1. Preprocessing 복습 및 과정 살펴보기
텍스트 분류(Text Classification) 등의 NLP 과제에서 전처리(Preprocessing)는 모델의 성능과 효율성에 큰 영향을 미치는 필수 단계다.
우리가 앞서 배운 Preprocessing의 내용에 대해서 간략히 살펴보고 이후 step들을 진행해보겠다.
우선 text data는 비정형적인 data가 주를 이루며, 이러한 정형화되어있지 않은 data를 머신러닝 모델이 더 잘 학습하고 분류하기 위해서는 전처리 과정이 필수적이다. 특히나 정보가 범람하는 요즘 시대에 자연어처리 task를 더 효과적으로 진행하기 위해서, 우리에게 필요한 정보만을 선별적으로 필터링 할 수 있는 text classification의 중요성은 더욱 중요해지고 있고, 이를 도와주는 것이 전처리 과정이기 때문이다.
전처리는 크게 Tokenization을 중심으로 하여, 그 전후로 나누어 구분해 볼 수 있다.
1. Tokenization 전
- Cleaning: 노이즈(불필요한 기호, HTML 태그, 과도한 공백, 이모지 등)를 제거하고, 일관된 문자열 형태로 만들기 위한 사전 작업이다.
- Normalization: 대소문자 변환, 숫자나 기호 정규화, 각종 형태적 변형을 규칙에 맞춰 통일하는 과정을 의미한다.
2. Tokenization
- Sentence, Word, Sub-word, Character Tokenization 등 특정 단위로 텍스트를 분할하는 단계이다. 말 그대로 text를 token화 하는 작업이기 때문에, NLP task에서 가장 중요한 핵심 과정이라고 할 수 있다.
3. Tokenization 후
- 토큰화가 끝나면 다시금 Cleaning과 Normalization의 필요성이 생길 수 있다. 예를 들어, 토큰화 후에 재확인된 불필요 토큰(공백만 남은 토큰, 문장 부호만 남은 토큰)이나 추가적인 정규화 필요성이 발견될 경우가 있다.
- 또한 Stemming이나 Lemmatization을 진행하여 단어 형태를 표준화하는 작업이 뒤따른다.
보다시피 전처리 전체 과정에서 Cleaning과 Normalization은 끊임없이 반복 혹은 보완되는 특성이 있으며, Tokenization과 유기적으로 맞물려야 최상의 효과를 낼 수 있다. 이번 글에서는 Cleaning과 Lemmatization을 중점으로 Preprocessing 과정을 살펴보겠다.
2. Cleaning
Cleaning은 텍스트에서 노이즈(Noise)를 제거하고, 일관성 있는 상태로 만드는 가장 초기 단계의 작업이다. 우리가 수집하는 텍스트 데이터는 종종 SNS에서의 이모티콘, 특수문자, 표준화되지 않은 약어 등 다양한 형태로 주어지므로, 이들을 적절히 처리하지 않으면 이후 단계에서 모델이 학습에 방해를 받게 된다.
Q. 이때, Noise란?
-> Text data 내에서 의미적 분석에 불필요하거나 방해가 되는 요소들을 의미한다.
-> 이들은 모델 학습의 정확도를 저해할 수 있으며, 데이터 정제 과정에서 제거해야 변환해야한다.
2.1. Noise Data의 주요 유형
- 특수 문자(Special Characters)
@, #, $, %, ^, &, *등- 텍스트 의미 해석에 불필요한 경우가 많으며, 정규 표현식(Regex) 등을 활용해 제거한다.
- 이모지 및 기호(Emojis and Symbols)
❤️, 😝, 💩, 👻등- 소셜미디어 분석에서 Sentiment Analysis를 한다면 유용할 수 있지만, 일반적인 문서 분석에서는 제거해야 할 수도 있다.
- HTML 태그 및 메타데이터(HTML Tags & Metadata)
- 웹에서 크롤링한 데이터라면
<div>,<p>등과 같은 태그가 포함될 수도 있다. BeautifulSoup등의 라이브러리를 사용하여 정리 가능하다.
- 웹에서 크롤링한 데이터라면
Q. BeautifulSoup 라이브러리란?
A. BeautifulSoup은 HTML 및 XML 문서에서 데이터를 쉽게 파싱하고 추출할 수 있도록 도와주는 파이썬 라이브러리이다. HTML 태그를 손쉽게 탐색하고 원하는 정보를 추출하는 기능을 제공한다.
from bs4 import BeautifulSoup
html = "<html><body><h1>Hello, World!</h1></body></html>"
soup = BeautifulSoup(html, "html.parser")
print(soup.h1.text) # "Hello, World!"- 중복 문자 및 비정상적인 패턴(Repeated Characters & Irregular Patterns)
"ㅋㅋㅋㅋㅋㅋㅋㅋ재밌다", "coooooool", "chillllllllll guy!!!!"- 철자 교정 또는 중복 문자 제거 기법을 적용해 정제 가능하다.
- URL 및 이메일 주소(URLs & Email Addresses)
- 예:
https://example.com,contact@example.com - 웹 텍스트에서는 흔하게 등장하며, 모델의 성능을 저하시킬 가능성이 있다.
- 예:
- Stopwords(불용어)
- 예: "the", "is", "and", "in"
- 문장 내에서 중요한 의미를 전달하지 않는 단어들로, 불용어 제거(Stopword Removal) 기법을 사용하여 정제
우리가 Cleaning과정을 거친다고 할때, 일반적으로 가장 먼저 떠올리게 되는 것은 Stopwords 처리이다. 더 자세한 Stopword에 대한 내용과 Stopword Remmoval 기법에 대해서는 아래에서 조금 더 자세하게 알아보도록 하자.
2.2. Stopword
Stopword는 의사소통에서 자주 등장하지만, 텍스트의 의미를 명확히 하는 데 크게 관여하지 않는 단어들을 말한다. 예를 들어, 영어에서는 관사와 전치사(“the”, “of”, “and”, “to” 등), 한국어에서는 조사(‘은’, ‘는’, ‘이’, ‘가’ 등)나 접속 부사(‘그러나’, ‘그러므로’ 등)가 같은 역할을 할 수 있다.
Stopword 제거 과정을 통해 모델이 더 중요한 토큰(명사, 동사, 형용사 등)에 집중하도록 만들 수 있다. 다만, 어떤 단어가 실제로 불필요한지 판단하는 기준은 분석 과제나 언어, 도메인에 따라 달라질 수 있으므로, 추가로 참고하면 좋은 것들이 몇 가지 존재한다.
1. 언어별 Stopword 사전
- NLTK, spaCy 등 외부 라이브러리가 제공하는 기본 Stopword 사전을 활용한다. 하지만 이 사전은 일반 텍스트 환경에서 유용할 뿐, 전문용어가 많은 법률, 의료, 금융 등 특정 도메인에는 맞지 않을 수 있다.
- 예시: NLTK가 정의한 영어 불용어들 제거하기
<NLTK가 불용어로 정의하고 있는 단어들 살펴보기>
!pip install konlpy
!pip install nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from konlpy.tag import Okt
nltk.download('stopwords')
nltk.download('punkt_tab')
stop_words_list = stopwords.words('english')
print('불용어 개수 :', len(stop_words_list))
print('불용어 10개 출력 :',stop_words_list[:10])
#불용어 개수 : 198
#불용어 10개 출력 : ['a', 'about', 'above', 'after', 'again', 'against', 'ain', 'all', 'am', 'an']<NLTK로 직접 불용어 삭제해보기>
example = "I want to be a chill guy. It looks so cool."
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example)
result = []
for word in word_tokens:
if word not in stop_words:
result.append(word)
print('불용어 제거 전 :',word_tokens)
print('불용어 제거 후 :',result)
#불용어 제거 전 : ['I', 'want', 'to', 'be', 'a', 'chill', 'guy', '.', 'It', 'looks', 'so', 'cool', '.']
#불용어 제거 후 : ['I', 'want', 'chill', 'guy', '.', 'It', 'looks', 'cool', '.']2. 도메인 특화 Stopword
- 특정 도메인에서는 자주 쓰이지만, 해당 필드 내에서의 의미적 구분력이 매우 낮은 단어들이 존재한다.
- 예를 들어, “patient”, “hospital”, "medicine"이 의료 데이터 분석에선 도메인 Stopword가 될 수도 있다. (의료 논문의 핵심적인 정보 전달에는 크게 기여하지 않을 수 있기 때문)
- 이는 다른 Stopword 제거와 마찬가지로 벡터화 과정중에서 차원 축소 기능을 담당하여 연산량을 크게 감소시키는 효과가 있다.
도메인별 Stopword 예시
- 법률(Legal) 분야: "court", "law", "judge", "case", "legal", "evidence"
- 금융(Finance) 분야: "stock", "market", "investment", "price", "trade", "financial"
- IT/기술(Technology) 분야: "data", "server", "network", "algorithm", "application"
3. 통계적 접근
- 코퍼스 내에서 너무 자주 등장하거나(상위 5~10% 정도), 거의 등장하지 않는(하위 1% 미만) 단어를 제거하는 기법도 있다. 단순 빈도 기반 접근이므로 자칫 잘못하다가는 유의미한 정보를 잃을 위험도 존재하지만, 큰 관점에서 일괄적인 기준을 설정할 때는 도움이 된다.
3. Normalization
텍스트 데이터는 문장부호, 대소문자, 단어 형태 변형 등으로 인해 같은 의미를 가짐에도 불구하고 서로 다른 단어로 취급될 수 있다. Normalization은 표면적으로 다른 단어/표현임에도 실제로는 같은 의미를 가지는 텍스트를 일관된 형태로 바꾸는 과정이다. (우리가 기존에 통계를 공부할 때 배웠던 Normalization과 다르지 않다)
Cleaning과 유사한 부분이 있지만, Cleaning이 비교적 일반적이고 규칙적인 제거/치환 과정에 집중한다면, Normalization은 언어의 형태 변화(예: 동사의 시제 변화, 명사의 복수 형태 등)와 같은 언어학적 변형을 처리하는 데 초점을 맞춘다.
Normalization은 크게 Stemming과 Lemmatization으로 나뉘는데, 두 방법 모두 단어를 정형화된 ‘기본 단위(lemma)’ 혹은 ‘어간(stem)’으로 변환함으로써 유의미한 단어 수를 줄이고, 유사한 개념을 동일하게 처리할 수 있도록 한다.
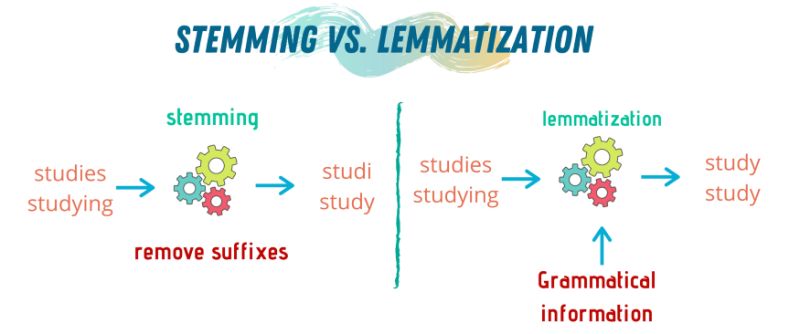
3.1. Stemming(어간 추출)
Stemming은 단어에서 접사(접두사, 접미사)를 기계적으로 제거하여 어간(Stem)을 추출하는 방법이다. Stemming은 기본적으로 규칙에 따라 단순한 문자열 변환을 수행하며, 단어의 문법적 형태나 의미를 고려하지 않고 단순히 형태를 줄이는 방식으로 동작한다.
예를 들어, 다음과 같은 단어들이 동일한 어간으로 변환될 수 있다.
- "studies" → "studi"
- "studying" → "studi"
- "study" → "studi"
즉, 서로 다른 형태를 가진 단어들이 동일한 어간으로 축소됨으로써 같은 의미를 가지는 단어들을 동일하게 처리할 수 있도록 한다.
위의 예시와 같이 Stemming 후에 도출되는 '어간'은 사전에는 없는 단어일 가능성이 크다.
(문법적 옳음이나 단어 사용 경향에 대한 정보가 아예 없는 rough한 과정이기 때문이다.)
3.1.1. Stemming의 장단점
1. 장점
- 단순한 규칙 기반 처리이므로 속도가 빠르며 계산량이 적다.
- 대규모 텍스트 데이터를 다룰 때 빠른 전처리가 가능하다.
- 검색 엔진과 같은 정보 검색 시스템에서 색인(Indexing)을 통합하는 데 유용하다.
2. 단점
- 언어학적 분석 없이 단순한 패턴 제거를 수행하기 때문에 정확도가 떨어질 가능성이 높다.
- 앞서 언급했듯, 의미를 고려하지 않고 단순한 변환을 수행하므로, 실제로 존재하지 않는 단어 형태를 생성할 수 있다. (예: "happy" → "happi", "better" → "bett")
- 서로 다른 의미의 단어가 동일한 어간으로 변환될 수 있다. 예를 들어, "university"와 "universal"이 같은 어간으로 변환될 가능성이 있다.
3.1.2. Stemming 방법들
Stemming을 수행하는 대표적인 알고리즘들에 대해 가볍게만 언급하고 넘어가도록 하자.
1) Porter Stemmer
- 가장 널리 사용되는 어간 추출 알고리즘으로, 접미사 제거 규칙을 기반으로 동작한다. 비교적 보수적인 절단 규칙을 적용하여, 불필요한 변형을 최소화한다.
- NLP의 다양한 분야에서 사용되며, 특히 검색 엔진에서 유용하게 활용된다.
- Porter Algorithm 상세규칙 여기 링크에서 Porter Algorithm에 대한 추가적인 정보를 확인할 수 있다.
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
words = ["running", "flies", "happiness"]
print([stemmer.stem(word) for word in words])
# ['run', 'fli', 'happi']2) Lancaster Stemmer
- Porter Stemmer보다 더 공격적인 규칙을 적용하여 단어를 더욱 짧게 변환한다.
- 어간이 너무 짧아지는 경향이 있어 의미 보존에 어려움이 있을 수 있다.
from nltk.stem import LancasterStemmer
stemmer = LancasterStemmer()
words = ["running", "flies", "happiness"]
print([stemmer.stem(word) for word in words])
# ['run', 'fli', 'happy']3) Snowball Stemmer
- Porter Stemmer의 확장 버전으로, 다양한 언어에 적용할 수 있도록 설계됨.
- 여러 언어를 지원하기 때문에 다국어 NLP 프로젝트에서 활용 가능하다.
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer("english")
words = ["running", "flies", "happiness"]
print([stemmer.stem(word) for word in words])
# ['run', 'fli', 'happi']3.2. Lemmatization(표제어 추출)
Lemmatization은 단어의 어형 변화를 분석하여 사전적 원형(lemma)으로 변환하는 방식이다. 즉, 문법적 요소(품사)를 고려하여 원형을 찾아 변환하는 방식으로 동작한다.
몇 가지 예시를 들어 보겠다.
- "am", "are", "is" → "be"
- "studies", "studying" → "study"
- "ran" → "run"
- "better" → "good"
예시에서 확인할 수 있다시피, Stemming이 단순히 단어의 일부를 잘라내는 방식이라면, Lemmatization은 언어적 의미와 문법을 고려하여 변환하는 과정이라고 할 수 있다.
3.2.1. Lemmatization의 특징
1. 장점
- 문법적 정확성을 유지하면서 단어를 변환할 수 있다. ("is" → "be")
- 언어학적으로 정확한 변환이 가능하므로 NLP task에서 의미 보존에 보다 용이하다.
- Sentiment Analysis이나 Text Classification과 같은 과제에서 더 나은 성능을 보일 가능성이 높다.
2. 단점
- 사전(Dictionary) 기반의 처리이므로 속도가 상대적으로 느리다.
- 형태소 분석을 필요로 하기 때문에 구현이 복잡하며, 언어별로 다른 형태소 분석기가 필요할 수 있다.
3.2.2. Lemmatization 방법들
Lemmatization을 수행하는 대표적인 도구들에 대해 가볍게만 언급하고 넘어가도록 하자.
1) WordNet Lemmatizer (NLTK)
- 아까 봤던 그 NLTK와 같은 NLTK가 맞다!
- WordNet을 기반으로 동작하는 가장 널리 사용되는 Lemmatization 도구이며, 품사 정보를 제공하지 않으면 기본적으로 명사(noun)로 처리된다.
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
words = ["running", "flies", "happiness", "better"]
print([lemmatizer.lemmatize(word) for word in words])
# ['running', 'fly', 'happiness', 'better']
# 품사 정보를 제공하면 더 정확한 결과를 얻을 수 있음
print(lemmatizer.lemmatize("running", pos="v")) # 'run'
print(lemmatizer.lemmatize("flies", pos="v")) # 'fly'
print(lemmatizer.lemmatize("better", pos="a")) # 'good'2) spaCy Lemmatizer
- NLTK보다 속도가 빠르고, 형태소 분석과 결합하여 더 정교한 결과를 제공한다.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("running flies happiness better")
print([token.lemma_ for token in doc])
# ['run', 'fly', 'happiness', 'good']4. 언어별 고려사항
위에서 Cleaning과 Normalization 과정이 주로 영어를 예시로 언급되었지만, 실제로는 언어마다 체계가 크게 달라 전처리 과정 자체를 특수화해야 하는 경우가 많다. 특히 한국어, 중국어, 일본어 등은 공백이나 문장 부호 기준으로 단어 경계를 구분하기 어렵기 때문에, 형태소 분석이 Cleaning·Normalization 과정과 맞물려 동작해야 한다.
마찬가지로 깊게 다루지 않고 가볍게만 다루겠다.
4.1. 한국어
<주요 특징>
- 교착어(Agglutinative Language)로, 어근 + 조사/어미로 구성된다.
- 공백만으로 단어를 분리하기 어려워 형태소 분석(Morphological Analysis)이 필수적이다.
<전처리 방법>
1. 형태소 분석 기반 Tokenization
- “그녀는 학교에 갔다” → ["그녀", "는", "학교", "에", "가", "았", "다"]
- 형태소 분석기(Mecab, Kkma, Komoran 등)를 활용해 단어를 정확히 분리.
2. 어미·조사 제거
- "학교에", "학교를", "학교가" → "학교"
- 불필요한 변형을 방지하여 단어를 일관된 형태로 유지.
from konlpy.tag import Mecab
mecab = Mecab()
print(mecab.morphs("그녀는 학교에 갔다."))
# ['그녀', '는', '학교', '에', '가', '았', '다', '.']4.2. 중국어 & 일본어
<중국어>
- 띄어쓰기가 없어 단어 경계를 판별해야 한다.
- Jieba 같은 중국어 전용 Tokenizer 사용.
import jieba
print(jieba.lcut("我喜欢看书"))
# ['我', '喜欢', '看书']<일본어>
- 히라가나, 가타카나, 한자 조합으로 구성.
- MeCab과 같은 형태소 분석기 활용.
import MeCab
mecab = MeCab.Tagger("-Ochasen")
print(mecab.parse("彼は学校へ行った"))5. Reference
[1] Oscar-cho / 01-03. Cleaning ~ 01-04. Normalization
- https://publish.obsidian.md/oscar-cho/Study/NLP/01.+Text+Preprocessing/01-03.+Cleaning
- https://publish.obsidian.md/oscar-cho/Study/NLP/01.+Text+Preprocessing/01-04.+Normalization
[2] 딥 러닝을 이용한 자연어 처리 입문 / 02. 텍스트 전처리 / 02-02 정제(Cleaning) and 정규화(Normalization)
[3] 텍스트 전처리 - 어간추출(Stemming) & 원형 복원(Lemmatization) : 김채형(Chaehyeong Kim)
[4] The Porter stemming algorithm
