아키텍처
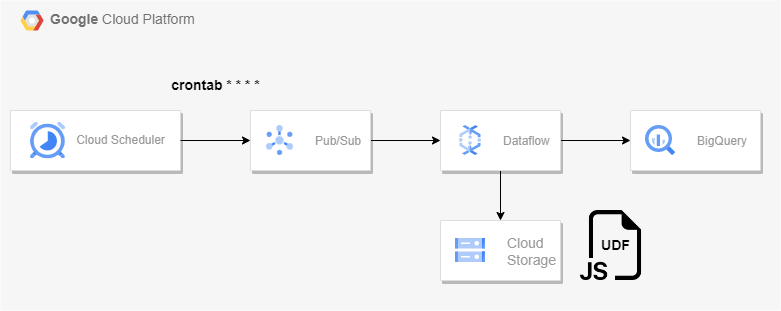
Dataflow의 Pub/Sub Topic to BigQuery 템플릿을 사용해 스트리밍 파이프라인을 구축할 것이다.
Pub/Sub으로 메시지를 게시하는 것은 우선 Cloud Scheduler를 사용하였다.
Pub/Sub 주제를 하나 기본 구독을 하나 추가해서 만들어준다.
Cloud Scheduler 작업 생성
Cloud Scheduler는 crontab을 사용하여 작업을 예약해서 실행해주는 것으로 * * * * 로 설정해서 1분에 한 번씩 pub/sub에 메시지를 게시하도록 설정할 수 있다.
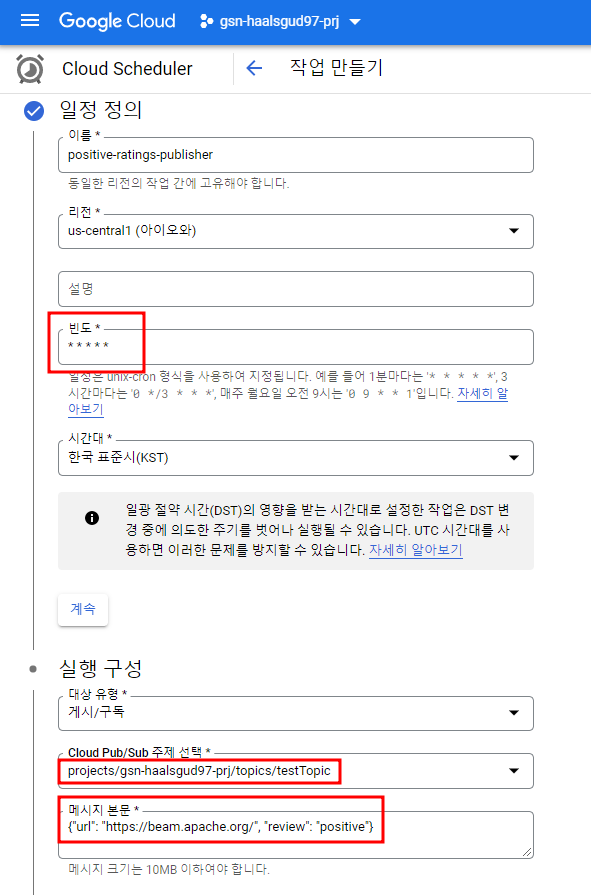
review가 positive인 것, negative인 것 두 가지의 Scheduler를 만들어줄 것이고 negative는 2분에 한 번씩 메시지를 push하게 설정해줄 것이다. 위와 동일한 형태로 이름과 crontab만 /2 * * 로 넣어줘서 Scheduler를 하나 더 만들어주자.

테이블 생성
빅쿼리에 아래의 스키마를 가지는 테이블을 하나 만들어준다.
[
{
"mode": "NULLABLE",
"name": "url",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "review",
"type": "STRING"
}
]UDF
Cloud Storage 버킷을 하나 만들어서 아래의 UDF 파일을 넣어준다. 해당 파일은 JSON을 떨어지는 값들을 빅쿼리에 적재하기 위한 형태로 변환해주는 역할.
datflow_udf_transform.js
function process(inJson) {
// Nashorn engine is only ECMAScript 5.1 (ES5) compliant. Newer ES6
// JavaScript keywords like `let` or `const` will cause syntax errors.
var obj = JSON.parse(inJson);
var includePubsubMessage = obj.data && obj.attributes;
var data = includePubsubMessage ? obj.data : obj;
# url값이 없거나 "https://beam.apache.org/"가 아닌 url이 들어오면 error를 출력하도록 하는 조건
if (!data.hasOwnProperty('url')) {
throw new Error("No url found");
} else if (data.url !== "https://beam.apache.org/") {
throw new Error("Unrecognized url");
}
return JSON.stringify(obj);
}Dataflow 작업 실행
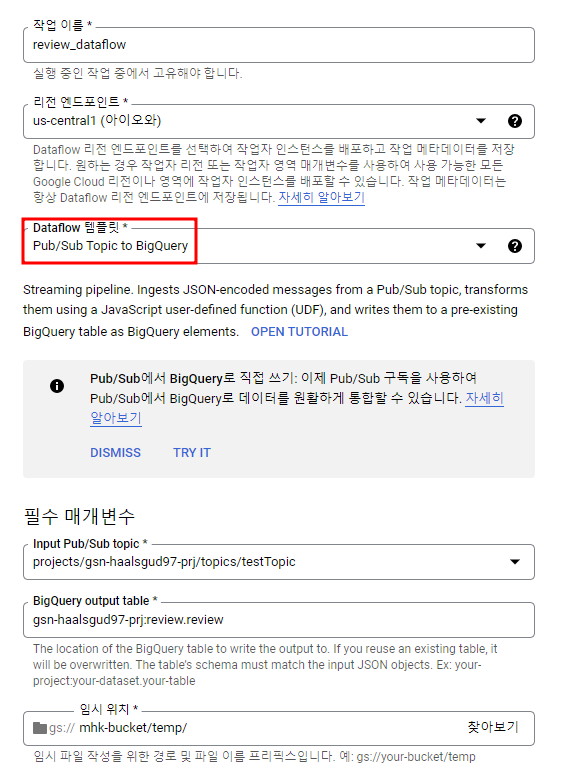
필수 매개변수
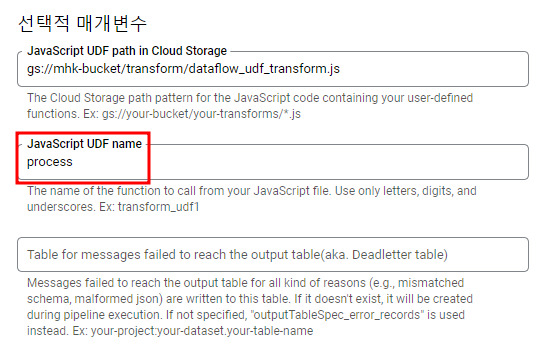
선택적 매개변수
UDF name은 위의 UDF파일에서 실행시키는 함수의 이름이다.
function process(inJSON) 을 실행시켜서 transform을 하는 것이므로 process가 된다.
실행
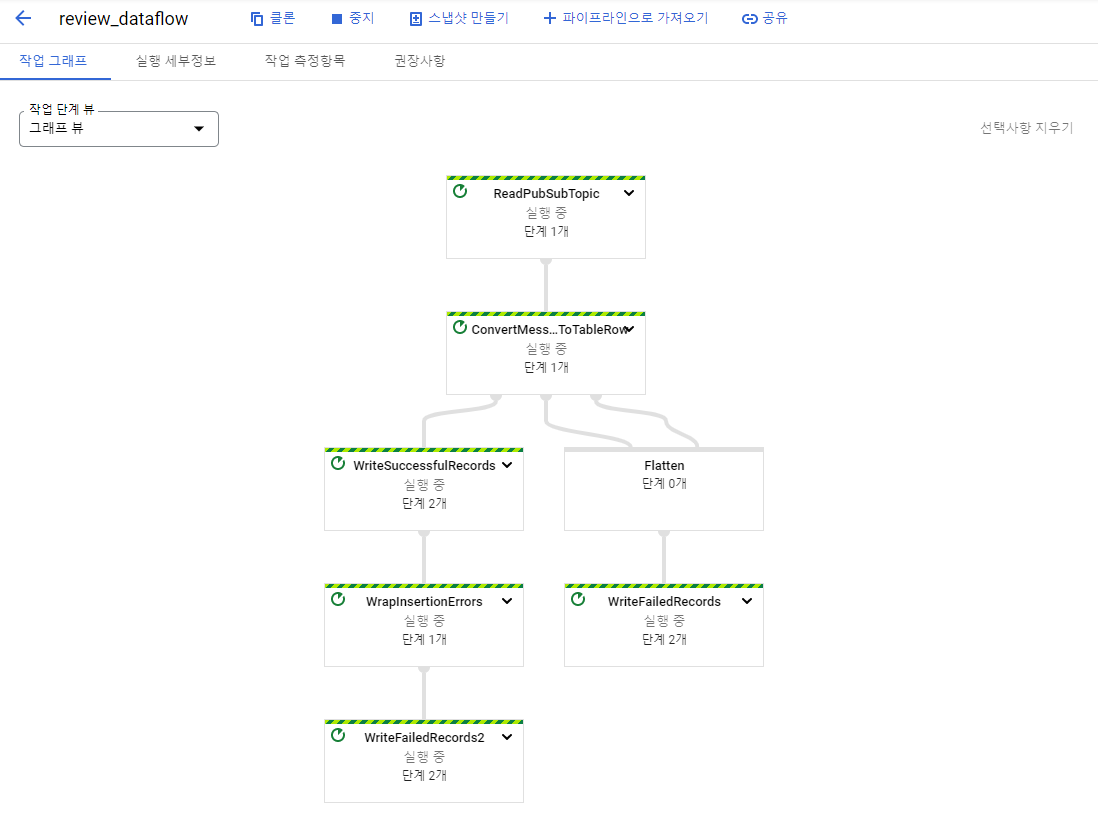
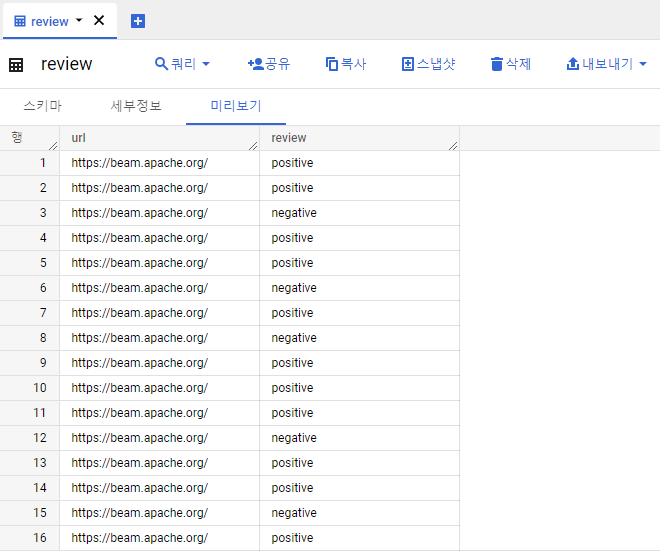
결과 확인

AI Solutions Architect