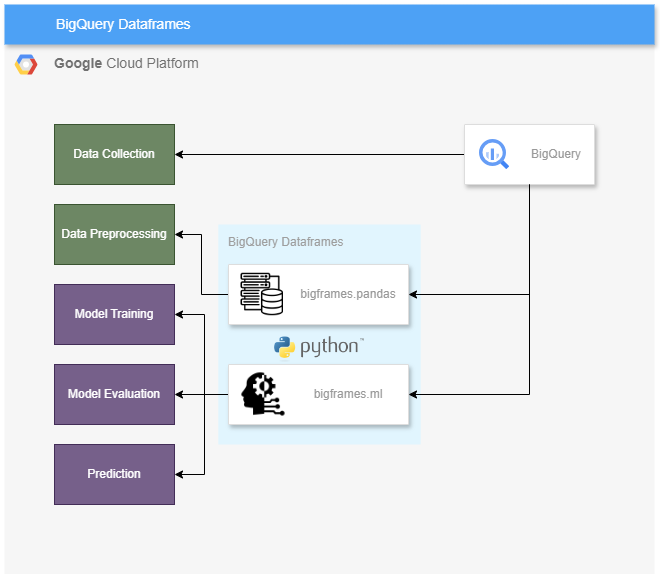
BigQuery DataFrames란?
BigQuery DataFrames는 BigQuery 데이터를 분석하고 머신러닝 작업을 수행하는 데 사용할 수 있는 Python 클라이언트 라이브러리이다.
bigframes 라이브러리
- bigframes.pandas는 BigQuery 상단에 pandas-like-API 구현.
- bigframes.ml는 BigQueryML 상단에 scikit-learn-API 구현.
+ 추가로 bigframes.ml의 경우 Google의 LLM 모델인 PaLM2, Gemini의 Text Generator모델과 PaLM2의 Text Embedding 모델도 지원하여 손쉽게 생성형 AI의 영역까지 확장하여 사용이 가능하다.
때문에 bigframes 라이브러리를 사용하면 SQL이 아닌 pandas가 익숙한 데이터 엔지니어, scikit-learn을 사용하는 게 익숙한 ML 엔지니어 모두 손에 익은 방식 그대로 BigQuery 데이터를 다룰 수 있다.
BigQuery 콘솔(이하 BigQuery Studio라고 명명)에서 노트북을 만들어 사용할 수 있는 기능이 출시됐다. 노트북을 사용하면 자체적으로 Colab Enterprise 노트북을 생성하는데 여기서 작업해볼 것이다.
참고로 BigQuery DataFrames도 그렇고 노트북 기능도 2024.03.19기준 GA되진 않았다.
노트북 생성
BigQuery Studio에서 바로 생성이 가능하다.

처음 생성하면 아래와 같이 BigQuery 데이터를 불러오는 예제가 있을 것이다. Example2를 보면 bigframes를 통해 불러오는 방법도 친절히 나와있다. 여기선 이 방식을 사용할 것이다.
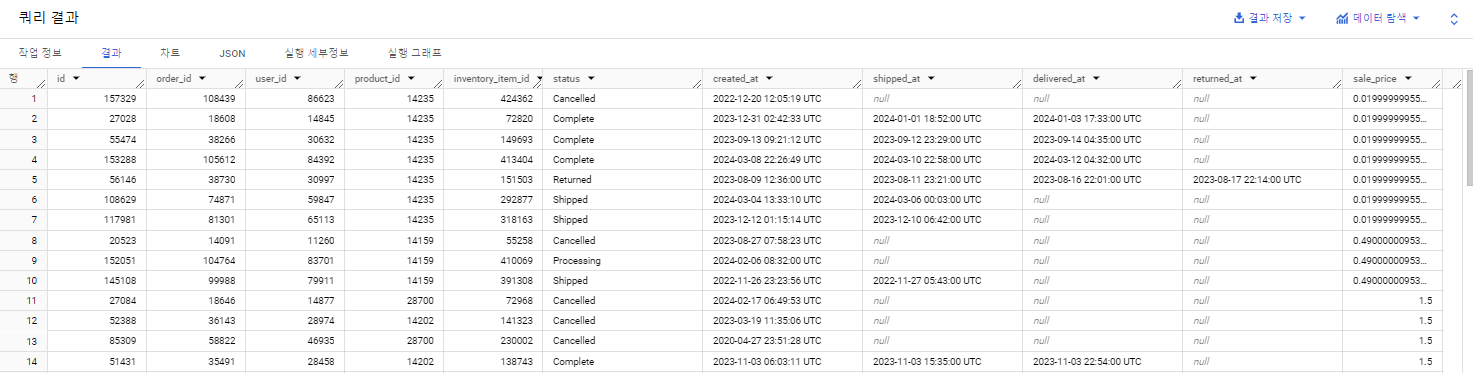
데이터 전처리
사용할 데이터는 BigQuery Public Data이고 아래와 같이 구성되어 있는 전자상거래 데이터이다.
(로컬에서 작업할 경우 pip install bigframes로 패키지를 설치해주고 사용하면 된다.)
import bigframes.pandas as bpd
df = bpd.read_gbq("bigquery-public-data.thelook_ecommerce.order_items")
# 데이터프레임을 특정 열로 제한
df = df[["user_id", "order_id", "sale_price", "created_at", "status"]].rename(columns={"created_at": "order_created_date"})
# 데이터셋을 1년간의 데이터로 제한
df = df[df["order_created_date"] > "2022-01-01"]
df = df[df["order_created_date"] < "2023-01-01"]
# 고객당 주문 수 계산
count_orders = df.groupby(["user_id"])["order_id"].count()
# 고객당 평균 지출액 계산
average_spend = df.groupby(["user_id"])["sale_price"].mean()
# 고객당 총 반품된 주문 수 계산
df["returned"] = df["status"] == "Returned"
returned = df.groupby(["user_id"])["returned"].sum()
# 고객당 수익률 계산
return_ratio = returned / count_orders
# ML모델 개발을 위한 데이터프레임 컴파일
df_customer = count_orders.rename("count_orders").to_frame()
df_customer["average_spend"] = average_spend
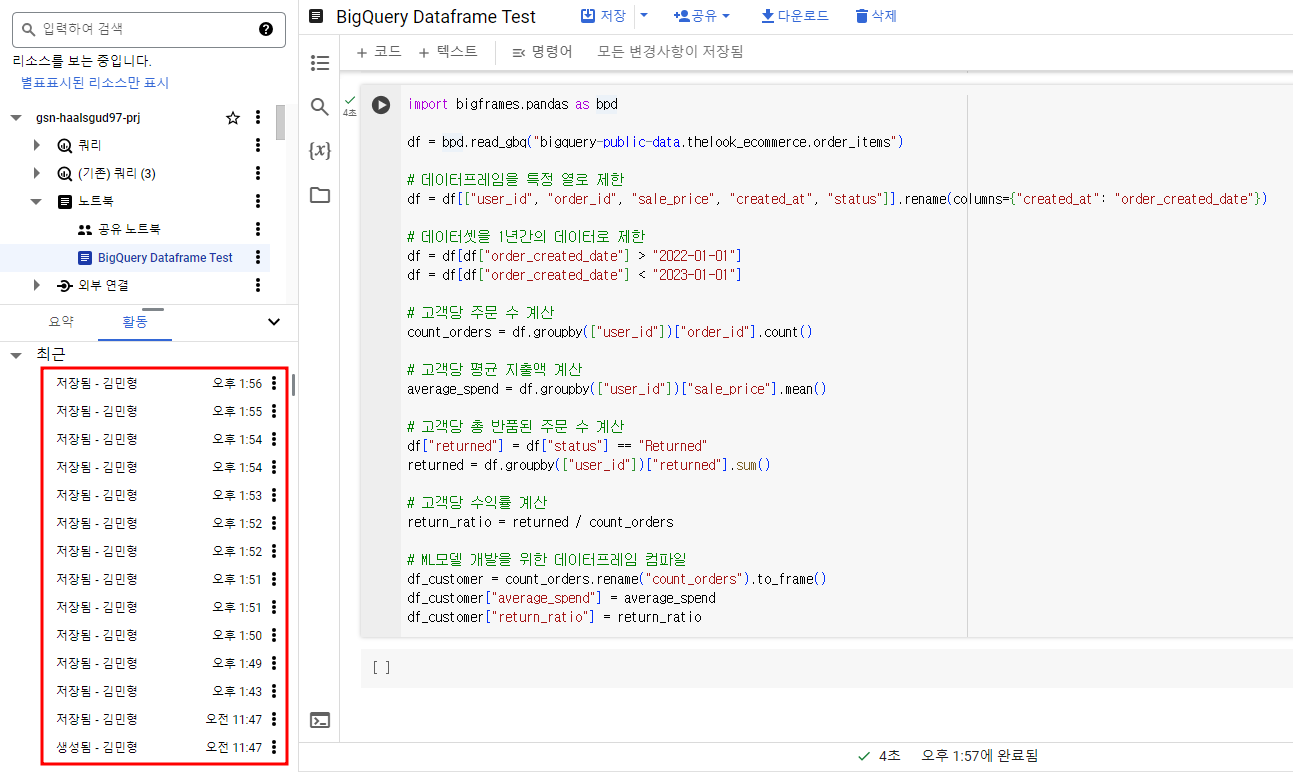
df_customer["return_ratio"] = return_ratioBigQuery Studio에서 확인.
BigQuery 노트북의 또 다른 좋은 점은 코드를 입력하고 지울 때마다 자동으로 저장이 되는데 그 버전 관리를 BigQuery에서 알아서 다 해준다...!!
데이터 분석
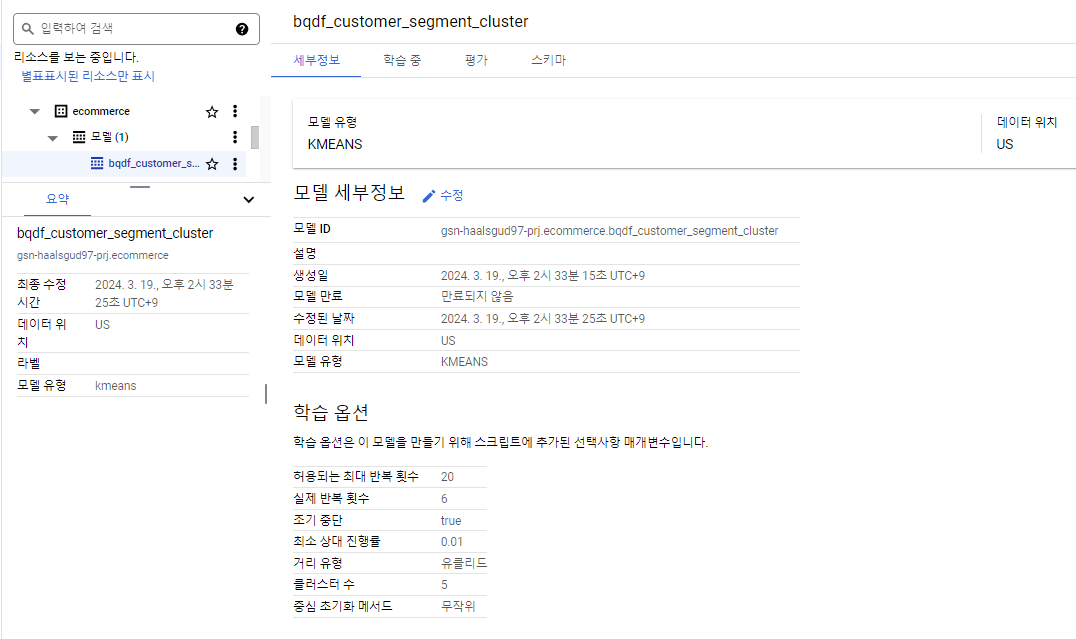
K-means Cluster 모델 생성
(US 멀티리전으로 BigQuery 데이터셋은 미리 만들어둬야 한다.)
from bigframes.ml.cluster import KMeans
from bigframes.ml.model_selection import train_test_split
# 트레이닝, 테스트 데이터셋으로 분할
df_customer = df_customer.dropna()
train_X, test_X = train_test_split(df_customer, test_size = 0.2)
# train_X = train_X.drop(columns = ["user_id"])
# K-Means cluster 모델 생성
kmeans = KMeans(n_clusters = 5)
kmeans.fit(train_X)
# 빅쿼리에 모델 저장
kmeans.to_gbq(f"{PROJECT_ID}.{DATASET_NAME}.{MODEL_NAME}", True)BigQuery Studio에서 확인.
실제로 BigQuery ML을 통해 생성한 것과 같이 BigQuery Studio에서 확인할 수 있는데.. 단 3줄의 코드밖에 소요되지 않았다.
시각화
scatterplot 차트로 K-means cluster를 시각화해보자.
'days_since_last_order'를 'average_spend'로 차트화하고 모델에서 생성된 segment/cluster_id별로 색상을 지정할 것이다.
#########################
#Plot K-Means clusters
#########################
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Import K-Means predictions to dataframe
segments_df = kmeans.predict(df_customer)
segments_df = segments_df.rename(columns={'CENTROID_ID': 'segment_id'})
segments_pd = segments_df.sample(frac=0.2, random_state=1).to_pandas()
g = sns.lmplot(x='count_orders', y='average_spend', data=segments_pd, fit_reg=False, hue='segment_id', palette='Set2', height=7, aspect=2)
g = (g.set_axis_labels('Count Orders','Average Spend ($)', fontsize=15).set(xlim=(0,10),ylim=(0,400)))
plt.title('Attribute Grouped by K-means Cluster', pad=20, fontsize=20)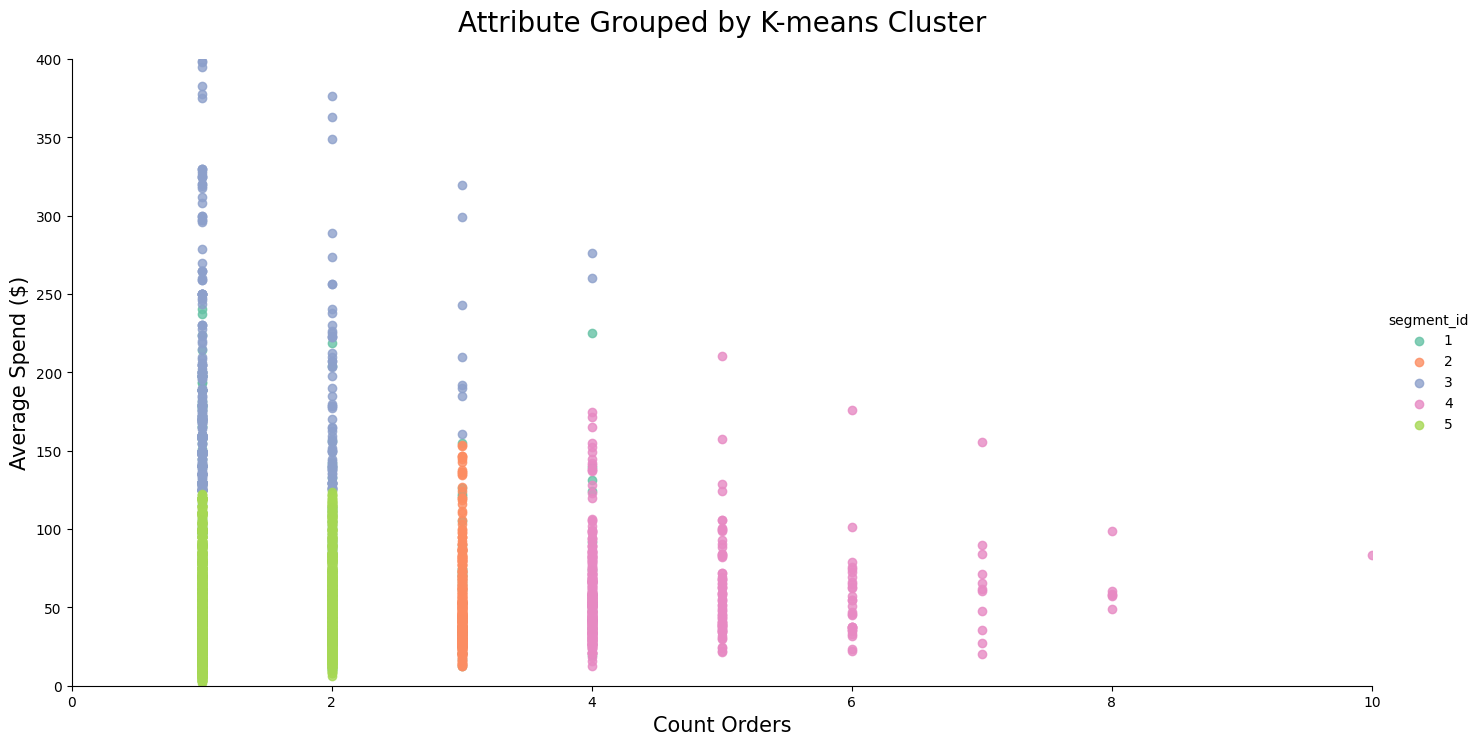
이제 이 클러스터에 대한 통계를 요약한 다음 해당 데이터를 갖고 뒤에서 생성형 AI를 활용해 마케팅 전략을 세워볼 것이다.
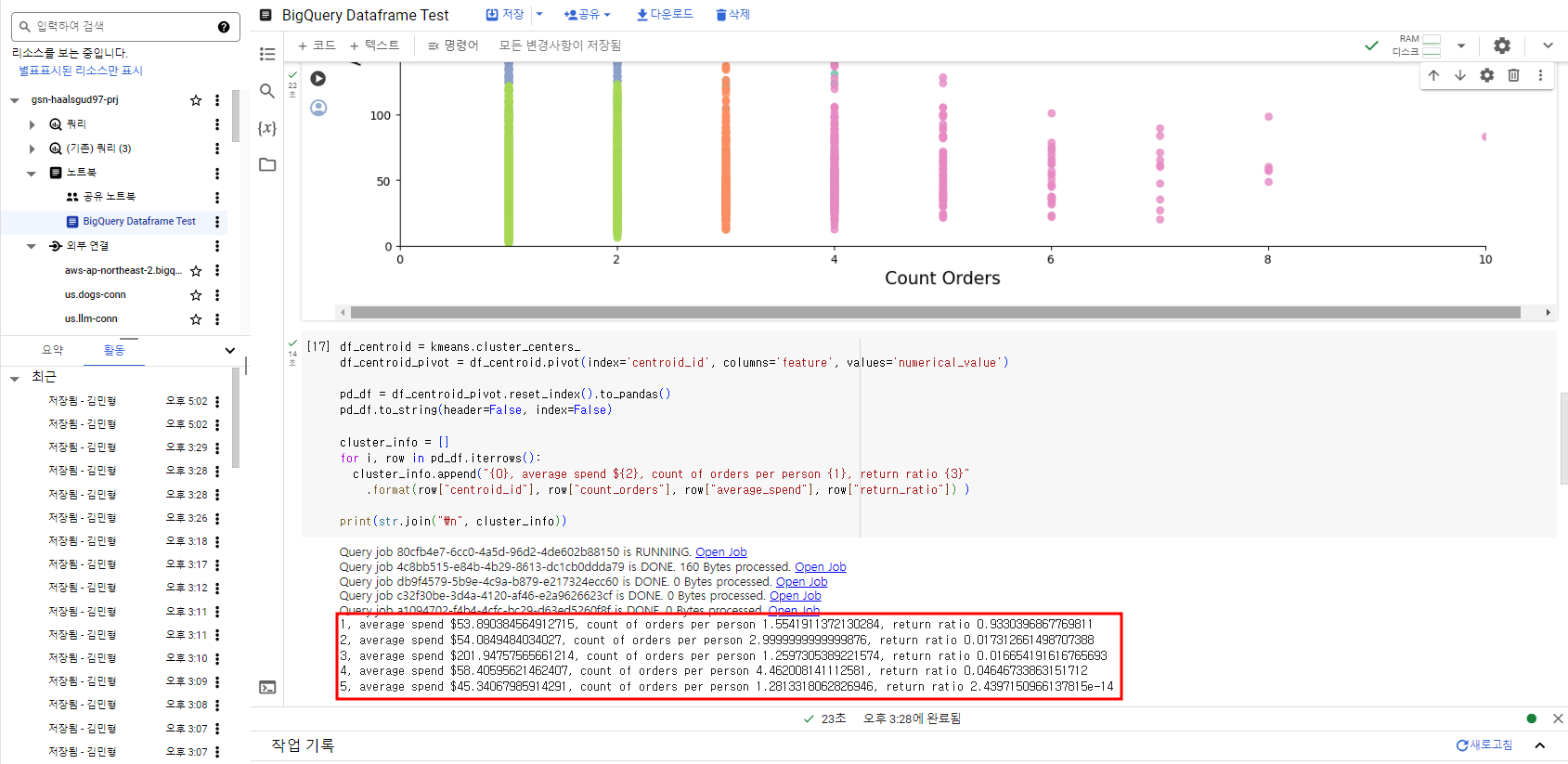
통계 요약
df_centroid = kmeans.cluster_centers_
df_centroid_pivot = df_centroid.pivot(index='centroid_id', columns='feature', values='numerical_value')
pd_df = df_centroid_pivot.reset_index().to_pandas()
pd_df.to_string(header=False, index=False)
cluster_info = []
for i, row in pd_df.iterrows():
cluster_info.append("{0}, average spend ${2}, count of orders per person {1}, return ratio {3}"
.format(row["centroid_id"], row["count_orders"], row["average_spend"], row["return_ratio"]) )
print(str.join("\n", cluster_info))cluster_info 확인
생성형 AI 적용
먼저 생성형 AI를 적용하기 위해선 BigQueryML의 ML.GENERATE_TEXT나 ML.GENERATE_TEXT_EMBEDDING 함수를 사용할 때도 마찬가지였던 것처럼 connection을 만들어줘야 한다.
Python Client Library - BigQuery DataFrames GeminiTextGenerator 링크에서 보면 알 수 있듯이 필요한 파라미터에 connection_name이 있다.

Connection 생성


연결 유형을 Vertex AI 원격 모델, 원격 함수, BigLake로 설정하고 ID를 지정해주어 연결을 생성한다.
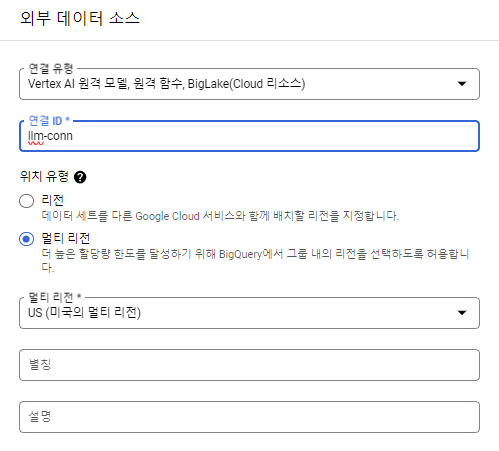
이제 이 connection을 통해 Vertex AI의 모델들을 활용할 수 있다.
from google.cloud import bigquery_connection_v1 as bq_connection
from bigframes.ml.llm import GeminiTextGenerator
CONNECTION = "<앞서 만들어준 connection 이름>"
connection_name = f"{PROJECT_ID}.{LOCATION}.{CONNECTION}"
session = bpd.get_global_session()
# BigQuery Connection 불러오기 (Request Parameter 설정)
client = bq_connection.ConnectionServiceClient()
new_conn_parent = f"projects/{PROJECT_ID}/locations/{LOCATION}"
exists_conn_parent = f"projects/{PROJECT_ID}/locations/{LOCATION}/connections/{CONNECTION}"
cloud_resource_properties = bq_connection.CloudResourceProperties({})
request = client.get_connection(
request=bq_connection.GetConnectionRequest(name=exists_conn_parent)
)
CONN_SERVICE_ACCOUNT = f"serviceAccount:{request.cloud_resource.service_account_id}"Gemini를 활용한 마케팅 전략 세우기
model = GeminiTextGenerator(session=session, connection_name=connection_name)
clusters = str.join("\n", cluster_info)
prompt = f"""
You're a creative brand strategist, given the following clusters, come up with creative brand persona, a catchy title, and next marketing action, explained step by step.
The marketing strategy should be written in Korean.
Clusters:
{clusters}
For each Cluster:
* Title:
* Persona:
* Next Marketing Step:
"""
prompt_df = bpd.read_pandas(pd.DataFrame({'prompt': [prompt]}))
pred = model.predict(prompt_df, max_output_tokens=2048, temperature=0.4, top_p=0.8, top_k=40)
print(pred.iloc[0,0])위의 코드를 보면 알겠지만 생성형 AI 모델을 가져오는 것도 코드 단 한 줄이면 됐다.
BigQuery Studio에서 확인.

[BigQuery DataFrames - Efficient, Scalable Data Processing 참고]
