CSV에서 데이터 수집
아래 csv파일 로컬로 다운로드
products.csv
ecommerce Dataset생성, 테이블 생성 클릭
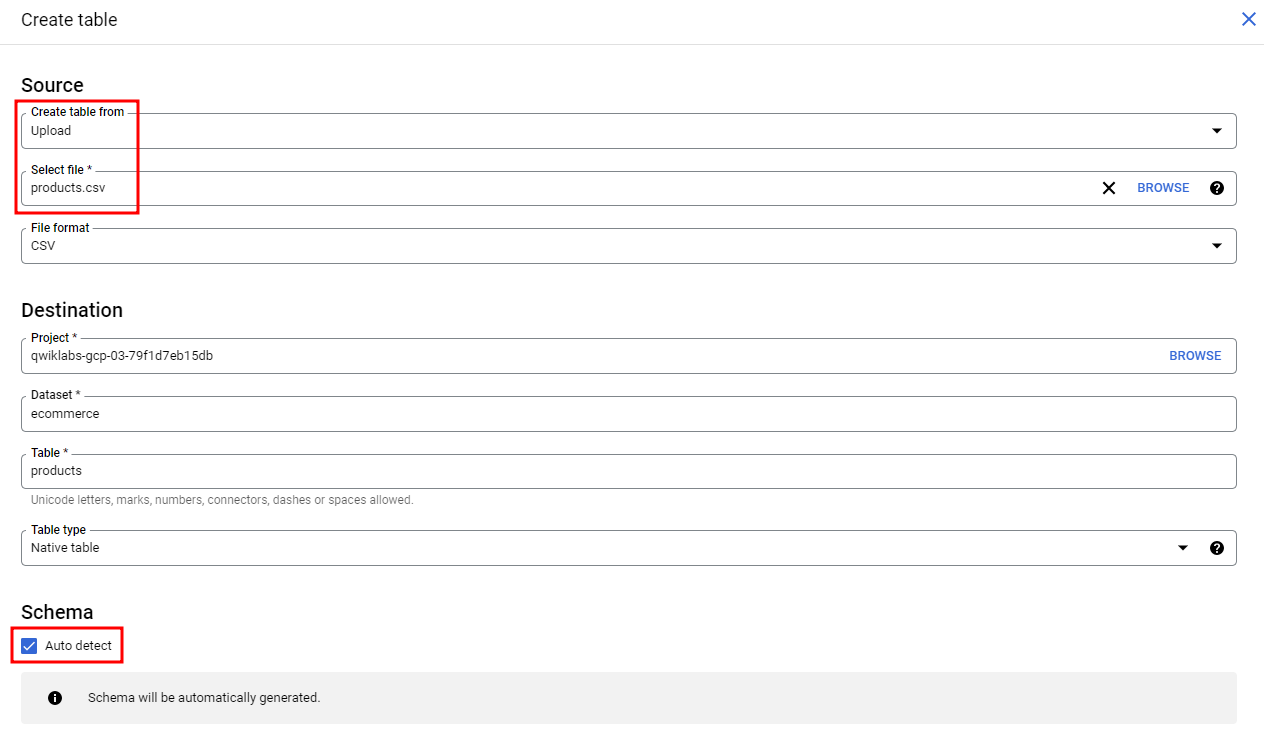
로드된 데이터 탐색
stockLevel이 가장 높은 상위 5개 제품 나열
#standardSQL
SELECT
*
FROM
ecommerce.products
ORDER BY
stockLevel DESC
LIMIT 5Cloud Storage에서 데이터 수집
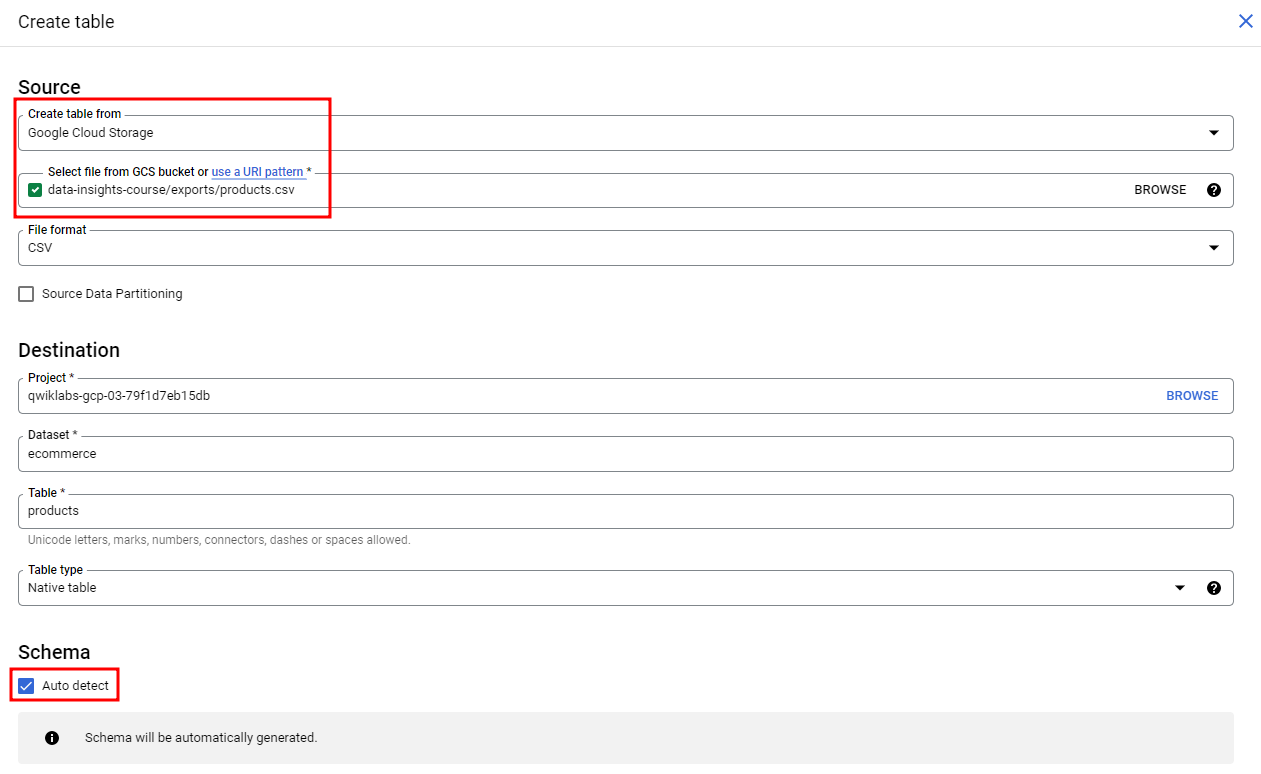
csv파일이 있는 cloud storage 경로를 넣어주어 생성
Google 스프레드시트에서 데이터 수집
재고 회전율을 기반으로 가장 재입고가 필요한 제품과 재공급 속도를 표시하는 쿼리 실행
#standardSQL
SELECT
*,
SAFE_DIVIDE(orderedQuantity,stockLevel) AS ratio
FROM
ecommerce.products
WHERE
# include products that have been ordered and
# are 80% through their inventory
orderedQuantity > 0
AND SAFE_DIVIDE(orderedQuantity,stockLevel) >= .8
ORDER BY
restockingLeadTime DESC쿼리 결과 저장

우린 Google 스프레드 시트에 로드할 것이지만 다양한 경로에 바로 로드가 가능한 것을 확인할 수 있다.
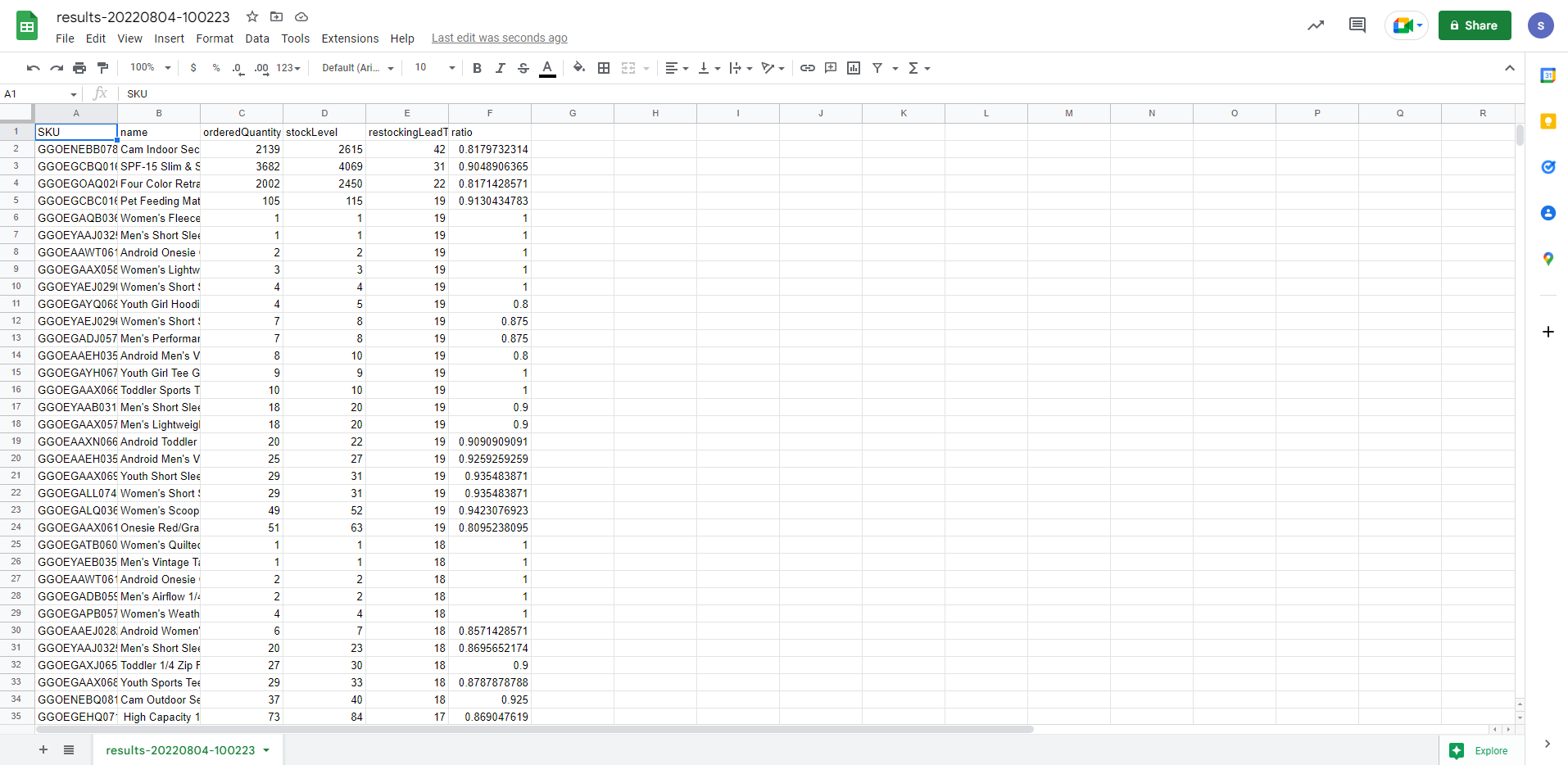
성공
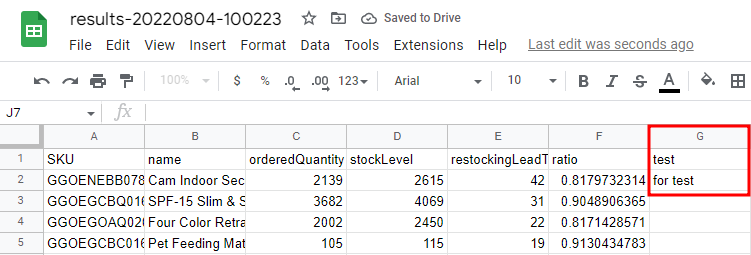
test를 위해 열 하나와 해당 값 하나를 추가해준다

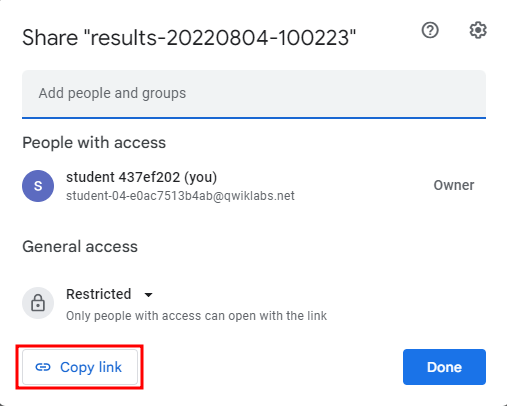
Share에서 공유 가능한 링크를 복사해 두고 빅쿼리로 돌아온다.
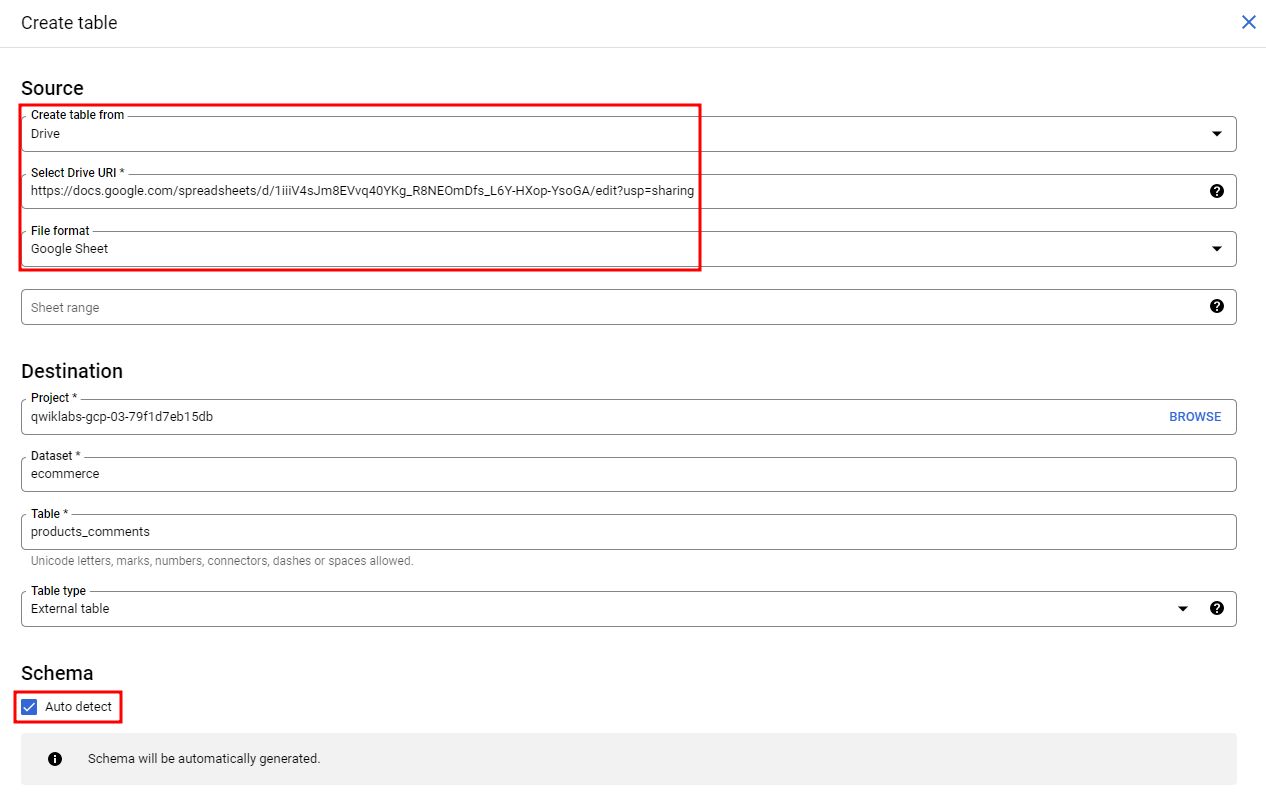
하지만 여기서 고급 옵션에서 Header rows to skip 1을 해주지 않으면

이렇게 0 1 2 3 4열이 스키마로 잡힌다.

아까와 같은 설정에서 Header rows to skip 1 추가
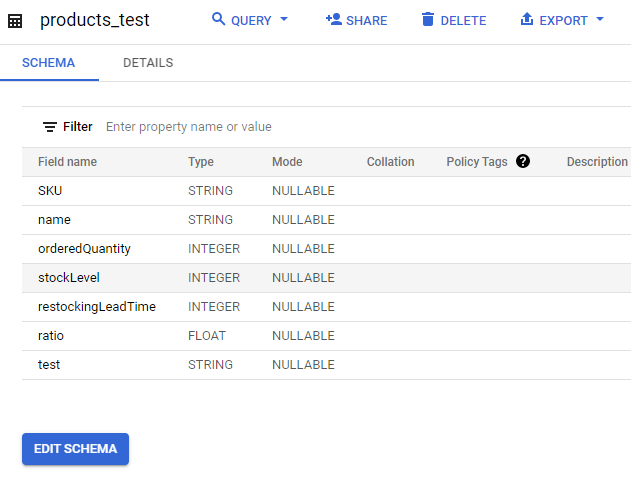
스키마가 잘 나온것을 볼 수 있고 추가해준 test열도 확인할 수 있다.
새 쿼리 작성
#standardSQL
SELECT * FROM `qwiklabs-gcp-03-79f1d7eb15db.ecommerce.products_test` WHERE test IS NOT NULL
다시 스프레드시트로 돌아가서 설명을 하나 더 추가하고 다시 쿼리를 실행
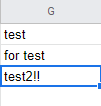

실시간으로 바로 반영되는 것을 확인할 수 있다.

AI Solutions Architect