기존의 하둡의 환경을 구성할 땐 마스터 노드와 작업자 노드를 연결시키는 것부터가 좀 번거로웠지만 Dataproc을 활용하면 매우 손쉬게 마스터 노드와 작업자 노드를 구성할 수 있다.
클러스터 생성
API 활성화

my-cluster라는 이름으로 클러스터를 만들어준다.
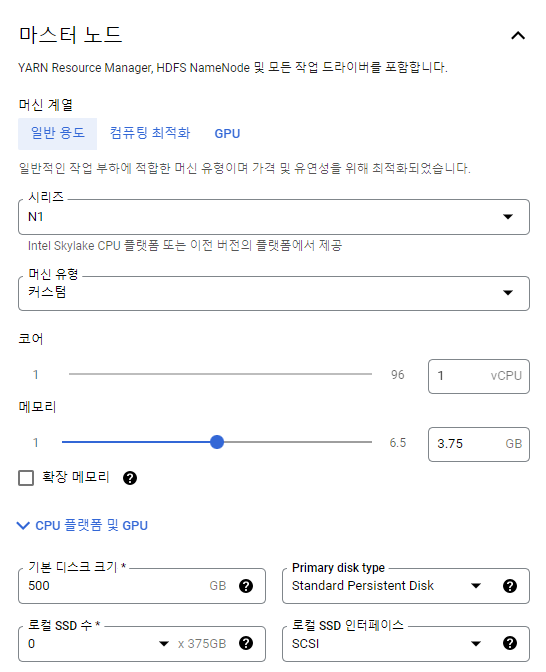
마스터 노드
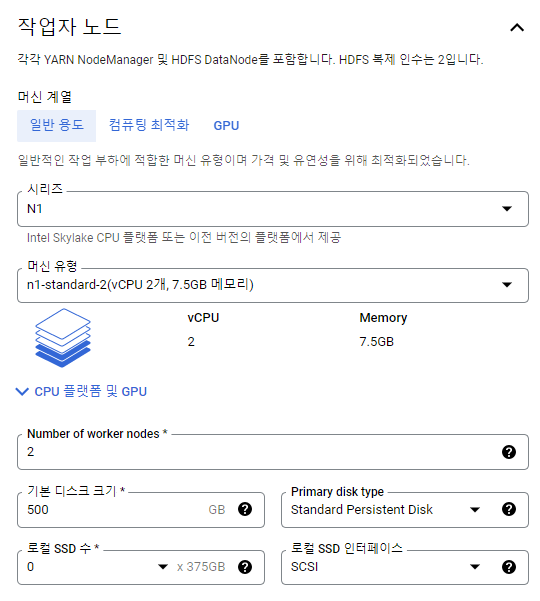
워커 노드
만약 GCP Trial Account의 경우 Dataproc 클러스터를 만들 때 최대 8개의 CPU를 사용할 수 있다.
이 말은 만약 마스터 노드의 vCPU 1개, 워커 노드의 vCPU 4개 x2대일 때 = vCPU가 9개이므로 에러가 날 것이다.
Trial Account는 아니지만 위에처럼 스펙을 설정했다.
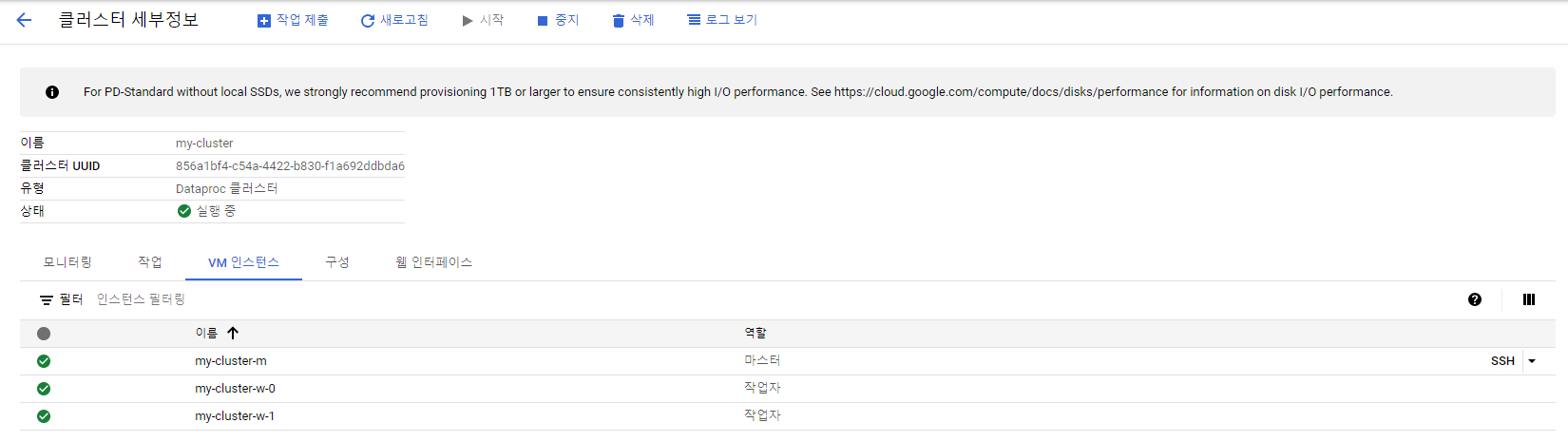
클러스터 생성 확인.
클러스터 웹 인터페이스 접속
내 PC에서 Dataproc Cluster에 접근할 수 있게 해주기 위해 방화벽 설정을 할 것이다
ip4.me에 접속하여 내 ip 확인
아래의 나오는 내 ip를 복사해둔다
방화벽 생성
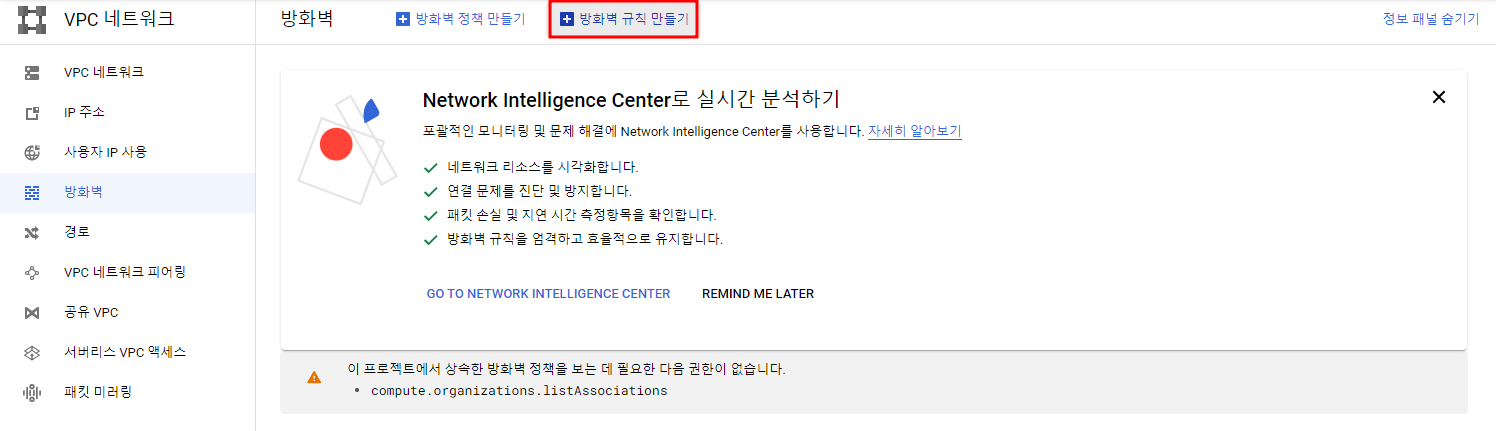
default vpc에 클러스터를 생성했고 default vpc 내의 모든 인스턴스에서 내 ip로부터 8088,9870포트로의 접근을 허용해준다.



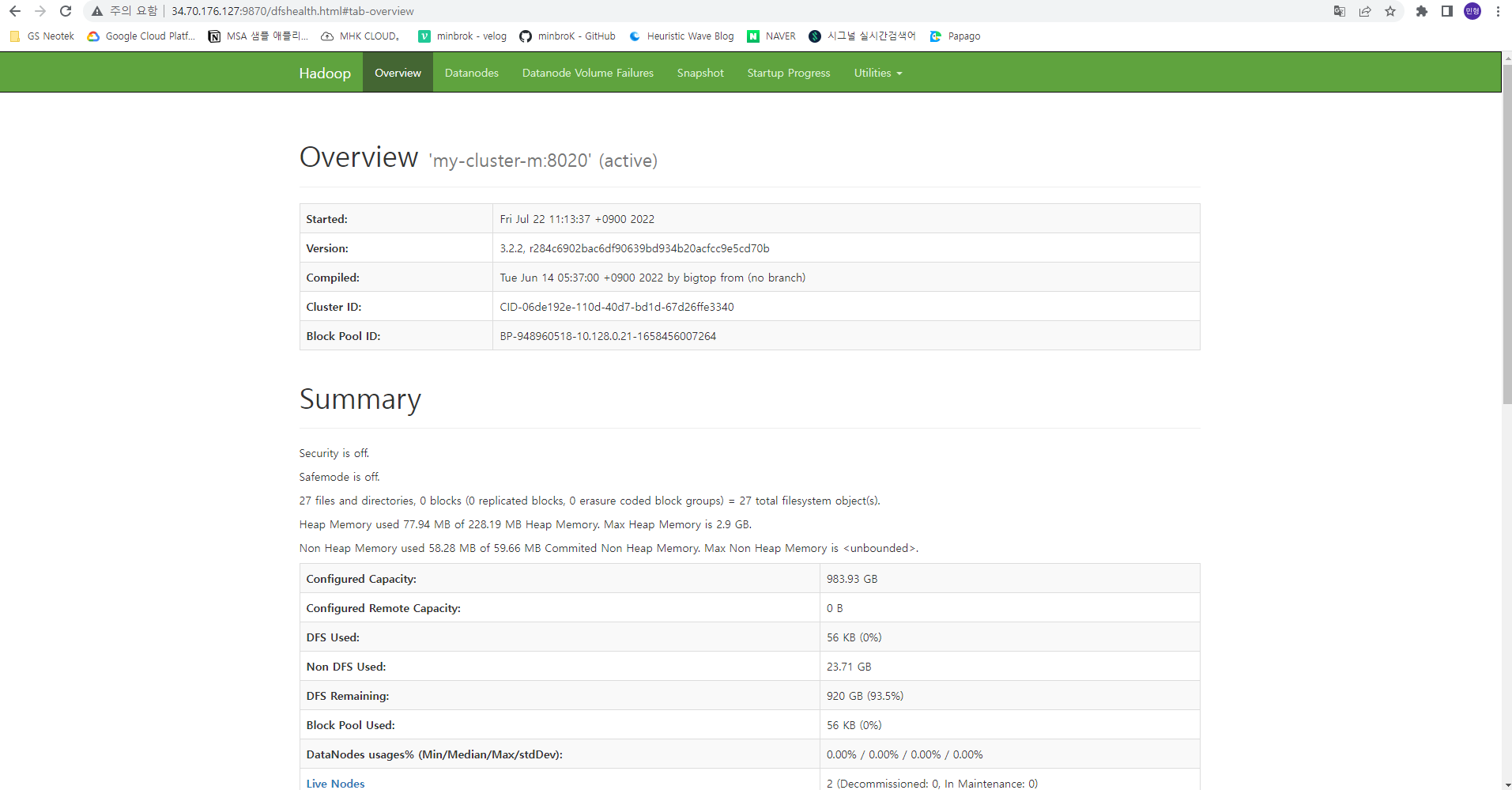
HDFS Namae Node
<master노드 외부ip>:9870
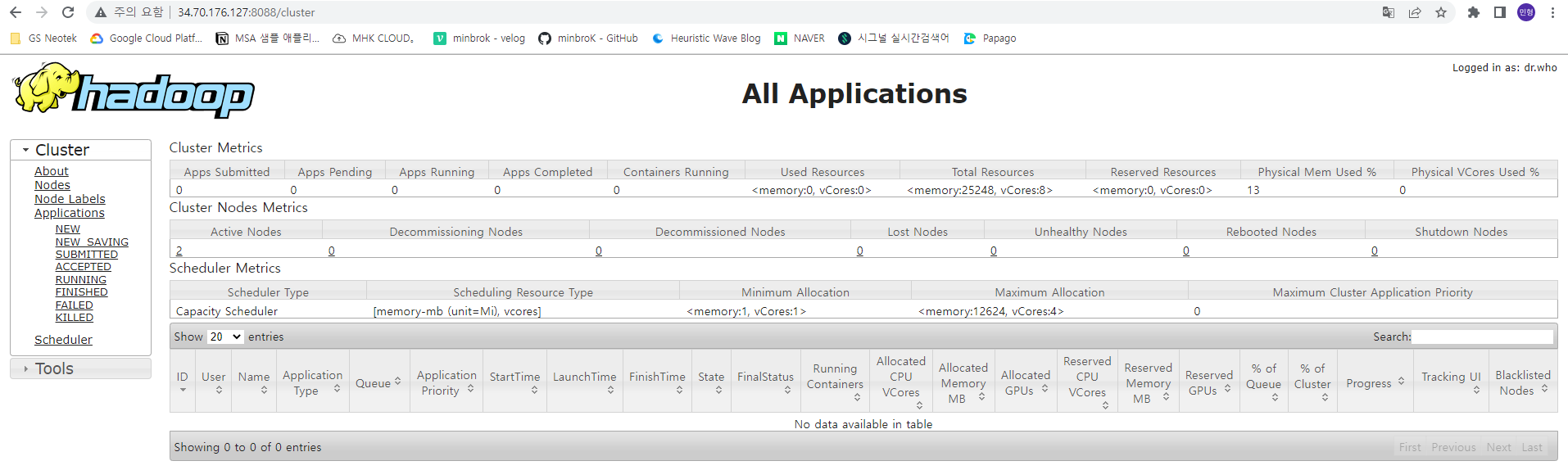
YARN Resource Manager
<master노드 외부ip>:8088
PySpark로 WordCount 해보기
Dataproc 관련 파일을 넣어줄 Cloud Storage 버킷 생성

input파일과 WordCount파일을 버킷에 업로드 해준다.
input.txt
In Spark, a DataFrame is a distributed collection of data organized into named colums. Users can use DataFrame API to perform various relational operations on both external data sources and Spark's built-in distributed collections without providing specific procedures for processing data. Also, programs based on DataFrame API will be automatically optimized by Spark's built-in optimizer, Catalyst.
WordCount.py
from pyspark import SparkContext
sc = SparkContext()
text_file = sc.textFile("gs://mhkim-dataproc-sample/input.txt")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
for data in counts.collect():
print(data)공백을 기준으로 나누어서 (단어, 1) 형태로 만든 뒤, 단어 기준으로 개수를 합쳐서 개별 단어에 대한 Word Count를 하는 코드.
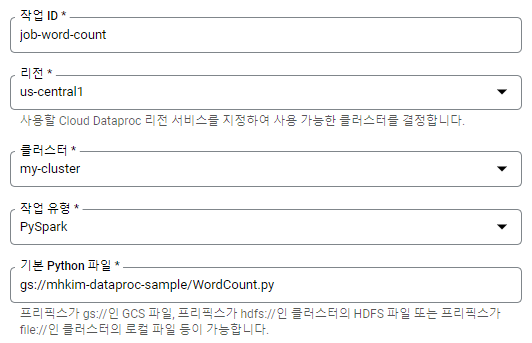
Dataproc에 작업 제출
결과 확인

