[j][i],3).max()
# print(maxproba)
df_result.loc['정답','라벨'] = int(y_test.values[i][0])
df_result.loc['정답','클래스'] = reverse_encoding_dict_detail[y_test.values[i][0]]
df_result.loc['정답','예측 확률'] = '-'
df_result.loc['예측','라벨'] = answer[0][0]
df_result.loc['예측','클래스'] = reverse_encoding_dict_detail[answer[0][0]]
df_result.loc['예측','예측 확률'] = str(np.round(maxproba*100,3))+'%'
df_result.loc['결과','라벨'] = is_correct
df_result.loc['결과','클래스'] = is_correct
df_result.loc['결과','예측 확률'] = '-'
print(df_result)
print('\n') # answer[0][0] = 1
get_pred_pics(reverse_encoding_dict_folder[answer[0][0]],reverse_encoding_dict_detail[answer[0][0]])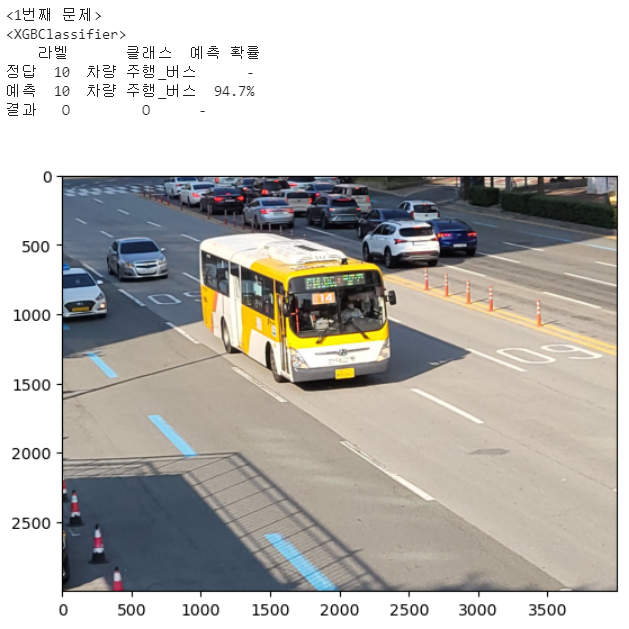


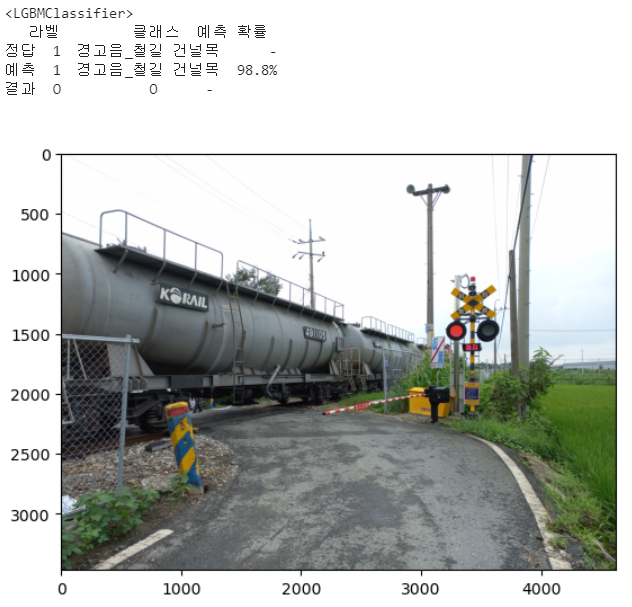
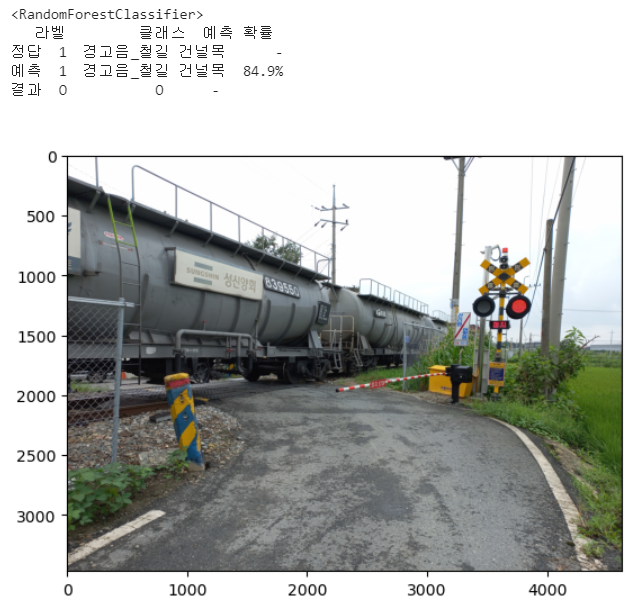
참고
해커톤이미지/사운드 매칭프로젝트 (3) 글에 기재된 발표 PPT 및 설명 참고하시면 되겠습니다.

https://github.com/min731