ARRAY
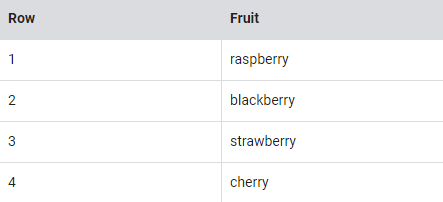
일반적으로 SQL에서는 아래 과일 목록과 같이 각 행에 대해 단일 값을 갖는다.
상점에 있는 각 사람의 과일 품목 목록을 원하면?
아래와 같이 볼 수 있다.
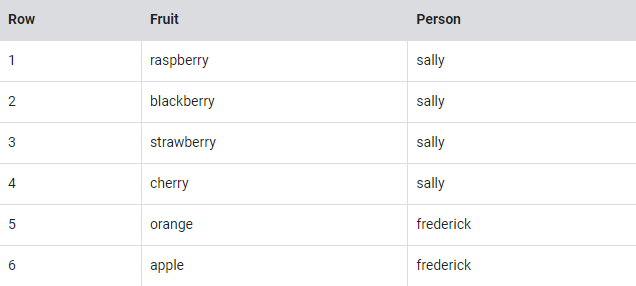
기존의 관계형 데이터베이스에서는 이름의 반복을 보고 즉시 위의 테이블을 과일 항목과 사람이라는 두 개의 개별 테이블로 분할하는 것을 생각할 것이다.
이 프로세스를 정규화라고 하고, 이것은 MySQL과 같은 트랜잭션 데이터베이스에 대한 일반적인 접근 방식이다.
데이터 웨어하우징의 경우 종종 반대 방향(비정규화)으로 이동하여 많은 개별 테이블을 하나의 큰 보고 테이블로 가져오기도 한다.
하지만 모든 데이터를 하나의 거대한 테이블에 저장하면 아래와 같은 문제들이 있을 수 있다.
- 테이블 행 크기가 기존 데이터베이스에 너무 클 수 있음
- 값(ex) 고객 이메일)을 변경하면 다른 많은 행(ex) 모든 주문)에 영향을 줄 수 있음.
- 세분화 수준이 다른 데이터는 덜 세분화된 필드가 반복되므로 보고 문제가 발생할 수 있음.
반복되는 필드를 사용하여 하나의 테이블에 서로 다른 세분화 수준으로 데이터를 저장할 수 있다.
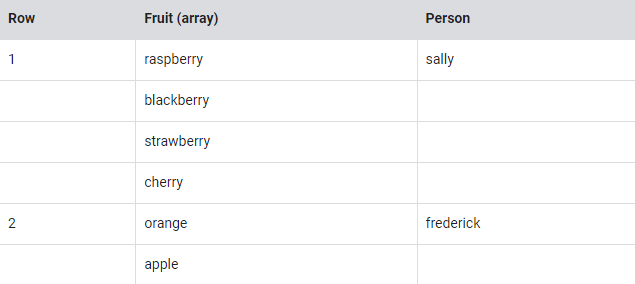
- 행은 딱 두줄
- 한 행에 과일에 대한 여러 필드 값이 있다.
- 사람은 그 사람이 가고 있는 모든 과일 필드 값과 연결된다.
위의 테이블은 쉽게 해석하면 아래와 같이 생각하면 된다.

빅쿼리에서 아래의 쿼리 수행
#standardSQL
SELECT
['raspberry', 'blackberry', 'strawberry', 'cherry'] AS fruit_array다음으로 아래의 쿼리 실행
#standardSQL
SELECT
['raspberry', 'blackberry', 'strawberry', 'cherry', 1234567] AS fruit_array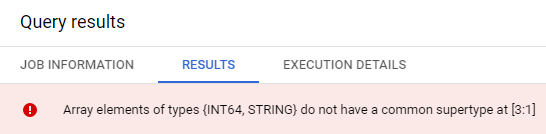
에러가 날 것이다. 이유는 배열의 데이터는 모두 같은 유형이어야 하기 때문이다.
아래의 쿼리 실행
#standardSQL
SELECT person, fruit_array, total_cost FROM `data-to-insights.advanced.fruit_store`;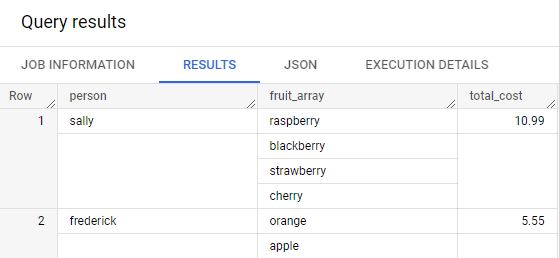
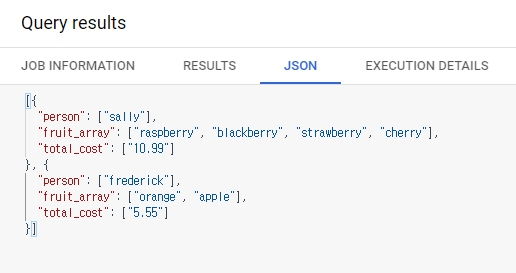
JSON 탭으로 중첩된 구조를 볼 수 있다.
fruit_store Dataset 생성
fruit_details 테이블 생성

여기서 소스로 사용하는 JSON 파일은 바로 위에서 쿼리해준 결과에서 확인한 JSON과 동일한 파일이다.
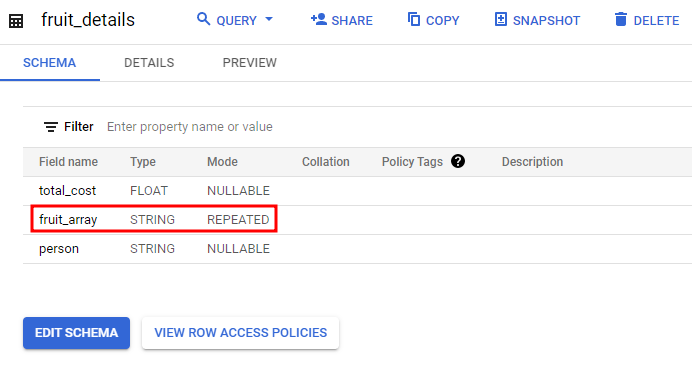
BigQuery에서는 ARRAY을 REPEATED 필드라고 한다.
ARRAY_AGG
아래의 쿼리 실행
SELECT
fullVisitorId,
date,
v2ProductName,
pageTitle
FROM `data-to-insights.ecommerce.all_sessions`
WHERE visitId = 1501570398
ORDER BY date

111개의 행이 나온다.
fullVisitorId와 date가 중복되므로 GROUP BY를 써서 묶어주고, ARRAY_AGG를 써서 products_viewed와 pages_viewed를 집계해줄 것이다.
SELECT
fullVisitorId,
date,
ARRAY_AGG(v2ProductName) AS products_viewed,
ARRAY_AGG(pageTitle) AS pages_viewed
FROM `data-to-insights.ecommerce.all_sessions`
WHERE visitId = 1501570398
GROUP BY fullVisitorId, date
ORDER BY date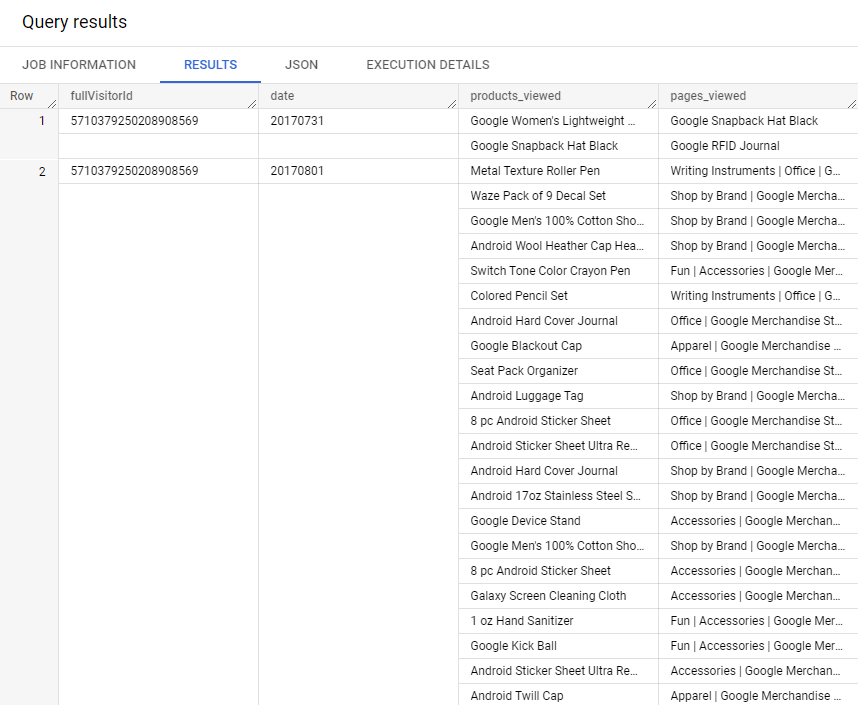
STRUCT
STRUCT에 대해 생각하는 가장 쉬운 방법은 개념적으로 기본 테이블에 조인된 별도의 테이블처럼 생각하는 것이다.
- 하나 이상의 필드를 가짐
- 각 필드에 대해 동일하거나 다른 데이터 유형
- STRUCT는 별칭(~.~)이 주어지며 개념적으로 기본 테이블 내부의 테이블로 생각할 수 있다.
google_analytics_sample 공개 데이터세트 탐색
BigQuery에서는 STRUCT를 RECORD 필드라고 한다.

한 STRUCT 안에 중첩된 STRUCT를 또 가질 수 있다.

단일 테이블에 32개의 STRUCT가 있으므로 JOIN을 수행하지 않고도 다음과 같은 쿼리를 실행할 수 있다.
SELECT
visitId,
totals.*,
device.*
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
WHERE visitId = 1501570398
LIMIT 10.*구문은 빅쿼리가 해당 STRUCT의 모든 필드를 반환하도록 한다.

#standardSQL
SELECT STRUCT("Rudisha" as name, 23.4 as split) as ru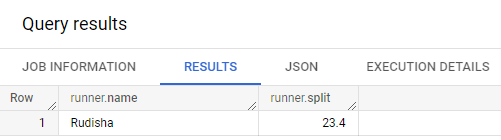
STRUCT 내에 중첩된 필드가 있는 것이고 name, split은 runner의 하위집합이다.
주자가 단일 레이스에 대해 여러 split time을 가지고 있는 경우라면?
각 split time을 ARRAY의 요소로 저장
#standardSQL
SELECT STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as splits) AS runner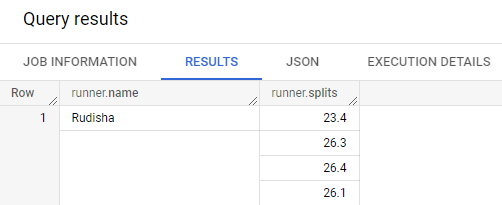
- STRUCT는 내부에 중첩된 여러 필드 이름과 데이터 유형을 가질 수 있다.
- ARRAY는 STRUCT 내부의 필드 유형 중 하나일 수 있다.
ARRAY & STRUCT
Racing Dataset 성성
race_results 테이블 생성
스키마
[
{
"name": "race",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "participants",
"type": "RECORD",
"mode": "REPEATED",
"fields": [
{
"name": "name",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "splits",
"type": "FLOAT",
"mode": "REPEATED"
}
]
}
]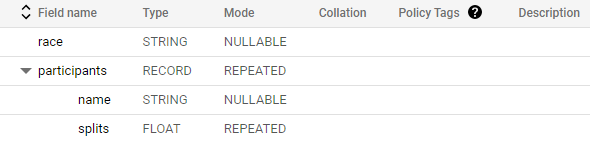
participants는 RECORD이므로 STRUCT
participants.splits필드는 상위 participants STRUCT 내부의 실수.
ARRAY를 나타내는 REPEATED 모드가 있다. 해당 ARRAY의 값은 단일 필드 내부의 여러 값이므로 중첩 값이라고 한다.
아래의 쿼리 실행
#standardSQL
SELECT * FROM Racing.race_results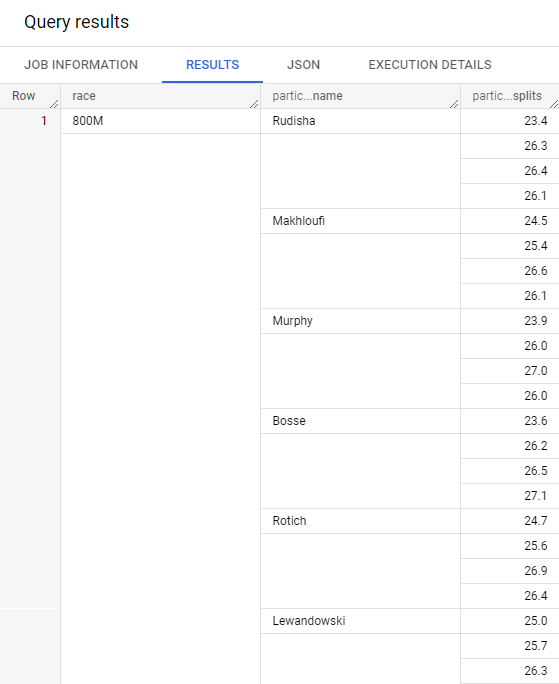
하나의 행이 나온다.
race와 name을 나열하려면?
아래의 쿼리를 실행해보자
#standardSQL
SELECT race, participants.name
FROM Racing.race_results
이런 오류가 난다
원하는 건 아래처럼 나오게 하는 것이다.

기존의 관계형 데이터베이스에서 race 테이블이 있다고 생각하고, participants 테이블이 있다고 생각하자.
두 테이블에서 정보를 얻기 위해선 JOIN을 해야한다.
CROSS JOIN을 해서 나타내보자
#standardSQL
SELECT race, participants.name
FROM Racing.race_results
CROSS JOIN
race_results.participants # full STRUCT name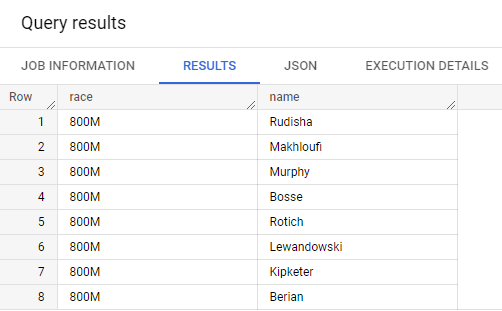
#standardSQL
SELECT race, participants.name
FROM Racing.race_results AS r, r.participants좀 더 간단한 쿼리로 똑같이 나타낼 수 있다.
UNNEST로 ARRAY 풀기
STRUCT(및 ARRAY)는 해당 요소에 대해 작업하기 전에 압축되어 있는 것을 풀어야 한다.
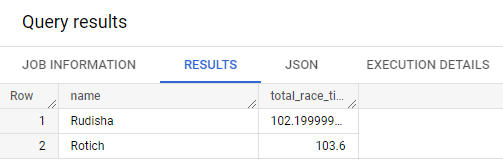
이름이 R로 시작하는 레이서의 총 레이스 시간을 나열하는 쿼리 작성
#standardSQL
SELECT
p.name,
SUM(split_times) as total_race_time
FROM Racing.race_results AS r
, UNNEST(r.participants) AS p
, UNNEST(p.splits) AS split_times
WHERE p.name LIKE 'R%'
GROUP BY p.name
ORDER BY total_race_time ASC;FROM 절 뒤에 데이터 소스로 STRUCT와 STRUCT 내의 ARRAY을 모두 풀어야 한다.
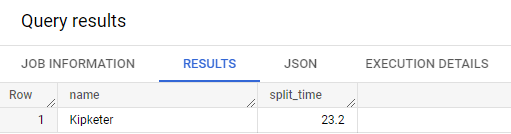
800M 경주에서 기록된 가장 빠른 랩 타임이 23.2초라는 것은 봤었지만 누구인지는 보지 못했다. 해당 결과를 나타내는 쿼리를 실행해보자
#standardSQL
SELECT
p.name,
split_time
FROM Racing.race_results AS r
, UNNEST(r.participants) AS p
, UNNEST(p.splits) AS split_time
WHERE split_time = 23.2;