Dataproc

배치처리, 쿼리, 스트리밍,머신러닝을 managed해주는 구글 클라우드의 Hadoop상품이라고 생각하면 된다.
Hadoop
각 노드에 있는 디스크를 하나인 것처럼 클러스터링하여 사용할 수 있는것
HDFS(Hadoop Distributed File System)에 데이터가 분산 저장된다.
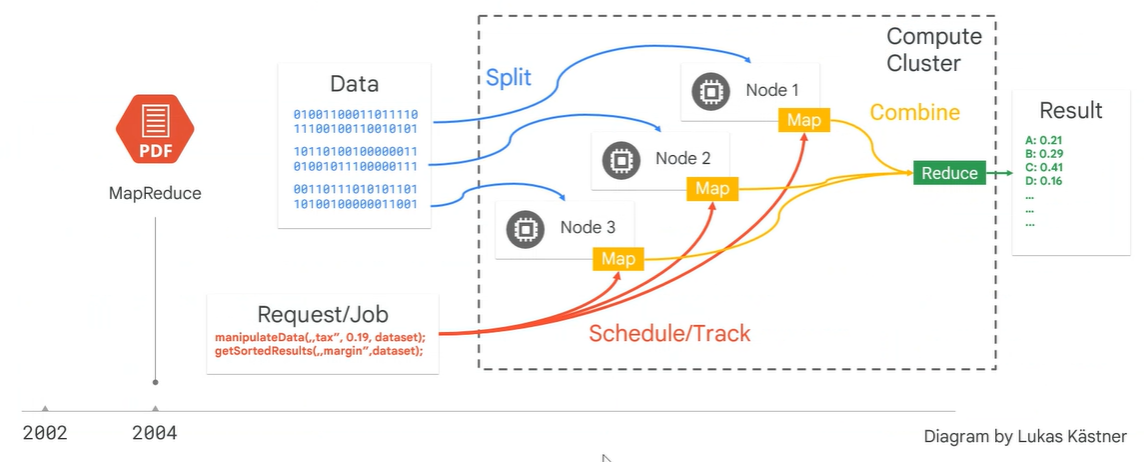
대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 방법으로, 여러 노드에 태스크를 분배하는 것을 맵리듀스라고 한다
Dataproc cluster 아키텍처
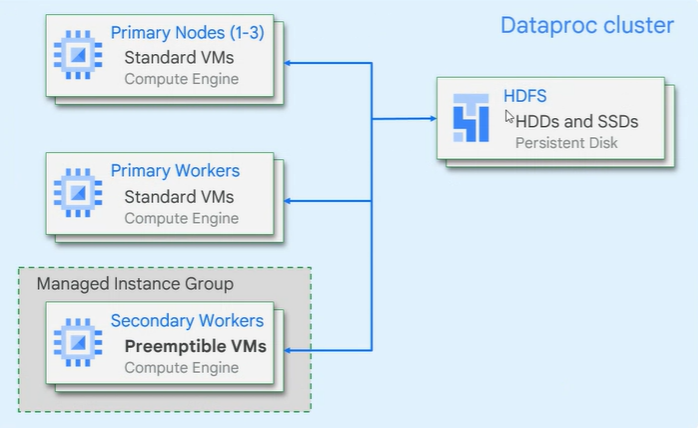
HDFS는 저장소 역할
여러노드가 있을 때 이 노드들을 제어해주는 master node가 있어야 한다
(마스터노드는 여기서 보이지 않는다. 실제 일을 하는 워커 노드만이 나타나있다.)
임시적으로 노드를 더 많이 늘린다음 작업을 할 수도 있다. 이러한 노드를 Preemptible VMs라고 한다.
안쓰고 있는 자원을 우리가 짧게 가져다 쓰는 것. 하지만 fail이 났을 때 큰 문제가 생기는 상황에선 쓰지 않는 것이 낫다.
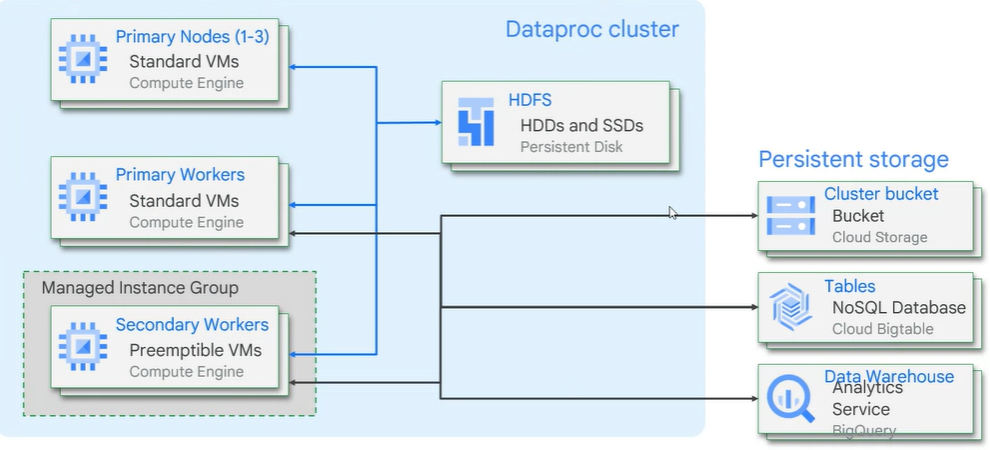
사용할 때 계속 클러스터를 띄워놓을 필요가 없고 작업이 끝나고 나면 해당 노드를 제거하면 된다.
하지만 필요한 데이터가 HDFS에 저장되어 있었다? > 클러스터가 제거되면 HDFS도 휘발되서 사라진다.
때문에 가능하면 이러한 데이터들은 Cloud Storage를 사용하여 외부에 저장하는게 바람직하다.
영구적으로 저장해야하는 경우에는 외부에 저장하는걸 추천한다.
원래 맵리듀스는 로컬에 잇는 데이터를 가지고 분산처리를 하기 위한 것
Node1 2 3의 데이터는 HDFS에 저장이 되어 있는 것인데 데이터를 GCS로 빼서 GCS를 통해 처리를 하게 파이프라인을 만드는 것이 낫다.
구글 클라우드 스토리지를 영구 데이터 스토리지로 사용하라는 뜻, 일부 케이스에만 HDFS를 사용하라는 뜻(로컬에 캐싱을 시켜놓고 재활용할 때만 사용 )
코드가 익숙하지 않다면 진입장벽이 높다..
Dataflow

실시간 데이터 처리에서는 들어오는 데이터를 바로 읽어서 처리하는 스트리밍 프레임워크가 대세인데, 대표적인 프레임워크로는 Aapche Spark등을 들 수 있다.
구글의 DataFlow는 구글 내부의 스트리밍 프레임워크를 Apache Beam이라는 형태의 오픈소스로 공개하고 이를 실행하기 위한 런타임을 DataFlow라는 이름으로 제공하고 있는 서비스
맵리듀스 기반으로 개발됐기 때문에 Dataflow 모델은 단계적 워크플로우와 비슷하다.
Driver Program
파이프라인을 구성하는 실행 단위. Apache Beam SDK를 통한 자바 및 Python API를 제공하기 때문에 간단하고 빠르게 파이프라인을 개발할 수 있다.
Apache BEAM = Batch + strEAM
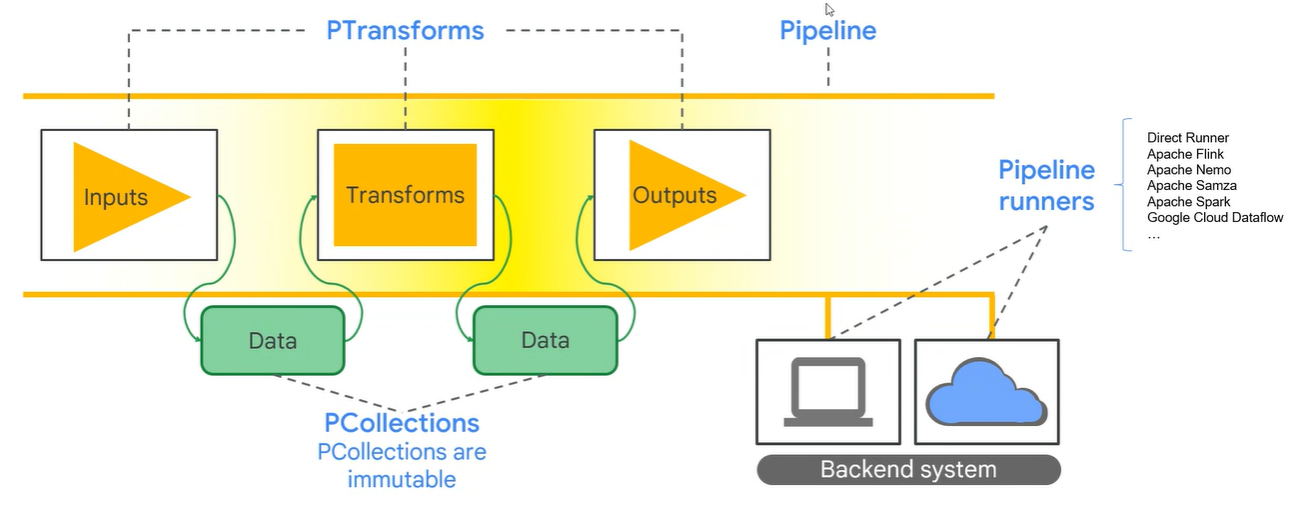
데이터는 PCollection
처리하는 것은 PTransform
처리가 되어서 나온 데이터도 PCollection
PCollection 데이터에 대한 변환은 PTransform이라고 하고 이 일련의 과정을 파이프라인이라고 한다.
PCollection
Dataflow 파이프라인이 작동하는 분산 데이터세트를 나타낸다. 일반적으로 파이프라인은 외부 데이터 원본에서 데이터를 읽어서 초기 PCollection을 생성하지만, Driver Program 내의 메모리 내 데이터에서 PCollection을 만들 수도 있다. 거기에서 PCollection은 파이프라인의 각 단계에 대한 입력과 출력
PCollection은 Dataflow 파이프라인 내에서 데이터를 저장하는 개념으로 한 번 생성되면 그 데이터는 수정이 불가능.
데이터를 변경하거나 수정하기 위해선 PCollection을 새로 생성해야 한다. PCollection은 다음과 같은 특징을 가진다.
- Element type: PCollection의 요소는 모든 유형이 될 수 있지만, 모두 동일한 유형이어야 한다. 그러나 분산 처리를 위해서는 각 개별 요소를 바이트 문자열로 인코딩할 수 있어야 한다.
- Immutability: PCollection은 변경이 불가능하기 때문에 변경을 위해서는 새로운 PCollection을 생성해야 한다.
- Random access: PCollection은 개별 요소에 대한 무작위 액세스를 지원하지 않는다.
- Size and boundedness: PCollection의 크기는 제한할 수도 있고 제한하지 않을수도 있다. 제한된 PCollection은 고정 크기의 데이터세트를 나타내지만, 제한되지 않은 PCollection은 무제한 크기의 데이터세트를 나타낸다. 보통 파일이나 데이터베이스 같은 배치 데이터 소스는 제한된 PCollection으로 만들고, Pub/Sub이나 Kafka같은 스트리밍 데이터 소스는 제한되지 않는 PCollection으로 만든다.
- Element timestamps: PCollection 각 요소에는 고유한 타임 스탬프가 있다. 각 요소의 타임스탬프는 소스에 의해 결정이 된다. Unbounded PCollection은 개별 요소가 읽히거나 추가될 때 타임 스탬프를 할당한다.
PTransform
데이터 처리 작업 또는 단계를 나타낸다. 모든 PTransform은 하나 이상의 PCollection 객체를 입력으로 가져와 해당 PCollection의 요소에 제공하는 처리 기능을 수행하고 0개 이상의 출력 PCollection 객체를 생성. 데이터를 변경할 때 사용하는 부분으로 아래 형태를 지원
| 지원 함수 | 설명 |
|---|---|
| ParDo | 데이터를 변환하거나 추출 또는 연산때 사용 |
| GroupByKey | Key-Value 형태의 컬렉션을 key 기준으로 Value를 묶어준다. |
| CoGroupByKey | 동일한 Key의 데이터세트가 여러개 있을 때 Key별로 묶어준다. |
| Combine | 데이터의 요소 및 값의 컬렉션을 결합하기 위해 사용한다. |
| Flattern | 여러 종류의 PCollection을 하나의 PCollection으로 합친다. |
| Partion | 큰 PCollection을 분할할 때 사용 |
Unbounded Data(스트리밍 데이터) 처리
스트리밍 데이터 같은 경우에는 데이터가 끊이지 않고 들어오기 때문에 결과를 내보내야 하는 타이밍을 잡기 애매하다. 이를 위해서 시간을 기준으로 작업을 끊어서 처리하는데 이를 윈도잉(Windowing) 이라고 한다.
Window
스트리밍 데이터는 계속 들어오기 때문에 특정 시간 단위로 지속적으로 처리를 하고 내보내야 한다. 이때 사용하는 개념이 Window인데 크게 텀블링 Window와 홉핑 Window, 세션 Window라는 개념을 사용한다.
(Beam에서는 Fixed window, Sliding Window, Session Window라고 한다.)
-
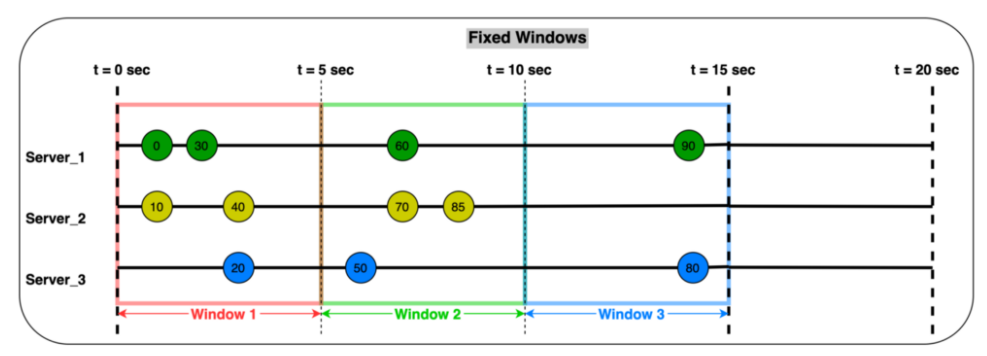
텀블링 Window
고정된 크기의 시간을 가지는 윈도우.
다른 윈도우와 겹치지 않는 고정된 간격이다. 10분으로 지정하면 데이터를 10분마다 10분 단위로 집계한다는 것.
-
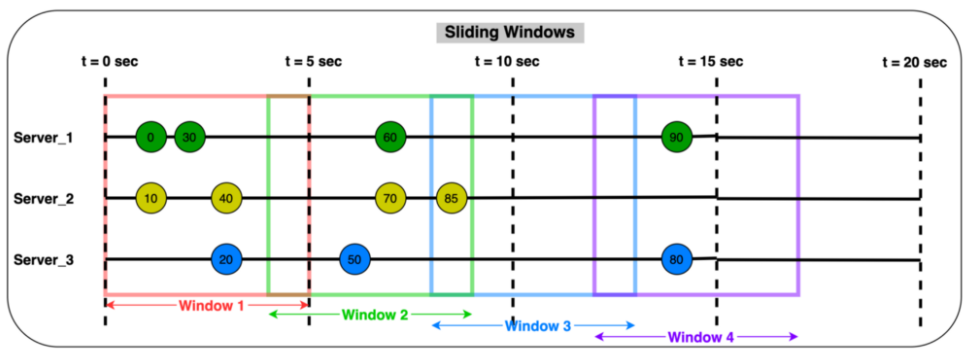
홉핑 Window
다른 윈도우들과 중첩이 되는 윈도우.
고정된 간격을 정의하지만 다른 윈도우와 겹칠 수 있다. 예를 들어 1분 분량의 데이터(윈도우의 시간 길이)를 보고싶지만 10초마다 새로운 윈도우를 표시할 때 사용한다.
(ex) 윈도우가 0:00-1:00, 0:10-1:10, 0:20-1:20 이런식으로 생성되는 것)
-
세션 Window
Session Window는 데이터가 들어오면 윈도우가 시작되고 세션 종료 시간까지 데이터가 들어오지 않으면, 그때 윈도우를 종료하고 새로운 데이터가 들어올 때 다시 새로운 윈도우를 생성한다.
텀블링이나 홉핑과 달리 세션은 각 데이터 키에 새 윈도우를 할당한다.
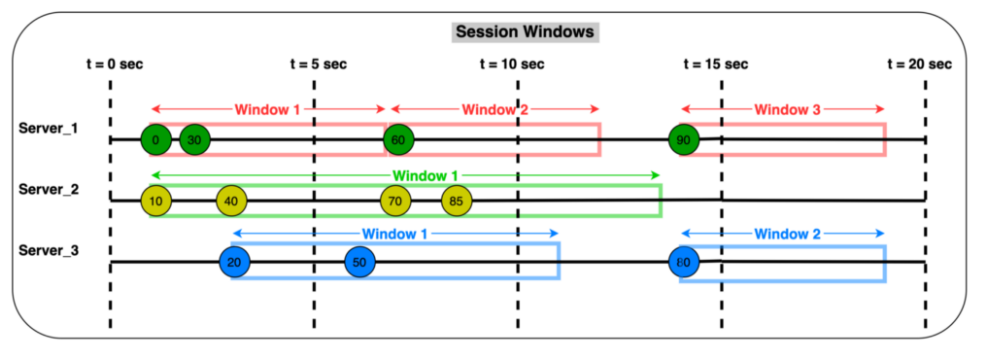
세션에 대한 가장 좋은 사례는 사용자 세션 데이터.
실시간으로 사용자 활동을 캡쳐하는 경우 사용자가 활동을 중지할 때까지 해당 키를 계속 집계한다.
Trigger
트리거는 처리 중인 데이터를 언제 다음 단계로 넘길지를 결정하는 개념.
만약 윈도우 길이가 1시간이라면 실제 결과를 1시간 뒤에나 볼 수 있는데, 이 경우 실시간 데이터 분석이라고 보기 애매해진다.
이때 윈도우가 끝나기 전에 중간 계산한 값들을 보여줄 수 있는데, 이때 이용하는 것이 트리거.
- Time trigger
특정 이벤트 시간에 작동(ex) 5분 단위, 윈도우 시작 후 1번, 우니도우 ㅅ종료 후 1번 등) - Element count trigger
데이터의 개수를 기반으로 작동 (ex) 데이터 100개마다) - Punctuations trigger
특정 데이터가 들어오는 순간에 작동 (ex) A데이터가 들어왔을 때) - Composite trigger
여러 가지 트리거를 조합한 형태
트리거링 될 때마다 전달되는 데이터는 과연 이전 데이터를 처리할까? 하지 않을까?
이때 Accumulating mode 옵션을 이용하여 누적 여부를 선택할 수 있다.
-
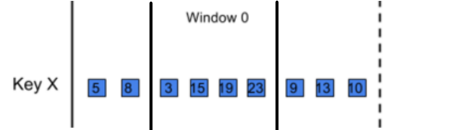
Accumulating mode의 경우
첫번째 트리거 후 : [5,8,3]
두번째 트리거 후 : [5,8,3,15,19,23]
세번째 트리거 후 : [5,8,3,15,19,239,13,10]와 같이 값이 반환되고 -
Discarding mode의 경우
첫번째 트리거 후 [5,8,3]
두번째 트리거 후 [15,19,23]
세번째 트리거 후 [9,13,10]이 반환된다.
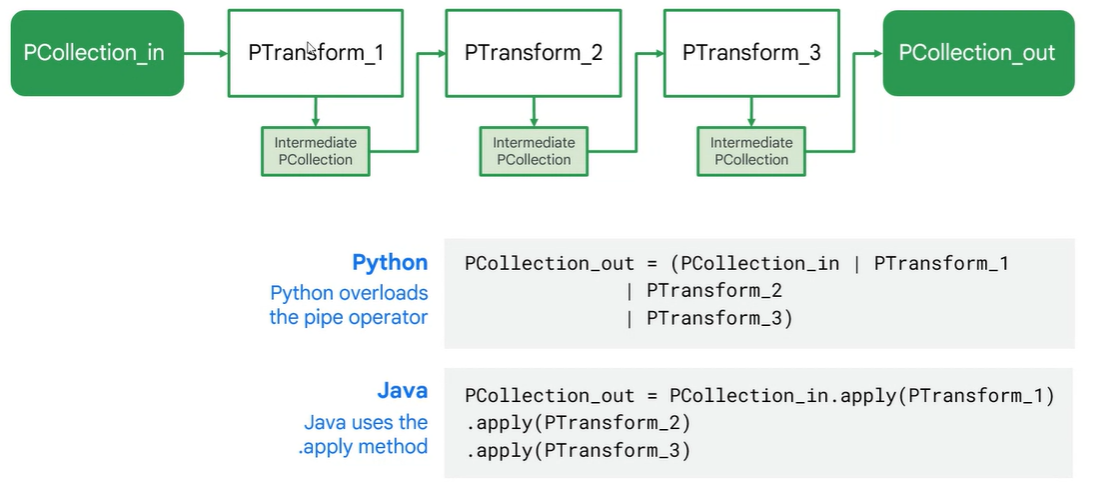
간단한 파이프라인 구성법
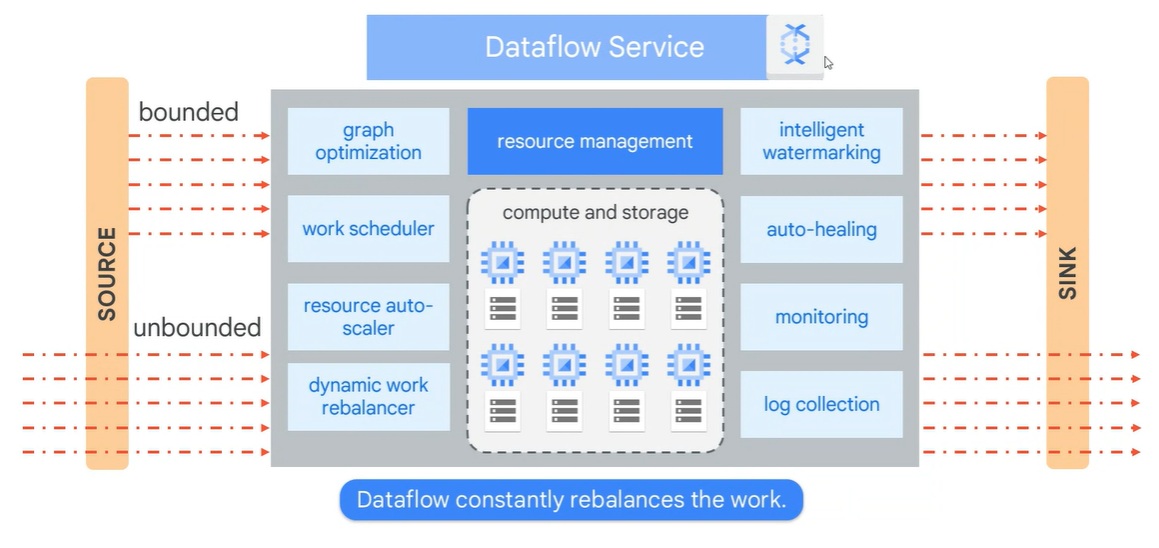
Dataflow 아키텍처
또한, 아래의 Dataflow 아키텍처를 보면 알 수 있다시피 Dataflow를 쓰면 인프라에 대한 신경을 쓸 필요가 없다.
Dataflow vs Dataproc
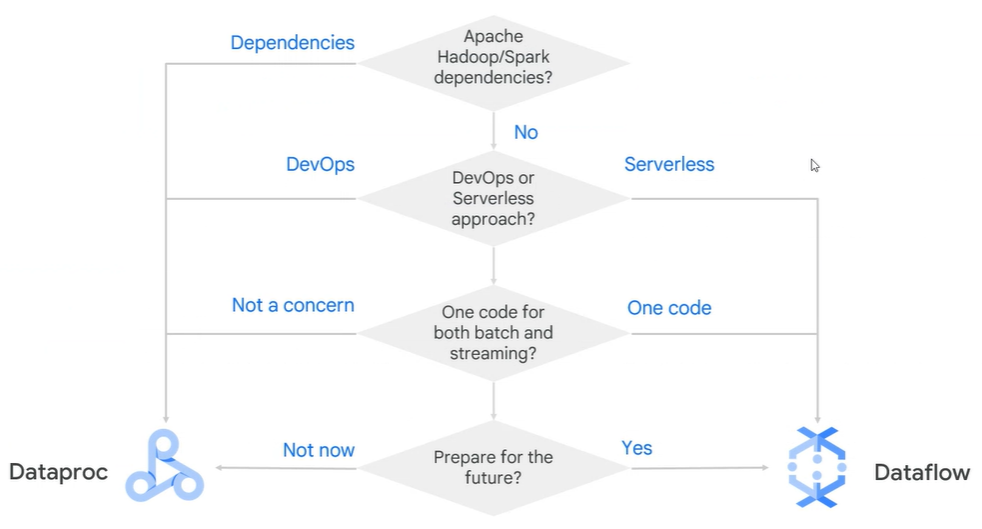
권장사항
Lift & shift 마이그레이션 > dataproc
처음 도입 > dataflow
Dataflow를 선택하게 되면 확장성 및 레이턴시에 있어 장점을 갖고 갈 수 있다.
[Dataflow 참고]
