아키텍처
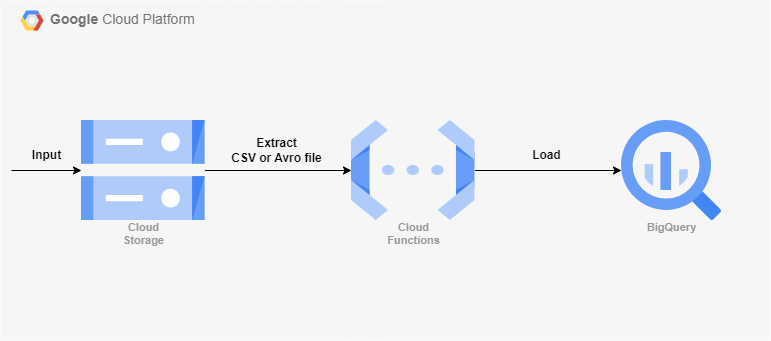
Cloud Storage에 들어오는 데이터를 빅쿼리로 적재하게끔 트리거를 걸 수 있는 Functions을 테스트 해볼 것이다.
두 가지 테스트를 할 것이다.
- 단순히 CSV파일이 들어오면 지정해준 빅쿼리 테이블로 Load 되는 것.
- CSV파일이 들어올 때마다 해당 파일 명으로 테이블이 생성되고 그 테이블에 Load 되는 것.
샘플 데이터는 Sample CSV file 에서 받았다.
다운 받은 CSV
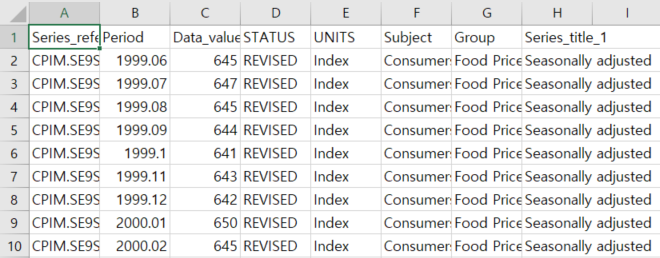
빅쿼리에 데이터 세트와 빈 테이블, Cloud Storage에 버킷을 생성해주자.
Cloud Functions 트리거
첫 번째 테스트
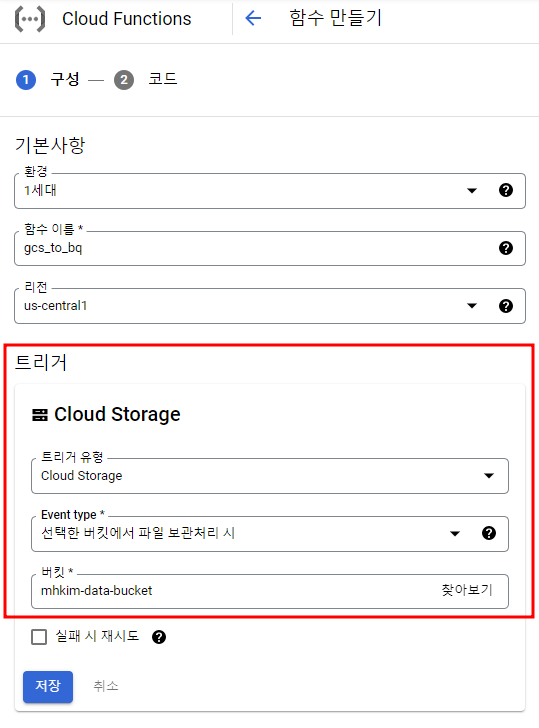
- 런타임 : Python 3.7
- 진입점 : import_to_bigquery
main.py
from google.cloud import bigquery
def import_to_bigquery(data, context):
client = bigquery.Client()
project_id = '<프로젝트 ID>'
dataset_id = '<데이터 세트 명>'
bucket_name = data['bucket']
file_name = data['name']
file_ext = file_name.split('.')[-1]
# gzip으로 압축한 .gz 형식도 지원되므로 해당 형식일 경우 if file_ext == 'gz':로 해도된다.
if file_ext == 'csv':
uri = 'gs://' + bucket_name + '/' + file_name
table_id = '<테이블 명>'
dataset_ref = client.dataset(dataset_id)
table_ref = dataset_ref.table(table_id)
#load config
job_config = bigquery.LoadJobConfig()
job_config.autodetect = True
job_config.schema_update_options = [
bigquery.SchemaUpdateOption.ALLOW_FIELD_ADDITION
]
#load data
load_job = client.load_table_from_uri(
uri,
table_ref,
job_config=job_config
)
print('Started job {}'.format(load_job.job_id))
load_job.result()
print('Job finished.')
destination_table = client.get_table(dataset_ref.table(table_id))
print('Loaded {} rows.'.format(destination_table.num_rows))
else:
print('Nothing To Do')requirements.txt
google-cloud-bigquery
google-cloud-storage배포

버킷에 위에서 다운 받았던 CSV파일을 업로드
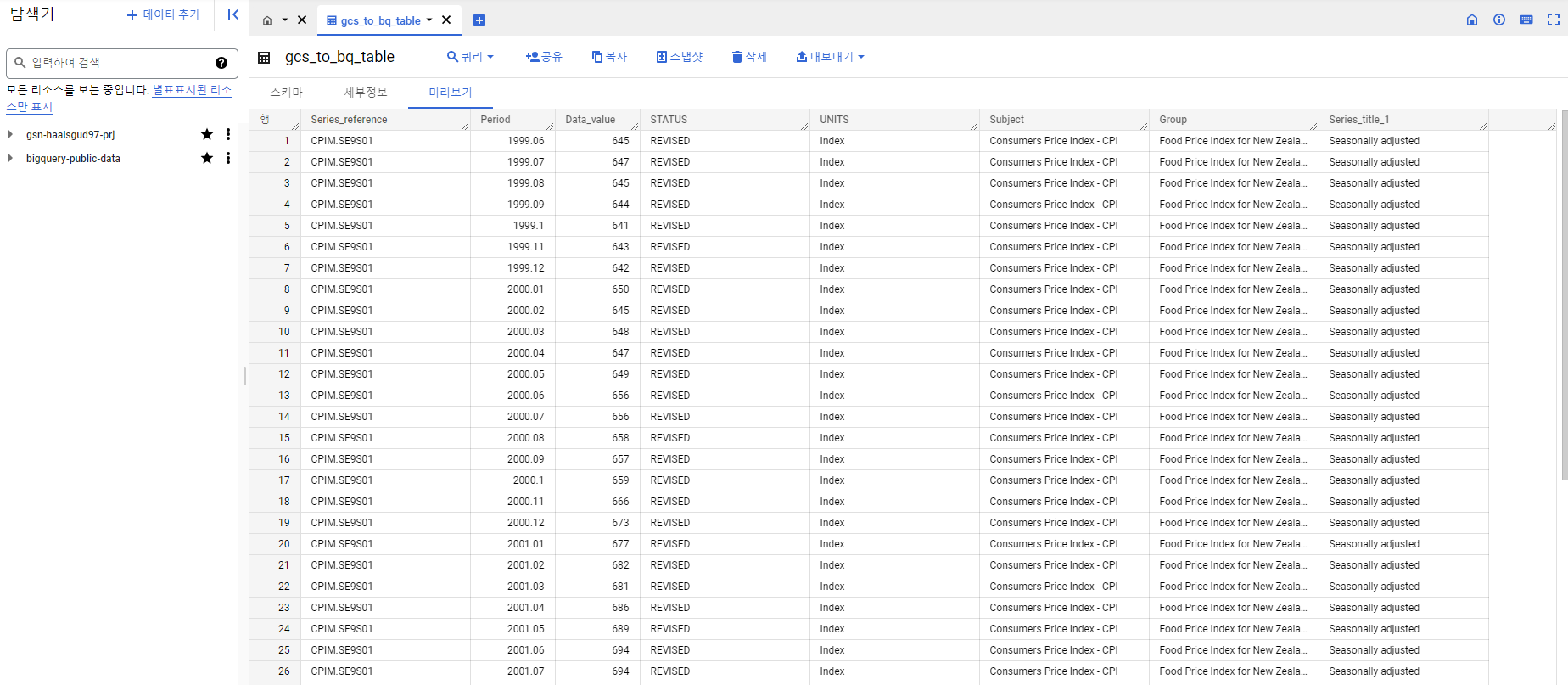
빅쿼리 콘솔에서 확인
Cloud Functions 로그 확인
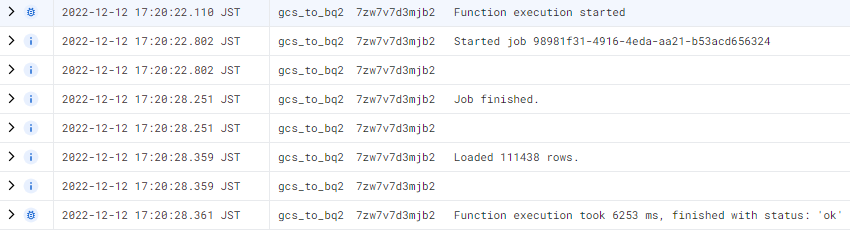
Cloud Functions 트리거2
두 번째 테스트
main.py
from google.cloud import bigquery
def import_to_bigquery2(data, context):
client = bigquery.Client()
project_id = '<프로젝트 ID>'
dataset_id = '<데이터 세트 명>'
bucket_name = data['bucket']
file_name = data['name']
# 테이블 ID를 파일 명에서 .을 기준으로 앞의 파일 이름과 동일하게 지정
table_id = file_name.split('.')[0]
file_ext = file_name.split('.')[-1]
if file_ext == 'csv':
uri = 'gs://' + bucket_name + '/' + file_name
dataset_ref = client.dataset(dataset_id)
table_ref = dataset_ref.table(table_id)
#load config
job_config = bigquery.LoadJobConfig()
job_config.autodetect = True
job_config.schema_update_options = [
bigquery.SchemaUpdateOption.ALLOW_FIELD_ADDITION
]
job_config.create_disposition = [
bigquery.CreateDisposition.CREATE_IF_NEEDED
]
#load data
load_job = client.load_table_from_uri(
uri,
table_ref,
job_config=job_config
)
print('Started job {}'.format(load_job.job_id))
load_job.result()
print('Job finished.')
destination_table = client.get_table(dataset_ref.table(table_id))
print('Loaded {} rows.'.format(destination_table.num_rows))
else:
print('Nothing To Do')버킷에 새로운 CSV파일 추가
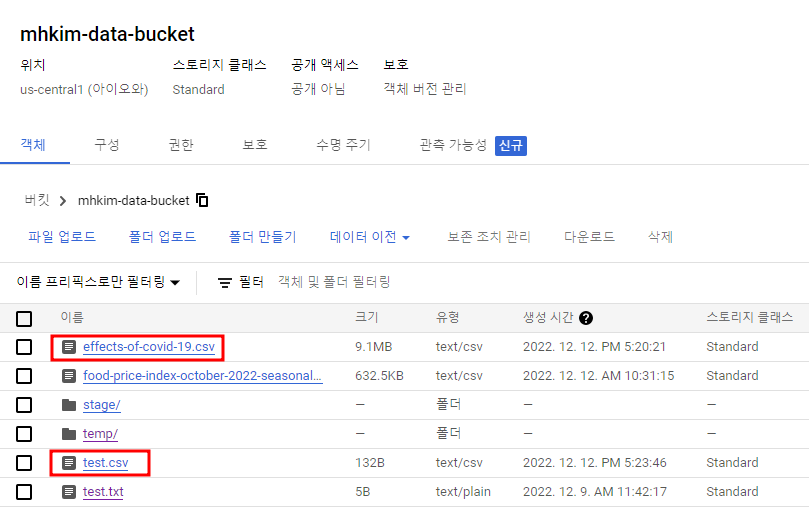
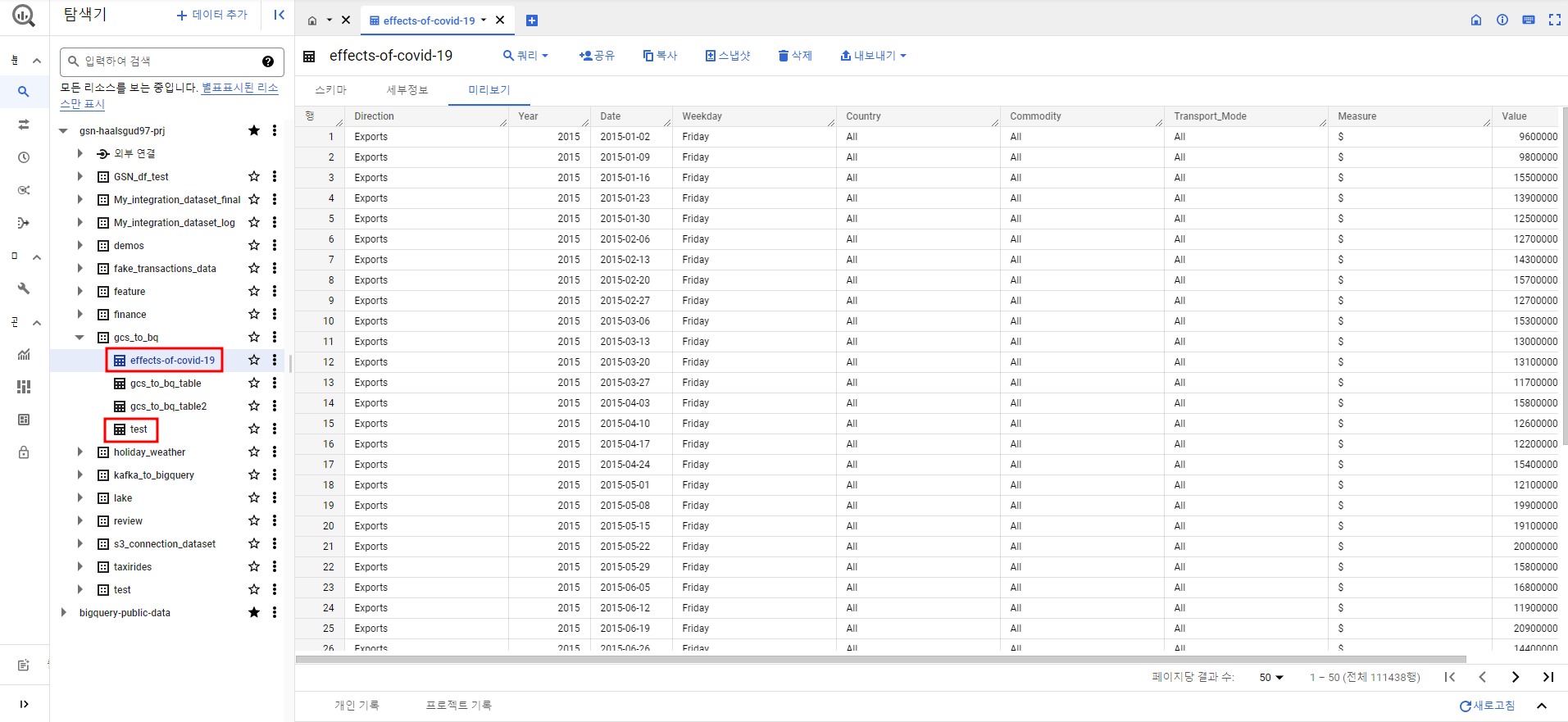
빅쿼리 콘솔에서 파일 명으로 테이블이 생성된 것 확인
주의할 점! 제대로된 csv파일이 아니라 확장자만 csv파일인 경우 아래와 같은 에러가 난다.
400 Error while reading data, error message: Error detected while parsing row starting at position: 0. Error: Bad character (ASCII 0) encountered.
먼저 메모장으로 열어보고 파일이 깨져있지 않은지 확인 후 테스트하자
[Cloud functions를 사용한 GCS to BigQuery 데이터 수집 참고]
https://marketingengineercareer.com/auto-gcs-bigquery

Cloud Solutions Architect | AI/LLM Engineer