아키텍처
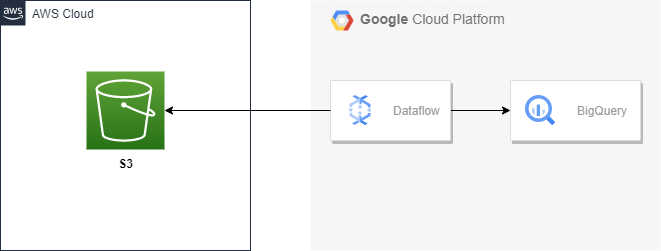
일회성 마이그레이션이나 멀티 클라우드 환경을 쓰고 있지 않는 이상 클라우드간 네트워크 송신 비용이 나가기 때문에 이런 케이스가 많이 있는 편은 아니다.
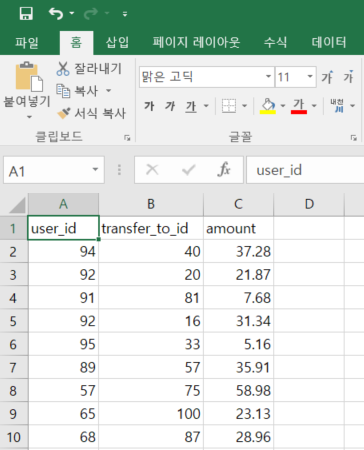
아래와 같은 csv파일에서 각 user_id에 대해 전송된 total amount를 계산해볼 것이다.
user_id가 키이고 amount가 값인 키,값 쌍 생성하여 총 금액을 계산한 후 빅쿼리에 적재하는 구조이다.
transfers_july.csv
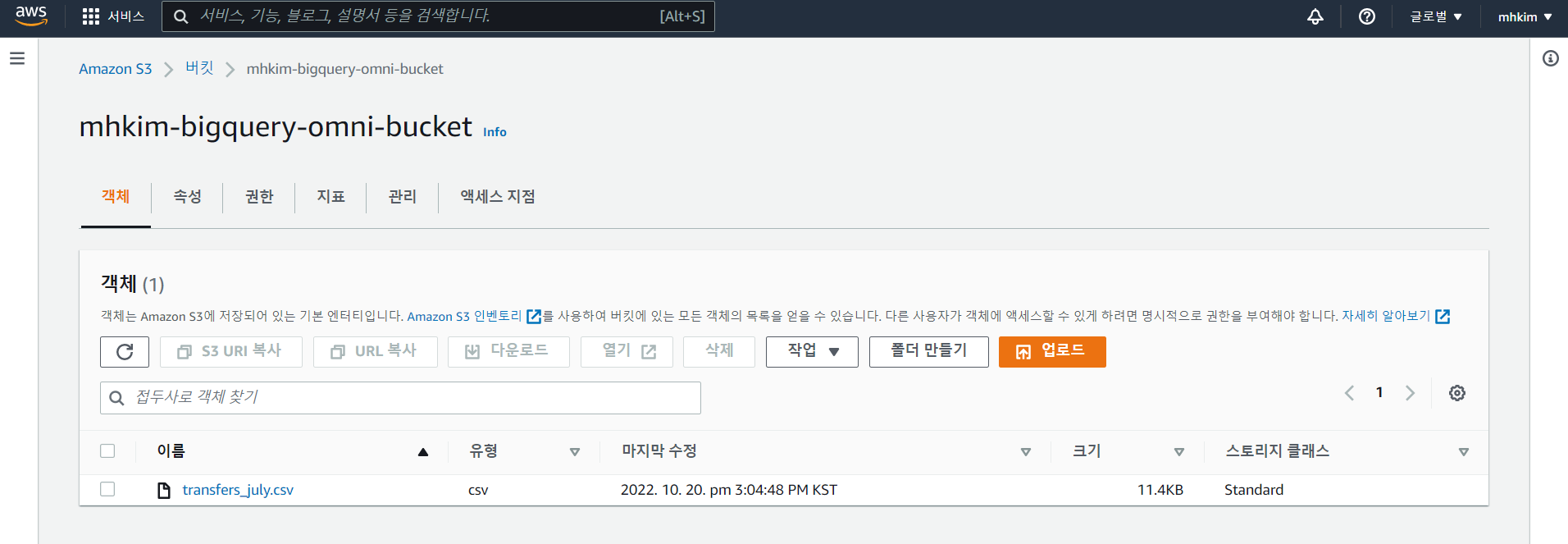
전에 만들어뒀던 s3 버킷에 파일을 올려놨다.
빅쿼리 finance 데이터 세트를 만들고 Dataflow용 Cloud Storage 버킷을 하나 생성해준다.
파이프라인 실행
# 소스 clone
git clone https://github.com/asaharland/beam-pipeline-examples.git
# maven 설치
sudo apt update
sudo apt install maven
# jdk 설치
wget --no-cookies --no-check-certificate --header "Cookie: oraclelicense=accept-securebackup-cookie" https://javadl.oracle.com/webapps/download/GetFile/1.8.0_281-b09/89d678f2be164786b292527658ca1605/linux-i586/jdk-8u281-linux-x64.tar.gz
# 압축 해제
tar xvzf jdk-8u281-linux-x64.tar.gz/etc/profile에 JAVA_HOME까지 설정을 완료해주고 파이프라인을 실행해줄 것이다. 그 전에 파이프라인 옵션을 살펴볼 필요가 있다.
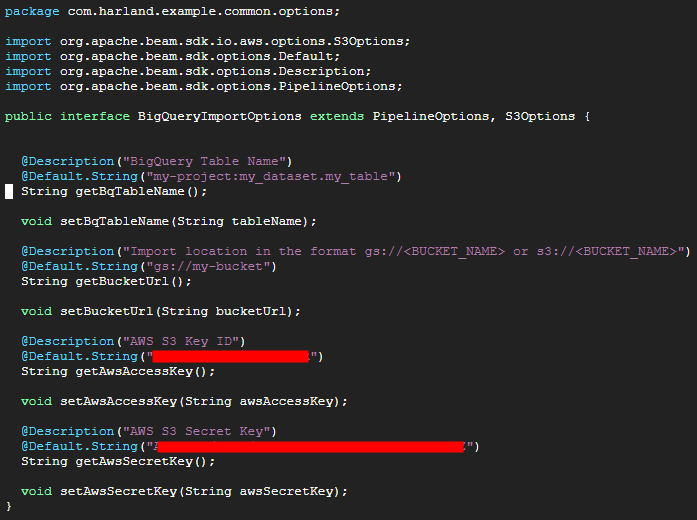
cd ~/beam-pipeline-examples/src/main/java/com/harland/example/common/optionsBigQueryImportOptions.java
default로 @Default.String에 있는 값들이 인식된다.
파이프라인 실행 시 옵션을 따로 지정해주고 싶지 않다면 여기에 값을 넣어서 고정해주면 된다.
파일 실행시 지정해주는 Options은 여기서 정의된 것으로 예를 들어 awsAccessKey와 SecretKey를 실행시 입력해주기 번거롭다고 하면 여기서 default로 지정해주면 된다.
cd ~/beam-pipeline-examples/src/main/java/com/harland/example/batchBigQueryImportPipeline.java
실제 파이프라인이 동작하게 되는 코드이다.
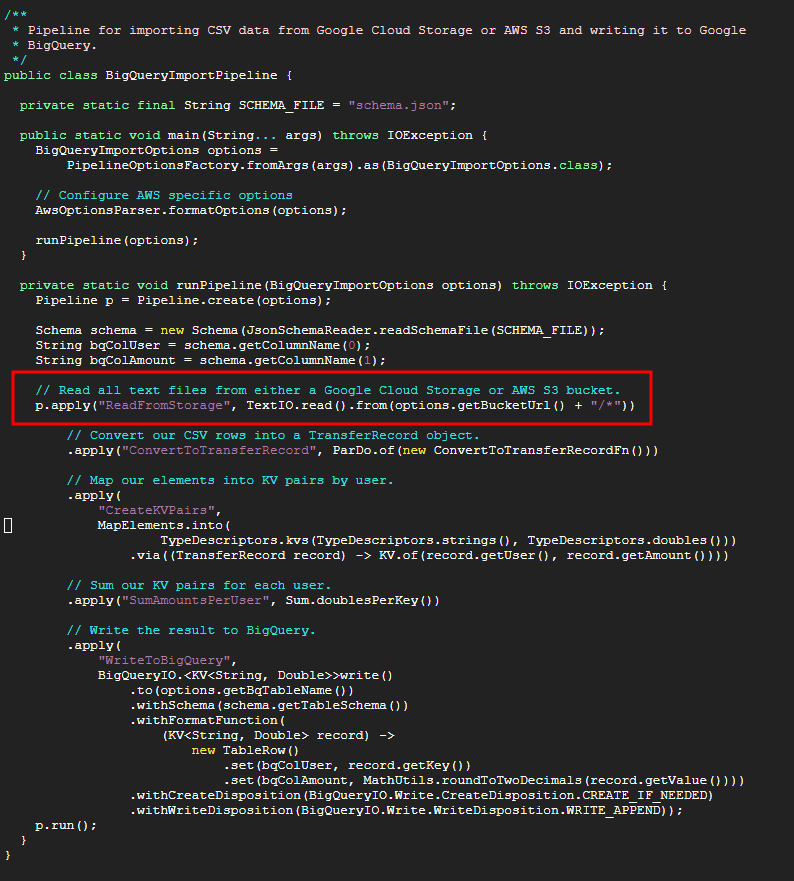
여기서 원하는 파일의 경로를 넣어줘도 되고 위의 사진과 같이 애스터리스크로 설정해줘도 된다. 난 버킷에 해당 파일밖에 없으므로 애스터리스크로 해줬다.
pom.xml이 있는 beam-pipeline-examples 폴더로 돌아와 파이프라인을 실행해주자.
mvn compile exec:java \
-Dexec.mainClass=com.harland.example.batch.BigQueryImportPipeline \
-Dexec.args="--project=<프로젝트 ID> \
--bucketUrl=s3://<s3 버킷 이름> \
--awsRegion=<s3 버킷 region> \
--bqTableName=<프로젝트 ID:finance.transactions> \
--runner=DataflowRunner \
--region=<Dataflow 리전> \
--stagingLocation=gs://<Dataflow용 버킷 이름>/stage/ \
--tempLocation=gs://<Dataflow용 버킷 이름>/temp/"awsAccessKey와 SecretKey는 BigQueryImportOptions.java에서 넣어준 값을 그냥 사용할 것이기 때문에 따로 옵션을 넣지 않았다.

빌드 성공

콘솔에서 확인
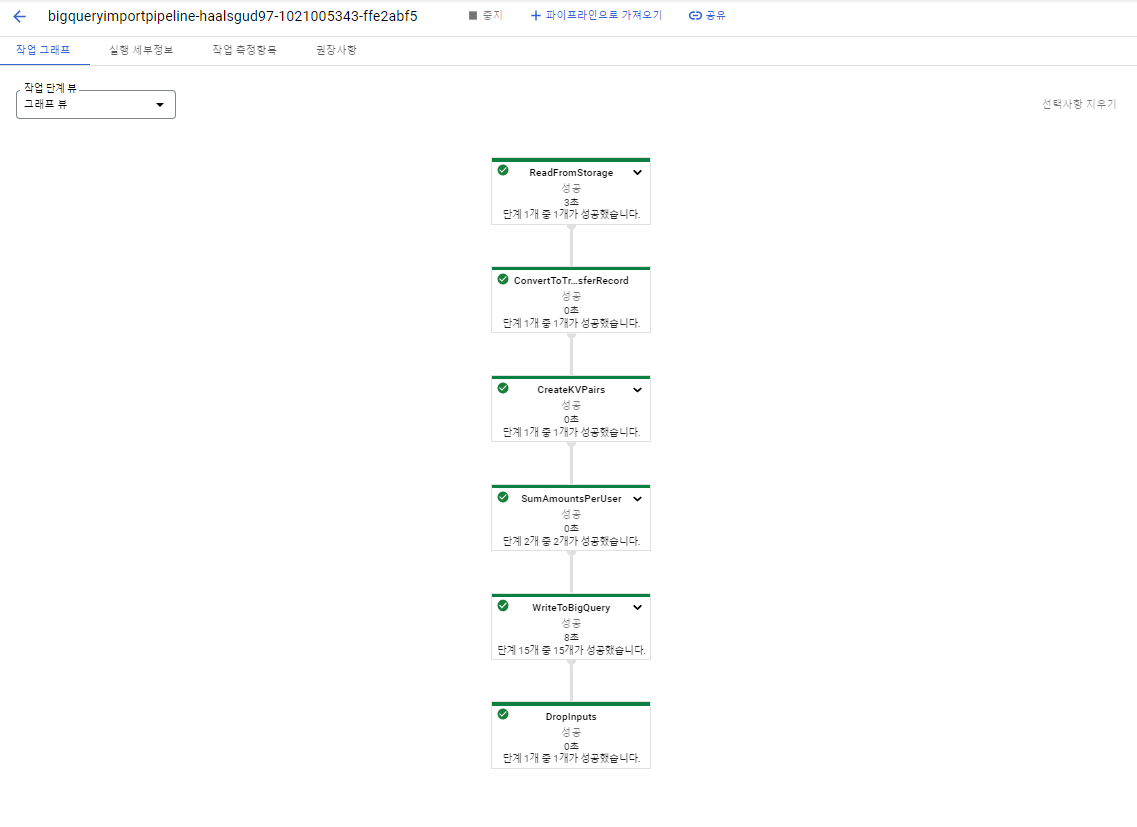
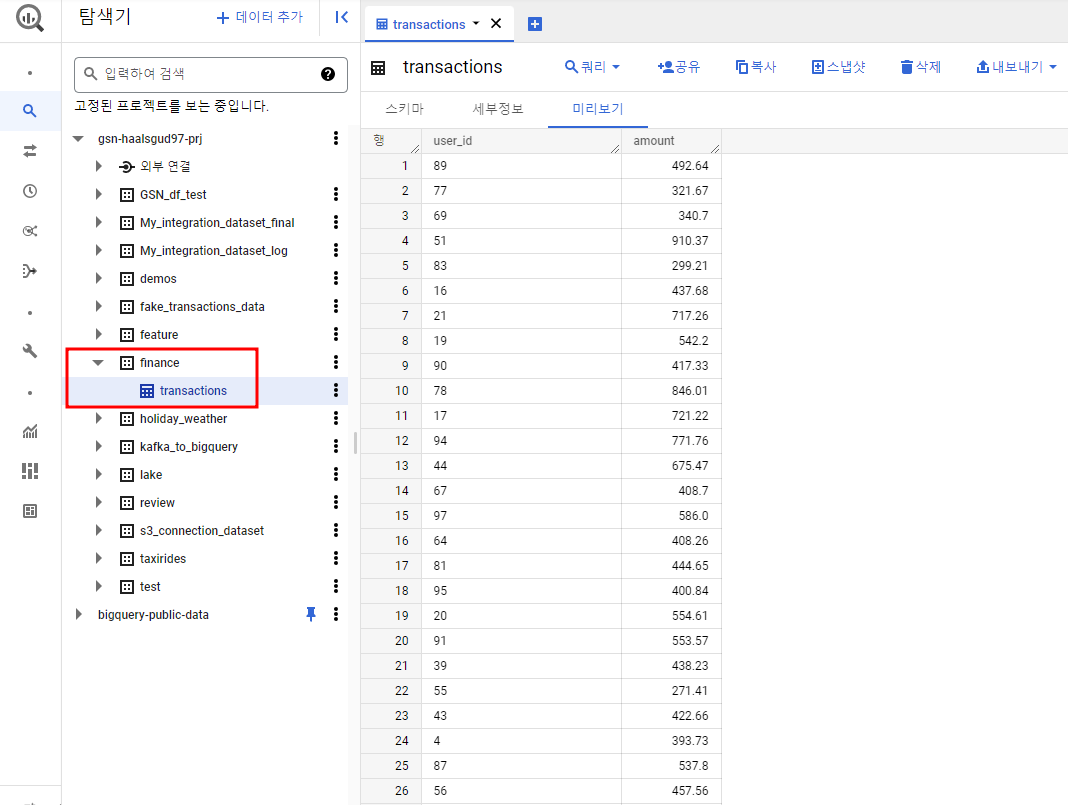
[Dataflow를 사용한 S3 to BigQuery 파이프라인 구축 참고]
https://medium.com/@asajharland/using-apache-beam-to-read-data-from-aws-s3-and-write-to-google-bigquery-3ccd163d12c4
