MapReduce란?
- 2004년 구글에서 발표한 Large Cluster 에서Data Processing 을 하기 위한 알고리즘
- Hadoop MapReduce 는 구글 알고리즘 논문을 소프트웨어 프레임워크로 구현한 구현체
- Key-Value 구조가 알고리즘의 핵심
- 모든 문제를 해결하기에 적합하지는 않을 수 있음(데이터의 분산 처리가 가능한 연산에 적합)
MapReduce 알고리즘
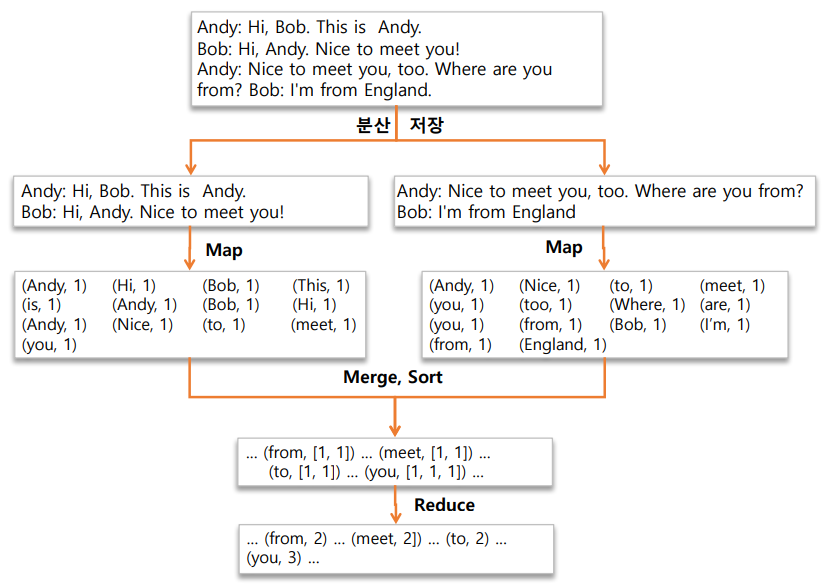
key-value구조로 되어있다.
Map Function과 Reduce Function 모두 input도 key value, output도 key value
- Map Function : (key1, value1) -> (key2, value2)
- Reduce Function : (key2, List of value2) -> (key3, value3)
| 장점 | 단점 |
|---|---|
| 단순하고 사용이 편리 | 고정된 단일 데이터 흐름 |
| 특정 데이터모델이나 스키마, 질의에 의존적이지 않은 유연성 | 기존 DBMS보다 불편한 스키마 정의 |
| 저장 구조의 독립성 | 단순한 스케줄링 |
| 데이터 복제에 기반한 내구성과 재수행을 통한 내결함성 확보 | 개발도구의 불편함 |
| 높은 확장성 | 기술지원의 어려움 |
컴포넌트
- 클라이언트(Client)
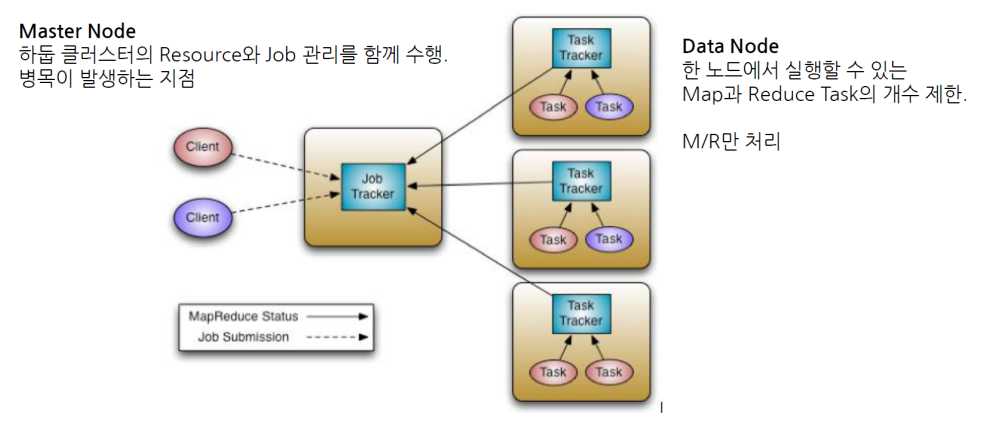
구현된 맵리듀스 Job 을 제출하는 실행 주체 - 잡트래커(JobTracker)
맵리듀스 Job이 수행되는 전체 과정을 조정하며, Job 에 대한 마스터(Master) 역할 수행 - 태스크트래커(TaskTracker)
Job 에 대한 분할된 Task 를 수행하며, 실질적인 Data Processing 의 주체 - 하둡 분산 파일시스템(HDFS)
각 단계들 간의 Data 와 처리과정에서 발생하는 중간 파일들을 공유하기 위해 사용
구동 절차
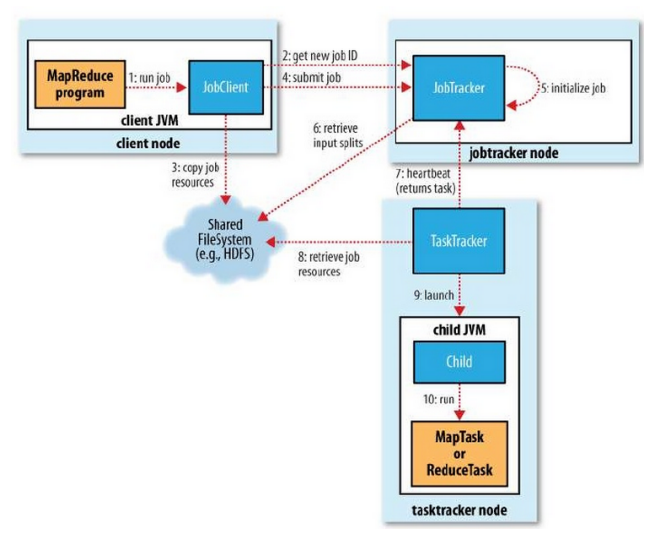
1. Job 실행
2. 신규 Job ID 할당(JobTracker) 및 수신
3. Job Resource 공유
4. Job 제출
5. Job 초기화
6. InputSplits 정보 검색
7. 절절한 TaskTracker 에 Task 를 할당
8. TaskTracker 가 공유되어 있는 Job Resource 를 Local 로 복사
9. TaskTracker 가 child JVM 실행
10. MapTask 또는 ReduceTask 실행
하둡 Job Tracker한테 Job 제출 -> 그 후로 동작하는 배포는 하둡에서 알아서 한다.
개발자가 자체 클러스터에 jar파일을 배포하는 등등의 과정을 거치지 않아도 된다.
(java로 만들었을때만)
InputSplit
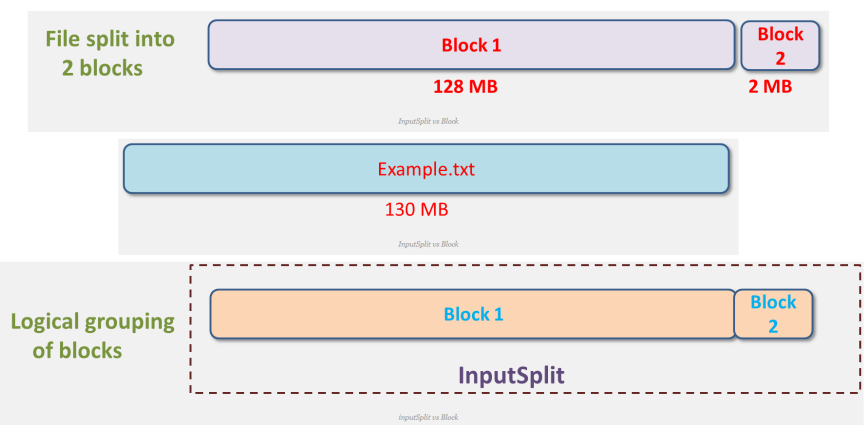
InputSplit 은 물리적 Block 들을 논리적으로 그룹핑한 개념
InputSplit 은 Mapper 의 입력으로 들어오는 데이터를 분할하는 방식을 제공하기 위해, 데이터의 위치와 읽어들이는 길이를 정의한다.
MapTask
로컬디스크에서 제일 처음 뜨는 태스크가 맵태스크
데이터 스플릿 되있는 애들을 맵태스크에서 읽어서 맵리듀스 알고리즘 기준으로 처리 -> output으로 떨구고 reduce로 데이터를 보낼 때 해시 파티셔닝을 하게 되어있다. 그 파티션을 기준으로 같은 키를 가진 애들끼리 머지한 후 reduce 연산을 하는 것이 전체 Workflow
예제
구현 인터페이스

필수로 구현해야하는 것은 mapper 하나이다. reduce는 옵션
mapper는 실제 비즈니스로직을 첫 번재로 구현하는 것
mapper의 결과를 파티션닝해서 서로 다른 노드에서 나온 키들을 같은 키끼리 묶을 수 있도록 같은 서버로 전송해준다.
그 output을 reduce functions을 지난 후 출력하는 것이 MapReduce
mapper > reduce 과정을 셔플이라고 한다.
분산 환경에선 이 과정에서 트래픽이 발생할 수밖에 없다.
맵리듀스 app이 동작할 때 셔플에서 발생할 수 있는 트래픽 양을 최소한으로 줄여주게끔 프로그래밍 해야 성능이 잘 나오는데그걸 해주는 게 Combiner와 Partitioner
-
Combiner
reduce에서 해야하는 연산을 미리 mapper쪽에서 수행 한다음 보내주는 것(트래픽으로 전송해야하는 양이 주는 것) -
Partitioner
파티셔너(default인 해시 파티셔너) 키가 있을 때 그걸 기준으로 해싱 처리하고 reducer의 개수만큼 모듈러 연산
Hadoop Version에 따른 차이
하둡 1.0과 2.0
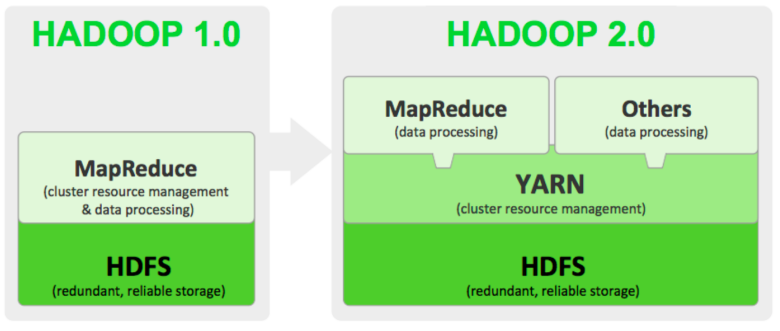
1.0은 hdfs에 저장되어있는 데이터를 mapreduce에서 바로 처리.
2.0은 yarn이라는 리소스 매니저 추가.
yarn을 통해서 mapreduce 알고리즘을 돌릴 수도 있고 그 외에 다른 분산처리 알고리즘을 돌릴 수도 있다.
(ex) 전통적인 parallel 컴퓨팅 API 등등)
1.0
2.0
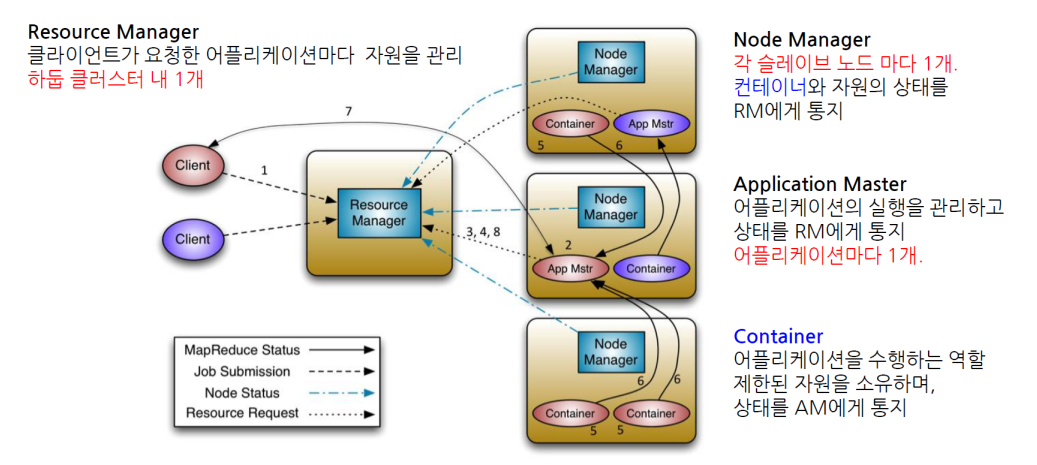
Job Tracker라는 데몬, task tracker라는 개념이 사라졌다.
리소스 매니저가 전체 클러스터에 하나 존재, 그리고 노드마다 노드 매니저 존재.
클라이언트가 어떤 app을 만들어서 Job을 submit하게 되면 전체 클러스터가 주기적으로 report를 받는다.
리소스 매니저에서 "이 app은 1번 서버에서 실행할 거야" 라고 노드 매니저에 명령을 내리면 노드 매니저는 Application Master를 구동시키는 방식으로 동작(1.0의 Job Tracker라고 보면 된다.)
yarn을 통해 job을 구동하면 좀 더 오래걸린다(구성이 1.0보다 좀 더 복잡해졌기 때문)
간단한 job을 실행해도 10초 20초씩 걸리는 복잡한 절차 때문에 하둡이 작은 데이터를 처리하기엔 적절하지 않은 플랫폼인 것이다.
3.0
가장 중요한 차이점은 하둡 내부에서 레이드 구성을 하는 이래이저 코딩 도입. (데이터 저장량을 원본 대비 두 배 정도만 되게끔 해준다.)
디렉토리 단위로 이래이저 코딩을 적용할 수도 있고 안할 수도 있다.
적용 x : 파일 사이즈가 매우 작을 경우
적용 : 파일 사이즈가 큰 경우 보통 적용하면 용량이 절반정도로 줄어드는 효과를 볼 수 있다.
Hive, Spark
보다 쉬운 분석을 위해 SQL로 지원을 하는 엔진들이다.
Spark
spark는 꼭 hadoop과의 dependency가 있지는 않지만 하둡에 저장되어있는 데이터를 sql로 처리할 수 있고 조금 더 다양한 것을 할 수 있다.
성능도 훨씬 빠름. (메모리상에서 처리하기 때문)
단점은 spark는 전체 클러스터의 메모리 사이즈를 벗어나는 데이터는 처리하지 못한다.
Hive
반면 hive는 디스크 단위로 읽고 쓴다.
보통은 메모리보다 디스크가 크기 때문에 spark에서 처리하지 못한 것들을 hive에선 처리할 수 있다.
하지만 대부분 분산환경에서 요새 메모리가 크기 때문에 spark sql로 etl처리를 하는 것이 일반적
hive는 기본적으로 메타스토어(mysql과 같은 rdb)가 있다.
하둡에 데이터를 저장해놓고 저장된 데이터를 rdb처럼 스키마 define 해줘서 분석에 사용할 수 있다.(define 되어있는 데이터를 sql 쿼리로 실행)
