Apache Kafka

Apache Kafka는 웹사이트, 어플리케이션, 센서 등에 취합한 데이터를 스트림 파이프라인을 통해 실시간으로 관리하고 보내기 위한 분산 스트리밍 플랫폼이다.
Kafka 개요
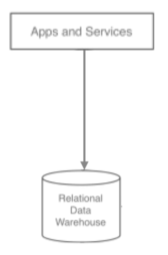
데이터를 넣는 source APP과 쌓이는 target APP이 있다.
처음엔 단방향 통신이었지만 시간이 지날수록 source APP과 target APP이 많아지면서 데이터 전송 라인이 많아지게 됐다.
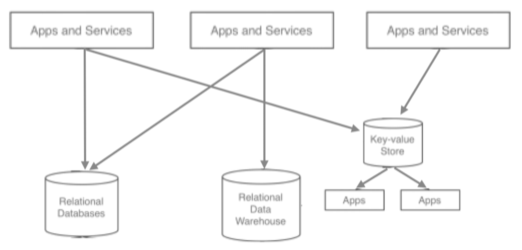
이런식의 구조로 가져가게 되면서 유지보수하기 매우 힘들어지게 됐다.
kafka는 이런 문제를 해결하기 위해 링크드인에서 개발하였고 현재는 오픈소스로 사용할 수 있다.
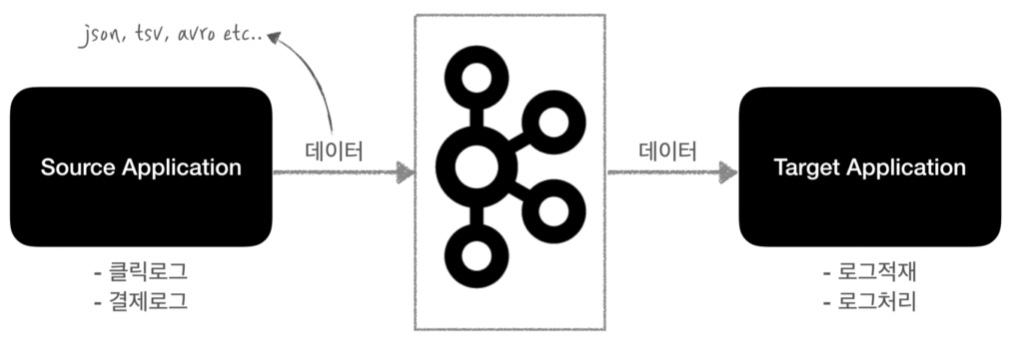
kafka는 각종 데이터를 담는 topic이라는 것이 있는데 간단하게 큐라고 생각하면 된다.
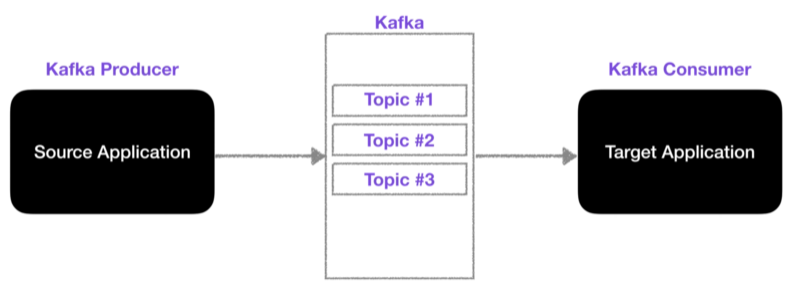
큐에 데이터를 넣는 역할은 프로듀서가, 가져가는 역할은 컨슈머가 한다. 프로듀서와 컨슈머는 라이브러리로 APP에서 가져다 쓸 수 있고 아래 사진과 같은 구조로 이루어져 있다고 보면 된다.
kafka는 fault tolerance 즉, 고가용성으로 서버가 이슈가 생기거나 랙이 다운되는 상황에서도 쉽게 복구할 수 있다.
낮은 latency, 높은 throughput으로 효과적으로 데이터를 아주 많이 처리할 수 있다는 장점이 있어서 현재 빅데이터를 처리하는 IT기업에선 안쓰는 곳이 없을 정도이다.
[Apache Kafka 참고]
Kafka 관련 모든 포스팅은 유튜버 '데브원영'님 영상을 참고 하였습니다.

AI Solutions Architect